ASR
Automatic Speech Recognition,语音转文本。
技术难点:
- 声学多样性
- 口音、方言、语速、背景噪声会影响识别准确性;
- 多人对话场景(如会议录音)需要区分说话人并分离语音。
- 语言模型适配
- 专业术语或网络新词需要动态更新模型;
- 上下文理解,如同音词纠错。
- 低资源语言支持:缺乏标注数据的小语种训练难度大。
- 实时性要求:实时转录需平衡延迟与准确率。
SenseVoice
GitHub,Hugging Face,ModelScope
SenseVoice-Small是基于非自回归端到端框架模型,为了指定任务,在语音特征前添加四个嵌入作为输入传递给编码器:
- LID:用于预测音频语种标签;
- SER:用于预测音频情感标签;
- AED:用于预测音频包含的事件标签;
- ITN:用于指定识别输出文本是否进行逆文本正则化。
Sonic
Sonic是一个开源音频处理库,最初由Google开发,主要用于在移动设备上实现高质量的音频播放和语音处理。
特性:
- 低延迟:Sonic设计用于低延迟场景,确保音频播放的实时性;
- 资源优化
- 节省带宽:通过高效的音频编码和解码,减少音频数据的传输量,节省网络带宽;
- 降低功耗:优化的音频处理算法可以降低设备的功耗,延长移动设备的电池寿命。
应用场景:
- 高质量音频播放
- 变速不变调:Sonic允许在不改变音调的情况下调整音频的播放速度,因为改变音调会影响语音的自然度和可理解性。
- 语音处理
- 语音加速:如需要快速回放语音;
- 语音减速:适用于需要仔细听取语音内容的场景,如学习或听力训练;
- 音量调节:提供动态音量调节功能,确保语音在不同设备和环境下都能清晰可听。
下载源码make编译后使用:./sonic -s 2.0 0415.wav 0415out.wavSetting speed to 2.00X
TTS
Text To Speech,文本转语音。
技术难点
- 自然度与情感表达
- 合成语音需避免机械感,需模拟语调、重音、停顿等副语言特征;
- 情感合成需要细粒度控制。
- 多音字与韵律处理
- 文本歧义依赖上下文;
- 韵律生成(如诗歌朗诵的节奏)需符合人类习惯。
- 个性化与音色克隆:定制化音色需少量样本即可模仿,涉及伦理问题。
- 跨语言合成:中英混合文本需无缝切换发音规则。
传统的TTS系统虽然能生成高质量语音,但往往存在控制能力有限、跨语言表现较差、声音风格固定等问题。
Hugging Face维护的TTS-Arena2榜单。
Gemini 2.5
支持多说话人场景,支持24种不同语言,几乎覆盖全球主要语言。提供30种不同的音色选择,从清晰的"Iapetus"到温和的"Vindemiatrix",从活泼的"Puck"到信息丰富的"Charon",每一种音色都有着鲜明的个性特征。
| Zephyr - Bright | Erinome- C/ear | Puck - Upbeat | Algenib- Gravelly | Charon - Informative | Rasalgethi - Informative |
|---|---|---|---|---|---|
| Kore – Firm | Laomedeia-Upbeat | Fenrir - Excitable | Achernar- Soft | Leda - Youthful | Alnilam-Firm |
| Orus – Firm | Schedar-Even | Aoede - Breezy | Gacrux - Mature | Callirrhoe - Easy-going | Pulcherrima-Forward |
| Autonoe- Bright | Achird - Friendly | Enceladus- Breathy | Zubenelgenubi - Casual | lapetus - Clear | Vindemiatrix-Gent/e |
| Umbriel - Easy-going | Sadachbia - Lively | Algieba-Smooth | Sadaltager - Knowledgeable | Despina-Smooth | Sulafat -Warm |
通过自然语言提示,可以精确控制AI的语音表现,维度包括:语调、情感、语速、口音、节奏等。
所有由Gemini 2.5生成的音频都嵌入SynthID水印技术,确保AI生成的内容可以被识别出来。
Dia-1.6B
Nari Labs开发推出,作为一款16亿参数规模的开源TTS模型,Dia不仅能够自然生成对话式语音,还首次在开源TTS模型中大规模引入情感控制、非语言表达合成与音频提示语音克隆等前沿特性,大大拓展语音生成的表现力和应用场景。
初步测试结果显示,Dia-1.6B在自然度、表现力和上下文适应性方面,均优于当前流行的模型如Sesame CSM-1B和ElevenLabs,尤其在复杂、多轮对话生成任务中表现出色。
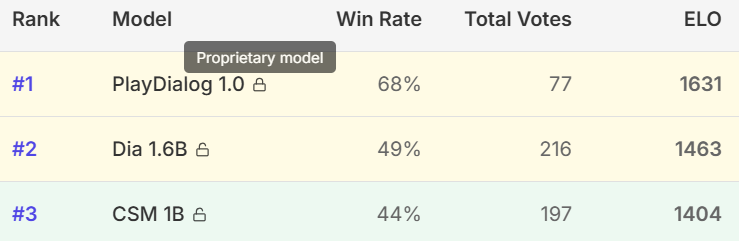
虽然官方尚未公布标准化量化指标,但得益于:
- 更大的模型参数规模;
- 先进的调节机制;
- 独特的非语言线索处理能力
Dia展现出更强的情绪细腻度和上下文理解能力,使得生成的语音作品更加接近真实人声。
核心功能
- 一次性生成完整对话流
不再逐行合成,Dia支持直接输入包含多轮互动的剧本,自动生成自然连贯的对话语音,营造沉浸式体验。 - 多说话人标记支持
通过在文本中添加[S1]、[S2]等说话人标签,可以轻松合成多角色对话,适用于有声读物、广播剧、游戏配音等场景。 - 精准的情感和语气控制
支持通过音频提示引导生成不同情绪的语音风格,实现更细腻的人机交流体验。 - 语音克隆与复制
通过提供参考音频,Dia可以复制特定说话人的声音特性,支持定制化语音合成(需遵循合法授权规范)。 - 自然插入非语言表达
在文本中加入如laughs,coughs等指令,Dia会自动在合成语音中插入自然的非语言声音,提升表现力。
局限:目前仅支持英文语音生成。
计划推出:
- 模型优化版:推理更快,资源占用更低;
- 量化版模型:适配低资源环境,如移动设备。
凭借其自然的对话生成、情感表达和非语言处理能力,Dia的潜在使用场景:
- 自动有声书制作;
- YouTube视频自动配音;
- AI呼叫中心智能响应。
入门示例:
import soundfile as sf
from dia.model import Dia
from IPython.display importAudiomodel = Dia.from_pretrained(
"nari-labs/Dia-1.6B"
)
# 输入文本(支持多说话人和非语言指令)
text = "[S1] Dia is an open weights text to dialogue model (sneezes). [S2] You get full control over scripts and voices. [S1] Wow. Amazing. (laughs) [S2] Try it now on GitHub or Hugging Face."
output = model.generate(text)
sf.write("simple.mp3", output, 44100)
# 播放音频
Audio("simple.mp3")
OpenAudio S1
官网
GitHub
Hugging Face
OpenAudio S1是FishAudio发布的领先的端到端TTS模型,训练数据超过200万小时,覆盖多语言、多场景,性能全面超越市面主流方案。
核心亮点
- 极致准确率:
S1 WER(词错误率):0.008
CER(字符错误率):0.004
支持基于GPT-4o的自动评估 - 多语言支持;
- 情感语音合成支持:超过50+种情绪标签&特殊语气标记
情绪:愤怒、高兴、忧虑、感动、轻蔑…
语气:耳语、匆忙、喊叫……
拟声:笑、叹气、抽泣、观众笑…… - 零样本/少样本克隆:只需10~30秒语音样本,就可实现个性化语音合成。
高推理效率
- RTX 4060:实时因子1:5
- RTX 4090:实时因子1:15
部署:支持Linux、Windows
模型规格对比
| 模型 | 参数量 | WER | CER | 说话人距离 |
|---|---|---|---|---|
| S1 | 4B | 0.008 | 0.004 | 0.332 |
| S1-mini | 0.5B | 0.011 | 0.005 | 0.380 |
两者均支持RLHF(人类反馈强化学习),在不同算力条件下灵活部署。
不足:尽管在自动评估指标上表现非常亮眼,但在人工主观测评中,生成语音在情绪连贯性和自然语气表达上仍显生硬,特别是在多轮对话、微妙语境表达等场景下。
为了优化与改进思路:
- 基于大语言模型的上下文建模:引入LLM对文本进行情感语境感知,辅助情绪embedding的动态生成,而非使用静态标签;
- Prosody Predictor优化:设计更细粒度的prosody编码器,如基于扩散模型或flow-based网络建模韵律曲线;
- Prompt-Tuning 情感模板机制:结合prompt learning,让语音风格与情境描述自然映射,而非硬编码;
- 多模态对齐学习:引入图像或视频作为额外条件,辅助训练跨模态情感表达,适用于虚拟人、客服等应用场景。
Vui
Fluxions-AI团队开源的轻量级、可在消费级设备端运行的语音对话模型Vui。
作为NotebookLM风格的语音模型,Vui不仅能生成流畅的对话,还能精准模拟语气词(如呃、嗯)、笑声和犹豫等非语言元素,带来沉浸式的交互体验。可被应用于语音助手、播客生成、客服AI等场景。
提供三款模型:
- Vui.BASE:通用基础模型,4万小时对话训练;
- Vui.ABRAHAM:单说话人模型,单人上下文感知;
- Vui.COHOST:双说话人模型,双人互动。
Vui的轻量设计和逼真语音让它适用于多种场景:
- 播客生成:Vui.COHOST模拟双人对话,快速生成访谈或辩论音频;
- 语音助手:Vui.ABRAHAM提供上下文感知回复,适合智能客服或个人助理;
- 内容创作:生成自然语音,添加[laugh]、[hesitate],提升视频/播客真实感;
- 教育培训:模拟对话场景,生成教学音频,助力语言学习;
- 语音克隆:个性化语音定制,适合品牌营销或虚拟主播。
使用
git clone https://github.com/fluxions-ai/vui.git
cd vui
pip install -e .
# 运行在线Demo
python demo.py
Spark-TTS
GitHub
凭借BiCodec编解码器和Qwen-2.5思维链技术,实现高质量、可控的语音生成。支持零样本语音克隆,还能进行细粒度语音控制,包括语速、音调、语气等多项参数调节,同时具备跨语言生成能力,让AI语音变得更加灵活、多样化。
核心能力
- 零样本语音克隆:只需提供几秒钟的语音样本,便能克隆目标说话人的声音;
- 细粒度控制调整:粗粒度控制(性别、说话风格等);调整(音高、语速等);
- 跨语言语音生成:支持跨语言语音合成,支持中文和英文,并保持自然度和准确性;
- 高质量自然语音:结合Qwen-2.5思维链技术,增强语音表达逻辑,自动调整语气、停顿、强调等语音表达;
- 音质&语音控制能力:采用BiCodec单流语音编解码器,将语音分解为语义信息和说话人属性;
- Web界面支持:提供Web UI,方便进行语音克隆和语音创建的界面。
应用场景
- 有声读物:通过调整语速、音高和风格,生成富有表现力的朗读语音,提升听众体验。
- 多语言内容:支持中英文跨语言生成,适用于国际化应用。
- AI角色配音:利用零样本克隆技术,快速生成特定说话者的声音,用于虚拟角色或定制化服务。
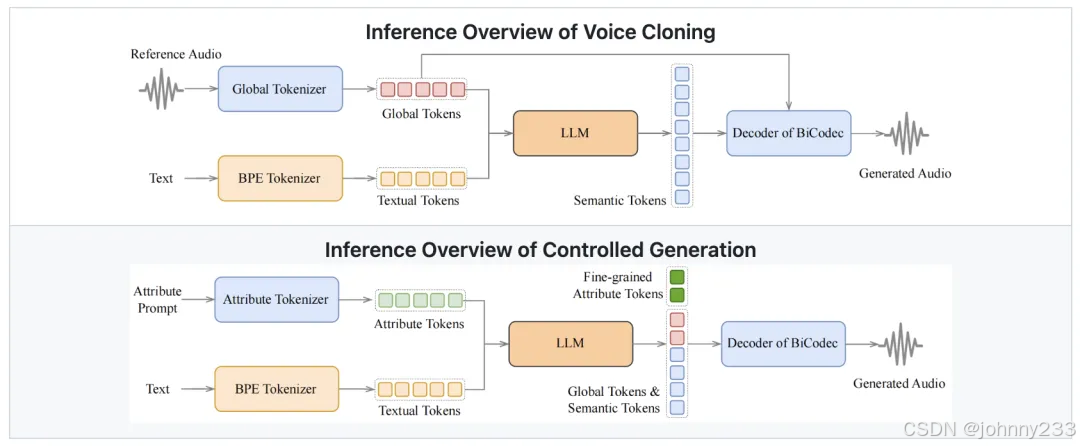
架构图
安装部署
git clone https://github.com/SparkAudio/Spark-TTS.git
cd Spark-TTS
创建Python虚拟环境,安装Python依赖
conda create -n sparktts -y python=3.12
conda activate sparktts
pip install -r requirements.txt
模型下载
- 通过Python代码下载
from huggingface_hub import snapshot_download
snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")
- 通过git下载
mkdir -p pretrained_models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
运行演示
cd example
bash infer.sh
在命令行中进行推理:
python -m cli.inference \--text "text to synthesis." \--device 0 \--save_dir "path/to/save/audio" \--model_dir pretrained_models/Spark-TTS-0.5B \--prompt_text "transcript of the prompt audio" \--prompt_speech_path "path/to/prompt_audio"
运行Web界面:python webui.py --device 0。
浏览器打开:
可以直接通过界面执行语音克隆和语音创建。支持上传参考音频或直接录制音频。
Index-TTS
GitHub,
IndexTTS-vLLM,GitHub,让语音合成更快速、更高效。核心价值在于通过vLLM加速IndexTTS的推理过程,显著提升语音合成的速度和并发能力。亮点:
- 单个请求RTF从0.3降至0.1;
- GPT模型decode速度提升至280 token/s;
- 支持多角色音频混合,为语音合成带来更多创意可能。
ASR和TTS
类似点:
- 深度学习架构:ASR和TTS均依赖序列模型(如Transformer、RNN),TTS常用Tacotron、VITS,ASR常用Conformer;
- 端到端训练:传统ASR需分别训练声学模型和语言模型,现代方法(如Whisper)趋向端到端;
- 数据预处理:语音增强(去噪)、文本归一化(数字100读作一百还是一零零)对两者均重要;
- 注意力机制:用于对齐语音与文本单元(如音素或字符)。
相比于ASR在复杂场景(如嘈杂环境)的技术难点,TTS复杂在:
- 主观评价标准:ASR的准确率可客观衡量(如词错误率),而TTS的自然度依赖人类主观评分(如MOS均值);
- 生成任务的复杂性:TTS需从文本生成高维语音波形,需建模细微的声学特征(如呼吸声、气口);
- 长尾问题:罕见词或特殊语境(如方言俚语)在TTS中更容易暴露不自然感。
未来趋势
- 联合建模:如SpeechGPT等统一架构尝试将ASR、TTS整合到单一模型中;
- 模型驱动:语音大模型(如OpenAI的Voice Engine)可能模糊ASR/TTS边界。



