在文章中《深度解析官方关于jdk1.8的resizeStamp的bug处理过程》,我们讨论关于CHM的核心设计——resizeStam需要修复的处理过程,本文再次基于openJDK的bugs讨论组提出的CHM源代码另外一个会造成死循环的bug,默认读者已经掌握CHM的核心源代码实现,否则无法从本文的讨论中获益。文章前部分先把computeIfAbsent的bug成因分析清楚,再来介绍官网ConcurrentHashMap.computeIfAbsent stuck in an endless loop的讨论过程,这样更容易看懂相关内容。
研究openJDK官方公布的相关源码bug有何“收益”:
虽然这些bug不是特别严重,修复起来也即几行代码,但如果想要解决这种看似“简单的bug”,要求对CHM设计原理、类、方法实现细节足够熟悉,也就是说,你要具备(至少在这个bug上下文的类、方法范围内)和源代码设计者同等思考视角才能去挖掘bug的本质原因并提出合理的修复建议。换句话说,你研究的不是这个bug本身,而是深入精通整个类的源代码实现,这种高级收益在日常业务开发几乎无法获得。
认识computeIfAbsent用法
理解computeIfAbsent在一些场合下的用法,有助于帮助切入源代码分析。
computeIfAbsent使用场景1:
package concurrent.demo;
import java.util.concurrent.ConcurrentHashMap;public class Demo1 {static int computeKeyLength(String key){ // 计算key的长度,将其作为该key对应的valuereturn key.length();}public static void main(String[] args){ConcurrentHashMap<String,Integer> map=new ConcurrentHashMap<>();map.put("foo",1);map.computeIfAbsent("foobar",key->computeKeyLength(key));System.out.println(map); //输出 {foobar=6, foo=1}}computeIfAbsent字面意思:如果key不在map里面,那么就使用给定的匿名函数(也叫映射函数)将key对应的value“计算出来”。(匿名函数也即lambda语法是jdk1.8语法新特性,这一点不必多说)
按这个思路可以有以下解释:
因为字符串"foobar"这个key不在map里面,因此把它放入map的同时,对应的value要用给定的函数computeKeyLength计算出来,例如这里调用computeKeyLength计算值为6,因此有key=foobar,value=6,将其放入map中。
map.put("bar",10);map.computeIfAbsent("bar",key->computeKeyLength(key));System.out.println(map); // 输出:{bar=10}
若key已经在map时,value不会被computeKeyLength(key)的计算值6所覆盖。
当然此demo做了一个不优雅的示范:既然可用匿名函数的写法去写逻辑,就没必要基于方法computeKeyLength去封装多一层,最简便写法如下:
map.computeIfAbsent("foobar",key->key.length());
注意这个key可以作为匿名函数的入参去参与到计算value,也可以不作为匿名函数的入参,如下:
map.computeIfAbsent("foobar",key->10);
显然foobar=10。
computeIfAbsent使用场景2:
并发场景下的频率统计:该demo方法其实在并发计数器LongAdder这个类的源码注释里面,Doug Lea已经告诉我们一个经典的场景恰好需要使用computeIfAbsent方法
LongAdders can be used with a java.util.concurrent.ConcurrentHashMap to maintain a scalable frequency map (a form of histogram or multiset). For example, to add a count to a ConcurrentHashMap<String,LongAdder> freqs, initializing if not already present, you can use freqs.computeIfAbsent(k -> new LongAdder()).increment();
package concurrent.demo;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.LongAdder;public class Demo2 {public static void main(String[] args){ConcurrentHashMap<String,LongAdder> map=new ConcurrentHashMap<>();String[] strings={"foo","bar","foo","foo"};for (String key : strings) {map.computeIfAbsent(key,k-> new LongAdder()).increment();}System.out.println(map); //输出 {bar=1, foo=3}}
}
该demo虽然只是用单个线程去执行computeIfAbsent,但逻辑是清晰的:实现对字符串出现次数进行统计
- 关于LongAdder的分析,它内部其实有一个像ConcurrentHashMap的fullAddCount并发计数逻辑,这里不再讨论,有关研究可参考本博客的文章《Java并发进阶系列:LongAdder高并发计数性能分析》
computeIfAbsent方法源码解析
这部内容要求读者已经掌握jdk1.8的ConcurrentHashMap设计及其关键方法的源代码实现逻辑,否则将难以理解其含义。本节所提的computeIfAbsent是未修复前的版本,这里并不会详细解析computeIfAbsent每一行代码,因为它跟putVal方法逻辑几乎一样,而不同地方可参考以下数字标记的说明:
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {if (key == null || mappingFunction == null)throw new NullPointerException()int h = spread(key.hashCode()); V val = null;int binCount = 0;for (Node<K,V>[] tab = table;;) { //看到这个写法应该很熟悉了:自旋+cas机制,为啥要自旋,因为线程不保证自己一次cas就成功,如果和其他线程竞争失败,则需要重试cas,这就是“自旋+cas机制”的黄金搭配。Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & h)) == null) { //① 如果key对应的桶位为空,先创建一个保留节点用于接下里的占位逻辑Node<K,V> r = new ReservationNode<K,V>();// ②当前线程用保留节点占位当然需要借用独占锁对r对象进行加锁synchronized (r) {// 在当前桶位放置保留节点用于占位,占位之后就可以给该桶位放入新建的node节点if (casTabAt(tab, i, null, r)) {binCount = 1;Node<K,V> node = null;try {/*putVal在桶位为空时的逻辑,可看到非常简单,直接使用cas给当前桶位设置新节点,value是给定的value,不需要通过函数计算出valueif (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null))) {break; }*/// 对于computeIfAbsent,value是需要用给定的匿名函数计算出的,正如前面场景1的“bar”这个key对应的“value”就是使用computeKeyLength(key)计算处理的值if ((val = mappingFunction.apply(key)) != null)node = new Node<K,V>(h, key, val, null);} finally {//虽然在②步骤那里已经在桶位i放置了一个ReservationNode用于占位,到了这个步骤才是真正把数据节点node放入桶位i当中setTabAt(tab, i, node);}}}// 显然②步骤一定能成功在桶位i放入node节点(binCount=1),既然已经将key和value放入map,那么任务完成,当前线程退出自旋if (binCount != 0)break;}//③如果key定位到的桶位i恰好是一个ForwardingNode占位节点,那么当前线程要去参与“帮助扩容”的逻辑,这里跟putval一样。else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {//代码若执行到这,说明桶位i是一个链表或者一棵红色树 boolean added = false;// 当前线程先给头节点加独占锁,保证当前线程写入节点操作时的独占性synchronized (f) {//并发环境,这里当然还要二次检查头节点是不是刚刚加锁前的头节点(也即检查加锁前后的头节点有无被改动过)if (tabAt(tab, i) == f) {// ④f节点是链表的情况if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek; V ev;// 在链表中遇到相同的key,那么就不做更新value操作,返回旧valueif (e.hash == h &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {val = e.val;break;}Node<K,V> pred = e;// 尾插法:来到链表尾部if ((e = e.next) == null) {// key不在链表时,value则由给定的匿名函数计算而来if ((val = mappingFunction.apply(key)) != null) {added = true;//尾插法pred.next = new Node<K,V>(h, key, val, null);}break;}}}// ④f节点是TreeBin的情况(该桶位是一棵红黑树)else if (f instanceof TreeBin) {binCount = 2;TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> r, p;if ((r = t.root) != null &&(p = r.findTreeNode(h, key, null)) != null)val = p.val;// key不在树里面时,value则由给定的匿名函数计算而来else if ((val = mappingFunction.apply(key)) != null) {added = true;t.putTreeVal(h, key, val);}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (!added)return val;break;}}}/*//以下两行是putVal的逻辑:CHM添加一个节点后,需要对size加1计数addCount(1L, binCount);return null;*/if (val != null)addCount(1L, binCount);return val;// }相信经过以上“可理解的场景使用和源代码分析”,computeIfAbsent应该能掌握了,下面进入官方bug解析的流程,具有较高水平的知识点,值得阅读!
an endless loop
具体提交页面参考官方bug描述页面
问题:ConcurrentHashMap.computeIfAbsent stuck in an endless loop
该提交者提交方式是那种示范性的提问方式,提供较为详细的辅助信息:jdk版本、操作系统信息、问题描述、以及复现bug的测试代码
package at.irian.misc.javabug;import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;public class Main {public static void main(String[] args) {Map<String, Integer> map = new ConcurrentHashMap<>(16);map.computeIfAbsent("AaAa",// 建议改写为 k1-> map.computeIfAbsent("BBBB",k2->42),相对直观易懂key -> {return map.computeIfAbsent("BBBB",key2 -> 42);});}}有了前面computeIfAbsent用法的介绍,提交者提交的测试代码其实很好理解:
“AaAa”对应的value需要根据map.computeIfAbsent("BBBB",key2 -> 42)计算出来,易知value返回的是42
本来期待map的结果是{AaAa=42,BBBB=42},当执行时,发现程序“卡住了”不能结束,说明bug已复现,但如何一步一步追踪它呢?
考虑到提交者的测试代码写得比较一般,比如匿名函数写个return显然是多余的,再例如为了制造两个key哈希冲突,写了个“AaAa”、“BBBB”,这当然无大碍,只是看起来有点“Counterintuitive”,因此这里给出相对容易接受的测试代码:
package concurrent.demo;
public class Demo3 {public static void main(String[] args){ConcurrentHashMap<Name, Integer> map = new ConcurrentHashMap<>(16);map.computeIfAbsent(new Name("foo"),k1-> map.computeIfAbsent(new Name("bar"),k2->10)/*或者使用 k1-> map.computeIfAbsent(new Name("bar"),k2-> k2.key.length()) 这里的k2是指new Name("bar"),那么k2.key就是“bar”这个字符串,那么k2.key.length()就是计算k2里面字符串的长度,预期输出结果为{bar=3,foo=3}*/);}// 定义一个Name对象,用于作为map的keystatic class Name {private String key;Name(String key){this.key=key;}@Overridepublic int hashCode() {// 重写hashCode方法,保证每个不同key计算的哈希值都一样,目的是让不同的key直接在同一桶位上发生哈希冲突,以便观察bug的执行流程。显然根据桶位计算方法:i = (16 - 1) & 1,由此可知,不同Name的key都会在桶位1上发生冲突。return 1;}@Overridepublic String toString(){return key;}}}
对于new Name("foo")和new Name("bar")这两个不同key,其哈希值都是1,期待运行结果:{foo=10,bar=10},实际运行结果:程序陷入了死循环,复现了源代码的bug。
深挖原因
借助IDEA debug即可完成此任务。在computeIfAbsent的以下代码处打上断点:
else if ((f = tabAt(tab, i = (n - 1) & h)) == null) { //这行不是断点位置 Node<K,V> r = new ReservationNode<K,V>(); // 这行是断点位置
根据Name的固定hash值可知道,当首次执行将 new Name("foo")放入桶位时,程序第一循环先完成table的初始化创建,即如下逻辑:
for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// ① 第1次循环,table为空,因此需要执行初始化逻辑if (tab == null || (n = tab.length) == 0)tab = initTable();else if{//...}
table的初始化之后,进行第2次循环,会进入到以下逻辑:
// ② 第2次循环,会进入此逻辑,这好理解,因为new Name("foo")这个key的哈希值为1,首次放入key之前,桶位1的头节点f一定是null的else if ((f = tabAt(tab, i = (n - 1) & h)) == null) {Node<K,V> r = new ReservationNode<K,V>(); //这行是断点位置synchronized (r) { // ③if (casTabAt(tab, i, null, r)) {binCount = 1;Node<K,V> node = null;try {//if ((val = mappingFunction.apply(key)) != null)
以上两点是要说明:运行debug时虽然执行流会马上停在断点代码位置,但在暂停前,代码已经执行完第1次循环(初始化操作)和正在进行第2次循环
因为CHM是并发的,因此进入加锁区后不是先把new Name(“foo”)这个节点直接放入桶位1中,而是先放一个保留节点用于占位(好让其他线程看到该桶位是一个保留节点后就转去做其他事情),然后才进入以下try代码区
try {if ((val = mappingFunction.apply(key)) != null)// ④node = new Node<K,V>(h, key, val, null);} finally {setTabAt(tab, i, node);}
标记④位置的代码就是揭开bug的关键入口点,在try代码块里面,new Name(“foo”)这个key的value是用指定的匿名函数(或者称为映射函数)计算出来,因此④位置代码是调用给定匿名函数去计算value,如果Step Into到这个位置,那么接下来再继续Step Into就会来测试代码这一位置k1-> map.computeIfAbsent(new Name("bar"),k2->10):
说明new Name(“foo”)这个key要想放入桶位1,得先等map.computeIfAbsent(new Name("bar"),k2->10)逻辑执行完成。
从Frames的线程方法调用栈也可以看出相关逻辑:
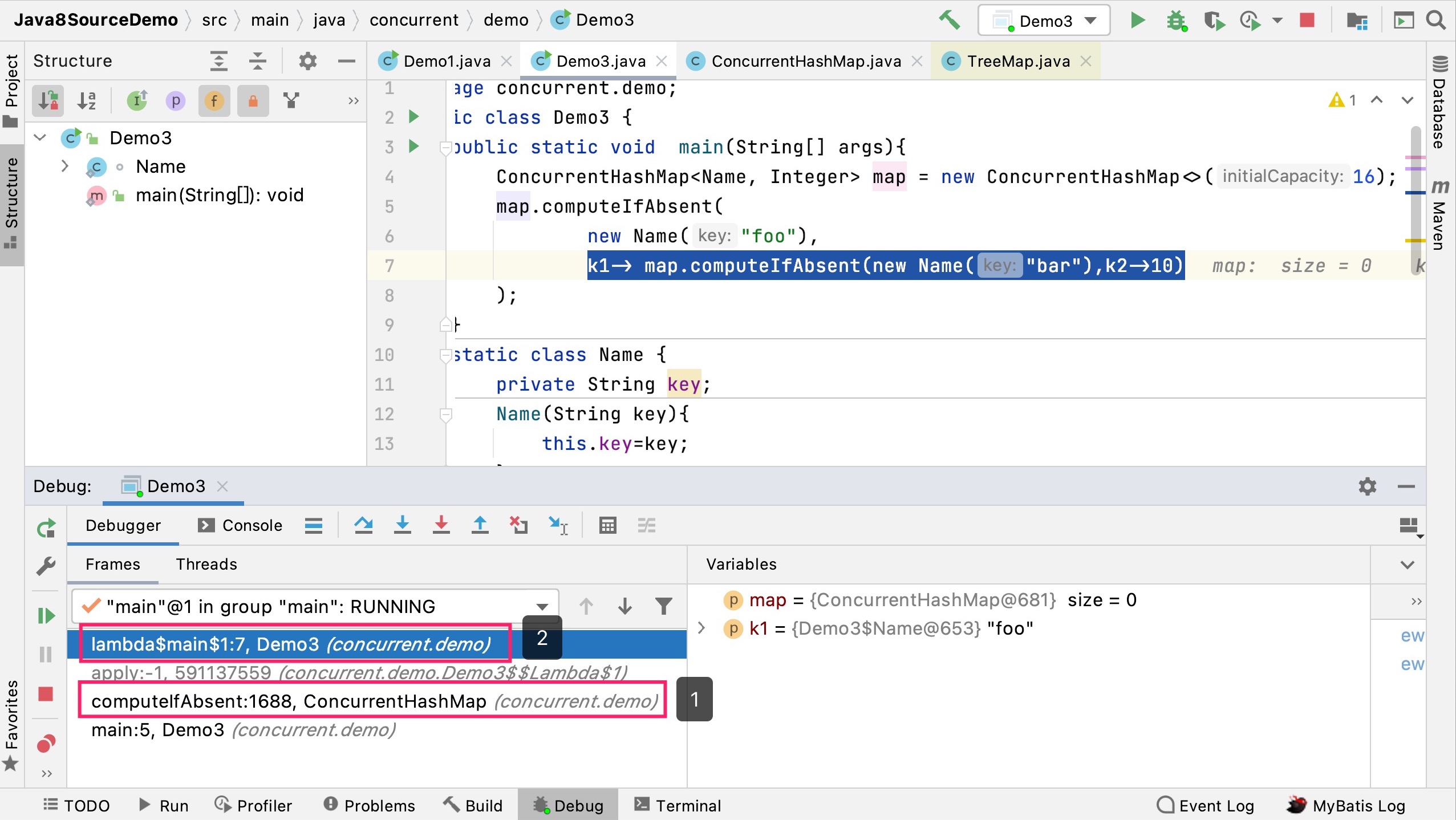
继续Step Into操作当然是再次进入computeIfAbsent方法内部,接下来,对于key为new Name("bar"),显然它也能定位到桶位1,接下来好办,进入for循环(自旋):
public V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) {if (key == null || remappingFunction == null)throw new NullPointerException();int h = spread(key.hashCode());V val = null;int delta = 0;int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;//① table已不为空,所以执行流不会进入此逻辑if (tab == null || (n = tab.length) == 0)tab = initTable();//② 执行第一次computeIfAbsent时,桶位1被放置了一个保留节点,因此桶位1不再为空,所以执行流不会进入此逻辑。注意注意:此桶位1还未放入new Name("foo")这个节点!因为new Name("foo")还在等new Name("bar")这个key计算valueelse if ((f = tabAt(tab, i = (n - 1) & h)) == null){}//③ 桶位1放的是一个保留节点ReservationNode,显然不是ForwardingNode节点,所以执行流不会进入此逻辑。else if ((fh = f.hash) == MOVED){}//④ 前面三个条件不满足,执行流最终会进入此逻辑,这里解析bug的关键逻辑!else {//4.1//4.2//4.3}
继续深入④逻辑:
//④ 前面三个条件不满足,执行流最终会进入此逻辑,这里解析bug的关键逻辑!else {boolean added = false;//对桶位上的头节点f加独占锁(这个f节点显然还是new Name("foo")放入的保留节点ReservationNode)synchronized (f) {if (tabAt(tab, i) == f) {//4.1 f是ReservationNode节点显然不是链表,所以执行流不会进入此逻辑if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek; V ev;if (e.hash == h &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {val = e.val;break;}Node<K,V> pred = e;if ((e = e.next) == null) {if ((val = mappingFunction.apply(key)) != null) {added = true;pred.next = new Node<K,V>(h, key, val, null);}break;}}}//4.2 f是ReservationNode节点,显然也不是TreeBin节点,所以执行流不会进入此逻辑else if (f instanceof TreeBin) {binCount = 2;TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> r, p;if ((r = t.root) != null &&(p = r.findTreeNode(h, key, null)) != null)val = p.val;else if ((val = mappingFunction.apply(key)) != null) {added = true;t.putTreeVal(h, key, val);}}}}//4.3 程序执行到这里发现都无法满足以上条件来放入new Name("bar")节这个节点,而new Name("foo")这个key又在等待new Name("bar")计算value的返回值,也即当前桶位还未放入这两个key节点,因此binCount还是初始值0,所以执行流不会进入此逻辑if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (!added)return val;break;}}//⑤ 执行流回到for循环继续,接下来就是一直死循环了
总结以上流程,用骨架代码解释死循环发生的过程:
对于new Name(“bar”)这个节点进入computeIfAbsent后,发生以下循环问题:
for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;//① table已不为空,所以执行流不会进入此逻辑if (tab == null || (n = tab.length) == 0)tab = initTable();//② 执行第一次computeIfAbsent时,该桶位已经是ReservationNode节点,所以执行流不会进入此逻辑!else if ((f = tabAt(tab, i = (n - 1) & h)) == null){}//③ f是ReservationNode节点不是fwd节点,所以执行流不会进入此逻辑else if ((fh = f.hash) == MOVED){}//④ 前面三个条件不满足,执行流最终会进入此逻辑,这里解析bug的关键逻辑!else {//4.1 f是ReservationNode节点不是链表,所以执行流不会进入此逻辑//4.2 f是ReservationNode节点不是TreeBin节点,所以执行流不会进入此逻辑//4.3 binCount还是初始值0,所以执行流不会进入此逻辑// 回到for循环:接下里即陷入死循环}
有没发现当准备为new Name(“bar”)节点找满足条件来插入节点时,发现for循环里面的7个条件(①、②、③、④、4.1、4.2、4.3))都不满足,那执行流接下里怎么办? 只能继续下一轮循环,下一轮循依旧出现7个条件都不满足只能再继续循环,因此进入了死循环陷阱。
本质原因是map写入节点的操作恰好同时满足以下两个条件:
(1)两个key定位到相同的桶位(hash冲突)
(2)一个key调用map.computeIfAbsent计算value的过程中又递归调用map.computeIfAbsent计算另外一个key的value
使用jstack定位死循环位置
既然已经掌握computeIfAbsent出现无限循环的原理,那么当发生无限循环时,可以使用jstack快速定位位置。
使用top -u 查看cpu使用率最高的进程号
~ top -u
PID COMMAND %CPU TIME #TH #WQ #PORTS MEM PURG CMPRS PGRP PPID STATE
40929 java 90.5 00:31.31 18/1 1 75 17M 0B 0B 8828 8828 running
再使用jps打印所有java进程执行,进程号40929对应的主类是Demo3,因此进程号40929就是目标处理对象
kevent@MacBookPro ~ jps
40928 Launcher
40929 Demo3
40967 Jps
8828
使用jstack打印40929进程里面的所有线程方法调用栈信息并输出文件中(把信息放在文本中方便查阅,否则直接在terminal打印不方便分析)
jstack -l 40929 > 40929.txt # -l选项表示长列表,会打印出更为详细关于锁的信息(如果有死锁被被监测到并打印出来)
如果程序fork了很多线程,还需要使用top -H -p pid来定位哪个线程的cpu使用率最高,然后再用线程号去jstack 输出文本里面grep到对应线程的调用栈信息。
打印出信息如下:
~ jstack -l 40929
Full thread dump OpenJDK 64-Bit Server VM (25.252-b09 mixed mode):# 省略其他输出"main" #1 prio=5 os_prio=31 tid=0x00007fc89300b000 nid=0x1003 runnable [0x0000700009038000]java.lang.Thread.State: RUNNABLEat concurrent.demo.ConcurrentHashMap.computeIfAbsent(ConcurrentHashMap.java:1747)at concurrent.demo.Demo3.lambda$main$1(Demo3.java:7)at concurrent.demo.Demo3$$Lambda$1/250421012.apply(Unknown Source)at concurrent.demo.ConcurrentHashMap.computeIfAbsent(ConcurrentHashMap.java:1688)- locked <0x0000000795864ea0> (a concurrent.demo.ConcurrentHashMap$ReservationNode)at concurrent.demo.Demo3.main(Demo3.java:5)Locked ownable synchronizers:- None
# 省略其他输出
Demo3执行后一直“卡着”并不会结束运行,上面显示main主线程,它的状态是RUNNABLE,这个正是说明当前Demo3一直在运行中没有结束。以下内容是主线程的方法调用栈,可以看到栈顶的computeIfAbsent方法
at concurrent.demo.ConcurrentHashMap.computeIfAbsent(ConcurrentHashMap.java:1747)at concurrent.demo.Demo3.lambda$main$1(Demo3.java:7)at concurrent.demo.Demo3$$Lambda$1/250421012.apply(Unknown Source)at concurrent.demo.ConcurrentHashMap.computeIfAbsent(ConcurrentHashMap.java:1688)- locked <0x0000000795864ea0> (a concurrent.demo.ConcurrentHashMap$ReservationNode)at concurrent.demo.Demo3.main(Demo3.java:5)
(ConcurrentHashMap.java:1747)信息很关键,它指出死循环发生在ConcurrentHashMap.java源代码文件的1747行,接着你可以在源代码文件相应位置加个打印语句System.out.println("dead loop");看看是否是这个是位置有死循环``,如下图所示:
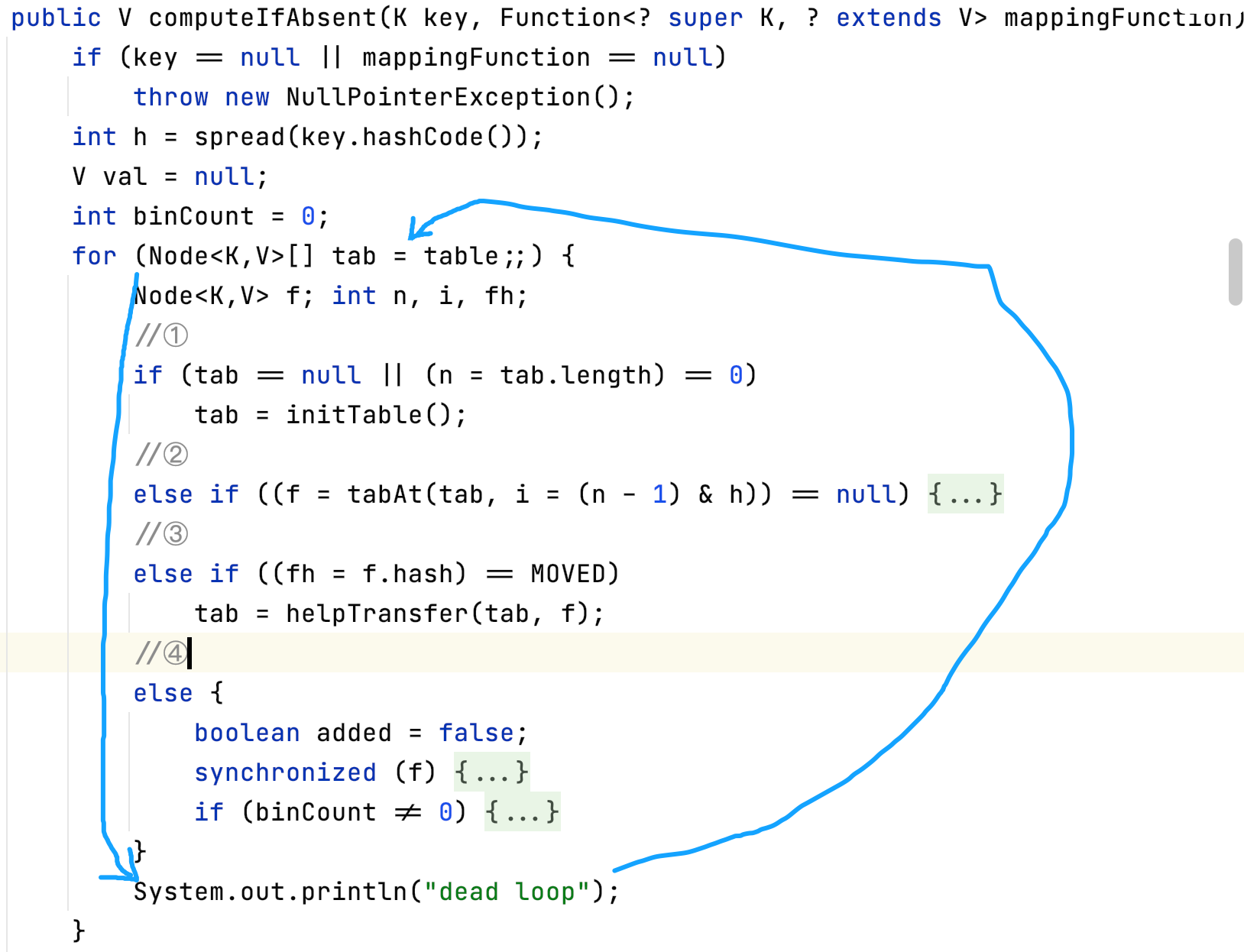
源代码能编辑的前提是你对IDEA的Sourcepath做了设置,至于如何设置,这些小trick不再说明。
再次执行Demo3时,则会一直打印dead loop,这种方式看起来也让其死循环行为更为直观。
openJDK官方的讨论过程
有了以上对computeIfAbsent全面的解析,则可以更好理解openJDK的官方讨论过程,参考此提交页面
1、Doug Lea added a comment - 2014-11-04 11:21
Doug Lea说自己没有一个好的方式去诊断CHM就此出现的问题,他猜测是否是线程在执行computing value逻辑时stuck住了,但从提交者的描述来看又无法确定这点。
I do not see a way to diagnose if there is a CHM problem here. The reservation mentioned may exist if some other thread is stuck while computing value, but there is no way to determine this from description.
你可以理解为Doug Lea对此bug暂无解决思路(未能在短时间内想起哪个逻辑出现问题),这是因为提交者首次提bug时没有附上“可复现bug的代码文件”,仅根据贴上的基本描述无法清晰指出问题所在。
Pardeep Sharma added a comment - 2014-12-03 03:58
Response from the submitter:
"I’ve been investigating the bug further in the mean time and I have a
minimal example (see attachment).The problem is that we’re doing a computeIfAbsent within another
computeIfAbsent with an object that has accidentally the same hashCode
(in the attached example “AaAa” and “BBBB” also have same hashCode).The documentation states that this is forbidden (mistake on our side)
but it also states that this should throw “IllegalStateException - if
the computation detectably attempts a recursive update to this map
that would otherwise never complete”. This is not the case.I would suggest that either
a) the documentation is adjusted to make it more clear that the
IllegalStateException is thrown on best effort basis.
or
b) the implementation is adjusted so that the IllegalStateException is
really thrown."
这部分内容很关键,提交者补充了准确的描述、修复意见和可复现bug的代码文件,补充的内容大概意思如下:
(1)bug产生的原因:map.computeIfAbsent里面的value再次调用computeIfAbsent,而且两个computeIfAbsent对应的key恰好hash冲突
(2)提出computeIfAbsent方法官方注释虽然提到禁止使用这种递归调用computeIfAbsent的用法,提交者认为更合理的方式是抛出:IllegalStateException
(3)提出源代码修复建议 a)注释里面尽可能对IllegalStateException抛出情况写清楚点 b)调整代码逻辑使得遇到此类情况可抛出IllegalStateException
3、Doug Lea added a comment - 2014-12-22 05:46
Ignore my previous comment. We discovered some feasible diagnostic improvements that cover more user errors involving recursive map updates by functions supplied in computeIfAbsent, including the case attached in this report.
Pending any further discussion on concurrency-interest, we should integrate to JDK9, then 8u.
在距离该bug提交时间(11-04)48天后(当然这里不是指Doug Lea每天思考该问题总共用了48天才找出如何解决),Doug Lea 终于搞懂bug的发生逻辑,也谦虚说忽略他之前给出的评论意见,说他们能找到问题的所在,并有该bug复现的case。提到之后如果有关于concurrency相关的讨论(修复)都应该优先在jdk9完成,然后再去处理jdk8u版本。
源代码修复说明
在这里不妨假设还是按照上面an endless loop章节在分析递归调用new Name("bar")的computeIfAbsent发生的循环逻辑,把整个执行流程放到以下修复后代码中去考察:
for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & h)) == null){}else if ((fh = f.hash) == MOVED){} else {boolean added = false;synchronized (f) {if (tabAt(tab, i) == f) {//4.1 f是ReservationNode节点不是链表,所以执行流不会进入此逻辑if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == h &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {val = e.val;break;}Node<K,V> pred = e;if ((e = e.next) == null) {if ((val = mappingFunction.apply(key)) != null) {// 新增的修复代码,链表这边也可能会出现递归调用,也需要直接抛出异常。为何这里也会出现if (pred.next != null)throw new IllegalStateException("Recursive update");added = true;pred.next = new Node<K,V>(h, key, val);}break;}}}//4.2 f是ReservationNode节点不是TreeBin节点,所以执行流不会进入此逻辑else if (f instanceof TreeBin) {binCount = 2;TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> r, p;if ((r = t.root) != null &&(p = r.findTreeNode(h, key, null)) != null)val = p.val;else if ((val = mappingFunction.apply(key)) != null) {added = true;t.putTreeVal(h, key, val);}}// 4.3 新增的修复代码// 在第一次computeIfAbsent执行时new Name("foo") 就是通过独占锁在桶位放置了一个ReservationNode然后等待new Name("bar") 的返回,而new Name("bar") 执行computeIfAbsent时来到相同桶位,此时桶位显然是一个ReservationNode,满足判断条件,故直接抛出异常使得线程终止运行,而不是继续下一轮遍历,解决了死循环。else if (f instanceof ReservationNode)throw new IllegalStateException("Recursive update");}
当然这种有递归更新操作的修复不单单只在computeIfAbsent方法修改,还有其他方法内部都需要修改,具体参考他们给出的修复前后diff链接。
Doug Lea除了修复这个死循环的问题,他还给出了一个提高computeIfAbsent性能的修复,修复前后diff连接
Improve already-present performance in computeIfAbsent, putIfAbsent
Revision 1.296 - (view) (annotate) - [selected]
Sun Jul 17 12:09:12 2016 UTC (5 years ago) by dl
Branch: MAIN
Changes since 1.295: +10 -2 lines
Diff to previous 1.295
其实也很简单,正如注释所说:check first node without acquiring lock,在无需加锁情况下,快速判断头节点是否和给定key相同,如相同则无须更新value,直接返回头节点原value。
//...else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else if (fh == h // check first node without acquiring lock&& ((fk = f.key) == key || (fk != null && key.equals(fk)))&& (fv = f.val) != null)return fv;else {boolean added = false;synchronized (f) {if (tabAt(tab, i) == f) {//...
有了以上全文内容的理解,再来回顾computeIfAbsent的源代码注释则能理解它要强调的重点!
/*** If the specified key is not already associated with a value,* attempts to compute its value using the given mapping function* and enters it into this map unless {@code null}. The entire* method invocation is performed atomically. The supplied* function is invoked exactly once per invocation of this method* if the key is absent, else not at all. (key不在map的情况下,给定的映射函数只会调用一次用来计算key对应的value)*Some attempted update operations on this map by other threads may be blocked while* computation is in progress, so the computation should be short* and simple.(给key调用映射函数计算value的过程中可能阻塞其他线程,因此这个“映射函数”的计算逻辑尽可能短、简单,例如key对应的value需要用10秒才计算完那么put这个key时显然会导致其他线程需要等待10秒才能继续后续写操作)** <p>The mapping function must not modify this map during computation.** @param key key with which the specified value is to be associated* @param mappingFunction the function to compute a value* @return the current (existing or computed) value associated with* the specified key, or null if the computed value is null* @throws NullPointerException if the specified key or mappingFunction* is null* @throws IllegalStateException if the computation detectably* attempts a recursive update to this map that would* otherwise never complete(抛出IllegalStateException就是修复的内容:如果检测到递归更新,如本文提供Demo3案例,则会抛出这个异常错误)* @throws RuntimeException or Error if the mappingFunction does so,* in which case the mapping is left unestablished*
掌握computeIfAbsent实现以及bug修复原理,你可以猜到HashMap、TreeMap、Hashtable等computeIfAbsent是如何处理吗?
这是一个陷阱式提问,显然HashMap、TreeMap、Hashtable的computeIfAbsent是不可能发生死循环,因为它们的computeIfAbsent源代码实现里面就不存在for循环(自旋)+CAS这套操作,而且HashMap、TreeMap这些也不是设计用于并发环境。
此外jdk1.8的ConcurrentHashMap的computeIfAbsent死循环的bug还引起阿里的分布式事务Seata框架发生同样的bug,文章为《ConcurrentHashMap导致的Seata死锁问题》,文章发布时间很新,2021年3月13日。写这篇深度分析文章的作者是Seata开发者之一,很不错,该文适合已经具有微服务下的分布式事务开发经验的同学研究。
One more thing
在“源代码修复diff说明”章节,代码修复只解释4.3新增的修复代码,眼尖的同学也许发现了4.1的链表也新增的修复代码而4.2的TreeBin里面确无需修改,这两部分的修复逻辑为何是这么处理呢?
讨论4.1位置指出的链表片段代码的修复思路
else {boolean added = false;synchronized (f) {if (tabAt(tab, i) == f) {//4.1 f是ReservationNode节点不是链表,所以执行流不会进入此逻辑if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == h &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {val = e.val;break;}Node<K,V> pred = e;if ((e = e.next) == null) {if ((val = mappingFunction.apply(key)) != null) {// 新增的修复代码,链表这边也可能会出现递归调用,也需要直接抛出异常。为何这里也会出现if (pred.next != null)throw new IllegalStateException("Recursive update");added = true;pred.next = new Node<K,V>(h, key, val);}break;}}}
首先应该可以猜到,既然Doug Lea 修复了它,说明链表里面肯定存在递归更新(且哈希冲突下的递归更新),但会出现类似ReservationNode的死循环bug吗?还是有其他不一样的情况?这里再次设计相关复现代码以解释之,Demo4如下:
package concurrent.demo;import java.util.concurrent.LinkedBlockingQueue;public class Demo4 {public static void main(String[] args){new LinkedBlockingQueue<>();ConcurrentHashMap<Name, Integer> map = new ConcurrentHashMap<>(16);map.put(new Name("a0"),1);map.put(new Name("a1"),2);map.computeIfAbsent(new Name("a2"),k1->map.computeIfAbsent(new Name("a3"),k2->k2.key.length()));System.out.println(map);}static class Name {private String key;Name(String key){this.key=key;}@Overridepublic int hashCode() {return 1;}@Overridepublic String toString(){return key;}}
}
以上预期打印结果:{a0=1,a1=2,a3=2,a2=2}
实际输出为:{a0=1, a1=2, a2=2}
原因分析如下图所示:

以上图示说明的是在链表中出现computeIfAbsent递归调用的bug并不会出现类似前面ReservationNode引起的死循环,而是出现“节点被覆盖”的bug,因此需要修复,修复的代码也很好处理:依据上图思路,在Time4时刻先判断此刻pred.next是否还是Time2时刻时的情况,即pred.next=null,如果不为空,说明在Time3时刻,递归调用了computeIfAbsent导致pred.next指向一个新增节点,出现了“inconsistent read”,这种情况很像mysql的“不可重复读”:
事务A在第一次读和第二次读的结果不一样,是因为在第一次和第二次读的中间时刻,有事务B对目标记录修改,导致事务A在一个事务内两次读到的数据不一样,也即不可重复读。
按这里的思路套入“上图中链表的不可重复读”:线程A第一次computeIfAbsent读取的pred.next为空,接着有线程A第一次computeIfAbsent内部再调用第二个computeIfAbsent对pred.next修改指向了一个非空新增节点,之后当线程A返回到执行第一次computeIfAbsent中断位置继续执行,发现第二次读取的pred.next不为空,那么线程A此时应该抛出异常,这就是Doug Lea对链表出现递归调用computeIfAbsent的修复策略,修复源代码片段如下:
Node<K,V> pred = e;if ((e = e.next) == null) { //这里可以看做是线程A第一次读取pred.next,显然此刻pred.next是指向nullif ((val = mappingFunction.apply(key)) != null) {// 新增的修复代码:线程A第二次读pred.next,如果此刻pred.next指向为null,说明本次computeIfAbsent内部没递归调用computeIfAbsent,是合法插入节点的操作,此时可以放心让pred.next指向新增节点if (pred.next != null)// 如果线程A第二次读pred.next不为空,说明本次computeIfAbsent递归调用computeIfAbsent,直接抛出IllegalStateExceptionthrow new IllegalStateException("Recursive update");// 线程A第二次读pred.next,如果此刻pred.next指向为null,说明本次computeIfAbsent内部没递归调用computeIfAbsent是合法插入节点的操作,此时可以放心让pred.next指向新增节点new Node。added = true;pred.next = new Node<K,V>(h, key, val);}break;}
多线程下的computeIfAbsent递归结果其实跟单线程一样,但肯定不会出现死循环,有余力的同学可以自行分析或者debug。
讨论4.2 位置TreeBin部分的修复思路
对比jdk1.8和jdk16的TreeBin片段前后,发现源代码无需修复,这是又是为何呢?
//4.2 f是ReservationNode节点不是TreeBin节点,所以执行流不会进入此逻辑else if (f instanceof TreeBin) {binCount = 2;TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> r, p;if ((r = t.root) != null &&(p = r.findTreeNode(h, key, null)) != null)val = p.val;else if ((val = mappingFunction.apply(key)) != null) {added = true;t.putTreeVal(h, key, val);}}//4.3 新增的修复,处理ReservationNode引起的死循环bugelse if (f instanceof ReservationNode)throw new IllegalStateException("Recursive update");}}
有了前面链表的分析积累,很好理解为何TreeBin无需担心递归更新带来的问题,因为它不会发生这样的bug,下面给出Demo5以及详细可理解的分析:
package concurrent.demo;
import java.util.concurrent.ConcurrentHashMap;
public class Demo5 {public static void main(String[] args) throws InterruptedException {ConcurrentHashMap<Name, Integer> map = new ConcurrentHashMap<>(16);// put64个节点触发扩容并会树化红黑树for(int i=0;i<64;i++){map.put(new Name("a"+i),i);}// 测试b2节点会不会像链表那边被b1节点覆盖map.computeIfAbsent(new Name("b1"),k1->map.computeIfAbsent(new Name("b2"),k2->k2.key.length()));System.out.println(map);}static class Name {private String key;Name(String key){this.key=key;}@Overridepublic int hashCode() {return 1;}@Overridepublic String toString(){return key;}}
}
详细图解:

小节
相信能读懂本文的同学,应该会受益匪浅,此外,网上也有coder能写出关于官方处理computeIfAbsent的修复过程解析,但他们基本停留在ReservationNode这一点上,而关于链表片段代码的修复以及红黑树部分片段维持不修复的本质原因却没有给出深度解读,这两点作为computeIfAbsent核心设计,肯定需要深挖为何如何修复或不修复的原因。


)



