tensorflow中文官网
介绍
TensorFlow 是由 Google 开发并维护的开源机器学习框架,它旨在简化从研究到生产的整个机器学习工作流程。TensorFlow 提供了灵活且全面的工具、库和社区资源,使得研究人员和开发者可以轻松地构建、训练和部署机器学习模型。
核心特性
- 易用性与灵活性:
- TensorFlow 设计为易于使用,同时提供了足够的灵活性来满足复杂的机器学习任务需求。
- 支持多种编程语言接口,包括 Python、C++、Java 和 JavaScript。
- 强大的生态系统:
- 拥有丰富的预训练模型、数据集以及第三方扩展库(如 TensorFlow Hub, TensorFlow Lite 等)。
- 通过 Keras API 提供高层次抽象,降低了入门门槛;同时也允许用户深入底层进行更精细控制。
- 分布式计算能力:
- 支持多 GPU 和 TPU 加速,适用于大规模数据处理和复杂模型训练。
- 可以跨多个设备甚至集群执行任务,提高了效率和吞吐量。
- 可移植性:
- TensorFlow Lite 专为移动设备和嵌入式系统优化,便于在边缘端部署模型。
- TensorFlow.js 允许直接在浏览器中运行 ML 模型,无需服务器端支持。
- 可视化工具:
- TensorBoard 是一个内置的可视化工具,用于监控训练进度、调试模型性能等。
- 支持记录和展示损失函数曲线、准确率变化图等多种图表。
- 自动微分机制:
- 自动计算梯度,简化了反向传播过程中的数学运算。
- 支持动态计算图(Eager Execution),使代码更加直观易读。
- 版本管理:
- TensorFlow 版本更新频繁,但保持良好的向后兼容性,确保现有项目能够平稳迁移至新版本。
主要模块
- tf.keras:高层API,用于快速原型设计和实验,提供简单易用的接口来定义、编译和评估模型。
- tf.data:高效加载和预处理数据集的库,支持管道化操作,提升数据输入速度。
- tf.distribute:实现分布式训练的功能集合,包括 MirroredStrategy 和 MultiWorkerMirroredStrategy。
- tf.saved_model:保存和加载完整的模型结构及权重,方便模型共享和服务部署。
- tf.estimator:封装了训练循环逻辑,适合大规模生产环境下的应用开发。
- tf.hub:访问预先训练好的模块,加速新项目的启动,并促进模型重用。
在 TensorFlow 中,自定义损失函数和层(Layer)是扩展框架功能、实现特定需求或优化模型性能的重要手段。下面我将详细介绍如何在 TensorFlow 中创建自定义损失函数和自定义层。
自定义损失函数
导包
from tensorflow import keras
import numpy as np
import pandas
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
数据加载、切割、标准化
housing = fetch_california_housing()
print(housing.DESCR)
.. _california_housing_dataset:California Housing dataset
--------------------------**Data Set Characteristics:**:Number of Instances: 20640:Number of Attributes: 8 numeric, predictive attributes and the target:Attribute Information:- MedInc median income in block- HouseAge median house age in block- AveRooms average number of rooms- AveBedrms average number of bedrooms- Population block population- AveOccup average house occupancy- Latitude house block latitude- Longitude house block longitude:Missing Attribute Values: NoneThis dataset was obtained from the StatLib repository.
http://lib.stat.cmu.edu/datasets/The target variable is the median house value for California districts.This dataset was derived from the 1990 U.S. census, using one row per census
block group. A block group is the smallest geographical unit for which the U.S.
Census Bureau publishes sample data (a block group typically has a population
of 600 to 3,000 people).It can be downloaded/loaded using the
:func:`sklearn.datasets.fetch_california_housing` function... topic:: References- Pace, R. Kelley and Ronald Barry, Sparse Spatial Autoregressions,Statistics and Probability Letters, 33 (1997) 291-297
print(housing.target)
[4.526 3.585 3.521 ... 0.923 0.847 0.894]
print(housing.data)
[[ 8.3252 41. 6.98412698 ... 2.5555555637.88 -122.23 ][ 8.3014 21. 6.23813708 ... 2.1098418337.86 -122.22 ][ 7.2574 52. 8.28813559 ... 2.8022598937.85 -122.24 ]...[ 1.7 17. 5.20554273 ... 2.325635139.43 -121.22 ][ 1.8672 18. 5.32951289 ... 2.1232091739.43 -121.32 ][ 2.3886 16. 5.25471698 ... 2.6169811339.37 -121.24 ]]
housing.data.shape
(20640, 8)
# 切割数据
# 训练数据, 验证集, 测试数据
from sklearn.model_selection import train_test_splitx_train_all, x_test, y_train_all, y_test = train_test_split(housing.data, housing.target, random_state=7)
# 从x_train_all中切割出训练数据和校验数据
x_train, x_valid, y_train, y_valid = train_test_split(x_train_all, y_train_all, random_state=11)
print(x_train.shape, y_train.shape)
print(x_valid.shape, y_valid.shape)
print(x_test.shape, y_test.shape)
(11610, 8) (11610,)
(3870, 8) (3870,)
(5160, 8) (5160,)
# 标准化处理
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.transform(x_valid)
x_test_scaled = scaler.transform(x_test)
x_train.shape
(11610, 8)
# 定义网络
model = keras.models.Sequential([# input_dim, input_shape一定要是元组keras.layers.Dense(32, activation='relu', input_shape=x_train.shape[1:]),keras.layers.Dense(1)
])
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 32) 288
_________________________________________________________________
dense_3 (Dense) (None, 1) 33
=================================================================
Total params: 321
Trainable params: 321
Non-trainable params: 0
_________________________________________________________________
定义损失函数
自定义损失函数可以通过继承 tf.keras.losses.Loss 类或者直接定义一个返回标量张量的 Python 函数来实现。后者更为简单,适合快速原型设计。
示例:使用 Python 函数定义
# 自定义损失函数
def customized_mse(y_true, y_pred):return tf.reduce_mean(tf.square(y_pred - y_true))
示例:继承 tf.keras.losses.Loss 类
class CustomLoss(tf.keras.losses.Loss):def __init__(self, reduction=tf.keras.losses.Reduction.AUTO, name='custom_loss'):super().__init__(reduction=reduction, name=name)def call(self, y_true, y_pred):# 自定义损失逻辑mse = tf.reduce_mean(tf.square(y_true - y_pred))mae = tf.reduce_mean(tf.abs(y_true - y_pred))return mse + mae
使用自定义损失函数
model.compile(loss=customized_mse, optimizer='sgd', metrics=[customized_mse])
训练
callbacks = []
history = model.fit(x_train_scaled, y_train, validation_data=(x_valid_scaled, y_valid), epochs=20)
Epoch 1/20
363/363 [==============================] - 1s 3ms/step - loss: 1.4343 - customized_mse: 1.4343 - val_loss: 0.5649 - val_customized_mse: 0.5649
Epoch 2/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4926 - customized_mse: 0.4926 - val_loss: 0.4804 - val_customized_mse: 0.4803
Epoch 3/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4379 - customized_mse: 0.4379 - val_loss: 0.4364 - val_customized_mse: 0.4363
Epoch 4/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4383 - customized_mse: 0.4383 - val_loss: 0.4246 - val_customized_mse: 0.4246
Epoch 5/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4080 - customized_mse: 0.4080 - val_loss: 0.6906 - val_customized_mse: 0.6904
Epoch 6/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4162 - customized_mse: 0.4162 - val_loss: 0.4171 - val_customized_mse: 0.4170
Epoch 7/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4023 - customized_mse: 0.4023 - val_loss: 0.4055 - val_customized_mse: 0.4055
Epoch 8/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3899 - customized_mse: 0.3899 - val_loss: 0.3947 - val_customized_mse: 0.3946
Epoch 9/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3905 - customized_mse: 0.3905 - val_loss: 0.3963 - val_customized_mse: 0.3962
Epoch 10/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3874 - customized_mse: 0.3875 - val_loss: 0.3891 - val_customized_mse: 0.3891
Epoch 11/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3707 - customized_mse: 0.3707 - val_loss: 0.3907 - val_customized_mse: 0.3906
Epoch 12/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3787 - customized_mse: 0.3787 - val_loss: 0.3818 - val_customized_mse: 0.3817
Epoch 13/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4084 - customized_mse: 0.4084 - val_loss: 0.3895 - val_customized_mse: 0.3894
Epoch 14/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3777 - customized_mse: 0.3777 - val_loss: 0.3799 - val_customized_mse: 0.3798
Epoch 15/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3656 - customized_mse: 0.3656 - val_loss: 0.4434 - val_customized_mse: 0.4433
Epoch 16/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3719 - customized_mse: 0.3719 - val_loss: 0.3776 - val_customized_mse: 0.3776
Epoch 17/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3799 - customized_mse: 0.3799 - val_loss: 0.3731 - val_customized_mse: 0.3730
Epoch 18/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3615 - customized_mse: 0.3615 - val_loss: 0.3756 - val_customized_mse: 0.3755
Epoch 19/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3606 - customized_mse: 0.3606 - val_loss: 0.3682 - val_customized_mse: 0.3682
Epoch 20/20
363/363 [==============================] - 1s 3ms/step - loss: 0.3899 - customized_mse: 0.3899 - val_loss: 0.3719 - val_customized_mse: 0.3719
history.history
{'loss': [0.9330089092254639,0.4829031229019165,0.4407883882522583,0.42390236258506775,0.4048228859901428,0.4041661322116852,0.3916810154914856,0.38817623257637024,0.3936411142349243,0.38223010301589966,0.38164976239204407,0.37922564148902893,0.3890188932418823,0.3752993047237396,0.37175652384757996,0.37133264541625977,0.3659913241863251,0.37019574642181396,0.3612913191318512,0.38453325629234314],'customized_mse': [0.9329553842544556,0.4827798008918762,0.4406143128871918,0.42377719283103943,0.40507742762565613,0.404208779335022,0.3916202187538147,0.38803204894065857,0.39359644055366516,0.38262665271759033,0.38174769282341003,0.3791141211986542,0.388969749212265,0.3752574622631073,0.37183016538619995,0.37126845121383667,0.3661367893218994,0.3701113164424896,0.3612798750400543,0.3848443925380707],'val_loss': [0.5649064779281616,0.4803864061832428,0.43639206886291504,0.4246464669704437,0.6905779838562012,0.4171085059642792,0.4055274724960327,0.3946874141693115,0.39630359411239624,0.38914406299591064,0.3907262980937958,0.3817906677722931,0.38947609066963196,0.3798745572566986,0.4433743953704834,0.3776334822177887,0.37310510873794556,0.375590980052948,0.36824488639831543,0.3719286024570465],'val_customized_mse': [0.5648690462112427,0.4803106188774109,0.4363250434398651,0.4245661199092865,0.6903709769248962,0.417031466960907,0.4054512083530426,0.3946200907230377,0.39622586965560913,0.3890681564807892,0.3906453251838684,0.38171830773353577,0.38940656185150146,0.37980276346206665,0.44327959418296814,0.3775603771209717,0.373036652803421,0.3755183517932892,0.3681769073009491,0.37186044454574585]}
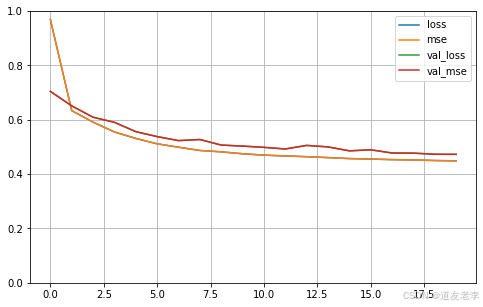
可视化
# 定义画图的函数
def plot_learning_curves(history):pandas.DataFrame(history.history).plot(figsize=(8, 5))plt.grid(True)plt.gca().set_ylim(0, 1)plt.show()
plot_learning_curves(history)
自定义layer
导包
from tensorflow import keras
import numpy as np
import pandas
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
数据加载、切割、标准化
housing = fetch_california_housing()
print(housing.DESCR)
.. _california_housing_dataset:California Housing dataset
--------------------------**Data Set Characteristics:**:Number of Instances: 20640:Number of Attributes: 8 numeric, predictive attributes and the target:Attribute Information:- MedInc median income in block- HouseAge median house age in block- AveRooms average number of rooms- AveBedrms average number of bedrooms- Population block population- AveOccup average house occupancy- Latitude house block latitude- Longitude house block longitude:Missing Attribute Values: NoneThis dataset was obtained from the StatLib repository.
http://lib.stat.cmu.edu/datasets/The target variable is the median house value for California districts.This dataset was derived from the 1990 U.S. census, using one row per census
block group. A block group is the smallest geographical unit for which the U.S.
Census Bureau publishes sample data (a block group typically has a population
of 600 to 3,000 people).It can be downloaded/loaded using the
:func:`sklearn.datasets.fetch_california_housing` function... topic:: References- Pace, R. Kelley and Ronald Barry, Sparse Spatial Autoregressions,Statistics and Probability Letters, 33 (1997) 291-297print(housing.target)
[4.526 3.585 3.521 ... 0.923 0.847 0.894]
print(housing.data)
[[ 8.3252 41. 6.98412698 ... 2.5555555637.88 -122.23 ][ 8.3014 21. 6.23813708 ... 2.1098418337.86 -122.22 ][ 7.2574 52. 8.28813559 ... 2.8022598937.85 -122.24 ]...[ 1.7 17. 5.20554273 ... 2.325635139.43 -121.22 ][ 1.8672 18. 5.32951289 ... 2.1232091739.43 -121.32 ][ 2.3886 16. 5.25471698 ... 2.6169811339.37 -121.24 ]]
housing.data.shape
(20640, 8)
# 切割数据
# 训练数据, 验证集, 测试数据
from sklearn.model_selection import train_test_splitx_train_all, x_test, y_train_all, y_test = train_test_split(housing.data, housing.target, random_state=7)
# 从x_train_all中切割出训练数据和校验数据
x_train, x_valid, y_train, y_valid = train_test_split(x_train_all, y_train_all, random_state=11)
print(x_train.shape, y_train.shape)
print(x_valid.shape, y_valid.shape)
print(x_test.shape, y_test.shape)
(11610, 8) (11610,)
(3870, 8) (3870,)
(5160, 8) (5160,)
# 标准化处理
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.transform(x_valid)
x_test_scaled = scaler.transform(x_test)
x_train.shape
(11610, 8)
layer = keras.layers.Dense(30, activation='relu', input_shape=(None, 5))
layer
<tensorflow.python.keras.layers.core.Dense at 0x23284c0f438>
layer.variables
[]
layer(np.zeros((10, 5)))
<tf.Tensor: shape=(10, 30), dtype=float32, numpy=
array([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]],dtype=float32)>
layer.variables
[<tf.Variable 'dense_2/kernel:0' shape=(5, 30) dtype=float32, numpy=array([[ 0.07377875, -0.15781999, 0.17441806, 0.41044047, 0.12637928,0.10069057, -0.40888438, 0.21114597, -0.04102927, 0.1911104 ,0.3706499 , -0.00777152, 0.39653602, -0.10702813, 0.21069297,0.4063345 , -0.38374054, -0.02153224, 0.22235844, -0.19130173,-0.11121887, -0.17694052, -0.14725426, -0.1367077 , -0.15052724,-0.10059273, -0.11096448, 0.36246517, -0.41349265, -0.1332745 ],[ 0.01045567, 0.25692943, -0.04703212, -0.40742022, -0.058061 ,0.19963357, -0.3597136 , -0.40909523, -0.21741137, -0.06122807,0.33772853, 0.25582066, 0.2508687 , 0.03732511, -0.22112669,0.13669083, -0.12699288, 0.14908692, -0.2465779 , -0.35868874,0.03354365, -0.39276415, -0.40883037, 0.18581268, 0.03020394,0.04725698, 0.36262736, -0.41178173, 0.13068542, 0.30259296],[-0.0390532 , 0.35915825, -0.14900988, 0.14218625, 0.22392318,-0.06672826, -0.37295154, 0.2179173 , -0.1641698 , 0.20182136,0.2693365 , -0.05218098, 0.02333841, 0.08451191, -0.02421036,0.17832932, -0.04388756, 0.29842207, 0.04996797, 0.21740773,-0.00870329, 0.08936617, -0.10373649, -0.12448472, 0.0588907 ,0.18343005, 0.1960747 , 0.2588921 , 0.19400522, 0.21396032],[-0.3160454 , 0.4080445 , 0.26255247, 0.27086523, -0.09026864,-0.0124262 , -0.16098952, -0.38160753, -0.13196355, -0.20225649,-0.12518492, 0.3570473 , 0.06296387, 0.10744056, -0.37734276,0.04127458, -0.25249505, 0.32583037, -0.15164885, -0.321797 ,0.3949028 , 0.10671434, -0.30817616, -0.24316958, -0.04385281,-0.29339156, 0.36301878, 0.04189736, -0.24018642, 0.39192936],[ 0.25731334, -0.31793687, -0.29365364, 0.24058959, -0.28362244,0.33795986, -0.19459574, 0.3009247 , 0.04505309, 0.12755081,-0.29095498, -0.34372756, 0.31210646, 0.17511132, -0.11675891,0.29953584, 0.352039 , 0.28779158, 0.40831617, -0.23186448,-0.06609696, 0.36298928, -0.28264546, 0.21196845, 0.40569887,-0.33992565, 0.13081315, 0.30123344, -0.22727355, 0.29445478]],dtype=float32)>,<tf.Variable 'dense_2/bias:0' shape=(30,) dtype=float32, numpy=array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)>]
layer.trainable
True
layer.trainable_variables
[<tf.Variable 'dense_2/kernel:0' shape=(5, 30) dtype=float32, numpy=array([[ 0.07377875, -0.15781999, 0.17441806, 0.41044047, 0.12637928,0.10069057, -0.40888438, 0.21114597, -0.04102927, 0.1911104 ,0.3706499 , -0.00777152, 0.39653602, -0.10702813, 0.21069297,0.4063345 , -0.38374054, -0.02153224, 0.22235844, -0.19130173,-0.11121887, -0.17694052, -0.14725426, -0.1367077 , -0.15052724,-0.10059273, -0.11096448, 0.36246517, -0.41349265, -0.1332745 ],[ 0.01045567, 0.25692943, -0.04703212, -0.40742022, -0.058061 ,0.19963357, -0.3597136 , -0.40909523, -0.21741137, -0.06122807,0.33772853, 0.25582066, 0.2508687 , 0.03732511, -0.22112669,0.13669083, -0.12699288, 0.14908692, -0.2465779 , -0.35868874,0.03354365, -0.39276415, -0.40883037, 0.18581268, 0.03020394,0.04725698, 0.36262736, -0.41178173, 0.13068542, 0.30259296],[-0.0390532 , 0.35915825, -0.14900988, 0.14218625, 0.22392318,-0.06672826, -0.37295154, 0.2179173 , -0.1641698 , 0.20182136,0.2693365 , -0.05218098, 0.02333841, 0.08451191, -0.02421036,0.17832932, -0.04388756, 0.29842207, 0.04996797, 0.21740773,-0.00870329, 0.08936617, -0.10373649, -0.12448472, 0.0588907 ,0.18343005, 0.1960747 , 0.2588921 , 0.19400522, 0.21396032],[-0.3160454 , 0.4080445 , 0.26255247, 0.27086523, -0.09026864,-0.0124262 , -0.16098952, -0.38160753, -0.13196355, -0.20225649,-0.12518492, 0.3570473 , 0.06296387, 0.10744056, -0.37734276,0.04127458, -0.25249505, 0.32583037, -0.15164885, -0.321797 ,0.3949028 , 0.10671434, -0.30817616, -0.24316958, -0.04385281,-0.29339156, 0.36301878, 0.04189736, -0.24018642, 0.39192936],[ 0.25731334, -0.31793687, -0.29365364, 0.24058959, -0.28362244,0.33795986, -0.19459574, 0.3009247 , 0.04505309, 0.12755081,-0.29095498, -0.34372756, 0.31210646, 0.17511132, -0.11675891,0.29953584, 0.352039 , 0.28779158, 0.40831617, -0.23186448,-0.06609696, 0.36298928, -0.28264546, 0.21196845, 0.40569887,-0.33992565, 0.13081315, 0.30123344, -0.22727355, 0.29445478]],dtype=float32)>,<tf.Variable 'dense_2/bias:0' shape=(30,) dtype=float32, numpy=array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)>]
layer.trainable_weights
[<tf.Variable 'dense_2/kernel:0' shape=(5, 30) dtype=float32, numpy=array([[ 0.07377875, -0.15781999, 0.17441806, 0.41044047, 0.12637928,0.10069057, -0.40888438, 0.21114597, -0.04102927, 0.1911104 ,0.3706499 , -0.00777152, 0.39653602, -0.10702813, 0.21069297,0.4063345 , -0.38374054, -0.02153224, 0.22235844, -0.19130173,-0.11121887, -0.17694052, -0.14725426, -0.1367077 , -0.15052724,-0.10059273, -0.11096448, 0.36246517, -0.41349265, -0.1332745 ],[ 0.01045567, 0.25692943, -0.04703212, -0.40742022, -0.058061 ,0.19963357, -0.3597136 , -0.40909523, -0.21741137, -0.06122807,0.33772853, 0.25582066, 0.2508687 , 0.03732511, -0.22112669,0.13669083, -0.12699288, 0.14908692, -0.2465779 , -0.35868874,0.03354365, -0.39276415, -0.40883037, 0.18581268, 0.03020394,0.04725698, 0.36262736, -0.41178173, 0.13068542, 0.30259296],[-0.0390532 , 0.35915825, -0.14900988, 0.14218625, 0.22392318,-0.06672826, -0.37295154, 0.2179173 , -0.1641698 , 0.20182136,0.2693365 , -0.05218098, 0.02333841, 0.08451191, -0.02421036,0.17832932, -0.04388756, 0.29842207, 0.04996797, 0.21740773,-0.00870329, 0.08936617, -0.10373649, -0.12448472, 0.0588907 ,0.18343005, 0.1960747 , 0.2588921 , 0.19400522, 0.21396032],[-0.3160454 , 0.4080445 , 0.26255247, 0.27086523, -0.09026864,-0.0124262 , -0.16098952, -0.38160753, -0.13196355, -0.20225649,-0.12518492, 0.3570473 , 0.06296387, 0.10744056, -0.37734276,0.04127458, -0.25249505, 0.32583037, -0.15164885, -0.321797 ,0.3949028 , 0.10671434, -0.30817616, -0.24316958, -0.04385281,-0.29339156, 0.36301878, 0.04189736, -0.24018642, 0.39192936],[ 0.25731334, -0.31793687, -0.29365364, 0.24058959, -0.28362244,0.33795986, -0.19459574, 0.3009247 , 0.04505309, 0.12755081,-0.29095498, -0.34372756, 0.31210646, 0.17511132, -0.11675891,0.29953584, 0.352039 , 0.28779158, 0.40831617, -0.23186448,-0.06609696, 0.36298928, -0.28264546, 0.21196845, 0.40569887,-0.33992565, 0.13081315, 0.30123344, -0.22727355, 0.29445478]],dtype=float32)>,<tf.Variable 'dense_2/bias:0' shape=(30,) dtype=float32, numpy=array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)>]
自定义layer
要创建自定义层,最常见的方法是继承 tf.keras.layers.Layer 并重写其构造函数 init 和前向传播方法 call。此外,还可以选择性地覆盖其他方法如 build 来初始化权重。
继承 tf.keras.layers.Layer 类
# 自定义layer
class CustomizedDenseLayer(keras.layers.Layer):def __init__(self, units, activation=None, **kwargs):self.units = unitsself.activation = keras.layers.Activation(activation)super().__init__(**kwargs)def build(self, input_shape):"""构建所需要的参数"""# None, 8 @ w + b# w * x + bself.kernel = self.add_weight(name='kernel',shape=(input_shape[1], self.units),initializer='uniform',trainable=True)self.bias = self.add_weight(name='bias',shape=(self.units,),initializer='zeros',trainable=True)super().build(input_shape)def call(self, x):"""完成正向传播"""return self.activation(x @ self.kernel + self.bias)
添加额外组件(可选)
- 正则化:通过添加正则项到权重中。
- 约束:限制权重值范围。
- 活动规则:修改输出激活函数。
通过lambda函数快速自定义层次
# 通过lambda函数快速自定义层次
# softplus : log(1 + e^x)
customized_softplus = keras.layers.Lambda(lambda x: tf.nn.softplus(x))
customized_softplus
<tensorflow.python.keras.layers.core.Lambda at 0x2328e7f8c18>
customized_softplus([-10., -5., 0., 5., 10.])
<IPython.core.display.Javascript object><tf.Tensor: shape=(5,), dtype=float32, numpy=
array([4.5398901e-05, 6.7153485e-03, 6.9314718e-01, 5.0067153e+00,1.0000046e+01], dtype=float32)>
定义网络
# 定义网络
model = keras.models.Sequential([# input_dim, input_shape一定要是元组# input_shape=(None, 8)# input_shape=(8,)CustomizedDenseLayer(32, input_shape=x_train.shape[1:]),customized_softplus,CustomizedDenseLayer(1)
])
<IPython.core.display.Javascript object>
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
customized_dense_layer_4 (Cu (None, 32) 288
_________________________________________________________________
lambda_1 (Lambda) (None, 32) 0
_________________________________________________________________
customized_dense_layer_5 (Cu (None, 1) 33
=================================================================
Total params: 321
Trainable params: 321
Non-trainable params: 0
_________________________________________________________________
# 配置
model.compile(loss='mean_squared_error', optimizer='sgd', metrics=['mse'])
训练
callbacks = []
history = model.fit(x_train_scaled, y_train, validation_data=(x_valid_scaled, y_valid), epochs=20)
Epoch 1/20<IPython.core.display.Javascript object><IPython.core.display.Javascript object>350/363 [===========================>..] - ETA: 0s - loss: 1.2791 - mse: 1.2791<IPython.core.display.Javascript object>363/363 [==============================] - 2s 4ms/step - loss: 1.2673 - mse: 1.2673 - val_loss: 0.7043 - val_mse: 0.7043
Epoch 2/20
363/363 [==============================] - 1s 4ms/step - loss: 0.6510 - mse: 0.6510 - val_loss: 0.6510 - val_mse: 0.6510
Epoch 3/20
363/363 [==============================] - 1s 4ms/step - loss: 0.6131 - mse: 0.6131 - val_loss: 0.6092 - val_mse: 0.6092
Epoch 4/20
363/363 [==============================] - 1s 4ms/step - loss: 0.5730 - mse: 0.5730 - val_loss: 0.5904 - val_mse: 0.5904
Epoch 5/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5294 - mse: 0.5294 - val_loss: 0.5561 - val_mse: 0.5561
Epoch 6/20
363/363 [==============================] - 1s 4ms/step - loss: 0.5145 - mse: 0.5145 - val_loss: 0.5378 - val_mse: 0.5378
Epoch 7/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4971 - mse: 0.4971 - val_loss: 0.5231 - val_mse: 0.5231
Epoch 8/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5064 - mse: 0.5064 - val_loss: 0.5272 - val_mse: 0.5272
Epoch 9/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4624 - mse: 0.4624 - val_loss: 0.5067 - val_mse: 0.5067
Epoch 10/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4624 - mse: 0.4624 - val_loss: 0.5030 - val_mse: 0.5030
Epoch 11/20
363/363 [==============================] - 1s 3ms/step - loss: 0.5018 - mse: 0.5018 - val_loss: 0.4983 - val_mse: 0.4983
Epoch 12/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4564 - mse: 0.4564 - val_loss: 0.4923 - val_mse: 0.4923
Epoch 13/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4613 - mse: 0.4613 - val_loss: 0.5055 - val_mse: 0.5055
Epoch 14/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4590 - mse: 0.4590 - val_loss: 0.4999 - val_mse: 0.4999
Epoch 15/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4699 - mse: 0.4699 - val_loss: 0.4855 - val_mse: 0.4855
Epoch 16/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4379 - mse: 0.4379 - val_loss: 0.4893 - val_mse: 0.4893
Epoch 17/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4561 - mse: 0.4561 - val_loss: 0.4775 - val_mse: 0.4775
Epoch 18/20
363/363 [==============================] - 1s 4ms/step - loss: 0.4494 - mse: 0.4494 - val_loss: 0.4770 - val_mse: 0.4770
Epoch 19/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4420 - mse: 0.4420 - val_loss: 0.4730 - val_mse: 0.4730
Epoch 20/20
363/363 [==============================] - 1s 3ms/step - loss: 0.4546 - mse: 0.4546 - val_loss: 0.4726 - val_mse: 0.4726
history.history
{'loss': [0.9686319231987,0.6334629654884338,0.5910705327987671,0.5548492670059204,0.5311656594276428,0.511313796043396,0.4988256096839905,0.4868493676185608,0.48182985186576843,0.4747821092605591,0.4697805345058441,0.4665999114513397,0.46402427554130554,0.460597962141037,0.45706820487976074,0.45521169900894165,0.4531698226928711,0.4520145654678345,0.4498659670352936,0.44859832525253296],'mse': [0.9686319231987,0.6334629654884338,0.5910705327987671,0.5548492670059204,0.5311656594276428,0.511313796043396,0.4988256096839905,0.4868493676185608,0.48182985186576843,0.4747821092605591,0.4697805345058441,0.4665999114513397,0.46402427554130554,0.460597962141037,0.45706820487976074,0.45521169900894165,0.4531698226928711,0.4520145654678345,0.4498659670352936,0.44859832525253296],'val_loss': [0.7043035626411438,0.650953471660614,0.6091620326042175,0.5904147028923035,0.5560877919197083,0.537843644618988,0.5231175422668457,0.5271777510643005,0.5067079663276672,0.5030060410499573,0.4983442723751068,0.492310494184494,0.5055224895477295,0.49990448355674744,0.4855071008205414,0.48930567502975464,0.4775150418281555,0.47700804471969604,0.4729941189289093,0.47260627150535583],'val_mse': [0.7043035626411438,0.650953471660614,0.6091620326042175,0.5904147028923035,0.5560877919197083,0.537843644618988,0.5231175422668457,0.5271777510643005,0.5067079663276672,0.5030060410499573,0.4983442723751068,0.492310494184494,0.5055224895477295,0.49990448355674744,0.4855071008205414,0.48930567502975464,0.4775150418281555,0.47700804471969604,0.4729941189289093,0.47260627150535583]}
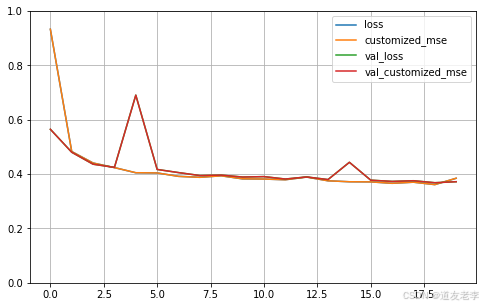
可视化
# 定义画图的函数
def plot_learning_curves(history):pandas.DataFrame(history.history).plot(figsize=(8, 5))plt.grid(True)plt.gca().set_ylim(0, 1)plt.show()
plot_learning_curves(history)