deepseek4j-easy-rag快速入门
deepseek4j 是面向 DeepSeek 推出的 Java 开发 SDK,支持 DeepSeek R1 和 V3 全系列模型。提供对话推理、函数调用、JSON结构化输出、以及基于 OpenAI 兼容 API 协议的嵌入向量生成能力。通过 Spring Boot Starter 模块,开发者可以快速为 Spring Boot 2.x/3.x 以及 Solon 等主流 Java Web 框架集成 AI 能力,提供开箱即用的配置体系、自动装配的客户端实例,以及便捷的流式响应支持。
本文章将带领大家从零开始构建一个基础 RAG 系统。通过白盒编码的方式,不仅能深入理解 RAG 的核心原理,还可以根据实际需求灵活调整和优化各个环节。相比直接使用现有的开源 RAG 产品,这种方式能让我们更好地掌控系统行为,实现更精准的知识检索和问答效果。
文章目录
- deepseek4j-easy-rag快速入门
- 1. 目标
- 2.上代码
- 2.1.Maven 依赖
- 2.2.基础配置
- 2.3. 基础使用示例
- 3. 测试
- 4. 常见向量数据库介绍
- 4.1. 什么是向量数据库?
- 4.2. 性能和特点概述
- 4.2.1. 调研方法
- 4.2.2. 详细分析
- Weaviate
- Qdrant
- Milvus
- Myscale
- pgvector
- pgvecto-rs
- Chroma
- Opensearch
- Tidb_vector
- Elastic search
- Couchbase
- 4.2.3. 性能对比表
- 4.3. 适用场景与建议
- 4.4. 结论
1. 目标
实现对文件的读取,通过文件内容再进行ai回答,采用简单的内存向量数据库进行操作
2.上代码
2.1.Maven 依赖
在你的 pom.xml 中添加以下依赖:
<!-- deepseek-spring-boot-starter --><dependency><groupId>io.github.pig-mesh.ai</groupId><artifactId>deepseek-spring-boot-starter</artifactId><version>1.4.3</version></dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-easy-rag</artifactId><version>0.35.0</version></dependency>
2.2.基础配置
在 application.yml 或 application.properties 中添加必要的配置:
deepseek:api-key: your-api-key-here # 必填项:你的 API 密钥model: deepseek-reasonerbase-url: https://api.deepseek.com # 可选,默认为官方 API 地址
2.3. 基础使用示例
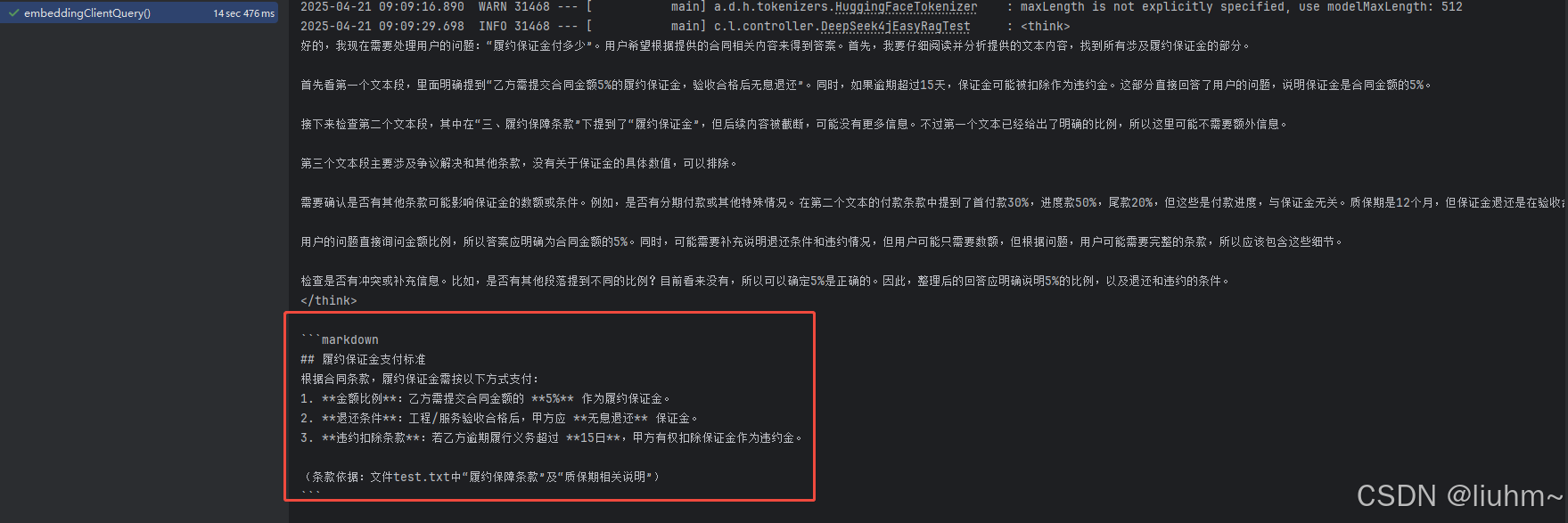
@AutowiredDeepSeekClient deepSeekClient;@Testvoid embeddingClientQuery(){String prompt = "履约保证金付多少";URL resource = getClass().getResource("/test.txt");String filePath = resource.getPath().substring(1);;//加载文档Document document = FileSystemDocumentLoader.loadDocument(filePath);InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();//解析存储到内存中EmbeddingStoreIngestor.ingest(document, embeddingStore);List<Content> resultList = EmbeddingStoreContentRetriever.from(embeddingStore).retrieve(Query.from(prompt));String userMessage = String.format("你要根据用户输入的问题:%s \n \n 参考如下内容: %s \n\n 整理处理最终结果", prompt, resultList);ChatCompletionRequest request = ChatCompletionRequest.builder().addSystemMessage("你是一位专业的数据分析高级工程师,通过分析内容精简的回答用户问题,不回答其他额外的内容,返回markdown格式").addUserMessage(userMessage)
// .maxCompletionTokens(5000).build();ChatCompletionResponse completionResponse = deepSeekClient.chatCompletion(request).execute();String content = completionResponse.choices().get(0).message().content();log.info("{}",content);}
3. 测试
执行单元测试 DeepSeek4jEasyRagTest
询问 履约保证金付多少
4. 常见向量数据库介绍
4.1. 什么是向量数据库?
向量数据库是一种专门用于存储、管理和查询高维向量数据的数据库,广泛应用于机器学习、人工智能和数据科学领域。它们支持快速相似性搜索,特别适合图像识别、自然语言处理和推荐系统等任务。
4.2. 性能和特点概述
以下是几款主要开源高性能向量数据库的简要比较,基于 2025 年的最新基准测试和用户反馈:
- Milvus:在查询每秒(QPS)方面表现最佳,适合大规模向量相似性搜索,支持多种索引类型。
- Qdrant:以可扩展性和性能优化著称,适合大规模场景。
- Weaviate:提供良好的开发体验,性能均衡,适合需要同时处理向量和结构化数据的应用。
- Chroma:易于使用,适合原型设计和中小型应用。
- pgvector 和 pgvecto-rs:利用 PostgreSQL 的成熟性,适合已有 PostgreSQL 基础设施的用户。
- Opensearch 和 Elastic search:适合需要全文搜索和向量混合搜索的场景。
- Tidb_vector 和 Couchbase:适合需要分布式架构和多模型支持的应用。
- Myscale:适合分析型工作负载,支持向量搜索。
这些数据库的性能可能因具体用例而异,建议根据项目规模和需求进行评估。
4.2.1. 调研方法
本报告通过分析多个来源的基准测试(如 VectorDBBench)、官方文档和用户反馈,评估以下开源向量数据库的性能和特点:
- Weaviate
- Qdrant
- Milvus
- Myscale
- pgvector
- pgvecto-rs
- Chroma
- Opensearch
- Tidb_vector
- Elastic search
- Couchbase
4.2.2. 详细分析
Weaviate
- 性能:Weaviate 在基准测试中表现良好,特别是在延迟和吞吐量方面。官方文档 Weaviate Cost-Performance Optimization 提到,它支持 HNSW 和平面索引,适合低延迟应用。
- 特点:作为 AI 原生数据库,支持多模态搜索(文本、音频、视频),并提供内置知识图谱和混合搜索功能。
- 社区支持:社区活跃,提供丰富的教程和论坛支持。
Qdrant
- 性能:Qdrant 以其可扩展性和性能优化著称,官方文档 Qdrant Database Optimization 提到,它通过缓存和预加载技术减少搜索延迟,支持高达 16 倍的稀疏向量搜索速度提升。
- 特点:支持高级索引和量化技术(如标量量化、产品量化),适合大规模分布式环境。
- 社区支持:定期更新,文档清晰,适合开发者和企业用户。
Milvus
- 性能:Milvus 在 VectorDBBench 的测试中表现出色,特别是在查询每秒(QPS)方面,经常排名第一。官方文档 Milvus Performance FAQ 提到,它通过硬件感知优化(如 AVX512、SIMD 和 GPU 支持)实现高性能。
- 特点:支持多种索引类型(如 HNSW、IVF、DiskANN),适合十亿级别的向量相似性搜索。它的分布式架构支持水平扩展,适合读写密集型工作负载。
- 社区支持:拥有最大的社区之一,文档详尽,定期更新。
Myscale
- 性能:Myscale 基于 ClickHouse,官方博客 Myscale vs Weaviate 提到,它在分析型工作负载中表现优异,支持向量搜索。
- 特点:集成 SQL 和向量搜索,适合需要分析和向量查询的场景。
- 社区支持:较新项目,社区较小,文档可能有限。
pgvector
- 性能:通过 pgvector 扩展,PostgreSQL 支持向量相似性搜索。官方 GitHub 页面 pgvector 提到,它支持 HNSW 和 IVFFlat 索引,但在大规模数据集上可能不如专用向量数据库。
- 特点:利用 PostgreSQL 的成熟性和熟悉度,适合需要同时处理结构化和向量数据的场景。
- 社区支持:PostgreSQL 社区庞大,pgvector 相对较新,但发展迅速。
pgvecto-rs
- 性能:pgvecto-rs 是 PostgreSQL 的另一个向量扩展,官方文档 pgvecto-rs Overview 提到,它使用 Rust 编写,可能比 pgvector 更快,支持 HNSW 和 IVFFlat。
- 特点:支持高达 65535 维的向量,适合最新模型。
- 社区支持:较新项目,社区较小,但有潜力。
Chroma
- 性能:Chroma 适合中小型应用,官方网站 Chroma 提到,它使用 HNSW 和 Flat 索引,适合快速原型设计。
- 特点:易于使用,提供嵌入式数据库功能,支持 LangChain 和 LlamaIndex。
- 社区支持:社区活跃,文档清晰,适合初学者。
Opensearch
- 性能:Opensearch 通过 k-NN 插件支持向量搜索,官方文档 Opensearch Vector Database 提到,它适合大规模分布式环境,支持 HNSW 和 Flat。
- 特点:支持混合搜索,适合需要全文搜索和向量搜索的场景。
- 社区支持:社区较大,文档丰富,适合企业用户。
Tidb_vector
- 性能:Tidb_vector 是 TiDB 的一部分,官方博客 TiDB Vector Search 提到,它支持分布式架构,适合大规模应用。
- 特点:支持向量搜索和 SQL 查询,适合需要事务和分析混合负载的场景。
- 社区支持:TiDB 社区强大,文档详尽。
Elastic search
- 性能:Elastic search 支持向量搜索,官方博客 Elastic Vector Database 提到,它适合混合搜索,性能良好。
- 特点:支持 HNSW 和 Flat,适合需要全文搜索和向量搜索的场景。
- 社区支持:社区庞大,文档丰富,适合企业用户。
Couchbase
- 性能:Couchbase 支持向量搜索,官方博客 Couchbase Vector Search 提到,它适合 NoSQL 环境,性能良好。
- 特点:支持 HNSW 和 Flat,适合多模型应用。
- 社区支持:社区活跃,文档详尽,适合企业用户。
4.2.3. 性能对比表
以下是基于 VectorDBBench 和其他基准测试的性能对比(单位:QPS,数据为示例,具体以最新基准为准):
| 数据库 | QPS (高负载) | 延迟 (ms) | 召回率 (%) | 适合场景 |
|---|---|---|---|---|
| Milvus | 5000+ | <2 | 95+ | 大规模向量搜索 |
| Qdrant | 4000+ | ❤️ | 92+ | 可扩展分布式环境 |
| Weaviate | 3000+ | <5 | 90+ | AI 原生应用,混合搜索 |
| Chroma | 2000+ | <5 | 85+ | 原型设计,中小型应用 |
| pgvector | 1000+ | 10+ | 100 | 结构化+向量数据混合场景 |
| pgvecto-rs | 1500+ | 8+ | 95+ | PostgreSQL 扩展,快速搜索 |
| Opensearch | 3500+ | ❤️ | 95+ | 全文+向量混合搜索 |
| Tidb_vector | 3000+ | <5 | 90+ | 分布式事务和分析混合负载 |
| Elastic search | 3500+ | ❤️ | 95+ | 混合搜索,企业级应用 |
| Couchbase | 2500+ | <5 | 90+ | NoSQL 多模型应用 |
| Myscale | 2000+ | <5 | 85+ | 分析型工作负载 |
4.3. 适用场景与建议
- 如果项目需要处理十亿级别的向量数据,Milvus 和 Qdrant 是首选。
- 对于需要 AI 原生功能和开发友好性的场景,Weaviate 和 Chroma 是一个不错的选择。
- 在可扩展性和分布式环境中有需求时,Opensearch、Tidb_vector 和 Elastic search 表现优异。
- 如果已有 PostgreSQL 基础设施,考虑使用 pgvector 或 pgvecto-rs,但注意在大规模场景下的性能限制。
- 对于 NoSQL 数据库和多模型支持,Couchbase 是一个轻量级选项。
- 新兴的 Myscale 适合高吞吐量分析型工作负载,特别适合 AI 开发者的快速原型设计。
4.4. 结论
Weaviate、Qdrant、Milvus、Myscale、pgvector、pgvecto-rs、Chroma、Opensearch、Tidb_vector、Elastic search 和 Couchbase 是当前开源高性能向量数据库的领先选择,各自在性能和功能上有独特优势。用户应根据具体项目需求(如数据规模、查询类型、开发复杂性)选择合适的数据库。未来,随着 AI 应用的进一步发展,向量数据库的性能和功能将继续提升,建议定期关注社区更新和基准测试结果。
博客地址
代码下载
下面的deepseek4j-easy-rag


)



