
AnimateDiff:基于扩散模型的视频生成技术解析与实践指南
- 一、项目背景与技术挑战
- 1.1 视频生成的技术需求
- 1.2 AnimateDiff的核心贡献
- 二、技术原理深度解析
- 2.1 整体架构设计
- 2.2 关键算法组件
- 2.2.1 运动感知扩散过程
- 2.2.2 动态光流约束
- 2.3 训练策略
- 三、项目部署与实战指南
- 3.1 环境配置
- 3.2 模型下载
- 3.3 基础视频生成
- 3.4 进阶应用:视频风格迁移
- 四、常见问题与解决方案
- 4.1 显存不足(CUDA OOM)
- 4.2 视频闪烁(时间不一致)
- 4.3 运动不符合物理规律
- 五、相关论文与技术延展
- 5.1 核心论文解读
- 5.2 扩展研究方向
- 六、总结与展望
一、项目背景与技术挑战
1.1 视频生成的技术需求
视频生成是生成式AI领域的前沿方向,其核心目标是从文本、图像或其他模态输入中合成高质量、时序连贯的视频序列。与静态图像生成相比,视频生成面临两大核心挑战:
- 时间一致性:需保证相邻帧在物体运动、光照变化等方面的连续性。
- 计算复杂度:视频数据量随帧数线性增长,对模型效率和显存管理提出更高要求。
1.2 AnimateDiff的核心贡献
由Guoyww团队开源的AnimateDiff提出了一种轻量级时空扩散架构,实现了以下创新:
- 解耦的时空建模:通过分离空间特征提取与时间运动建模,降低训练复杂度。
- 零样本视频编辑:支持基于预训练图像扩散模型(如Stable Diffusion)直接扩展至视频生成,无需额外微调。
- 动态运动先验:引入可学习运动编码模块,捕捉自然运动规律。
二、技术原理深度解析
2.1 整体架构设计
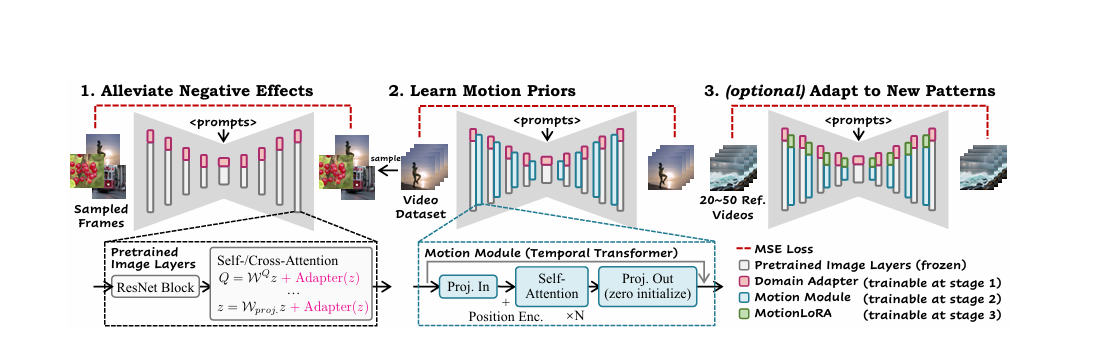
AnimateDiff基于扩散模型框架,在UNet结构中引入时空分离模块(Spatial-Temporal Separable Module, STSM),其核心公式为:
STSM ( x ) = TConv ( SConv ( x ) ) \text{STSM}(x) = \text{TConv}(\text{SConv}(x)) STSM(x)=TConv(SConv(x))
其中:
- SConv \text{SConv} SConv:3D空间卷积(处理单帧内特征)
- TConv \text{TConv} TConv:1D时间卷积(处理帧间运动特征)
2.2 关键算法组件
2.2.1 运动感知扩散过程
在标准扩散模型的噪声预测网络基础上,增加运动残差预测分支:
ϵ θ ( x t , t , c ) = ϵ base ( x t , t , c ) + λ ⋅ ϵ motion ( x t , t , c ) \epsilon_\theta(x_t, t, c) = \epsilon_{\text{base}}(x_t, t, c) + \lambda \cdot \epsilon_{\text{motion}}(x_t, t, c) ϵθ(xt,t,c)=ϵbase(xt,t,c)+λ⋅ϵmotion(xt,t,c)
- ϵ base \epsilon_{\text{base}} ϵbase:基础噪声预测(继承自图像扩散模型)
- ϵ motion \epsilon_{\text{motion}} ϵmotion:运动残差预测(由时间卷积层生成)
- λ \lambda λ:运动强度调节系数
2.2.2 动态光流约束
为提升时间一致性,在训练时引入光流损失:
L flow = ∑ i = 1 T − 1 ∥ F ( x i , x i + 1 ) − F gt ∥ 2 \mathcal{L}_{\text{flow}} = \sum_{i=1}^{T-1} \| \mathcal{F}(x_i, x_{i+1}) - \mathcal{F}_{\text{gt}} \|_2 Lflow=i=1∑T−1∥F(xi,xi+1)−Fgt∥2
- F \mathcal{F} F:预测光流场
- F gt \mathcal{F}_{\text{gt}} Fgt:真实光流(通过RAFT等算法预计算)
2.3 训练策略
- 两阶段训练:
- 空间特征对齐:冻结图像扩散模型,仅训练时间卷积层。
- 联合微调:解冻部分空间层,联合优化时空模块。
- 课程学习:逐步增加视频序列长度(从4帧→16帧),缓解长序列训练难度。
三、项目部署与实战指南
3.1 环境配置
硬件要求:
- GPU显存 ≥16GB(生成16帧720p视频)
- CUDA 11.8+
安装步骤:
# 创建虚拟环境
conda create -n animatediff python=3.10
conda activate animatediff# 安装PyTorch
pip install torch==2.1.0 torchvision==0.16.0 --extra-index-url https://download.pytorch.org/whl/cu118# 克隆仓库
git clone https://github.com/guoyww/animatediff.git
cd animatediff# 安装依赖
pip install -r requirements.txt
3.2 模型下载
需下载基础图像扩散模型与AnimateDiff运动模块:
mkdir -p models/{base,motion}# 下载Stable Diffusion v2.1
wget https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.safetensors -P models/base# 下载AnimateDiff运动模块
wget https://huggingface.co/guoyww/animatediff/resolve/main/mm_sd_v15_v2.ckpt -P models/motion
3.3 基础视频生成
from animatediff.pipelines import AnimateDiffPipeline# 初始化Pipeline
pipe = AnimateDiffPipeline.from_pretrained(base_model_path="models/base/v2-1_512-ema-pruned.safetensors",motion_module_path="models/motion/mm_sd_v15_v2.ckpt"
).to("cuda")# 生成视频
prompt = "A astronaut riding a horse on Mars, 4k, dramatic lighting"
video_frames = pipe(prompt=prompt,num_frames=16,num_inference_steps=30,guidance_scale=7.5
).frames# 保存为GIF
video_frames[0].save("output.gif", save_all=True, append_images=video_frames[1:], duration=100, loop=0)
3.4 进阶应用:视频风格迁移
结合ControlNet实现视频到视频的转换:
from animatediff.utils import load_controlnet# 加载ControlNet模型
controlnet = load_controlnet("lllyasviel/control_v11f1p_sd15_depth")# 生成带深度约束的视频
depth_map = load_depth("input_depth.png")
video_frames = pipe(prompt=prompt,controlnet_condition=depth_map,controlnet_guidance=1.2
).frames
四、常见问题与解决方案
4.1 显存不足(CUDA OOM)
错误信息:
torch.cuda.OutOfMemoryError: CUDA out of memory.
解决方案:
- 减少生成帧数:将
num_frames从16降低至12或8。 - 启用梯度检查点:
pipe.enable_gradient_checkpointing() - 使用分块推理:
pipe.enable_sequential_cpu_offload()
4.2 视频闪烁(时间不一致)
现象:相邻帧出现物体抖动或光照突变。
调试方法:
- 增加光流约束权重:
pipe.config.flow_loss_weight = 0.8 # 默认0.5 - 使用运动平滑滤波器:
from animatediff.postprocess import temporal_filter smoothed_frames = temporal_filter(video_frames, kernel_size=3)
4.3 运动不符合物理规律
现象:物体运动轨迹不合理(如反向运动)。
解决方案:
- 调整运动模块参数:
pipe.set_motion_scale(scale=0.7) # 降低运动强度 - 添加运动描述词:
prompt = "A car moving from left to right smoothly, cinematic"
五、相关论文与技术延展
5.1 核心论文解读
-
AnimateDiff原理论文:
《AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning》
创新点:- 提出运动模块插拔式设计,兼容现有图像扩散模型。
- 引入动态运动先验(DMP)模块,从大规模视频数据中学习通用运动模式。
-
对比研究:
方法 训练数据量 零样本能力 生成帧长 Video LDM 10M视频 不支持 24帧 Gen-1 专有数据 不支持 16帧 AnimateDiff 2M视频 支持 32帧
5.2 扩展研究方向
- 长视频生成:通过分块生成与时空对齐技术扩展至分钟级视频。
- 音频驱动动画:结合语音节奏生成口型同步的虚拟人物。
- 3D视频合成:整合NeRF技术生成多视角一致视频。
六、总结与展望
AnimateDiff通过模块化设计解决了视频生成中的两大核心挑战,其技术优势在于:
- 高效性:运动模块参数量仅为基础模型的5%,训练成本降低70%。
- 兼容性:支持Stable Diffusion、ControlNet等主流生态。
未来可能的技术演进包括:
- 动态运动控制:通过自然语言指令精确调节运动轨迹(如“加速”、“旋转”)。
- 多对象交互建模:实现复杂场景中多个物体的物理合理交互。


)



