本节重点介绍 :
- 5大数据查询接口
- instant_query查询一个点
- range_query查询一段时间数据
- series查询 全量标签数据
- labels查询 标签key集合
- label values查询
5大数据查询接口
instant_query查询
- 对应uri为
/api/v1/query - 报警使⽤、预聚合、当前点查询(table)
- 可以用来调用监控数据生成报表
python脚本
import json
import timeimport requests
import logginglogging.basicConfig(format='%(asctime)s %(levelname)s %(filename)s [func:%(funcName)s] [line:%(lineno)d]:%(message)s',datefmt="%Y-%m-%d %H:%M:%S",level="INFO"
)def ins_query(host,expr="node_disk_reads_merged_total"):start_ts = time.perf_counter()uri="http://{}/api/v1/query".format(host)g_parms = {"query": expr,}res = requests.get(uri, g_parms)if res.status_code!=200:msg = "[error_code_not_200]"logging.error(msg)returnjd = res.json()if not jd:msg = "[error_loads_json]"logging.error(msg)returninner_d = jd.get("data")if not inner_d:returnresult = inner_d.get("result")result_series = len(result)end_ts = time.perf_counter()for index,x in enumerate(result):msg = "[series:{}/{}][metric:{}]".format(index+1,result_series,json.dumps(x.get("metric"),indent=4))logging.info(msg)msg = "Load time: {} Resolution: {}s Result series: {}".format(end_ts-start_ts,15,result_series)logging.info(msg)
if __name__ == '__main__':ins_query("192.168.0.106:9090",expr='''max(rate(node_network_receive_bytes_total{origin_prometheus=~"",job=~"node_exporter"}[2m])*8) by (instance)''')
源码
- 首先解析时间,意思是可以查询之前的一个时间戳的数据,默认我们不指定,由前端拿当前时间做为参数
- 用 传入的ql参数初始化 NewInstantQuery,同时判断错误
- 主要是判断用户传入的ql是否正确
- api.Queryable是merge的stroage ,本地或者还有remote的
-
qry, err := api.QueryEngine.NewInstantQuery(api.Queryable, r.FormValue("query"), ts)if err == promql.ErrValidationAtModifierDisabled {err = errors.New("@ modifier is disabled, use --enable-feature=promql-at-modifier to enable it")} else if err == promql.ErrValidationNegativeOffsetDisabled {err = errors.New("negative offset is disabled, use --enable-feature=promql-negative-offset to enable it")}if err != nil {return invalidParamError(err, "query")}
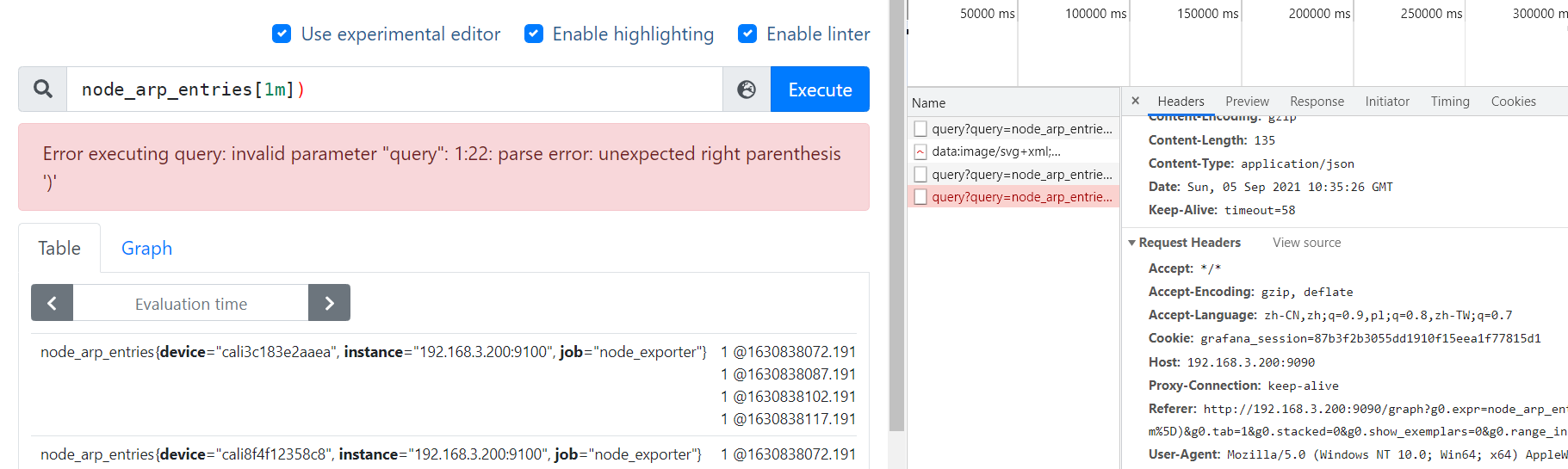
- 调用exec执行查询
-
res := qry.Exec(ctx)if res.Err != nil {return apiFuncResult{nil, returnAPIError(res.Err), res.Warnings, qry.Close}}// Optional stats field in response if parameter "stats" is not empty.var qs *stats.QueryStatsif r.FormValue("stats") != "" {qs = stats.NewQueryStats(qry.Stats())}return apiFuncResult{&queryData{ResultType: res.Value.Type(),Result: res.Value,Stats: qs,}, nil, res.Warnings, qry.Close}
range_query查询
- 对应uri为
/api/v1/query_range - 查询⼀段时间的曲线
- 可以用来调用监控数据生成报表
- 模拟prometheus页面打印的结果
2021-05-03 09:06:55 INFO 001_range_query.py [func:ins_query] [line:51]:[series:1/2][metric:{"__name__": "node_load1","instance": "192.168.43.114:9100","job": "node_exporter"
}]
2021-05-03 09:06:55 INFO 001_range_query.py [func:ins_query] [line:51]:[series:2/2][metric:{"__name__": "node_load1","instance": "192.168.43.2:9100","job": "node_exporter"
}]
2021-05-03 09:06:55 INFO 001_range_query.py [func:ins_query] [line:57]:Load time: 0.006407099999999999 Resolution: 30s Result series: 2源码解读
-
queryRange 位置 F:\go_path\src\github.com\prometheus\prometheus\web\api\v1\api.go
-
首先解析时间参数
- 解析start 和end时间,start必须要在end前面
- 解析分辨率参数,要求 时间差/分辨率 不能大于11000,目的是防止返回的点数过多
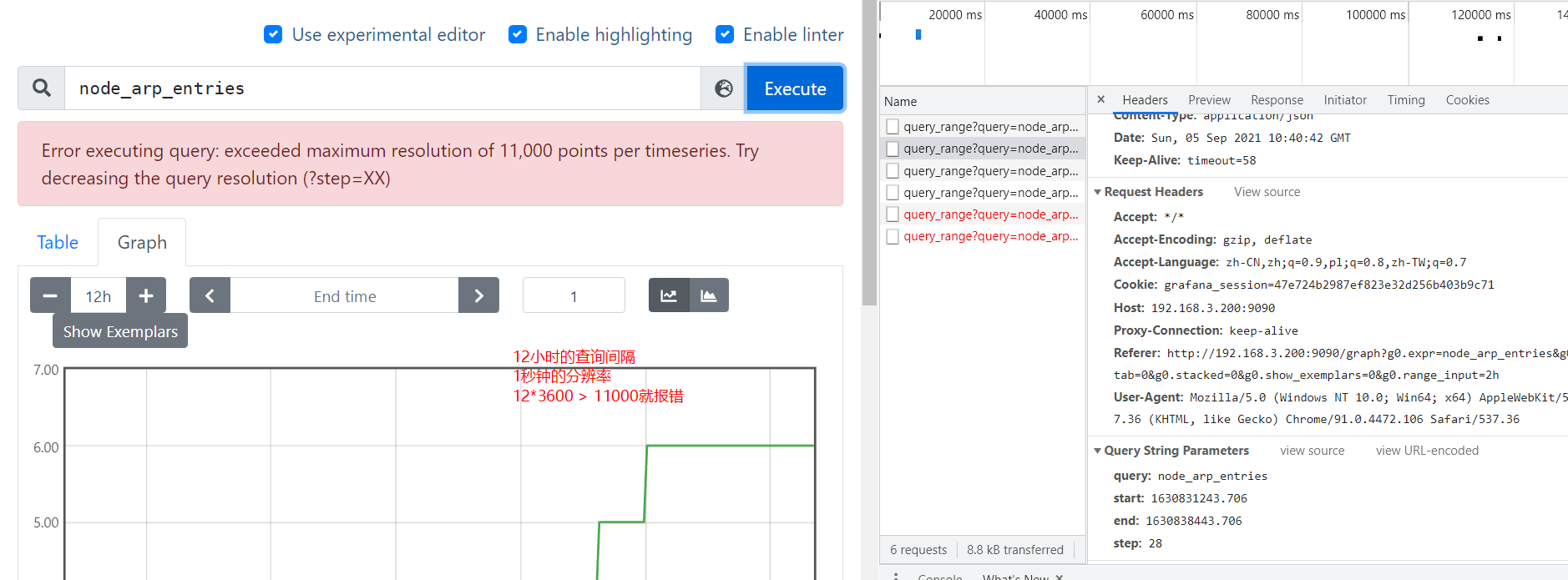
-
start, err := parseTime(r.FormValue("start"))if err != nil {return invalidParamError(err, "start")}end, err := parseTime(r.FormValue("end"))if err != nil {return invalidParamError(err, "end")}if end.Before(start) {return invalidParamError(errors.New("end timestamp must not be before start time"), "end")}step, err := parseDuration(r.FormValue("step"))if err != nil {return invalidParamError(err, "step")}if step <= 0 {return invalidParamError(errors.New("zero or negative query resolution step widths are not accepted. Try a positive integer"), "step")}// For safety, limit the number of returned points per timeseries.// This is sufficient for 60s resolution for a week or 1h resolution for a year.if end.Sub(start)/step > 11000 {err := errors.New("exceeded maximum resolution of 11,000 points per timeseries. Try decreasing the query resolution (?step=XX)")return apiFuncResult{nil, &apiError{errorBadData, err}, nil, nil}} -
用存储new一个rangeQuery的对象,也需要校验用户传入ql是否正确
-
qry, err := api.QueryEngine.NewRangeQuery(api.Queryable, r.FormValue("query"), start, end, step)if err == promql.ErrValidationAtModifierDisabled {err = errors.New("@ modifier is disabled, use --enable-feature=promql-at-modifier to enable it")} else if err == promql.ErrValidationNegativeOffsetDisabled {err = errors.New("negative offset is disabled, use --enable-feature=promql-negative-offset to enable it")}if err != nil {return apiFuncResult{nil, &apiError{errorBadData, err}, nil, nil}} -
调用exec查询结果
-
res := qry.Exec(ctx)if res.Err != nil {return apiFuncResult{nil, returnAPIError(res.Err), res.Warnings, qry.Close}}// Optional stats field in response if parameter "stats" is not empty.var qs *stats.QueryStatsif r.FormValue("stats") != "" {qs = stats.NewQueryStats(qry.Stats())}return apiFuncResult{&queryData{ResultType: res.Value.Type(),Result: res.Value,Stats: qs,}, nil, res.Warnings, qry.Close}
python脚本
import json
import time
import requests
import logginglogging.basicConfig(format='%(asctime)s %(levelname)s %(filename)s [func:%(funcName)s] [line:%(lineno)d]:%(message)s',datefmt="%Y-%m-%d %H:%M:%S",level="INFO"
)def ins_query(host,expr="node_load1"):start_ts = time.perf_counter()uri="http://{}/api/v1/query_range".format(host)end = int(time.time())minutes = 5 * 12start = end - minutes * 60# step = 20 * (1 + minutes // 60)step = 30G_PARMS = {"query": expr,"start": start,"end": end,"step": step}res = requests.get(uri, G_PARMS)if res.status_code!=200:msg = "[error_code_not_200]"logging.error(msg)returnjd = res.json()if not jd:msg = "[error_loads_json]"logging.error(msg)returninner_d = jd.get("data")if not inner_d:returnresult = inner_d.get("result")result_series = len(result)end_ts = time.perf_counter()for index,x in enumerate(result):msg = "[series:{}/{}][metric:{}]".format(index+1,result_series,json.dumps(x.get("metric"),indent=4))logging.info(msg)msg = "Load time: {} Resolution: {}s Result series: {}".format(end_ts-start_ts,step,result_series)logging.info(msg)
if __name__ == '__main__':ins_query("192.168.43.114:9090")
series查询
- 对应uri为
/api/v1/series - grafana 使⽤label_values查询变量
- grafana label_values 根据
node_uname_info{job="node_exporter"}查询instance变量的集合
label_values(node_uname_info{job="node_exporter"}, instance)

源码解读series
- 解析查询参数,一定要求有match,不然报错
-
if err := r.ParseForm(); err != nil {return apiFuncResult{nil, &apiError{errorBadData, errors.Wrapf(err, "error parsing form values")}, nil, nil}}if len(r.Form["match[]"]) == 0 {return apiFuncResult{nil, &apiError{errorBadData, errors.New("no match[] parameter provided")}, nil, nil}}start, err := parseTimeParam(r, "start", minTime)if err != nil {return invalidParamError(err, "start")}end, err := parseTimeParam(r, "end", maxTime)if err != nil {return invalidParamError(err, "end")}matcherSets, err := parseMatchersParam(r.Form["match[]"])if err != nil {return invalidParamError(err, "match[]")} - 使用query存储创建querier对象
-
q, err := api.Queryable.Querier(r.Context(), timestamp.FromTime(start), timestamp.FromTime(end))if err != nil {return apiFuncResult{nil, &apiError{errorExec, err}, nil, nil}} - 构造select查询,并执行
-
hints := &storage.SelectHints{Start: timestamp.FromTime(start),End: timestamp.FromTime(end),Func: "series", // There is no series function, this token is used for lookups that don't need samples.}var sets []storage.SeriesSetfor _, mset := range matcherSets {// We need to sort this select results to merge (deduplicate) the series sets later.s := q.Select(true, hints, mset...)sets = append(sets, s)} - 最后对结果进行merge
-
var sets []storage.SeriesSetfor _, mset := range matcherSets {// We need to sort this select results to merge (deduplicate) the series sets later.s := q.Select(true, hints, mset...)sets = append(sets, s)}set := storage.NewMergeSeriesSet(sets, storage.ChainedSeriesMerge)metrics := []labels.Labels{}for set.Next() {metrics = append(metrics, set.At().Labels())}
-
python脚本
import json
import time
import requests
import logging
import curlifylogging.basicConfig(format='%(asctime)s %(levelname)s %(filename)s [func:%(funcName)s] [line:%(lineno)d]:%(message)s',datefmt="%Y-%m-%d %H:%M:%S",level="INFO"
)def label_values(host, metric_name, exist_tag_kv, tag_key):uri = 'http://{}/api/v1/series'.format(host)end = int(time.time())start = end - 5 * 60expr= '''%s{%s}''' % (metric_name, exist_tag_kv),G_PARMS = {"match[]": expr,"start": start,"end": end,}res = requests.get(uri, G_PARMS,timeout=5)print(curlify.to_curl(res.request))tag_values = set()if res.status_code != 200:msg = "[error_code_not_200]"logging.error(msg)returnjd = res.json()if not jd:msg = "[error_loads_json]"logging.error(msg)returnfor i in jd.get("data"):tag_values.add(i.get(tag_key))msg = "\n[prometheus_host:{}]\n[expr:{}]\n[target_tag:{}]\n[num:{}][tag_values:{}]".format(host,expr,tag_key,len(tag_values),tag_values)logging.info(msg)return tag_valuesif __name__ == '__main__':start = time.perf_counter()label_values("172.20.70.205:9090","jvm_info",'job="jmx_exporter"',"instance")end = time.perf_counter()haoshi = end-startprint(haoshi)
- 对于python脚本调用结果为
2021-05-03 09:23:44 INFO 001_series_query.py [func:label_values] [line:43]:
[prometheus_host:192.168.43.114:9090]
[expr:('node_uname_info{job="node_exporter"}',)]
[target_tag:instance]
[num:2][tag_values:{'192.168.43.2:9100', '192.168.43.114:9100'}]- 再排序即可
- 注意这里是重查询的可能点之一?思考为什么?开销在哪里
labels查询 标签key集合
- 对应uri为
/api/v1/labels - 获取标签key集合
源码解读 labelNames
- 如果配置了match就走labelnames的查询,同时要将series的结果过滤 标签的name
-
if len(matcherSets) > 0 {labelNamesSet := make(map[string]struct{})for _, matchers := range matcherSets {vals, callWarnings, err := q.LabelNames(matchers...)if err != nil {return apiFuncResult{nil, &apiError{errorExec, err}, warnings, nil}}warnings = append(warnings, callWarnings...)for _, val := range vals {labelNamesSet[val] = struct{}{}}}// Convert the map to an array.names = make([]string, 0, len(labelNamesSet))for key := range labelNamesSet {names = append(names, key)}sort.Strings(names)} - 如果没有matcher,那么直接查询labelsNames
-
else {names, warnings, err = q.LabelNames()if err != nil {return apiFuncResult{nil, &apiError{errorExec, err}, warnings, nil}}}
python脚本
import json
import time
import requests
import logginglogging.basicConfig(format='%(asctime)s %(levelname)s %(filename)s [func:%(funcName)s] [line:%(lineno)d]:%(message)s',datefmt="%Y-%m-%d %H:%M:%S",level="INFO"
)def label_names(host, expr=""):uri = 'http://{}/api/v1/labels'.format(host)end = int(time.time())start = end - 5 * 60G_PARMS = {# "match[]": expr,"start": start,"end": end,}if expr:G_PARMS["match[]"] = exprres = requests.get(uri, G_PARMS)tag_values = set()if res.status_code != 200:msg = "[error_code_not_200]"logging.error(msg)returnjd = res.json()if not jd:msg = "[error_loads_json]"logging.error(msg)returnlabel_names_num = len(jd.get("data"))msg = "[series_selector:{}][label_names_num:{}][they are:{}]".format(expr,label_names_num,json.dumps(jd.get("data"),indent=4))logging.info(msg)if __name__ == '__main__':# label_names("192.168.43.114:9090","node_uname_info")label_names("192.168.0.106:9090","node_cpu_seconds_total")
- 举例1 获取node_uname_info的标签key集合
2021-05-03 09:43:26 INFO 001_labels_name_query.py [func:label_names] [line:40]:[series_selector:node_uname_info][label_names_num:9][they are:["__name__","domainname","instance","job","machine","nodename","release","sysname","version"
]]- 举例2 获取一个prometheus的所有标签key集合
2021-05-03 09:45:32 INFO 001_labels_name_query.py [func:label_names] [line:43]:[series_selector:][label_names_num:83][they are:["__name__","account","address","alertmanager","alertname","alertstate","branch","broadcast",
- 原理
D:\nyy_work\go_path\pkg\mod\github.com\prometheus\prometheus@v1.8.2-0.20210220213500-8c8de46003d1\web\api\v1\api.go- 如果没有series_selector则获取指定block的标签集合
- 这个在head block中直接在倒排索引中返回,速度最快
- 如果有series_selector则需要遍历获取结果
label values查询
- 对应uri为
/api/v1/label/<label_name>/values - 获取标签label_name的 value集合
源码解读 labelValues
- 底层调用的就是head的倒排索引查询数据,位置 F:\go_path\src\github.com\prometheus\prometheus\tsdb\head_read.go
-
func (h *headIndexReader) LabelValues(name string, matchers ...*labels.Matcher) ([]string, error) {if h.maxt < h.head.MinTime() || h.mint > h.head.MaxTime() {return []string{}, nil}if len(matchers) == 0 {h.head.symMtx.RLock()defer h.head.symMtx.RUnlock()return h.head.postings.LabelValues(name), nil}return labelValuesWithMatchers(h, name, matchers...) } func (p *MemPostings) LabelValues(name string) []string {p.mtx.RLock()defer p.mtx.RUnlock()values := make([]string, 0, len(p.m[name]))for v := range p.m[name] {values = append(values, v)}return values }
python脚本
import json
import time
import requests
import logging
import curlifylogging.basicConfig(format='%(asctime)s %(levelname)s %(filename)s [func:%(funcName)s] [line:%(lineno)d]:%(message)s',datefmt="%Y-%m-%d %H:%M:%S",level="INFO"
)def label_values(host, label_name,expr="",):uri = 'http://{}/api/v1/label/{}/values'.format(host,label_name)end = int(time.time())start = end - 5 * 60G_PARMS = {# "match[]": expr,"start": start,"end": end,}if expr:G_PARMS["match[]"] = exprres = requests.get(uri, G_PARMS)print(curlify.to_curl(res.request))tag_values = set()if res.status_code != 200:msg = "[error_code_not_200]"logging.error(msg)returnjd = res.json()if not jd:msg = "[error_loads_json]"logging.error(msg)returnlabel_names_num = len(jd.get("data"))msg = "\n[series_selector:{}][target_label:{}][label_names_num:{}][they are:{}]".format(expr,label_name,label_names_num,json.dumps(jd.get("data"),indent=4))logging.info(msg)if __name__ == '__main__':# label_values("192.168.43.114:9090","job","")label_values("192.168.0.106:9090","instance",'''node_arp_entries{job=~".*"}''')
- 举例1 获取所有job的name集合
2021-05-03 09:54:28 INFO 001_labels_value_query.py [func:label_values] [line:44]:
[series_selector:][target_label:job][label_names_num:10][they are:["blackbox-http","blackbox-ping","blackbox-ssh","mysqld_exporter","node_exporter","process-exporter","prometheus","pushgateway","redis_exporter_targets","shard_job"
]]
- 举例2:根据
node_uname_info{job="node_exporter"}查询instance变量的集合
2021-05-03 09:56:11 INFO 001_labels_value_query.py [func:label_values] [line:44]:
[series_selector:node_uname_info][target_label:instance][label_names_num:2][they are:["192.168.43.114:9100","192.168.43.2:9100"
]]
/api/v1/series 和 /api/v1/label/<label_name>/values 区别
- series使用
Querier.Select然后grafana自身遍历 - 后者使用
LableQuerier.LabelValues提供标签查询
总结 5大数据查询接口
- 代码位置 web\api\v1\api.go
r.Get("/query", wrap(api.query))r.Get("/query_range", wrap(api.queryRange))r.Get("/labels", wrap(api.labelNames))r.Get("/label/:name/values", wrap(api.labelValues))r.Get("/series", wrap(api.series))
本节重点总结 :
- 5大数据查询接口
- instant_query查询一个点
- range_query查询一段时间数据
- series查询 全量标签数据
- labels查询 标签key集合
- label values查询



