博客配套代码发布于github:爬小说
相关知识点:[爬虫知识] Cookie与Session
相关爬虫专栏:JS逆向爬虫实战 爬虫知识点合集 爬虫实战案例
此篇文章侧重于对xpath的使用理解与requests.session的具体使用。
这里以小说网站5000言为例,我们试图爬取该页面中的《越女剑》,在获取对应章节的标题同时,对标题的链接进行二次访问,再获取每个章节的具体内容,并最终输出,保存写入在文件夹里。
一、分析网站
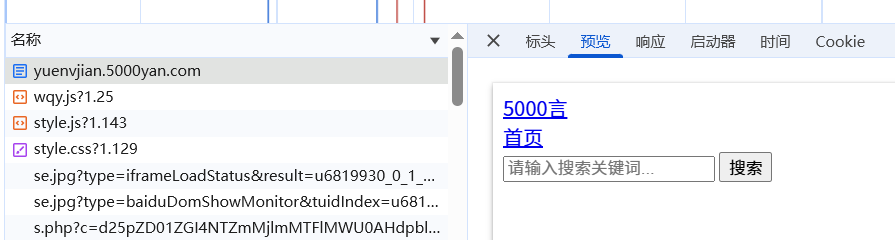
刷新网页后看到这个html文件,而且预览中能看到整个页面布局,基本确定这是个text型数据(如想了解text型与json型数据的区别与处理方式,欢迎点击数据解析进行了解),需要用xpath的方式取到对应我们想要的数据。
再从标头中把各项请求参数大致浏览,基本确定后,开始爬虫初始化动作。
二、爬取代码初始化
- 确认页面 -- url = 'https://yuenvjian.5000yan.com/'
- 确认请求头 -- headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36',
'referer':'https://5000yan.com/'
} - 发起请求 -- response = requests.get(url,headers=headers).text
print一下:
发现虽然打印成功但是有乱码,这里加入个编码格式response.encoding = 'utf8'就可以了: (别忘把之前response的.text去掉,在print环节再加.text)
得到对应我们想要的整个html数据就可以进行我们下步的数据清洗了。
三、数据清洗
1.一次请求获取标题与链接
在该页面直接选中这个元素查看:

发现这个a标签里既有我们想要的href链接,也有标题,直接将其copy过来并做进一步处理:
os.mkdir('越女剑')
tree = etree.HTML(response.text)
a_list = tree.xpath('/html/body/div[2]/div[1]/div[1]/div[3]/ul/li/a')
for a in a_list:if a == a_list[0]: # 这里去掉首项(因为它就是小说的整个文章)continuetitle = a.xpath('./text()')[0]href = a.xpath('./@href')[0]print(title,href)
如上,顺利打印出标题与文本,接着开始二次访问
2.二次请求链接获取标题里的文本
response_detail = requests.get(url=href,headers=headers)response_detail.encoding = 'utf8'tree = etree.HTML(response_detail.text)contents = tree.xpath('/html/body/div[2]/div[1]/div[1]/div[3]/div[4]/p/text()')print(contents)
如上,打印后发现其中每个contents都是个列表,其中有很多空格。这里我们通过join方法把列表里的内容变成字符串形式,同时再用个简单正则去掉字符串中含有空格的地方:
content = ''.join(contents)content = re.sub(r'\s+', '', content)print(content)
可以看出文章处理基本完成,剩下的就是将数据写入文件夹中
3.写入并保存对应文本
with open(f'./越女剑/{title}.txt', 'w', encoding='utf8') as f:f.write(content)print(f'{title}爬取成功!')
print(f'全部爬取完成!共计爬取{len(a_list) - 1}条数据!')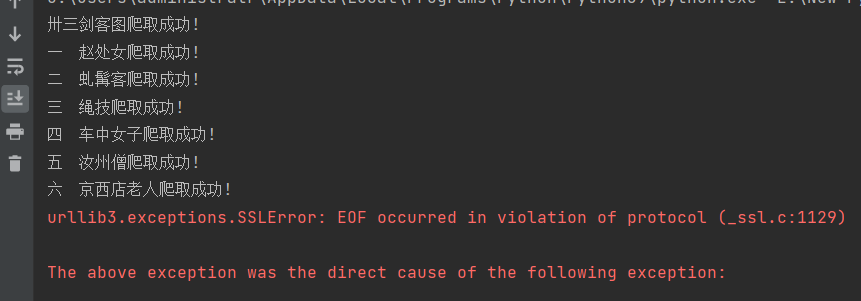
如图:很奇怪,我们爬取成功,而且确实能看到我们爬到的数据,那为什么会在爬的一半报这个SSL错误呢?挨个问题排除一下,
- 网站触发严厉反爬了吗 -- 否,访问网站仍然能访问,如果反爬早该封ip了
- 爬取太快吗 -- 否,在代码中加入time.sleep(random.uniform(0.1,0.3)),随机休眠0.1-0.3浮点数也报错。哪怕将数字提升到1-3也不行。
- 爬取逻辑出问题吗 -- 否,每次爬取都是随机数量,有时两三个有时七八个,如果爬取逻辑有误不会爬的这么诡异。
- IP代理的问题吗 -- 否,理由跟上条一样,用不用代理都是爬取到随机数量个
4.处理爬取异常问题
先说结论:上述爬取失败的最终错误原因在于反复请求次数过多,requests.get()每次复用都是重新建立了一个新的TCP连接,然后关闭它。服务器视角来看,就是一个IP地址进行极其频繁的连接-断开动作,再加上这里的请求量较大,最终被服务器最大连接数限制或者被识别为异常行为,拒绝新请求。
而通过requests.session就可以完美解决上述问题,关于其在这方面的逻辑与用法,还有类似场景理解可以在 爬虫知识之Cookie与Session了解。我们理解具体原因后再加入相关session处理,再试一次:
# xxx
session = requests.session()
# xxx
response = session.get(url,headers=headers)
# xxx
response_detail = session.get(url=href,headers=headers)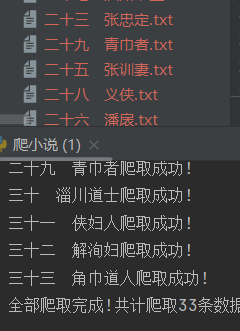 如图,完美解决了该问题,完整爬下了共33条数据,同时耗时也比之前的做法要快很多。
如图,完美解决了该问题,完整爬下了共33条数据,同时耗时也比之前的做法要快很多。
四、总结
在text型网页爬取过程中,合理运用xpath将其选中并处理。同时尽量用requests.session来替代requests.get/post,能有效提升爬虫健壮度与爬取能力。
练手网站:PPT模板_PPT模板免费下载和在线预览 - 站长素材
尝试爬取当前页面的每个页面标题与对应链接,同时二次访问再获取到对应链接里的下载文件,最后批量保存到文件夹中。
对应代码的获取可以在评论或者私信"PPT模板"后发给你。
分布式锁)

)


