第三章 线性回归与感知机:从基础模型到分类边界
线性模型是机器学习中最基础且重要的模型类别,它们不仅简单直观,而且为许多复杂模型奠定了基础。本章将详细介绍线性回归和感知机这两类核心线性模型,揭示它们在回归和分类问题中的应用原理。
一、线性回归:预测建模的基石
1.1 线性回归的起源与发展
线性回归的历史可以追溯到19世纪,英国统计学家弗朗西斯·高尔顿在研究父母与子女身高关系时发现了"回归"现象:子女身高趋向于"中亲"身高(父母身高的平均值)与总体平均身高之间的某个值。这一发现奠定了回归分析的基础。
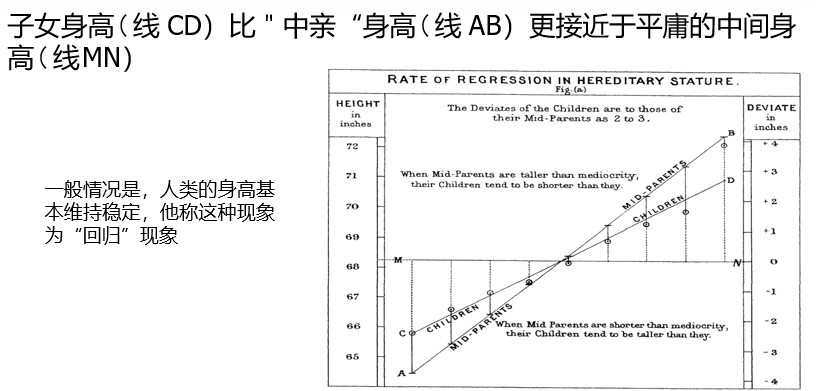
现代应用场景:
- 房价预测:基于房屋面积、位置等特征
- 销售预测:基于历史销售数据和市场指标
- 经济分析:GDP增长与各种经济指标的关系
1.2 线性回归模型详解
模型形式
- 一元线性回归:Y = w₀ + w₁X + ε
- 多元线性回归:Y = w₀ + w₁X₁ + w₂X₂ + … + wₚXₚ + ε

其中:
- Y:目标变量(因变量)
- X:特征变量(自变量)
- w:模型参数(权重)
- ε:随机误差项
矩阵表示

对于包含n个样本、p个特征的数据集,可以表示为:
Y = Xw + ε
其中:
- Y ∈ ℝⁿ:目标向量
- X ∈ ℝⁿˣᵖ:设计矩阵
- w ∈ ℝᵖ:参数向量
1.3 参数估计:最小二乘法
最小二乘法是线性回归最常用的参数估计方法,其核心思想是找到使残差平方和最小的参数值。

优化目标:


解析解:


几何解释:
最小二乘解实际上是在特征空间中找到目标向量Y在设计矩阵X列空间上的正交投影。
1.4 正则化:应对过拟合
当特征维度高或特征间存在多重共线性时,标准最小二乘法可能表现不佳。正则化通过引入惩罚项来解决这些问题。


常见正则化方法:



- 岭回归(L2正则化):
- 目标函数:min ||Y - Xw||² + λ||w||²
- 特点:收缩系数但不产生稀疏解
- Lasso回归(L1正则化):
- 目标函数:min ||Y - Xw||² + λ||w||₁
- 特点:可产生稀疏解,实现特征选择
- Elastic Net:
- 结合L1和L2正则化
- 适用于特征维度很高且特征间相关性强的场景
1.5 线性回归的局限与扩展
局限性:
- 假设线性关系,无法捕捉非线性模式
- 对异常值敏感
- 当特征维度大于样本量时,标准方法失效
扩展方法:
- 多项式回归:通过引入特征的高次项
- 局部加权回归:赋予不同样本不同权重
- 广义线性模型:扩展至非正态分布响应变量
二、感知机:线性分类的基础
2.1 感知机的起源与意义
感知机由Frank Rosenblatt于1957年提出,是最早的人工神经网络模型之一。它模拟了生物神经元的工作方式,为现代深度学习奠定了基础。

核心思想:
通过线性超平面将特征空间划分为两个区域,分别对应不同的类别。
2.2 感知机模型
模型定义

对于输入特征x,感知机模型为:
f(x) = sign(wᵀx + b)
其中:
- w:权重向量
- b:偏置项
- sign:符号函数,输出+1或-1
几何解释
感知机在特征空间中构造一个分离超平面wᵀx + b = 0,将不同类别的样本分开。

2.3 学习算法
感知机使用基于误分类的损失函数,并通过梯度下降法进行优化。
损失函数



误分类点到超平面的总距离:
L(w,b) = -Σ yᵢ(wᵀxᵢ + b)
原始形式算法


- 初始化参数w,b
- 选取误分类点(xᵢ,yᵢ)
- 更新参数:
w ← w + ηyᵢxᵢ
b ← b + ηyᵢ - 重复直到没有误分类点
其中η为学习率,控制参数更新步长。
对偶形式


将对偶形式表示为:
f(x) = sign(Σ αᵢyᵢxᵢᵀx + b)
通过计算Gram矩阵(xᵢᵀxⱼ)可以加速运算。
2.4 感知机的局限与扩展
局限性:
- 仅适用于线性可分数据
- 对初始值和样本顺序敏感
- 无法直接处理多分类问题
扩展方法:
- 多层感知机:通过堆叠多个感知机实现非线性分类
- 支持向量机:最大化分类间隔的线性分类器
- 核方法:通过核函数处理非线性可分数据
2.5 感知机与线性回归的比较
| 特性 | 线性回归 | 感知机 |
|---|---|---|
| 任务类型 | 回归 | 分类 |
| 输出 | 连续值 | 离散类别 |
| 损失函数 | 平方损失 | 0-1损失近似 |
| 优化方法 | 最小二乘/梯度下降 | 梯度下降 |
| 解的唯一性 | 通常唯一 | 可能多个 |
| 正则化 | 常用 | 较少使用 |

三、本章总结
线性回归和感知机作为机器学习中最基础的线性模型,具有以下核心特点:
- 模型简单:线性结构易于理解和实现
- 计算高效:通常有解析解或简单迭代算法
- 可解释性强:参数直接反映特征重要性
- 扩展性强:为更复杂模型奠定基础
在实际应用中需要注意:
- 线性假设的合理性检验
- 正则化参数的选择
- 模型评估与验证方法
- 对数据质量和特征工程的依赖
理解这些基础模型不仅有助于解决简单问题,更是掌握复杂机器学习方法的重要阶梯。在后续章节中,我们将看到这些线性模型如何演变为更强大的非线性模型。


![[C++] STL数据结构小结](http://pic.xiahunao.cn/nshx/[C++] STL数据结构小结)



