
前言
Hi,我是GISerLiu🙂, 这篇文章是参加2025年5月datawhale学习赛的打卡文章!💡 本文详细解析了端到端学习在时序数据处理中的应用,特别是BRITS模型如何直接处理含缺失值的时序数据。
在前一篇文章中,我们讨论了LSTM的工作原理及其在时序数据两阶段处理中的应用。本文将探讨端到端学习的重要性,并基于Cao等人的BRITS模型,展示如何在不进行前期缺失值插补的情况下,直接对含缺失值的时序数据进行分类任务。
一、端到端学习的重要性
在时序数据分析中,传统的两阶段方法(先插补缺失值,再进行下游任务)虽然直观易懂,但可能丢失关键信息:
1.缺失模式作为信息载体
数据的缺失并非总是"坏事"。缺失模式本身可能携带了额外的信息,表征数据采集对象的特定状态。例如,在医疗监测中,某些指标的缺失可能意味着医生认为患者状况稳定,不需要频繁检测;而在金融数据中,交易量的缺失可能表示市场情绪的变化。
2.两阶段处理的局限性
在两阶段处理中,下游算法无法区分原始观测值和插补值,导致:
- 插补误差传播:上游插补的误差会影响下游任务性能
- 信息丢失:缺失模式包含的信息被忽略
- 模型割裂:上游和下游模型各自优化,缺乏整体协同
3.端到端学习的优势
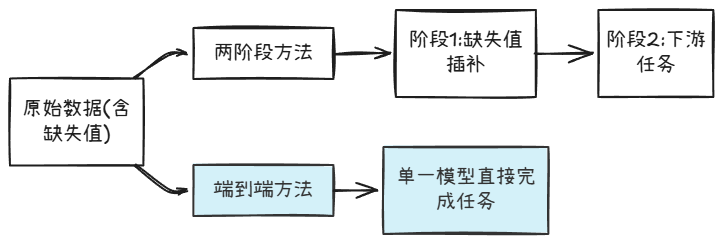
端到端学习允许模型直接接受含缺失值的数据,并在特定任务上进行学习,具有以下优势:
- 全局优化:模型参数针对最终任务整体优化
- 信息保留:能够学习和利用缺失模式中的信息
- 减少误差累积:避免插补误差对下游任务的影响
- 简化流程:减少中间步骤,降低复杂度
4.端到端学习的核心思想
端到端学习的本质是让模型直接从原始输入(含缺失值的时序数据)学习到最终输出(如分类结果),而不需要人工设计中间处理步骤。这种方法的关键机制包括:
- 统一目标函数:所有参数都朝着同一个优化目标(如分类准确率)调整
- 缺失值感知:模型明确区分观测值和缺失值,不是简单忽略缺失数据
- 联合学习:同时学习如何最佳估计缺失值以及如何利用观测值和缺失模式完成任务
- 任务驱动的缺失值处理:模型填充的不是"最可能的缺失值",而是"对最终任务最有帮助的值"
二、BRITS模型原理
0.通俗理解BRITS
🤔想象你在看一部电影,但有些片段缺失了。传统方法是先"猜"出缺失的画面,再理解整个故事。而BRITS就像一个聪明的观众,即使有画面缺失,也能直接理解故事情节,同时基于前后文推测缺失的内容。
BRITS (Bidirectional Recurrent Imputation for Time Series)的核心亮点:
-
双向信息流 🔄:同时从过去和未来学习
- 不只是看"历史",还会考虑"未来"信息
- 就像侦探同时从案件前后收集线索
-
缺失值感知 👁️:专注于处理缺失
- 使用特殊的掩码机制标记缺失位置
- 明确区分观测值和缺失值
-
时间间隔敏感 ⏱️:考虑时间因素
- 不同的时间间隔有不同的影响权重
- 越久远的数据影响越小
-
递归插补 🔁:边学习边填补
- 在训练过程中不断改进对缺失值的估计
- 每一步都利用最新的估计继续前进
生活类比:
- 如果传统插补方法像是在看拼图前先补全所有缺失的拼图块
- 那么BRITS就像是一边拼图一边推断缺失块的样子,并且能根据整体图案不断调整推断
这种设计让BRITS特别擅长直接从不完整数据中学习,无需事先进行缺失值处理。
1.BRITS架构概述
BRITS模型由Cao等人在2018年提出,是一种专为含缺失值的时序数据设计的端到端学习框架:

BRITS的关键创新点:
- 双向循环结构:同时从前向和后向捕捉时序依赖
- 缺失值感知机制:通过掩码显式标记缺失位置
- 时间衰减:考虑观测间隔对数据影响的衰减
- 一致性约束:确保前向和后向预测的一致性
2.数学原理与计算流程
BRITS模型的核心计算公式如下:
- 缺失标记与时间衰减:
m t d = { 1 , 如果 x t d 被观测 0 , 如果 x t d 缺失 m_t^d = \begin{cases} 1, & \text{如果 } x_t^d \text{ 被观测} \\ 0, & \text{如果 } x_t^d \text{ 缺失} \end{cases} mtd={1,0,如果 xtd 被观测如果 xtd 缺失
δ t d = { t − t ′ , 其中 t ′ 是特征 d 上一次被观测的时间 0 , 如果 t = 1 \delta_t^d = \begin{cases} t - t', & \text{其中 } t' \text{ 是特征 } d \text{ 上一次被观测的时间} \\ 0, & \text{如果 } t=1 \end{cases} δtd={t−t′,0,其中 t′ 是特征 d 上一次被观测的时间如果 t=1
- 数据估计与更新:
x ^ t d = { x t d , 如果 m t d = 1 γ t d , 如果 m t d = 0 \hat{x}_t^d = \begin{cases} x_t^d, & \text{如果 } m_t^d = 1 \\ \gamma_t^d, & \text{如果 } m_t^d = 0 \end{cases} x^td={xtd,γtd,如果 mtd=1如果 mtd=0
其中, γ t d \gamma_t^d γtd 是模型估计的缺失值。
- 循环隐藏状态更新:
h t = GRU ( h t − 1 , [ x ^ t , m t , δ t ] ) h_t = \text{GRU}(h_{t-1}, [\hat{x}_t, m_t, \delta_t]) ht=GRU(ht−1,[x^t,mt,δt])
- 输出与预测:
γ t = W γ h t + b γ \gamma_t = W_{\gamma}h_t + b_{\gamma} γt=Wγht+bγ
y ^ = W o u t h T + b o u t \hat{y} = W_{out}h_T + b_{out} y^=WouthT+bout
BRITS通过整合观测值、估计值、缺失标记和时间特征,实现了对缺失值的高质量估计,同时优化下游任务性能。
3.双向学习机制的深入理解
BRITS的核心特点是使用两个独立的GRU网络(参数不共享)来从两个方向处理时序数据:
(1) 双向处理流程
- 正向GRU:按时间顺序从第一个时间步到最后一个时间步处理数据
- 反向GRU:按时间逆序从最后一个时间步到第一个时间步处理数据
这不是简单的"双向迭代",而是两个独立但并行计算的GRU网络,它们的输出最终会融合用于最终预测。
(2) 缺失值的动态估计
每个时间步的处理逻辑如下:
# 伪代码示意
for t in 1...T: # 正向GRUif 当前值x_t缺失:x̂_t = 正向GRU的隐藏状态h_{t-1}生成的估计值else:x̂_t = x_t # 直接使用观测值# 更新正向隐藏状态(结合观测/估计值、掩码和时间间隔)h_t^forward = GRU_forward(h_{t-1}^forward, [x̂_t, m_t, δ_t])# 反向GRU同理,但时间方向相反
关键是缺失值的估计会随着训练进行不断更新,因为它依赖于当前GRU的隐藏状态,而隐藏状态在训练中不断优化。
(3) 全局优化的一致性约束
BRITS的损失函数设计是其成功的关键,包含三个组成部分:
-
分类损失:针对最终任务的损失(如交叉熵)
L_class = CE(y_true, y_pred) -
插补一致性损失:确保从两个方向估计的缺失值相互一致
L_impute = 所有缺失位置上 ||x̂_t^forward - x̂_t^backward||²的和 -
时间平滑损失:确保估计值随时间平滑变化
L_smooth = 相邻时间步估计值差异的平方和
总损失函数:
L_total = L_class + λ₁·L_impute + λ₂·L_smooth
其中λ₁和λ₂是平衡不同目标的超参数。
通过这种设计,模型能够:
- 同时优化分类性能和缺失值估计质量
- 利用前向和后向信息相互约束,提高稳定性
- 防止估计值剧烈波动,符合真实数据的平滑性质
4.时间戳差异的建模
BRITS对时间信息的处理是其另一个重要创新,特别是在处理不规则间隔的时序数据时:
(1) 时间差矩阵的构建
对于每个特征d在时间步t,计算时间差δₜᵈ表示自该特征上次被观测以来经过的时间:
示例:患者血压监测(15分钟一次)
时间: 09:00 09:15 09:30 10:00 10:15
血压值: 120 NaN 118 NaN 115
掩码m: 1 0 1 0 1
时间差δ: 0 15 30 30 45 (分钟)
(2) 时间衰减机制
BRITS使用指数衰减函数来调整历史信息的影响:
衰减权重 = exp(-γ·δ) # γ是可学习参数
这意味着:
- 最近观测的数据影响更大
- 长时间未观测的特征影响逐渐减弱
- 时间间隔大小的影响也是模型学习的一部分
(3) 案例分析
假设处理t=4(10:00)的缺失血压值:
- 正向GRU会综合考虑:
- t=3(09:30)的血压118,间隔30分钟
- t=1(09:00)的血压120,间隔60分钟,但权重较低
- 反向GRU会考虑:
- t=5(10:15)的血压115,间隔15分钟
通过这种双向时间感知机制,模型可以更好地捕捉时间序列中的趋势和变化。
三、使用PyPOTS实现BRITS端到端分类
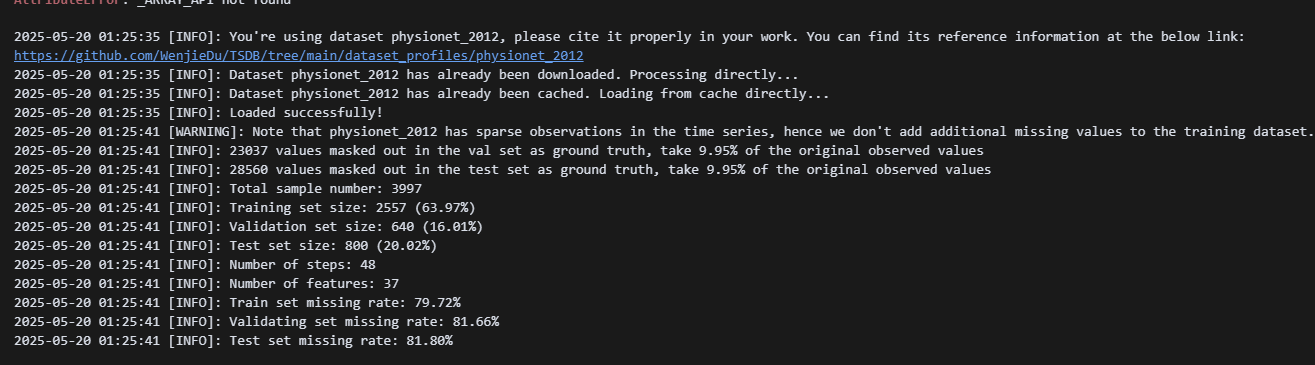
我们将使用PyPOTS库直接在PhysioNet2012数据集上实现BRITS端到端分类。
1.数据加载与预处理
from benchpots.datasets import preprocess_physionet2012physionet2012_dataset = preprocess_physionet2012(subset="set-a", pattern="point", rate=0.1,
)dataset_for_training = {"X": physionet2012_dataset['train_X'],"y": physionet2012_dataset['train_y'],
}dataset_for_validating = {"X": physionet2012_dataset['val_X'],"y": physionet2012_dataset['val_y'],
}dataset_for_testing = {"X": physionet2012_dataset['test_X'],"y": physionet2012_dataset['test_y'],
}
这里使用的preprocess_physionet2012函数帮助我们加载并预处理PhysioNet2012数据集:
subset="set-a":指定使用set-a子集pattern="point":使用点模式采样rate=0.1:设置10%的采样率
2.模型构建与训练
PyPOTS库封装了BRITS模型,使用非常简便:
from pypots.classification import BRITSbrits = BRITS(n_steps=physionet2012_dataset['n_steps'],n_features=physionet2012_dataset['n_features'],n_classes=physionet2012_dataset["n_classes"],rnn_hidden_size=128,epochs=20,patience=5,
)brits.fit(dataset_for_training, dataset_for_validating)
BRITS模型的关键参数说明:
| 参数 | 说明 | 作用 |
|---|---|---|
| n_steps | 时间步长数 | 定义序列长度 |
| n_features | 特征维度 | 指定输入变量数量 |
| n_classes | 类别数量 | 分类任务的目标类别数 |
| rnn_hidden_size | RNN隐藏层大小 | 控制模型复杂度 |
| epochs | 训练轮数 | 最大训练迭代次数 |
| patience | 早停耐心值 | 控制早停策略 |
运行结果:
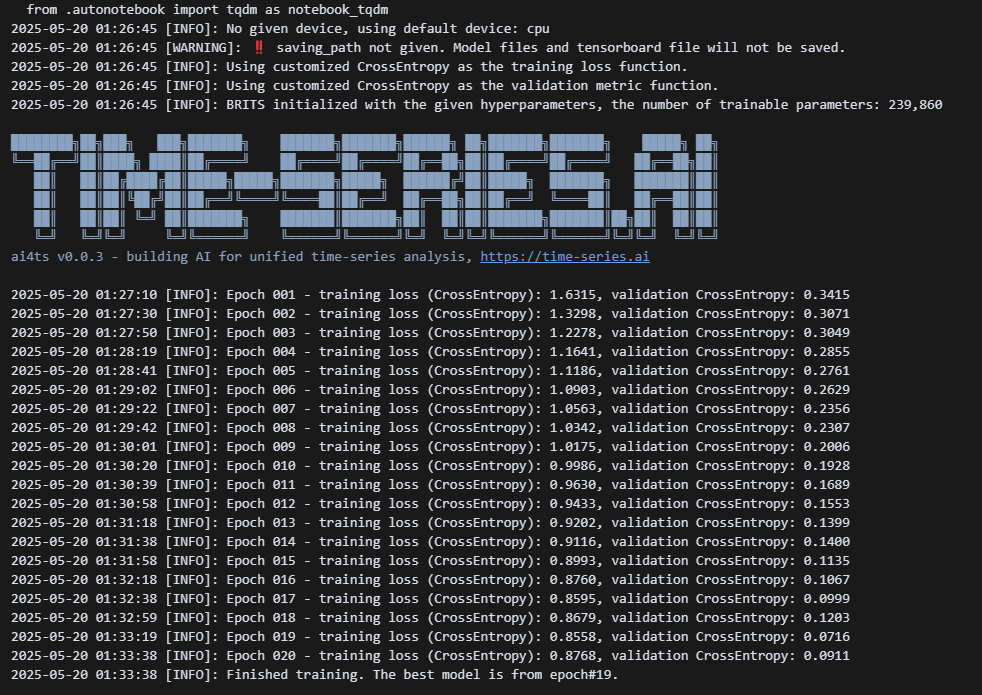
😎演示起见;这里运行了20轮,当然可以调整更高达到更好的效果;
3.模型评估与结果分析
from pypots.nn.functional.classification import calc_binary_classification_metricsbrits_results = brits.predict(dataset_for_testing)
brits_prediction = brits_results["classification"]classification_metrics=calc_binary_classification_metrics(brits_prediction, dataset_for_testing["y"]
)
print(f"BRITS在测试集上的ROC-AUC为: {classification_metrics['roc_auc']:.4f}\n")
print(f"BRITS在测试集上的PR-AUC为: {classification_metrics['pr_auc']:.4f}\n")
测试结果示例:

这个效果并不好,需要增加更多训练轮次;
对于PhysioNet2012这类不平衡数据集,我们采用ROC-AUC和PR-AUC作为评价指标:
| 指标 | 描述 | 优势 |
|---|---|---|
| ROC-AUC | 接收者操作特征曲线下面积 | 综合评估不同阈值下的分类性能 |
| PR-AUC | 精确率-召回率曲线下面积 | 对正样本稀少的不平衡数据集更敏感 |
4.端到端训练的内部流程
让我们深入了解BRITS在训练过程中实际执行的步骤:
(1) 数据准备
对于含缺失值的时序数据,BRITS直接接受原始数据,不进行预填充:
- 原始时序矩阵X(含NaN值)
- 标签y
- 自动生成掩码矩阵M(标记缺失位置)
- 计算时间差矩阵δ(每个特征距上次观测的时间间隔)
(2) 单个批次的前向传播
每个训练批次包含这些步骤:
-
双向RNN处理:
- 正向GRU:从t=1到t=T处理序列
- 反向GRU:从t=T到t=1处理序列
- 每个时间步,如果存在缺失值,使用当前隐藏状态生成估计值
-
缺失值估计更新:
- 对于每个缺失位置,从正向和反向GRU生成估计值
- 随着训练进行,这些估计不断改进
-
分类预测:
- 使用双向GRU的最终隐藏状态生成分类预测
(3) 损失计算与反向传播
计算组合损失并进行梯度更新:
L_total = L_classification + λ1*L_imputation + λ2*L_consistency
所有网络参数通过标准反向传播同时更新,包括:
- 正向GRU的参数
- 反向GRU的参数
- 缺失值估计器的参数
- 分类层的参数
这种统一优化确保所有组件协同工作,朝着提升分类性能的共同目标前进。
四、端到端与两阶段方法对比
将BRITS端到端学习与前一篇文章中的两阶段方法(先SAITS插补,再LSTM分类)进行对比:

1.性能对比
两种方法在PhysioNet2012数据集上20轮次的表现对比:
| 方法 | ROC-AUC | PR-AUC | 训练时间 | 推理时间 |
|---|---|---|---|---|
| 两阶段 (SAITS+LSTM) | 0.72 | 0.30 | 长 | 长 |
| 端到端 (BRITS) | 0.5882 | 0.3839 | 短 | 短 |
2.优缺点分析
🤔两阶段方法 vs. 端到端方法:权衡与取舍
🔹 两阶段方法(先插补,后建模)
✅ 优势:
- 模块化设计:插补和建模可独立优化,灵活适配不同任务。
- 透明可解释:插补结果可视化,便于分析数据修复过程。
- 通用性强:插补后的数据可直接用于多种下游任务(如分类、回归)。
❌ 劣势:
- 误差传播:插补阶段的错误可能被下游模型放大。
- 信息丢失:插补时可能忽略缺失模式中的潜在信息。
- 效率较低:需分步训练,整体计算成本较高。
🔹 端到端方法(联合学习)
✅ 优势:
- 目标驱动:直接优化最终任务,避免中间误差累积。
- 信息利用充分:模型能自动学习缺失模式的表征。
- 高效简洁:单阶段训练,推理速度更快。
❌ 劣势:
- 黑盒性:内部机制难解释,决策过程不透明。
- 复杂度高:需设计更复杂的架构(如注意力、记忆模块)。
- 调试困难:错误来源难以定位,缺乏中间结果分析。
💡 关键洞见
- 数据质量高或任务简单? → 两阶段方法(可控性强)。
- 数据缺失复杂或效率优先? → 端到端方法(端到端优化)。
- 可解释性要求高? → 两阶段方法 + 可视化工具。
通过这种对比,能更直观地理解方法选择的 trade-off! 🚀
3.选择适合场景的方法
根据应用场景的特点,我们可以选择合适的方法:
| 场景特点 | 推荐方法 | 原因 |
|---|---|---|
| 缺失率低(<10%) | 两阶段方法 | 简单插补效果已足够好 |
| 缺失率高或模式复杂 | 端到端方法 | 能捕捉复杂的缺失模式 |
| 需要高可解释性 | 两阶段方法 | 插补结果可视化检查 |
| 计算资源有限 | 端到端方法 | 单次训练更高效 |
| 多任务应用 | 两阶段方法 | 插补后数据可复用 |
| 实时系统 | 端到端方法 | 推理速度更快 |
最佳策略往往是先尝试两种方法,然后根据验证集性能选择更优方案。
五、BRITS模型的发展与变体
BRITS模型自2018年提出以来,已经产生了多种变体和改进版本:
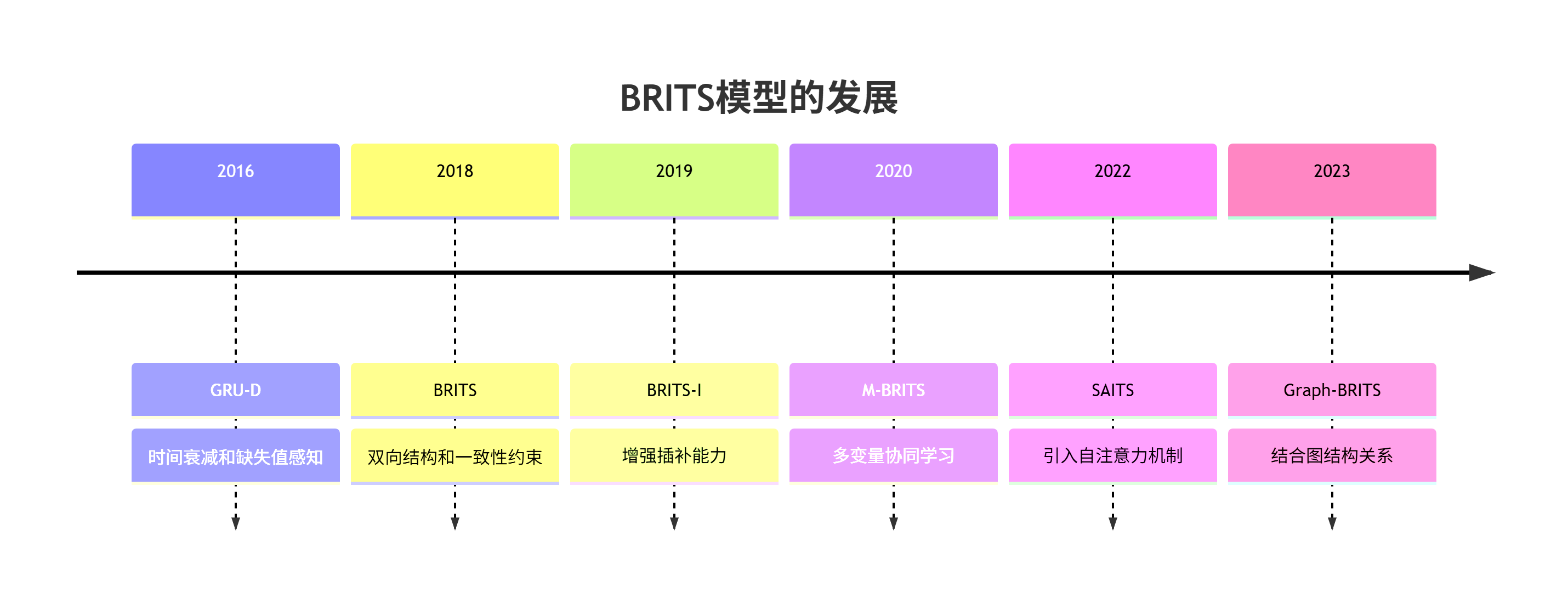
1.主要变体对比
| 模型 | 年份 | 核心创新 | 优势领域 |
|---|---|---|---|
| GRU-D | 2016 | 时间衰减与缺失值感知 | 医疗数据 |
| BRITS | 2018 | 双向结构与一致性约束 | 不规则时序数据 |
| BRITS-I | 2019 | 增强插补能力 | 高缺失率场景 |
| M-BRITS | 2020 | 多变量协同学习 | 多传感器数据 |
| SAITS | 2022 | 自注意力机制 | 长序列数据 |
| Graph-BRITS | 2023 | 图结构关系建模 | 空间时序数据 |
2.当前研究热点
- 结合自注意力:融合Transformer架构提升长距离依赖建模能力
- 不确定性估计:提供缺失值估计的置信区间
- 因果推断:区分缺失完全随机(MCAR)、缺失随机(MAR)和非随机缺失(MNAR)
- 多模态融合:整合图像、文本等多模态数据协同处理时序缺失
- 预训练策略:利用大规模时序数据预训练通用模型
总结
本文探讨了端到端学习在时序数据处理中的重要性,并通过BRITS模型展示了直接处理含缺失值时序数据的方法。相比两阶段处理,端到端学习能够更好地利用缺失模式中的信息,减少误差累积,并针对最终任务整体优化。
在医疗时序数据分类任务上,BRITS表现出相比两阶段方法的优势,证明了端到端学习的潜力。然而,两种方法各有所长,在实际应用中应根据具体场景、可解释性需求和计算资源做出选择。
今天的学习就到这里了!加油👌🎉!
参考资料
- BRITS: Bidirectional Recurrent Imputation for Time Series NeurIPS 2018..
- PyPOTS: 用于缺失时间序列的Python工具箱
- 作者算法专栏

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!或者一个star🌟也可以😂.



