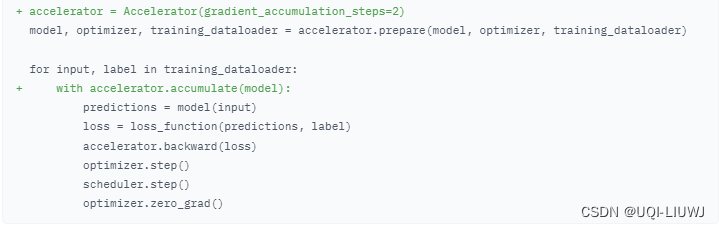
1 介绍
- PyTorch 的分布式模块通过在系统中所有GPU之间进行来回通信来操作。
- 这种通信需要时间,并且确保所有进程了解彼此的状态
- 在使用ddp模块时会在特定的触发点发生
- 这些触发点被添加到PyTorch模型中,特别是它们的 forward() 和 backward() 方法中
- 当通过 optimizer.step() 更新模型参数时。如果不进行梯度累积,所有模型实例需要更新它们计算、汇总和更新的梯度,然后才能继续到下一批数据。
- 这种无谓的进程间通信可能会导致显著的减速
- 进行梯度累积时,会累积 n 个损失梯度并跳过 optimizer.step(),直到达到 n 批次
- 如果不注意梯度同步和GPU通信,当这些GPU在不必要的时期相互通信时,可能会浪费大量时间。
1.1直观感受一下速度的差异
先直观看一下不进行任何改进的话,每个batch都进行通信,会是什么样的速度:
考虑以下设置:
- 两个单GPU节点、一个有两个GPU的节点
- 每个GPU都是T4,并托管在GCP上
- 每个GPU的批次大小为16,梯度每4步累积一次
比较的内容:
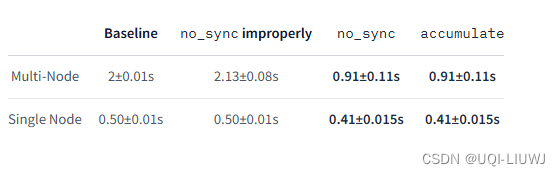
- 基线:没有使用任何同步实践【同步实践后面会说】
- no_sync使用不当:只在backward调用时使用no_sync,而不是在forward
- 正确使用no_sync:正确使用no_sync模式
- 使用accumulate:正确使用accumulate()
以下是每种设置在单节点和双节点设置上迭代29批数据的平均秒数:
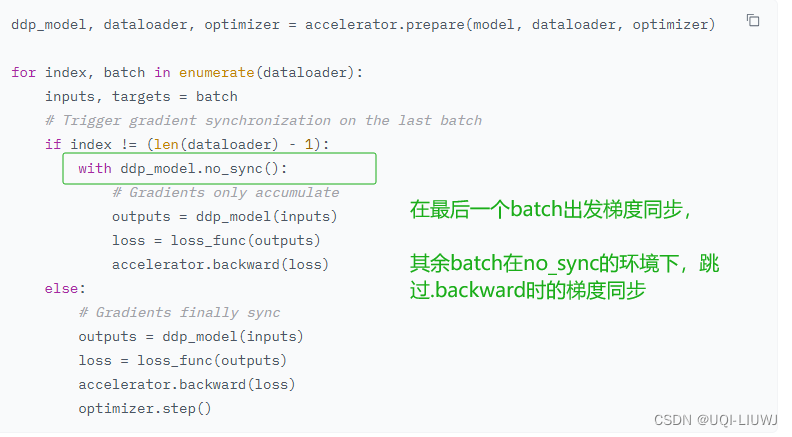
2 解决方法1:no_sync
- 通过 no_sync 上下文管理器
- 在此上下文管理器下,PyTorch 将跳过在调用 .backward() 时同步梯度
- 此上下文管理器外的第一次调用 .backward() 将触发同步
另一种写法是:
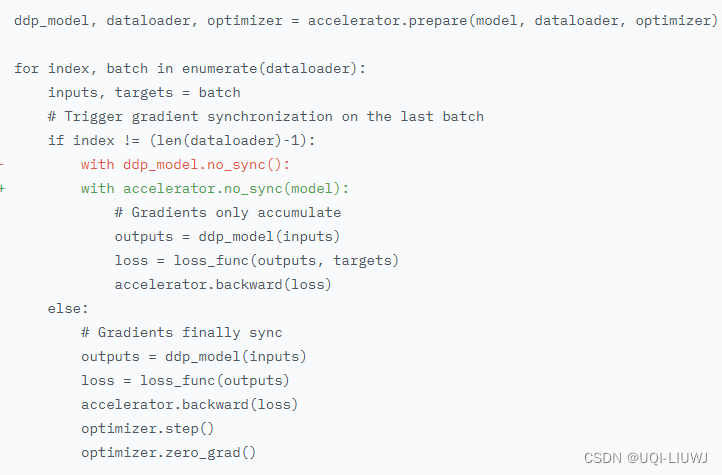
3 解决方法2:accumulate 梯度累计