知识点回顾:
- 随机种子
- 内参的初始化
- 神经网络调参指南
- 参数的分类
- 调参的顺序
- 各部分参数的调整心得
作业:对于day41的简单cnn,看看是否可以借助调参指南进一步提高精度。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import os
import random# 设置随机种子
def set_seed(seed=42, deterministic=True):"""设置全局随机种子,确保实验可重复性"""random.seed(seed)os.environ['PYTHONHASHSEED'] = str(seed)np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)if deterministic:torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = False# 设置随机种子
set_seed(42)# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 随机裁剪图像,从原图中随机截取32x32大小的区域transforms.RandomCrop(32, padding=4),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 测试集进行标准化
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform # 使用增强后的预处理
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)# 初始化权重self._initialize_weights()def _initialize_weights(self):"""初始化模型权重"""for m in self.modules():if isinstance(m, nn.Conv2d):# 使用Kaiming初始化(适合ReLU激活函数)nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):# 批量归一化参数初始化nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):# 全连接层权重初始化nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 查看模型参数和权重初始化情况
def print_model_summary(model):"""打印模型结构和参数统计"""print("模型结构:")print(model)# 打印参数统计total_params = sum(p.numel() for p in model.parameters())trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f"\n总参数数量: {total_params:,}")print(f"可训练参数数量: {trainable_params:,}")# 打印各层权重统计print("\n权重初始化统计:")for name, param in model.named_parameters():if param.requires_grad:print(f"{name}: 形状={param.shape}, 均值={param.mean().item():.6f}, 标准差={param.std().item():.6f}")# 可视化权重分布
def visualize_weights(model, save_path=None):"""可视化模型权重分布"""# 获取所有卷积层和全连接层conv_layers = [m for m in model.modules() if isinstance(m, nn.Conv2d)]fc_layers = [m for m in model.modules() if isinstance(m, nn.Linear)]# 计算总共需要的子图数量total_layers = len(conv_layers) + len(fc_layers)# 设置图形大小,根据层数动态调整fig_height = min(15, 5 * total_layers) # 最大高度限制为15英寸plt.figure(figsize=(15, fig_height))# 遍历所有层并创建子图layer_idx = 1for i, conv in enumerate(conv_layers):# 权重分布直方图plt.subplot(total_layers, 2, 2*layer_idx-1)weights = conv.weight.data.flatten().cpu().numpy()plt.hist(weights, bins=50)plt.title(f'{conv.__class__.__name__} 权重分布')# 权重热图plt.subplot(total_layers, 2, 2*layer_idx)n = len(weights)side = int(np.sqrt(n))# 如果不能完美整除,添加零填充使能重塑if n % side != 0:new_size = side * (side + 1)if new_size < n:side += 1new_size = side * sideweights_padded = np.zeros(new_size)weights_padded[:n] = weightsweights = weights_paddedplt.imshow(weights.reshape(side, -1), cmap='viridis')plt.colorbar()plt.title(f'{conv.__class__.__name__} 权重热图')layer_idx += 1for i, fc in enumerate(fc_layers):# 权重分布直方图plt.subplot(total_layers, 2, 2*layer_idx-1)weights = fc.weight.data.flatten().cpu().numpy()plt.hist(weights, bins=50)plt.title(f'{fc.__class__.__name__} 权重分布')# 权重热图plt.subplot(total_layers, 2, 2*layer_idx)n = len(weights)side = int(np.sqrt(n))# 如果不能完美整除,添加零填充使能重塑if n % side != 0:new_size = side * (side + 1)if new_size < n:side += 1new_size = side * sideweights_padded = np.zeros(new_size)weights_padded[:n] = weightsweights = weights_paddedplt.imshow(weights.reshape(side, -1), cmap='viridis')plt.colorbar()plt.title(f'{fc.__class__.__name__} 权重热图')layer_idx += 1plt.tight_layout()if save_path:plt.savefig(save_path)plt.show()# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)# 打印模型摘要和权重统计
print_model_summary(model)# 可视化权重分布
visualize_weights(model, "initial_weights.png")criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号# 记录每个 epoch 的准确率和损失train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 绘制每个 epoch 的准确率和损失曲线plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))# 绘制准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)# 绘制损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始使用CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
使用设备: cuda
Files already downloaded and verified
模型结构:
CNN((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu2): ReLU()(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu3): ReLU()(pool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(fc1): Linear(in_features=2048, out_features=512, bias=True)(dropout): Dropout(p=0.5, inplace=False)(fc2): Linear(in_features=512, out_features=10, bias=True)
)总参数数量: 1,147,914
可训练参数数量: 1,147,914权重初始化统计:
conv1.weight: 形状=torch.Size([32, 3, 3, 3]), 均值=-0.002415, 标准差=0.083342
conv1.bias: 形状=torch.Size([32]), 均值=0.000000, 标准差=0.000000
bn1.weight: 形状=torch.Size([32]), 均值=1.000000, 标准差=0.000000
bn1.bias: 形状=torch.Size([32]), 均值=0.000000, 标准差=0.000000
conv2.weight: 形状=torch.Size([64, 32, 3, 3]), 均值=0.000156, 标准差=0.059072
conv2.bias: 形状=torch.Size([64]), 均值=0.000000, 标准差=0.000000
bn2.weight: 形状=torch.Size([64]), 均值=1.000000, 标准差=0.000000
bn2.bias: 形状=torch.Size([64]), 均值=0.000000, 标准差=0.000000
conv3.weight: 形状=torch.Size([128, 64, 3, 3]), 均值=0.000043, 标准差=0.041678
conv3.bias: 形状=torch.Size([128]), 均值=0.000000, 标准差=0.000000
bn3.weight: 形状=torch.Size([128]), 均值=1.000000, 标准差=0.000000
bn3.bias: 形状=torch.Size([128]), 均值=0.000000, 标准差=0.000000
fc1.weight: 形状=torch.Size([512, 2048]), 均值=0.000004, 标准差=0.010003
fc1.bias: 形状=torch.Size([512]), 均值=0.000000, 标准差=0.000000
fc2.weight: 形状=torch.Size([10, 512]), 均值=-0.000053, 标准差=0.009953
fc2.bias: 形状=torch.Size([10]), 均值=0.000000, 标准差=0.000000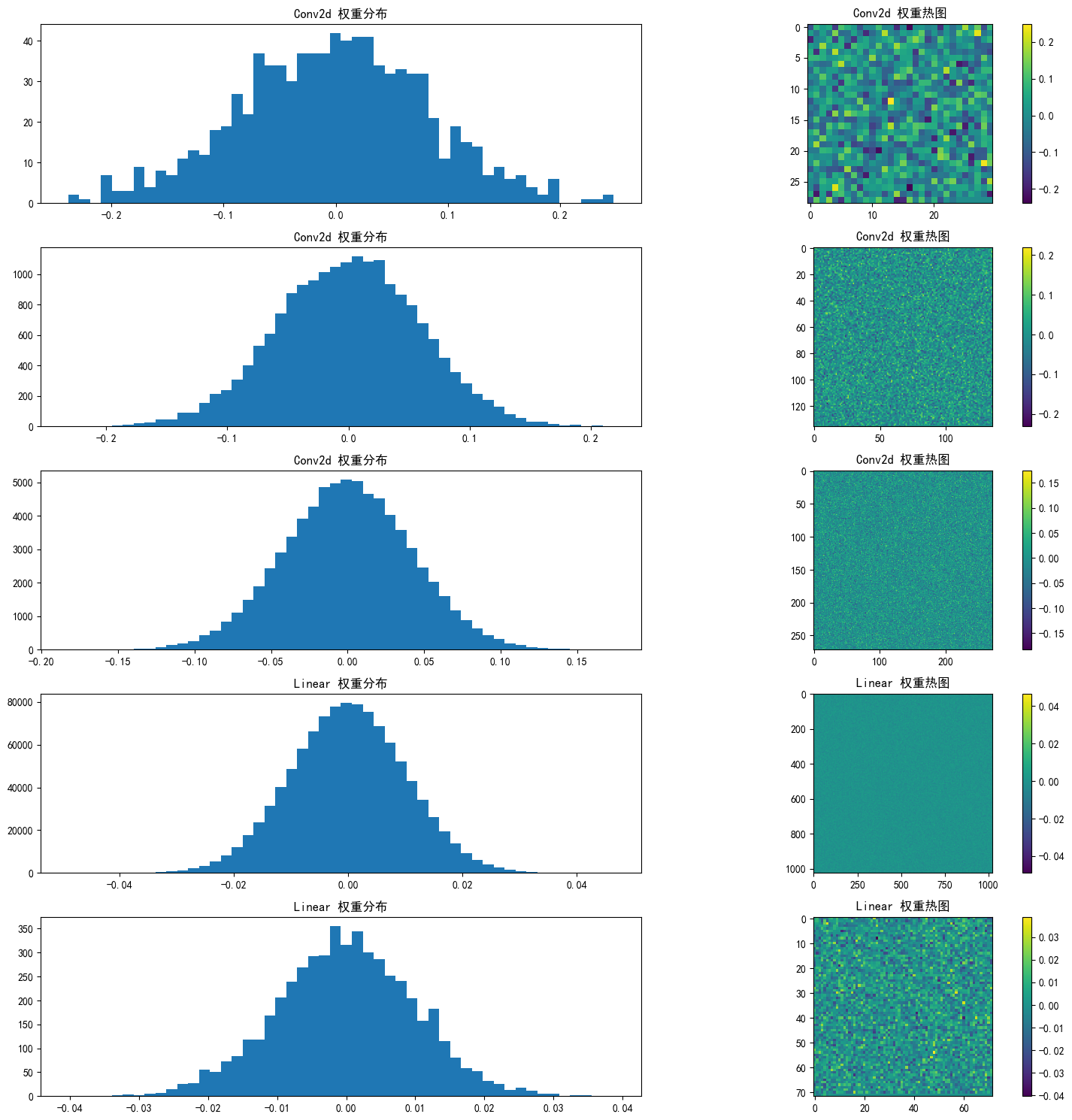
开始使用CNN训练模型...
Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.8162 | 累计平均损失: 1.9758
Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 1.6490 | 累计平均损失: 1.8679
Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.5797 | 累计平均损失: 1.8007
Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.6934 | 累计平均损失: 1.7529
Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 1.6073 | 累计平均损失: 1.7149
Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.4690 | 累计平均损失: 1.6867
Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 1.4577 | 累计平均损失: 1.6629
Epoch 1/20 完成 | 训练准确率: 39.14% | 测试准确率: 49.44%
Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 1.3756 | 累计平均损失: 1.4135
Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 1.2840 | 累计平均损失: 1.3768
Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 1.2561 | 累计平均损失: 1.3551
Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 1.1801 | 累计平均损失: 1.3301
Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 1.2188 | 累计平均损失: 1.3113
Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 1.0969 | 累计平均损失: 1.2908
Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 1.1654 | 累计平均损失: 1.2769
Epoch 2/20 完成 | 训练准确率: 54.19% | 测试准确率: 63.99%
Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 1.1490 | 累计平均损失: 1.1420
Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 0.8593 | 累计平均损失: 1.1307
Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 1.1695 | 累计平均损失: 1.1087
Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 1.0301 | 累计平均损失: 1.1032
Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 0.9763 | 累计平均损失: 1.0932
Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 1.3007 | 累计平均损失: 1.0879
Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 1.0772 | 累计平均损失: 1.0782
Epoch 3/20 完成 | 训练准确率: 61.94% | 测试准确率: 67.00%
Epoch: 4/20 | Batch: 100/782 | 单Batch损失: 1.0564 | 累计平均损失: 1.0408
Epoch: 4/20 | Batch: 200/782 | 单Batch损失: 1.1284 | 累计平均损失: 1.0211
Epoch: 4/20 | Batch: 300/782 | 单Batch损失: 1.0225 | 累计平均损失: 1.0077
Epoch: 4/20 | Batch: 400/782 | 单Batch损失: 1.1155 | 累计平均损失: 1.0046
Epoch: 4/20 | Batch: 500/782 | 单Batch损失: 0.8628 | 累计平均损失: 0.9997
Epoch: 4/20 | Batch: 600/782 | 单Batch损失: 0.7647 | 累计平均损失: 0.9921
Epoch: 4/20 | Batch: 700/782 | 单Batch损失: 0.9006 | 累计平均损失: 0.9855
Epoch 4/20 完成 | 训练准确率: 65.28% | 测试准确率: 71.70%
Epoch: 5/20 | Batch: 100/782 | 单Batch损失: 0.8740 | 累计平均损失: 0.9175
Epoch: 5/20 | Batch: 200/782 | 单Batch损失: 0.9027 | 累计平均损失: 0.9190
Epoch: 5/20 | Batch: 300/782 | 单Batch损失: 0.7604 | 累计平均损失: 0.9232
Epoch: 5/20 | Batch: 400/782 | 单Batch损失: 0.7810 | 累计平均损失: 0.9290
Epoch: 5/20 | Batch: 500/782 | 单Batch损失: 1.1292 | 累计平均损失: 0.9206
Epoch: 5/20 | Batch: 600/782 | 单Batch损失: 0.8289 | 累计平均损失: 0.9188
Epoch: 5/20 | Batch: 700/782 | 单Batch损失: 0.9832 | 累计平均损失: 0.9172
Epoch 5/20 完成 | 训练准确率: 67.94% | 测试准确率: 74.05%
Epoch: 6/20 | Batch: 100/782 | 单Batch损失: 0.9124 | 累计平均损失: 0.8894
Epoch: 6/20 | Batch: 200/782 | 单Batch损失: 0.7619 | 累计平均损失: 0.8787
Epoch: 6/20 | Batch: 300/782 | 单Batch损失: 0.8946 | 累计平均损失: 0.8795
Epoch: 6/20 | Batch: 400/782 | 单Batch损失: 0.8688 | 累计平均损失: 0.8838
Epoch: 6/20 | Batch: 500/782 | 单Batch损失: 0.9621 | 累计平均损失: 0.8799
Epoch: 6/20 | Batch: 600/782 | 单Batch损失: 0.7851 | 累计平均损失: 0.8745
Epoch: 6/20 | Batch: 700/782 | 单Batch损失: 0.6696 | 累计平均损失: 0.8710
Epoch 6/20 完成 | 训练准确率: 69.30% | 测试准确率: 75.26%
Epoch: 7/20 | Batch: 100/782 | 单Batch损失: 0.9662 | 累计平均损失: 0.8486
Epoch: 7/20 | Batch: 200/782 | 单Batch损失: 0.8045 | 累计平均损失: 0.8361
Epoch: 7/20 | Batch: 300/782 | 单Batch损失: 0.9796 | 累计平均损失: 0.8404
Epoch: 7/20 | Batch: 400/782 | 单Batch损失: 0.8340 | 累计平均损失: 0.8389
Epoch: 7/20 | Batch: 500/782 | 单Batch损失: 0.8260 | 累计平均损失: 0.8415
Epoch: 7/20 | Batch: 600/782 | 单Batch损失: 0.9148 | 累计平均损失: 0.8390
Epoch: 7/20 | Batch: 700/782 | 单Batch损失: 0.6942 | 累计平均损失: 0.8348
Epoch 7/20 完成 | 训练准确率: 70.68% | 测试准确率: 74.51%
Epoch: 8/20 | Batch: 100/782 | 单Batch损失: 0.5026 | 累计平均损失: 0.8051
Epoch: 8/20 | Batch: 200/782 | 单Batch损失: 0.6307 | 累计平均损失: 0.8059
Epoch: 8/20 | Batch: 300/782 | 单Batch损失: 0.5882 | 累计平均损失: 0.7966
Epoch: 8/20 | Batch: 400/782 | 单Batch损失: 0.9657 | 累计平均损失: 0.7997
Epoch: 8/20 | Batch: 500/782 | 单Batch损失: 0.7939 | 累计平均损失: 0.7991
Epoch: 8/20 | Batch: 600/782 | 单Batch损失: 0.8021 | 累计平均损失: 0.7966
Epoch: 8/20 | Batch: 700/782 | 单Batch损失: 0.9676 | 累计平均损失: 0.7957
Epoch 8/20 完成 | 训练准确率: 72.17% | 测试准确率: 76.53%
Epoch: 9/20 | Batch: 100/782 | 单Batch损失: 0.6977 | 累计平均损失: 0.7637
Epoch: 9/20 | Batch: 200/782 | 单Batch损失: 0.6645 | 累计平均损失: 0.7666
Epoch: 9/20 | Batch: 300/782 | 单Batch损失: 0.9691 | 累计平均损失: 0.7722
Epoch: 9/20 | Batch: 400/782 | 单Batch损失: 0.8165 | 累计平均损失: 0.7734
Epoch: 9/20 | Batch: 500/782 | 单Batch损失: 0.8008 | 累计平均损失: 0.7737
Epoch: 9/20 | Batch: 600/782 | 单Batch损失: 0.6249 | 累计平均损失: 0.7736
Epoch: 9/20 | Batch: 700/782 | 单Batch损失: 0.7685 | 累计平均损失: 0.7730
Epoch 9/20 完成 | 训练准确率: 72.91% | 测试准确率: 76.65%
Epoch: 10/20 | Batch: 100/782 | 单Batch损失: 0.7310 | 累计平均损失: 0.7588
Epoch: 10/20 | Batch: 200/782 | 单Batch损失: 0.8178 | 累计平均损失: 0.7646
Epoch: 10/20 | Batch: 300/782 | 单Batch损失: 0.6414 | 累计平均损失: 0.7621
Epoch: 10/20 | Batch: 400/782 | 单Batch损失: 0.6683 | 累计平均损失: 0.7620
Epoch: 10/20 | Batch: 500/782 | 单Batch损失: 0.6209 | 累计平均损失: 0.7595
Epoch: 10/20 | Batch: 600/782 | 单Batch损失: 0.5887 | 累计平均损失: 0.7583
Epoch: 10/20 | Batch: 700/782 | 单Batch损失: 0.4939 | 累计平均损失: 0.7576
Epoch 10/20 完成 | 训练准确率: 73.22% | 测试准确率: 76.70%
Epoch: 11/20 | Batch: 100/782 | 单Batch损失: 0.7068 | 累计平均损失: 0.7181
Epoch: 11/20 | Batch: 200/782 | 单Batch损失: 0.9008 | 累计平均损失: 0.7324
Epoch: 11/20 | Batch: 300/782 | 单Batch损失: 0.6470 | 累计平均损失: 0.7302
Epoch: 11/20 | Batch: 400/782 | 单Batch损失: 0.7137 | 累计平均损失: 0.7310
Epoch: 11/20 | Batch: 500/782 | 单Batch损失: 0.7769 | 累计平均损失: 0.7368
Epoch: 11/20 | Batch: 600/782 | 单Batch损失: 0.5939 | 累计平均损失: 0.7398
Epoch: 11/20 | Batch: 700/782 | 单Batch损失: 0.7608 | 累计平均损失: 0.7373
Epoch 11/20 完成 | 训练准确率: 74.10% | 测试准确率: 77.57%
Epoch: 12/20 | Batch: 100/782 | 单Batch损失: 0.7336 | 累计平均损失: 0.7193
Epoch: 12/20 | Batch: 200/782 | 单Batch损失: 0.7847 | 累计平均损失: 0.7234
Epoch: 12/20 | Batch: 300/782 | 单Batch损失: 0.6507 | 累计平均损失: 0.7258
Epoch: 12/20 | Batch: 400/782 | 单Batch损失: 0.8989 | 累计平均损失: 0.7211
Epoch: 12/20 | Batch: 500/782 | 单Batch损失: 0.9421 | 累计平均损失: 0.7282
Epoch: 12/20 | Batch: 600/782 | 单Batch损失: 0.7559 | 累计平均损失: 0.7241
Epoch: 12/20 | Batch: 700/782 | 单Batch损失: 0.7424 | 累计平均损失: 0.7247
Epoch 12/20 完成 | 训练准确率: 74.93% | 测试准确率: 76.88%
Epoch: 13/20 | Batch: 100/782 | 单Batch损失: 0.7262 | 累计平均损失: 0.6855
Epoch: 13/20 | Batch: 200/782 | 单Batch损失: 0.9355 | 累计平均损失: 0.6993
Epoch: 13/20 | Batch: 300/782 | 单Batch损失: 0.6589 | 累计平均损失: 0.7058
Epoch: 13/20 | Batch: 400/782 | 单Batch损失: 0.7592 | 累计平均损失: 0.7042
Epoch: 13/20 | Batch: 500/782 | 单Batch损失: 0.7651 | 累计平均损失: 0.7008
Epoch: 13/20 | Batch: 600/782 | 单Batch损失: 0.4891 | 累计平均损失: 0.7007
Epoch: 13/20 | Batch: 700/782 | 单Batch损失: 0.6534 | 累计平均损失: 0.7030
Epoch 13/20 完成 | 训练准确率: 75.20% | 测试准确率: 78.37%
Epoch: 14/20 | Batch: 100/782 | 单Batch损失: 0.4732 | 累计平均损失: 0.6872
Epoch: 14/20 | Batch: 200/782 | 单Batch损失: 0.7734 | 累计平均损失: 0.6868
Epoch: 14/20 | Batch: 300/782 | 单Batch损失: 0.5929 | 累计平均损失: 0.6815
Epoch: 14/20 | Batch: 400/782 | 单Batch损失: 0.6299 | 累计平均损失: 0.6807
Epoch: 14/20 | Batch: 500/782 | 单Batch损失: 0.4751 | 累计平均损失: 0.6868
Epoch: 14/20 | Batch: 600/782 | 单Batch损失: 0.6173 | 累计平均损失: 0.6889
Epoch: 14/20 | Batch: 700/782 | 单Batch损失: 0.6702 | 累计平均损失: 0.6896
Epoch 14/20 完成 | 训练准确率: 75.80% | 测试准确率: 79.82%
Epoch: 15/20 | Batch: 100/782 | 单Batch损失: 0.9308 | 累计平均损失: 0.6779
Epoch: 15/20 | Batch: 200/782 | 单Batch损失: 0.8000 | 累计平均损失: 0.6732
Epoch: 15/20 | Batch: 300/782 | 单Batch损失: 0.6398 | 累计平均损失: 0.6766
Epoch: 15/20 | Batch: 400/782 | 单Batch损失: 0.5607 | 累计平均损失: 0.6811
Epoch: 15/20 | Batch: 500/782 | 单Batch损失: 0.8946 | 累计平均损失: 0.6828
Epoch: 15/20 | Batch: 600/782 | 单Batch损失: 0.8959 | 累计平均损失: 0.6833
Epoch: 15/20 | Batch: 700/782 | 单Batch损失: 0.6729 | 累计平均损失: 0.6855
Epoch 15/20 完成 | 训练准确率: 75.89% | 测试准确率: 80.02%
Epoch: 16/20 | Batch: 100/782 | 单Batch损失: 0.5656 | 累计平均损失: 0.6533
Epoch: 16/20 | Batch: 200/782 | 单Batch损失: 0.6207 | 累计平均损失: 0.6534
Epoch: 16/20 | Batch: 300/782 | 单Batch损失: 0.8071 | 累计平均损失: 0.6530
Epoch: 16/20 | Batch: 400/782 | 单Batch损失: 0.7246 | 累计平均损失: 0.6562
Epoch: 16/20 | Batch: 500/782 | 单Batch损失: 0.9227 | 累计平均损失: 0.6639
Epoch: 16/20 | Batch: 600/782 | 单Batch损失: 0.7183 | 累计平均损失: 0.6662
Epoch: 16/20 | Batch: 700/782 | 单Batch损失: 0.7518 | 累计平均损失: 0.6651
Epoch 16/20 完成 | 训练准确率: 76.70% | 测试准确率: 80.15%
Epoch: 17/20 | Batch: 100/782 | 单Batch损失: 0.6151 | 累计平均损失: 0.6365
Epoch: 17/20 | Batch: 200/782 | 单Batch损失: 0.5609 | 累计平均损失: 0.6436
Epoch: 17/20 | Batch: 300/782 | 单Batch损失: 0.6423 | 累计平均损失: 0.6537
Epoch: 17/20 | Batch: 400/782 | 单Batch损失: 0.8539 | 累计平均损失: 0.6556
Epoch: 17/20 | Batch: 500/782 | 单Batch损失: 0.6525 | 累计平均损失: 0.6566
Epoch: 17/20 | Batch: 600/782 | 单Batch损失: 0.6431 | 累计平均损失: 0.6589
Epoch: 17/20 | Batch: 700/782 | 单Batch损失: 0.6822 | 累计平均损失: 0.6617
Epoch 17/20 完成 | 训练准确率: 76.96% | 测试准确率: 80.77%
Epoch: 18/20 | Batch: 100/782 | 单Batch损失: 0.8017 | 累计平均损失: 0.6452
Epoch: 18/20 | Batch: 200/782 | 单Batch损失: 0.5719 | 累计平均损失: 0.6489
Epoch: 18/20 | Batch: 300/782 | 单Batch损失: 0.7306 | 累计平均损失: 0.6522
Epoch: 18/20 | Batch: 400/782 | 单Batch损失: 0.5835 | 累计平均损失: 0.6473
Epoch: 18/20 | Batch: 500/782 | 单Batch损失: 0.4232 | 累计平均损失: 0.6511
Epoch: 18/20 | Batch: 600/782 | 单Batch损失: 0.5977 | 累计平均损失: 0.6478
Epoch: 18/20 | Batch: 700/782 | 单Batch损失: 0.7233 | 累计平均损失: 0.6478
Epoch 18/20 完成 | 训练准确率: 77.39% | 测试准确率: 80.26%
Epoch: 19/20 | Batch: 100/782 | 单Batch损失: 0.8074 | 累计平均损失: 0.6337
Epoch: 19/20 | Batch: 200/782 | 单Batch损失: 0.7008 | 累计平均损失: 0.6229
Epoch: 19/20 | Batch: 300/782 | 单Batch损失: 0.7300 | 累计平均损失: 0.6263
Epoch: 19/20 | Batch: 400/782 | 单Batch损失: 0.6363 | 累计平均损失: 0.6329
Epoch: 19/20 | Batch: 500/782 | 单Batch损失: 0.6353 | 累计平均损失: 0.6304
Epoch: 19/20 | Batch: 600/782 | 单Batch损失: 0.5567 | 累计平均损失: 0.6311
Epoch: 19/20 | Batch: 700/782 | 单Batch损失: 0.6145 | 累计平均损失: 0.6329
Epoch 19/20 完成 | 训练准确率: 77.80% | 测试准确率: 81.21%
Epoch: 20/20 | Batch: 100/782 | 单Batch损失: 0.4181 | 累计平均损失: 0.6422
Epoch: 20/20 | Batch: 200/782 | 单Batch损失: 0.3887 | 累计平均损失: 0.6341
Epoch: 20/20 | Batch: 300/782 | 单Batch损失: 0.4621 | 累计平均损失: 0.6364
Epoch: 20/20 | Batch: 400/782 | 单Batch损失: 0.5439 | 累计平均损失: 0.6291
Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.4895 | 累计平均损失: 0.6233
Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.6241 | 累计平均损失: 0.6285
Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.8962 | 累计平均损失: 0.6287
Epoch 20/20 完成 | 训练准确率: 78.18% | 测试准确率: 81.16%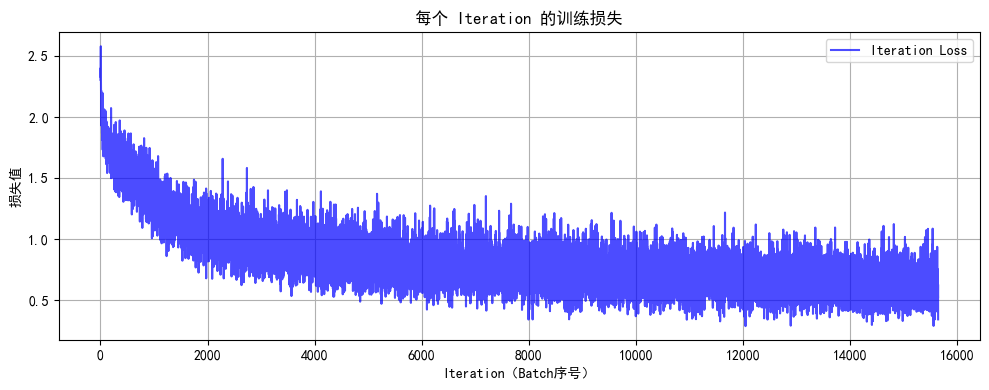
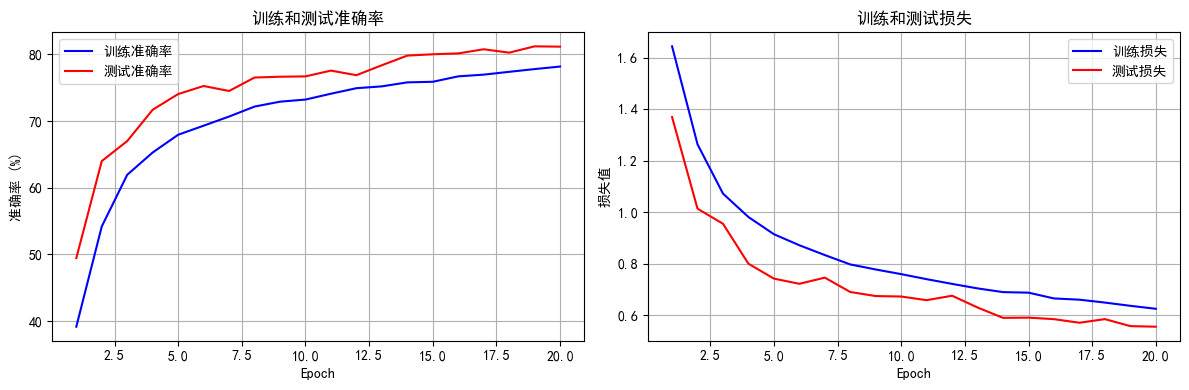
训练完成!最终测试准确率: 81.16%
@浙大疏锦行


)



