MySQL 修改数据的全链路流程(InnoDB)
- 全链路流程图
- 关键步骤详解
- 1. 建立连接阶段
- 2.SQL解析与优化
- 3. InnoDB内存操作
- 4. 日志记录过程
- 5. 二阶段提交(2PC)
- 磁盘同步机制
- 1. Redo Log刷盘策略(innodb_flush_log_at_trx_commit)
- 2. Binlog刷盘策略(sync_binlog)
- 3. 脏页刷新机制
- 异常恢复流程
- 性能优化要点
- 1. 日志相关参数
- 2.监控指标
- 全链路耗时分布(示例)
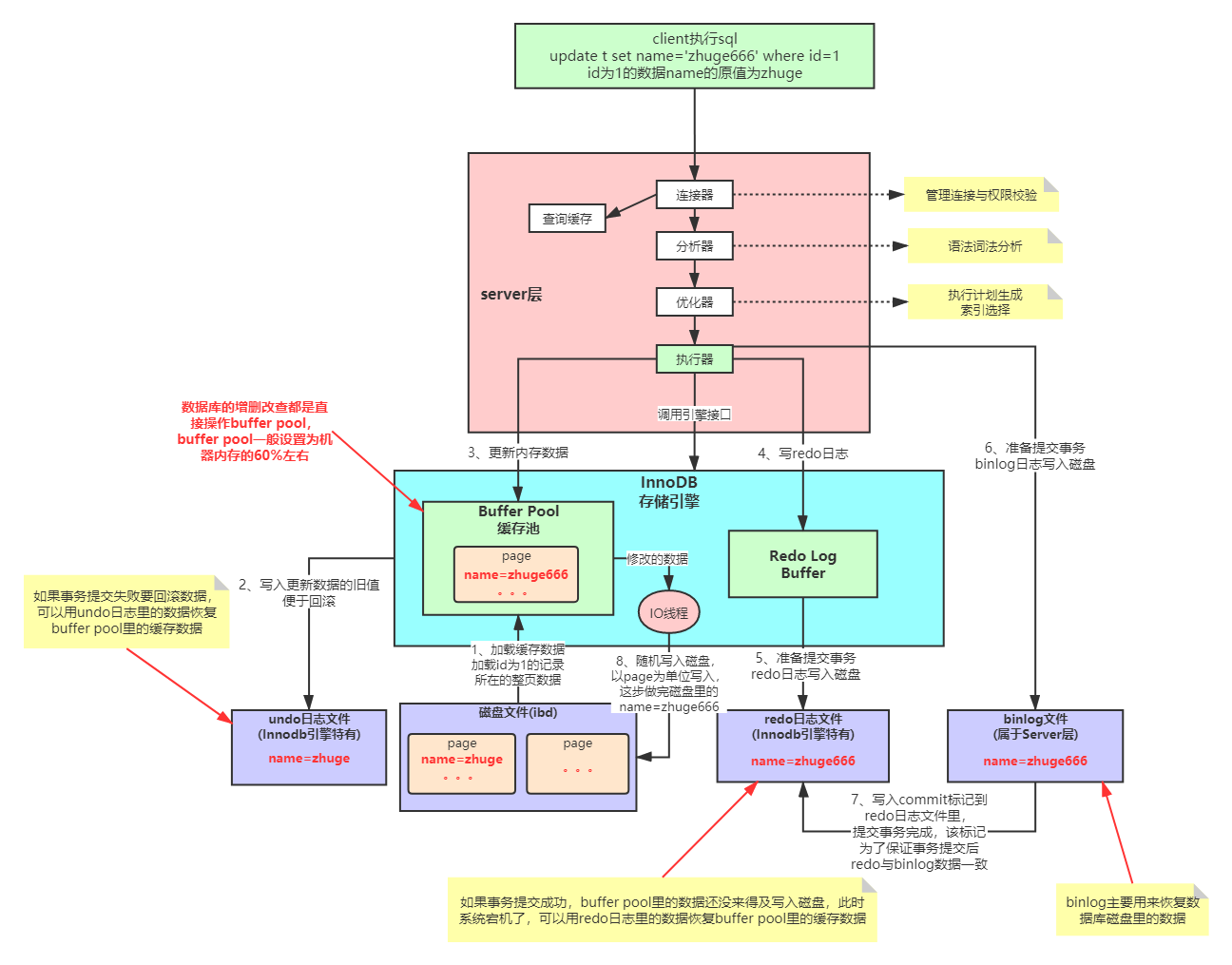
全链路流程图
关键步骤详解
1. 建立连接阶段
查看当前连接
SHOW PROCESSLIST;
- TCP三次握手建立连接
- 线程验证(用户名/密码/IP白名单)
- 连接池分配线程ID
2.SQL解析与优化
– 查看执行计划
EXPLAIN UPDATE users SET balance=100 WHERE id=5;
- 语法解析器生成解析树
- 优化器选择执行计划(是否走索引)
3. InnoDB内存操作
// 伪代码:Buffer Pool处理
if (!page_in_buffer_pool) {read_page_from_disk();
}row = find_row_in_page();
old_data = copy_row(row); // 用于undo log
modify_row(row); // 内存修改
4. 日志记录过程
| 日志类型 | 内容示例 | 写入时机 |
|---|---|---|
| Undo Log | 把id=5的balance从200改为100 | 修改前记录 |
| Redo Log | page_no=3, offset=128, value=100 | prepare阶段 |
| Binlog | UPDATE users SET balance=100 WHERE id=5 | 事务提交前 |
5. 二阶段提交(2PC)
磁盘同步机制
为什么Mysql不能直接更新磁盘上的数据而且设置这么一套复杂的机制来执行SQL了?
因为来一个请求就直接对磁盘文件进行随机读写,然后更新磁盘文件里的数据性能可能相当差。
因为磁盘随机读写的性能是非常差的,所以直接更新磁盘文件是不能让数据库抗住很高并发的。
Mysql这套机制看起来复杂,但它可以保证每个更新请求都是更新内存BufferPool,然后顺序写日志文件,同时还能保证各种异常情况下的数据一致性。
更新内存的性能是极高的,然后顺序写磁盘上的日志文件的性能也是非常高的,要远高于随机读写磁盘文件。
正是通过这套机制,才能让我们的MySQL数据库在较高配置的机器上每秒可以抗下几干甚至上万的读写请求
1. Redo Log刷盘策略(innodb_flush_log_at_trx_commit)
# my.cnf配置
innodb_flush_log_at_trx_commit=1 # 最安全(每次提交刷盘)
2. Binlog刷盘策略(sync_binlog)
sync_binlog=1 # 每次提交同步到磁盘
3. 脏页刷新机制
-- 查看刷页状态
SHOW ENGINE INNODB STATUS\G
- 当脏页比例超过innodb_max_dirty_pages_pct(默认75%)时触发
- 使用双写缓冲(Double Write Buffer)防止页断裂
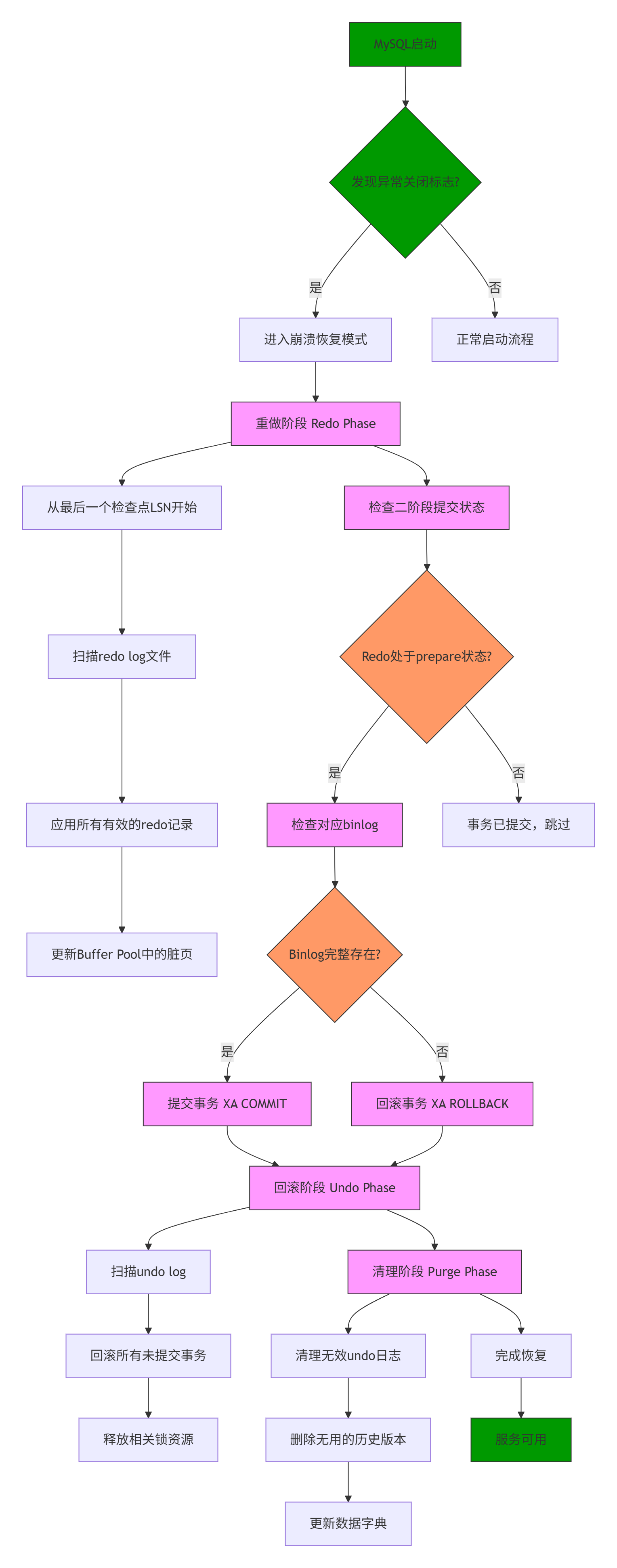
异常恢复流程
graph TDA[MySQL启动] --> B{发现异常关闭标志?}B -->|是| C[进入崩溃恢复模式]B -->|否| Z[正常启动流程]C --> D[重做阶段 Redo Phase]D --> D1[从最后一个检查点LSN开始]D1 --> D2[扫描redo log文件]D2 --> D3[应用所有有效的redo记录]D3 --> D4[更新Buffer Pool中的脏页]D --> E[检查二阶段提交状态]E --> E1{Redo处于prepare状态?}E1 --是--> F[检查对应binlog]E1 --否--> G[事务已提交,跳过] F --> F1{Binlog完整存在?}F1 -->|是| H[提交事务 XA COMMIT]F1 -->|否| I[回滚事务 XA ROLLBACK]H & I --> J[回滚阶段 Undo Phase]J --> J1[扫描undo log]J1 --> J2[回滚所有未提交事务]J2 --> J3[释放相关锁资源]J --> K[清理阶段 Purge Phase]K --> K1[清理无效undo日志]K1 --> K2[删除无用的历史版本]K2 --> K3[更新数据字典]K --> L[完成恢复]L --> M[服务可用]
性能优化要点
1. 日志相关参数
innodb_log_file_size=4G # 更大的redo log文件
innodb_log_buffer_size=256M # 增大日志缓冲区
binlog_group_commit_sync_delay=100 # 延迟组提交(微秒)
2.监控指标
-- 查看日志写入情况
SELECT * FROM performance_schema.innodb_metrics
WHERE NAME LIKE '%log%';-- 查看脏页比例
SELECT (SELECT variable_value FROM information_schema.global_status
WHERE variable_name='Innodb_buffer_pool_pages_dirty') /
(SELECT variable_value FROM information_schema.global_status
WHERE variable_name='Innodb_buffer_pool_pages_total') AS dirty_ratio;
全链路耗时分布(示例)
| 阶段 | 典型耗时 | 可优化手段 |
|---|---|---|
| 网络连接 | 1-10ms | 使用连接池 |
| SQL解析 | 0.1-1ms | 避免复杂SQL |
| 内存查找 | 0.01-0.1ms | 增大Buffer Pool |
| 日志写入 | 0.5-5ms | 调整刷盘策略 |
| 磁盘同步 | 1-10ms | 使用SSD |
这个流程完整展示了从客户端发起到数据落盘的全过程,其中Redo Log的二阶段提交机制和WAL(Write-Ahead Logging)原则是保证ACID特性的关键设计。


)



