哈喽,大家好,我是我不是小upper,
今天系统梳理了线性回归的核心知识,从模型的基本原理、参数估计方法,到模型评估指标与实际应用场景,帮助大家深入理解这一经典的机器学习算法,助力数据分析与预测工作。
非线性数据的回归处理方法解答
读者问:如果我的数据中的变量间关系不是线性的,是不是可以用多项式回归和变换方法,比如对数变换,但不太明白它们是如何应用的。
答:当数据中的变量关系呈现非线性特征时,传统的线性回归模型往往难以实现良好的数据拟合效果,此时多项式回归和变换方法就派上用场了,它们能够有效捕捉数据中的非线性关系。下面我详细为你介绍这两种方法的应用方式,你可以动手实践试试看。
1. 多项式回归
多项式回归是通过引入原始特征的高次幂项,对线性模型进行拓展,以此来描述数据间的非线性关系。例如,对于单个特征 x,除了考虑 x 本身,多项式回归还会纳入 、
等高次项;而对于多个特征
的多元情况,会包含如
、
、
等组合项 。
以一元二次多项式回归为例,其模型表达式为:
,其中 、
、
是待估计的参数,
是误差项;多元多项式回归(以两个特征
、
为例)的表达式可能为:
。
在应用多项式回归时,有 3 个关键要点需要注意:
- 防止过拟合:随着高次项的引入,模型的复杂度大幅增加,很容易出现过拟合现象,即模型在训练数据上表现良好,但在新数据上预测效果不佳。因此,在构建模型时,要谨慎选择多项式的次数,不能盲目追求高次项。
- 选择最佳次数:可以借助交叉验证或学习曲线来确定最合适的多项式次数。交叉验证通过将数据多次划分成训练集和验证集,综合评估不同次数下模型在验证集上的表现;学习曲线则展示随着训练数据量变化,模型在训练集和验证集上的性能变化趋势,帮助判断模型是否处于过拟合或欠拟合状态,从而选择合适的次数。
- 特征缩放:由于多项式回归中不同次幂的特征取值范围差异较大,在使用前通常需要对特征进行缩放处理,比如采用标准化(将特征转换为均值为 0,标准差为 1 的分布)或归一化(将特征值映射到 [0, 1] 区间)等方法,确保不同特征的尺度一致,这样有助于提升模型训练的稳定性和收敛速度。
2. 变换方法(以对数变换为例)
变换方法的核心思路是对原始数据进行特定的数学变换,使变换后的数据更符合线性关系,进而能够使用线性回归模型进行处理。对数变换是众多变换方法中较为常用的一种,尤其适用于数据呈现指数增长趋势的情况。
对数变换的具体操作是对原始数据 y 取对数,即 (这里的对数可以是自然对数
,也可以是以 10 为底的对数
,具体根据数据特点和需求选择)。经过对数变换后,原本指数增长的数据趋势会变得相对平缓,更接近线性关系。
在应用对数变换时,有 2 个要点需要关注:
- 对数变换的条件:对数函数的定义域是正数,所以对数变换仅适用于数据全部为正数的情况。如果数据中存在 0 或负数,需要先对数据进行适当的平移处理(例如加上一个正数,确保所有数据大于 0),再进行对数变换。此外,当数据呈现明显的指数增长趋势时,对数变换往往能取得较好的效果。
- 恢复变换后的预测值:在使用对数变换后,模型得到的预测值是变换后数据的预测结果,需要通过指数函数进行逆变换,才能得到原始数据尺度下的预测值,即
(如果之前是自然对数变换)。
注意点和建议
- 探索性数据分析(EDA):在决定使用多项式回归或变换方法之前,一定要先进行探索性数据分析。通过绘制散点图、箱线图、直方图等可视化图表,直观了解数据的分布形态、变量之间的关系以及是否存在异常值等特性,为后续选择合适的方法提供依据。
- 尝试不同方法:由于不同数据集的特点千差万别,处理非线性关系时,可以尝试多种方法,包括不同次数的多项式回归、不同类型的变换(如平方根变换、倒数变换等),然后通过对比模型在验证集上的性能指标(如均方误差、决定系数
等),选择最适合当前数据的方法。
- 注意异常值:异常值可能会对非线性关系的发现和模型拟合产生较大干扰。在建模之前,要仔细检查并处理异常值,可以采用统计方法(如 3 倍标准差法)识别异常值,然后根据实际情况选择删除异常值、修正异常值或者将其作为特殊数据单独处理。
- 模型评估:使用合适的评估指标(如均方误差、平均绝对误差、
总体而言,当数据呈现非线性关系时,多项式回归和变换方法是两种常见且有效的处理手段。但在实际应用中,需要根据数据特点谨慎选择,并进行充分的模型评估和调整。如果还有问题,欢迎在评论区继续探讨!
L1 和 L2 正则化的区别与应用解析
读者问:刚刚学习了 L1(LASSO)和 L2(岭回归)正则化,还是有点模糊其中的区别?它们是如何影响回归模型的?
大壮答:你好!L1 正则化(LASSO)和 L2 正则化(岭回归)都是回归模型中常用的正则化技术,它们的核心目的是通过对模型参数施加约束,防止模型过拟合,提升模型的泛化能力。下面我将详细介绍它们之间的区别,以及对回归模型的具体影响。
1. 区别
a. 正则化项的形式
- L1 正则化(LASSO):其正则化项是模型参数的绝对值之和,也就是 L1 范数,数学表达式为:
, 在损失函数中,最终的优化目标变为:
, 其中
是均方误差,
是正则化强度参数,用于控制正则化项对损失函数的影响程度。
- L2 正则化(岭回归):正则化项是模型参数平方和的平方根,即 L2 范数,表达式为:
, 在实际应用中,为了方便计算和优化,通常使用其平方形式,此时损失函数变为:
。
b. 特征选择
- L1 正则化(LASSO):具有独特的特征选择能力。在优化过程中,随着正则化强度
- L2 正则化(岭回归):一般不会将模型参数压缩到零,而是对所有参数进行均匀缩放。它通过减小参数的大小,降低模型对某些特征的依赖程度,但不会完全剔除某个特征,因此在处理特征间存在较强相关性(多重共线性)的问题时表现较好。
c. 解的稳定性
- L1 正则化(LASSO):由于其正则化项的形状(棱角分明),在某些情况下,解可能会不稳定。当数据或模型结构发生微小变化时,某些参数可能会突然从非零值变为零,导致模型结构发生较大改变,进而影响模型的稳定性和预测结果的一致性。
- L2 正则化(岭回归):对参数施加的是平滑约束,使得参数的变化更加连续和稳定。即使数据存在一定波动或模型结构略有调整,参数也不会发生剧烈变化,因此更容易得到稳定的解,在实际应用中表现出更好的稳健性。
2. 影响回归模型的方式
a. 参数收缩
- L1 正则化(LASSO):通过将部分不重要的参数缩小到零,实现了对模型参数的 “裁剪”,剔除了那些对预测结果贡献较小的特征,从而有效降低了模型的复杂度,避免模型过度拟合训练数据中的噪声和细节。
- L2 正则化(岭回归):对所有参数进行收缩,使它们的绝对值都变小,但不会完全消除某个参数。这种方式有助于在保留所有特征信息的同时,降低每个特征的权重,缓解多重共线性问题对模型的影响,使得模型在面对新数据时更加鲁棒。
b. 模型复杂度
- L1 正则化(LASSO):倾向于生成稀疏模型,当我们认为数据中只有少数关键特征对目标变量有实质性影响时,使用 L1 正则化可以自动筛选出这些重要特征,减少模型的冗余,降低模型复杂度,提高模型的可解释性。
- L2 正则化(岭回归):主要作用是平滑参数,通过对所有参数进行调整,使得模型在各个特征上的权重分布更加均衡。在特征间关联较强,且我们希望保留所有特征信息的情况下,岭回归能够有效控制模型复杂度,避免过拟合,同时保持模型的稳定性和预测性能。
3. 注意点和建议
- 超参数调整:正则化强度参数
- 问题特征:根据具体问题和数据的特征来选择合适的正则化方法。如果初步分析认为数据中存在大量冗余特征,且只有少数特征对目标变量起关键作用,那么 L1 正则化(LASSO)可能是更好的选择;而当特征间存在较强的相关性,且我们不确定哪些特征更重要,希望保留所有特征信息时,L2 正则化(岭回归)更为合适。
- 综合考虑:在一些复杂的实际问题中,还可以尝试同时使用 L1 和 L2 正则化,这种方法被称为弹性网络(Elastic Net)。弹性网络结合了 L1 和 L2 正则化的优点,既能够实现特征选择,又能处理多重共线性问题,在某些情况下可以取得比单独使用 L1 或 L2 正则化更好的效果。
总的来说,L1 和 L2 正则化都是回归模型中控制模型复杂度、提升模型泛化能力的有效工具。具体使用哪种方法,需要根据数据特点、问题需求以及模型评估结果进行综合判断。如果还有疑问,欢迎随时提问!
学习曲线和验证曲线在回归模型评估中的应用
读者问:这几天遇到一个问题,就是我应该如何使用学习曲线和验证曲线来评估我的回归模型?这些曲线能告诉我什么,以及我该如何根据它们来调整模型参数?
大壮答:你好!在回归模型的训练和优化过程中,学习曲线和验证曲线是非常实用的两种分析工具,它们能够帮助我们深入了解模型的性能,并为调整模型参数提供重要依据。下面我分别为你介绍这两种曲线的原理、能传达的信息,以及如何基于它们进行模型参数调整。
学习曲线
学习曲线是一种用于展示训练数据大小与模型性能之间关系的图表。在绘制学习曲线时,通常会在不同数量的训练数据上训练模型,并分别计算模型在训练集和验证集上的性能指标(如均方误差、决定系数 等),然后以训练数据量为横坐标,性能指标为纵坐标进行绘图。
学习曲线能告诉我们的信息
- 欠拟合:如果在学习曲线上,训练集和验证集的性能都较差,且随着训练数据量的增加,性能提升不明显,那么很可能是模型过于简单,无法捕捉数据中的复杂关系,处于欠拟合状态。这意味着模型对数据的拟合程度不足,不能很好地反映数据的真实规律,在训练数据和新数据上的预测效果都不理想。
- 过拟合:当训练集上的性能很好,但验证集上的性能较差,并且随着训练数据量的增加,两者之间的差距逐渐增大时,说明模型可能过于复杂,学习到了训练数据中的噪声和特定样本的细节,出现了过拟合现象。此时模型在训练数据上表现出色,但在面对新的测试数据时,由于无法泛化到其他数据分布,预测准确率会大幅下降。
- 合适的模型复杂度:理想情况下,当训练集和验证集上的性能随着训练数据量的增加逐渐趋于稳定,并且两者的差距较小,能够收敛到相近的水平时,说明我们找到了合适的模型复杂度。此时模型既能够充分学习数据的特征,又不会过度拟合,在新数据上具有较好的泛化能力。
如何根据学习曲线调整模型参数
- 欠拟合时:为了提高模型的拟合能力,可以尝试增加模型复杂度。例如,对于线性回归模型,可以引入多项式特征,将线性模型扩展为多项式回归模型;或者更换为更复杂的模型,如决策树回归、随机森林回归、支持向量机回归等,以增强模型对非线性关系的捕捉能力。
- 过拟合时:为了降低模型复杂度,缓解过拟合问题,可以采取多种措施。比如减少模型中的特征数量,通过特征选择方法(如 L1 正则化、相关性分析等)剔除那些对目标变量贡献较小或冗余的特征;增加正则化强度,对模型参数施加更严格的约束,防止参数过度拟合训练数据;或者选择更简单的模型结构,避免模型过于复杂。
验证曲线
验证曲线是用于分析模型性能与某一特定参数(例如正则化参数、多项式次数、学习率等)之间关系的图表。通过在不同的参数取值下训练和评估模型,得到对应的性能指标,然后以该参数值为横坐标,性能指标为纵坐标绘制曲线。
验证曲线能告诉我们的信息
- 最优参数取值:观察验证曲线的变化趋势,我们可以找到使模型在验证集上性能最优的参数取值。在曲线的最高点(对于越大越好的指标,如
- 过拟合和欠拟合:验证曲线也可以帮助我们检测模型是否处于过拟合或欠拟合状态。如果随着参数值的变化,验证集上的性能出现较大波动,例如在某些参数值下性能突然下降,可能是因为模型在这些参数设置下出现了过拟合或欠拟合现象。此外,如果训练集和验证集的性能差异较大,也可能暗示模型存在过拟合问题。
如何根据验证曲线调整模型参数
- 选择最优参数:根据验证曲线的走势,直接选取能够使验证集性能达到最佳的参数取值作为模型的最终参数设置。这样可以确保模型在当前数据和任务下具有最优的性能表现。
- 调整模型复杂度:如果验证曲线显示模型存在过拟合或欠拟合情况,可以结合具体的参数含义,相应地调整模型复杂度或正则化强度。例如,如果验证曲线是关于正则化参数的,当出现过拟合时,可以增大正则化参数,加强对模型参数的约束;当出现欠拟合时,可以减小正则化参数,让模型有更多的自由度去学习数据特征。
下面通过代码演示如何使用学习曲线和验证曲线来评估回归模型,并根据结果调整模型参数,这里以线性回归模型为例,使用 scikit-learn 库实现:
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import learning_curve, validation_curve# 生成随机回归数据
X, y = make_regression(n_samples=1000, n_features=20, noise=0.2, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义线性回归模型
estimator = LinearRegression()def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=None, train_sizes=np.linspace(.1, 1.0, 5)):plt.figure()plt.title(title)if ylim is not None: # 修复此处语法错误plt.ylim(*ylim)plt.xlabel("Training examples")plt.ylabel("Score")train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)train_scores_mean = np.mean(train_scores, axis=1)train_scores_std = np.std(train_scores, axis=1)test_scores_mean = np.mean(test_scores, axis=1)test_scores_std = np.std(test_scores, axis=1)plt.grid()plt.fill_between(train_sizes, train_scores_mean - train_scores_std,train_scores_mean + train_scores_std, alpha=0.1,color="r")plt.fill_between(train_sizes, test_scores_mean - test_scores_std,test_scores_mean + test_scores_std, alpha=0.1, color="g")plt.plot(train_sizes, train_scores_mean, 'o-', color="r",label="Training score")plt.plot(train_sizes, test_scores_mean, 'o-', color="g",label="Cross-validation score")plt.legend(loc="best")return pltdef plot_validation_curve(estimator, title, X, y, param_name, param_range, cv=None, scoring=None):train_scores, test_scores = validation_curve(estimator, X, y, param_name=param_name, param_range=param_range,cv=cv, scoring=scoring)train_scores_mean = np.mean(train_scores, axis=1)train_scores_std = np.std(train_scores, axis=1)test_scores_mean = np.mean(test_scores, axis=1)test_scores_std = np.std(test_scores, axis=1)plt.title(title)plt.xlabel(param_name)plt.ylabel("Score")plt.ylim(0.0, 1.1)lw = 2plt.plot(param_range, train_scores_mean, label="Training score",color="darkorange", lw=lw)plt.fill_between(param_range, train_scores_mean - train_scores_std,train_scores_mean + train_scores_std, alpha=0.2,color="darkorange", lw=lw)plt.plot(param_range, test_scores_mean, label="Cross-validation score",color="navy", lw=lw)plt.fill_between(param_range, test_scores_mean - test_scores_std,test_scores_mean + test_scores_std, alpha=0.2,color="navy", lw=lw)plt.legend(loc="best")return plt# 使用示例
plot_learning_curve(estimator, "Learning Curve", X_train, y_train, cv=5)
plt.show()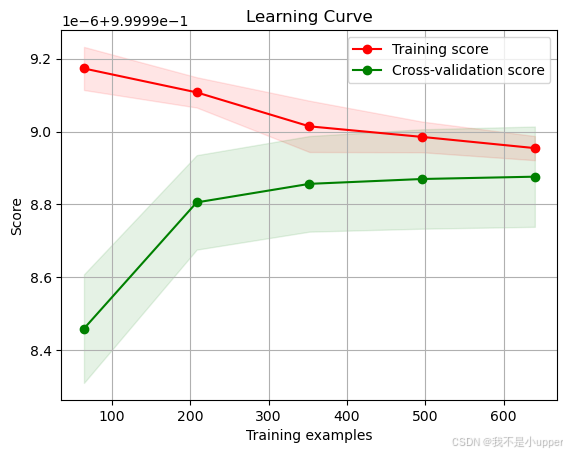
在这段代码中,我们首先定义了一个线性回归模型 LinearRegression(),然后将其传递给了 plot_learning_curve 函数。这样就可以成功绘制学习曲线了。
非线性回归模型的例子解析
读者问:,能给我一些非线性回归模型的例子吗?它们与线性回归主要不同点在哪里?
答:在数据分析与建模领域,当自变量和因变量之间的关系无法用直线(线性函数)准确描述,而是呈现曲线等复杂形态时,就需要借助非线性回归模型。下面我为你详细介绍几种常见的非线性回归模型,并深入对比它们与线性回归的差异。
1. 多项式回归
多项式回归通过引入自变量的高次幂拓展线性模型,打破了自变量幂次为 1 的限制。例如一元二次多项式回归模型表达式为:
;
若拓展到三次项,则变为
。
通过增加高次项,模型能拟合如抛物线、波浪线等复杂的非线性关系。与线性回归
相比,多项式回归具备刻画曲线趋势的能力,可用于模拟商品价格随时间先升后降、植物生长速度随周期变化等场景。
2. 指数回归
指数回归采用指数函数 (a、b 为参数,e 是自然常数) 构建模型,适用于描述因变量随自变量呈指数增长或衰减的现象。比如在研究细菌繁殖时,细菌数量会随时间呈指数增长;放射性物质的衰变过程,其剩余质量随时间呈指数衰减。这种模型通过指数函数的特性,精准捕捉数据在不同阶段的快速变化趋势,与线性回归均匀变化的趋势形成鲜明对比。
3. 对数回归
对数回归通过对自变量或因变量取对数实现非线性建模,常见形式有
或 。
当数据呈现指数增长或衰减趋势,且希望压缩数据跨度、使数据分布更均匀时,对数变换能将其转化为线性或更易处理的形式。例如在经济学中,描述收入与消费的关系,随着收入增加,消费增长速度逐渐放缓,对数回归可有效拟合这种非线性关系,而线性回归在此场景下则难以准确刻画。
4. 广义可加模型(Generalized Additive Models, GAM)
GAM 是一种高度灵活的非线性回归模型,表达式为:
。
其中, 是非线性函数,通常采用平滑的样条函数等形式,可根据数据特点自适应调整形状。GAM 不仅能处理单个自变量的非线性关系,还能综合多个自变量的非线性效应,适用于复杂多因素影响的场景,如分析气候因素(温度、湿度、风速等)对农作物产量的影响 。相比之下,线性回归要求自变量和因变量呈线性组合关系,难以应对此类复杂的非线性交互。
非线性回归与线性回归的核心差异
线性回归基于自变量和因变量呈线性关系的假设,模型形式简单,解释性强,但在面对现实世界中广泛存在的曲线趋势、指数变化、复杂交互等数据时,拟合效果欠佳。而非线性回归模型通过引入多项式、指数函数、对数变换或灵活的非线性函数,极大拓展了模型对复杂数据关系的刻画能力,能更精准地描述数据内在规律。不过,这种灵活性也带来弊端:一方面,模型结构复杂,计算复杂度增加,训练耗时更长;另一方面,参数解释难度加大,模型的可解释性变弱,且存在过拟合风险,需要更精细的模型评估与调优。
多项式回归代码演示
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures# 生成带噪声的非线性数据
np.random.seed(0)
X = np.linspace(-3, 3, 100)
y = 2 * X**3 - 3 * X**2 + 4 * X - 5 + np.random.normal(0, 10, 100)# 将 X 转换成矩阵形式
X = X[:, np.newaxis]# 使用多项式特征进行变换
poly = PolynomialFeatures(degree=3)
X_poly = poly.fit_transform(X)# 构建并拟合多项式回归模型
model = LinearRegression()
model.fit(X_poly, y)# 绘制原始数据和拟合曲线
plt.scatter(X, y, color='blue')
plt.plot(X, model.predict(X_poly), color='red')
plt.title('Polynomial Regression')
plt.xlabel('X')
plt.ylabel('y')
plt.show()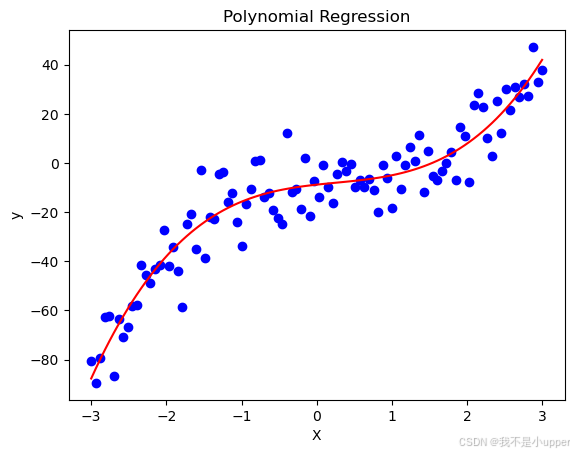
上述代码先生成包含三次函数趋势与随机噪声的非线性数据,随后借助 PolynomialFeatures 将原始自变量 X 转换为包含一次、二次、三次项的多项式特征矩阵。基于此,使用
LinearRegression 拟合多项式回归模型,并绘制原始数据散点图与拟合曲线。从图像中可直观看到,多项式回归模型能够较好地捕捉数据的非线性趋势,而普通线性回归难以实现如此精准的拟合效果,这也凸显了非线性回归模型在处理复杂数据关系时的独特优势。
自相关性详解
读者问:我看到关于自相关性的描述,但不太明白时间序列数据中的自相关是什么意思。如果我的数据存在自相关,会对我的模型造成什么影响?有没有简单的方法可以检测和处理自相关性?
大壮答:你好!时间序列数据中的自相关性是一个核心概念,许多实际问题都与之紧密相关。后续我会专门出一期内容系统讲解时间序列分析,今天先聚焦自相关性。
自相关性,简单来说,指的是同一变量在时间序列中不同时间点的观测值之间的关联程度。例如,今天的气温与昨天、前天的气温存在关联,股票今日收盘价与过去几日的价格存在某种趋势联系,这些都是自相关的体现。通过分析自相关性,我们可以挖掘数据中的周期性(如每日、每月的规律波动)或趋势性(如逐年增长或下降),这对预测未来数据至关重要。
然而,自相关性会给回归模型带来挑战。线性回归模型的一个基本假设是残差(预测值与真实值的差值)相互独立,即不同时间点的误差之间不存在关联。但当数据存在自相关时,残差会呈现出某种规律(例如连续多个正残差或负残差),导致残差不再独立。这会引发一系列问题:
- 参数估计偏差:模型可能错误地将自相关的影响归因于自变量,导致系数估计不准确;
- 预测失效:模型无法有效捕捉数据的真实波动,预测结果的误差增大;
- 模型评估失效:传统的统计检验(如显著性检验)结果可能失去可靠性,无法真实反映模型性能。
在实际分析中,我们可以通过以下 4 种方法检测和处理自相关性:
- 自相关函数(ACF)与偏自相关函数(PACF):通过绘制 ACF 和 PACF 图,直观展示不同时间间隔下数据的相关性。ACF 衡量所有滞后阶数的总相关性,而 PACF 剔除中间阶数的影响,仅显示当前阶数的直接相关性。这些图能帮助我们判断时间序列的阶数,进而选择合适的自回归(AR)或移动平均(MA)模型。
- 差分法:对时间序列进行一阶或多阶差分(即计算相邻时间点的差值),可有效消除趋势和季节性,使数据更平稳,从而减弱自相关性。例如,一阶差分公式为:
。
- 自回归移动平均模型(ARMA):结合自回归(AR)和移动平均(MA)两种机制,直接建模自相关性。AR 项描述当前值与过去值的关系,MA 项描述当前值与过去误差的关系,二者结合可精准刻画时间序列的动态特征。
- 自回归积分移动平均模型(ARIMA):在 ARMA 基础上加入差分操作,专门处理非平稳时间序列。通过 “差分→拟合 ARMA→逆差分” 的流程,既能消除自相关性,又能保留数据的原始趋势和特征。
下面通过代码演示差分法处理自相关性的过程:
import torch
import numpy as np
import matplotlib.pyplot as plt# 生成示例时间序列数据
np.random.seed(0)
n = 100
t = np.arange(n)
y = 0.5 * t + 0.3 * np.sin(0.1 * t) + np.random.normal(0, 1, n)# 绘制原始时间序列图
plt.figure(figsize=(10, 4))
plt.plot(t, y, label='Original Time Series')
plt.xlabel('Time')
plt.ylabel('Value')
plt.title('Original Time Series Data')
plt.legend()
plt.grid(True)
plt.show()# 计算一阶差分
diff_y = np.diff(y)# 绘制一阶差分后的时间序列图
plt.figure(figsize=(10, 4))
plt.plot(t[1:], diff_y, label='First Difference')
plt.xlabel('Time')
plt.ylabel('Value')
plt.title('First Difference Time Series Data')
plt.legend()
plt.grid(True)
plt.show()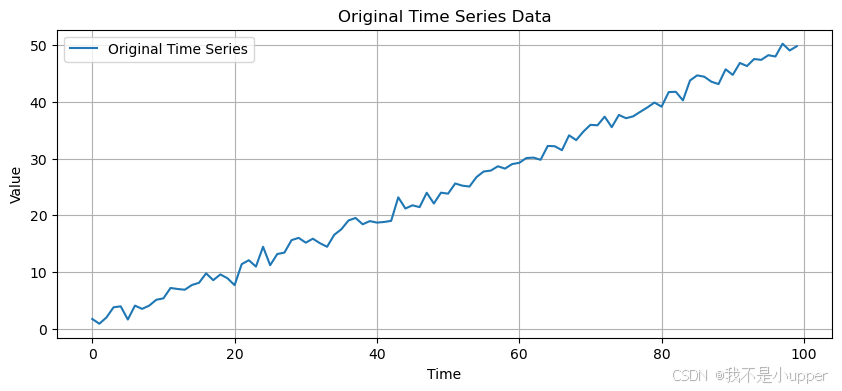
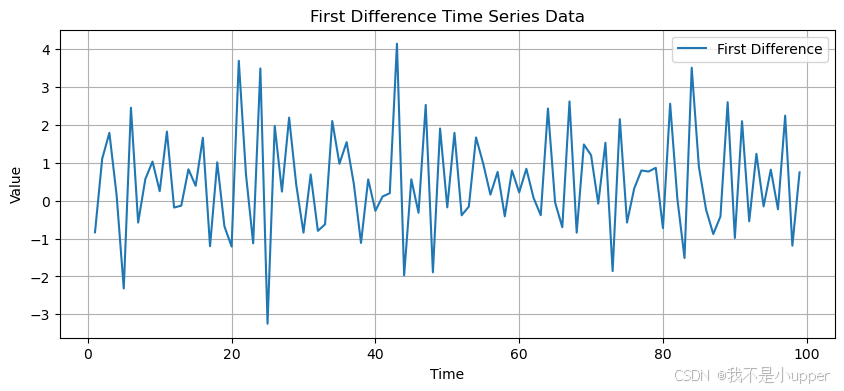
上述代码中,我们首先生成了一条包含线性趋势、周期性波动和随机噪声的时间序列数据。从原始序列图中可以观察到明显的上升趋势和周期性正弦波动,这些特征可能导致数据存在自相关。
随后,通过计算一阶差分(np.diff(y)),我们得到相邻时间点的差值。对比前后图像可以发现,差分后的数据趋势消失,波动更加平稳,自相关性显著减弱。这验证了差分法在去除时间序列趋势、降低自相关性上的有效性。在实际应用中,可根据数据特点选择更高阶的差分,或结合其他方法进一步优化模型性能。



