
Vegapunk No.01 海贼王角色,用 ChatGPT 生成
这是我们新系列《DeepSeek-V3 解读》的第一篇文章,在这个系列里,我们会努力揭开 DeepSeek 刚开源的最新模型 DeepSeek-V3 [1, 2] 的神秘面纱。
在这个系列里,我们计划覆盖两个主要话题:
• DeepSeek-V3 的主要架构创新,包括 MLA(Multi-head Latent Attention)[3]、DeepSeekMoE [4]、无辅助损失负载均衡 [5] 和多 token 预测训练。
• DeepSeek-V3 的训练流程,包括预训练、微调、以及强化学习(RL)对齐阶段。
这篇文章主要聚焦在 Multi-head Latent Attention 上,最早在 DeepSeek-V2 开发过程中首次提出,后来也被用到了 DeepSeek-V3 上。
• 背景 我们会先回顾一下标准的 Multi-Head Attention(MHA),解释为什么在推理过程中需要 Key-Value(KV)缓存。然后,我们会探讨 MQA(Multi-Query Attention)和 GQA(Grouped-Query Attention)是怎么去优化内存和计算效率的。最后,还会简单说一下 RoPE(旋转式位置编码)是怎么把位置信息融合进注意力机制的。 • Multi-head Latent Attention 深入介绍 MLA,涵盖它的核心动机、为什么需要解耦 RoPE、以及它是怎么比传统注意力机制表现更好的。
🔍 我们在研究这些新架构的同时,也在整理一套完整的「LLM底层机制拆解系列」资料,聚焦模型结构演进与推理效率优化。如果你也在搭建或评估大模型系统,不妨关注这个系列一起深入分析底层设计背后的工程逻辑。
背景
为了更好地理解 MLA,并让这篇文章能自洽,我们先在这一节里回顾一些相关概念,然后再正式进入 Multi-head Latent Attention 的细节。
只用 Decoder 的 Transformer 里的 MHA
要注意,MLA 是专门为了加速自回归文本生成推理而设计的。所以,这里提到的 Multi-Head Attention(MHA)是在只用 Decoder 的 Transformer 架构下的。
下面这张图比较了三种用于解码的 Transformer 架构。图(a)展示了在《Attention is All You Need》论文里最初提出的 Encoder-Decoder 架构。后来,[6] 对这个 Decoder 设计进行了简化,变成了图(b)这种只用 Decoder 的 Transformer,也成了 GPT [8] 等一大票生成式模型的基础。
现在,大型语言模型(LLM)更常用图(c)这种架构,因为它训练起来更稳定。这个设计里,归一化是应用在输入上而不是输出上,LayerNorm 也换成了更稳定的 RMSNorm。这也是本文讨论的基础架构。
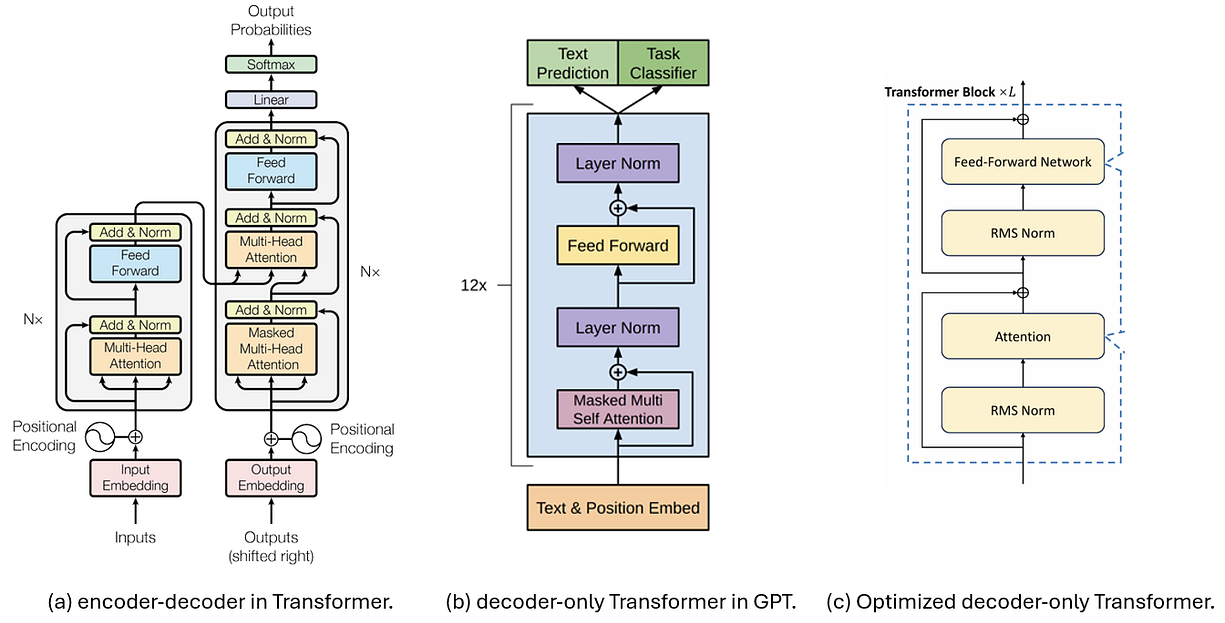
图 1. Transformer 架构。(a)[6] 中提出的 Encoder-Decoder。(b)[7] 中提出并在 GPT [8] 中使用的只用 Decoder 的 Transformer。(c)在(b)基础上优化,Attention 前加 RMSNorm。[3]
在这个背景下,Multi-Head Attention(MHA)的计算基本遵循 [6] 中描述的方法,如下图所示:
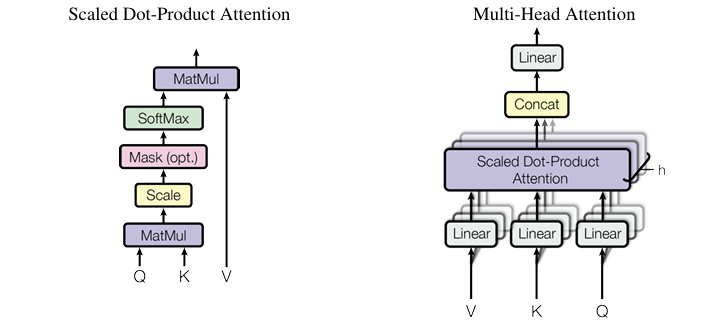
图 2. 缩放点积注意力 vs. Multi-Head Attention,图片来自 [6]。
假设我们有 n_h 个注意力头,每个头的维度是 d_h。所有头的输出拼接后,总维度就是 (n_h · d_h)。
对于一个有 L 层的模型,记第 t 个 token 输入某一层时的表示为 h_t,维度是 d。要计算 Multi-Head Attention,首先用线性映射矩阵把 h_t 从 d 维投影到 (n_h · d_h) 维。
更正式地说,公式如下(改编自 [3]):
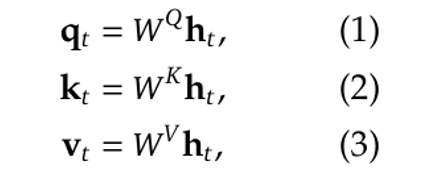
其中,W^Q、W^K 和 W^V 是线性映射矩阵:
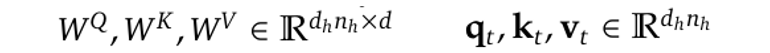
经过这步投影后,得到的向量 q_t、k_t 和 v_t 会各自分成 n_h 个头。每个头独立进行缩放点积注意力计算:
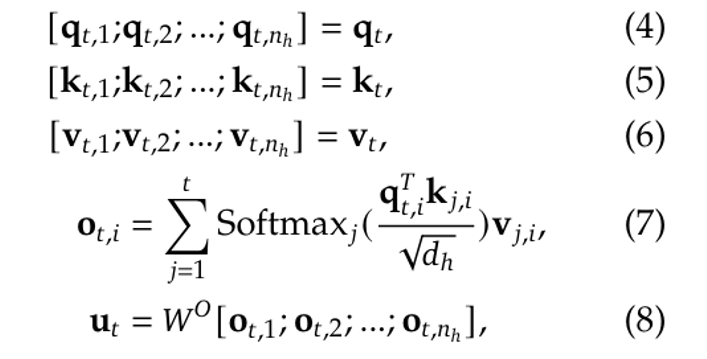
这里,W^O 是输出投影矩阵,把拼接后的注意力输出从 (n_h · d_h) 维映射回原本的 d 维。
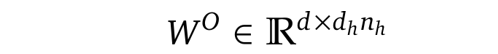
要注意,公式(1)到(8)描述的是单个 token 的处理过程。在推理过程中,每生成一个新的 token,都要重复这一整套流程,导致大量重复计算。为了解决这个问题,有一个常见的优化方法叫 Key-Value 缓存(KV 缓存)。
Key-Value 缓存
顾名思义,Key-Value(KV)缓存就是为了加速自回归生成,避免每步解码时重复计算,而是把之前算好的 key 和 value 保存下来直接复用。
需要注意的是,KV 缓存一般只在推理时用,训练时是并行处理整段输入序列,不需要缓存。
KV 缓存通常是一个滚动缓冲区。每步解码时,只需要计算新的 query 向量 Q,而之前存好的 K 和 V 可以直接拿来用。注意力就是用新的 Q 和缓存的 K、V 来计算的。然后把新生成的 token 的 K 和 V 加到缓存里,留着下一步用。
不过,KV 缓存带来的加速是以大量内存开销为代价的。缓存大小一般是批次大小 × 序列长度 × 隐藏层大小 × 注意力头数。所以在大 batch 或长序列情况下,KV 缓存很容易成为内存瓶颈。
为了减少这个内存负担,后来又发展出了两种优化技术:Multi-Query Attention(MQA)和 Grouped-Query Attention(GQA)。
Multi-Query 注意力(MQA)和 Grouped-Query 注意力(GQA)
下面这张图比较了原版 Multi-Head Attention(MHA)、Grouped-Query Attention(GQA)[10] 和 Multi-Query Attention(MQA)[9]。
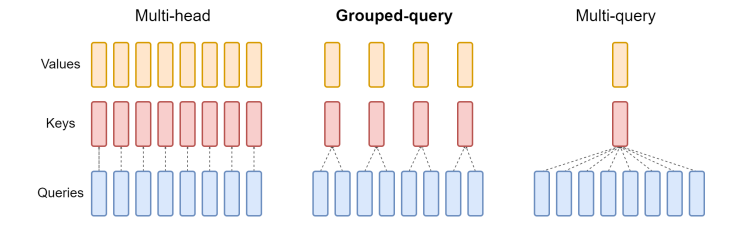
图 3. MHA [6]、GQA [10] 和 MQA [9],图片来自 [10]。
MQA 的核心思想是,让所有 query 头共享同一个 key 和同一个 value 头。这样可以大幅减少内存占用,尤其是在推理时。但缺点是注意力的表达能力会下降,影响准确度。
Grouped-Query Attention(GQA)可以看作是 MHA 和 MQA 之间的折中。在 GQA 里,一组 query 头共享一对 key 和 value,而不是所有 query 头都共用。这样内存效率更好一点,但比起全 MHA,灵活性还是差一些,效果也稍微差一点。
后面,我们就要看看 Multi-head Latent Attention(MLA)是怎么在内存效率和建模准确性之间找到一个更好的平衡点的。
RoPE(旋转式位置编码)
最后还有一块背景知识要补充,就是 RoPE [11]。RoPE 是通过对 multi-head attention 里的 query 和 key 向量应用正弦旋转矩阵,把位置信息直接编码进去的。
具体来说,RoPE 是对每个 token 的 query 和 key 向量应用一个跟位置相关的旋转矩阵。虽然它也是用正弦和余弦函数,但用的是独特的旋转方式,能保留相对位置信息。
举个简单例子,假设有一个 4 维的嵌入向量 (x_1, x_2, x_3, x_4),
应用 RoPE 的时候,先把连续的两个维度分组:
• (x_1, x_2) -> 位置1
• (x_3, x_4) -> 位置2
然后对每一组应用旋转矩阵:
图 4. 对一对 token 应用旋转矩阵的示意图。图片作者自制。
这里,θ = θ(p) = p ⋅ θ₀,θ₀ 是基础频率。这个例子里,(x₁, x₂) 会旋转 θ₀,(x₃, x₄) 会旋转 2 ⋅ θ₀。
所以,旋转矩阵是位置相关的:每个位置用不同的旋转角度。
RoPE 在现代 LLM 中很常见,因为它能高效编码长序列。但正因为它的旋转是位置相关的,所以跟 MLA 的机制存在兼容性问题。
📎 我们在项目实践中持续测试 MLA 与多种 KV 缓存结构的真实表现,也记录了一些实用调优经验和图解流程。如你在优化推理路径或设计内存机制的过程中遇到困惑,可留言交流,我们乐于分享更多实现细节。
Multi-head Latent Attention
好了,现在终于可以进入 Multi-head Latent Attention(MLA)了。在这一节,我们会先讲 MLA 的整体直觉,再说说为什么要对 RoPE 进行改造,最后给出 MLA 的详细算法流程和性能表现。
MLA:高层次的思路
MLA 的基本思路就是,把输入的注意力向量 h_t 压缩成一个低维的潜在向量,维度是 d_c,d_c 要比原来的 (n_h · d_h) 小很多。
后面需要计算注意力的时候,再把这个低维潜向量投影回高维空间,重建出 keys 和 values。
这意味着只需要保存这个小小的潜在向量,大大减少了内存开销。
这个流程可以更正式地用下面这些公式描述,其中 c^{KV}_t 是潜向量,W^{DKV} 是降维矩阵,把 h_t 从 (n_h · d_h) 投影到 d_c(这里 D 表示 "down-projection",也就是降维),而 W^{UK} 和 W^{UV} 是上采样矩阵,把共享的潜在向量再映射回高维,恢复出 keys 和 values。

同样地,也可以把 queries 投影到一个低维潜空间,之后再恢复到原来的高维空间:

为什么需要解耦 RoPE
前面说过,RoPE 是生成模型处理中长序列时常用的做法。
但如果直接把 MLA 这套压缩策略用上去,会跟 RoPE 不兼容。
更具体地看,当我们用公式(7)计算注意力时:q^T 要跟 k 相乘,中间会出现 W^Q 和 W^{UK} 这两个矩阵。
这俩组合起来,实际上相当于一个从 d_c 到 d 的单独映射。
在原论文 [3] 里,作者用 “W^{UK} 可以被吸收到 W^Q 里” 来描述这事儿。这样的话,在 KV 缓存里就不用专门存 W^{UK},进一步节省了内存。
但问题来了:RoPE 里的旋转矩阵是跟位置相关的,每个位置都不一样。所以,W^{UK} 就没法直接被吸进 W^Q 里了。
为了解决这个冲突,作者提出了一个叫做「解耦 RoPE」(decoupled RoPE)的方法。
它引入了额外的 query 向量和一个共享的 key 向量,只对这些新增向量应用 RoPE,而原本的 key 不做旋转。
这样就实现了把位置信息编码跟主要的注意力计算分开,避免冲突。
完整的 Multi-head Latent Attention(MLA)过程如下图总结(公式编号对应 [3] 的附录 C):
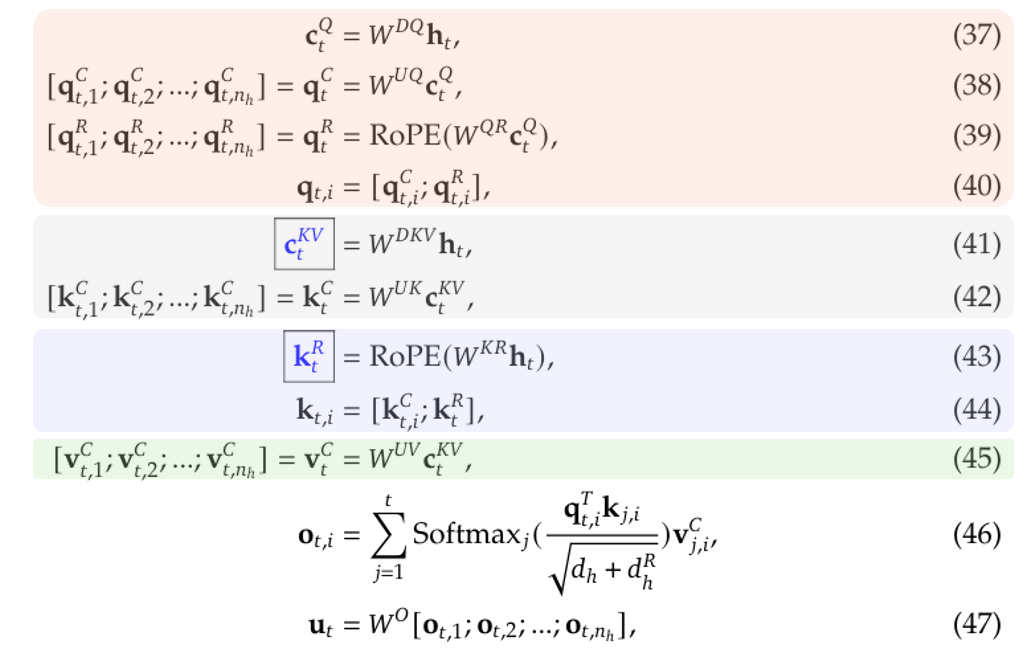
图 5. MLA 流程。图片根据 [3] 的公式编辑而成。
这里:
• 公式(37)到(40)描述了怎么处理 query tokens。
• 公式(41)和(42)描述了怎么处理 key tokens。
• 公式(43)和(44)描述了怎么用新增的共享 key 做 RoPE,要注意(42)里出来的结果不参与 RoPE。
• 公式(45)描述了怎么处理 value tokens。
在这个过程中,只有蓝色方框标出来的变量需要缓存。
整个工作流在下面这个流程图里更直观地展示出来了:
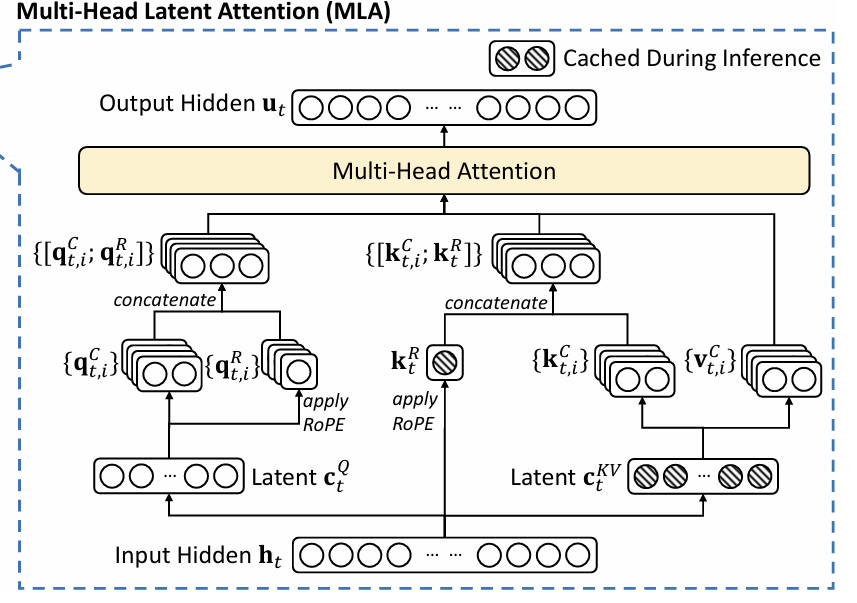
图 6. MLA 流程图。图片来自 [3]。
MLA 的性能表现
下面这个表格对比了每个 token 的 KV 缓存大小和建模能力,在 MHA、GQA、MQA 和 MLA 之间,突出展示了 MLA 是怎么在内存效率和表达能力之间取得更好平衡的。
有趣的是,即使用了更少的内存,MLA 的建模能力居然还能超越原版的 MHA。
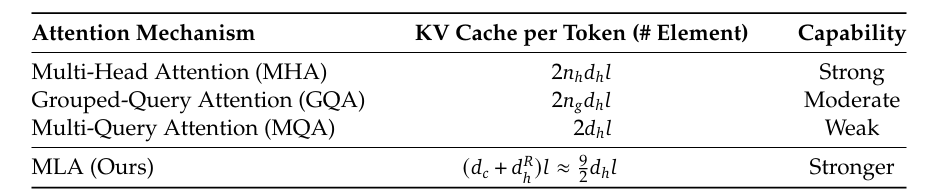 表格 1,来自 [3]。
表格 1,来自 [3]。
更具体地说,下面这个表格给出了在 7B 规模模型下,MHA、GQA 和 MQA 的表现数据,
可以看到 MHA 明显比 MQA 和 GQA 效果好一大截。
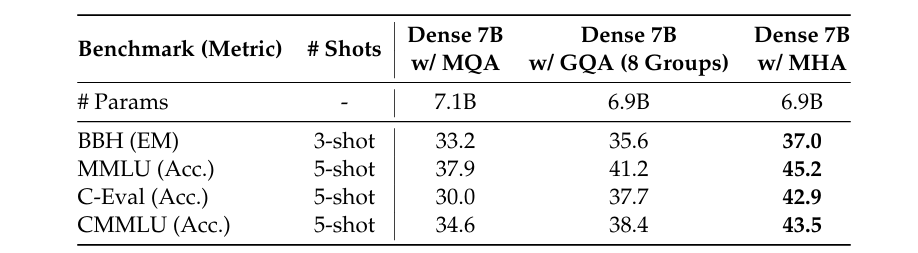 表格 8,来自 [3]。
表格 8,来自 [3]。
作者们还进一步比较了 MHA 和 MLA,
总结在下面这个表格里,MLA 在各种基准测试上都全面优于 MHA。
 表格 9,来自 [3]。
表格 9,来自 [3]。
📬 本文是我们 LLM 结构拆解系列的第一篇,后续还将继续解析 DeepSeek-V3 中的 DeepSeekMoE、Token-Level 预测、以及训练对齐细节。
如果你也正在研究 AI 模型架构,或希望深入了解其背后的系统工程方法,欢迎私信「结构解读」获取系列结构图和实战解析清单(已整理为 PDF)。
参考文献
[1] DeepSeek
[2] DeepSeek-V3 技术报告
[3] DeepSeek-V2:一种强大、经济且高效的混合专家语言模型
[4] DeepSeekMoE:迈向混合专家语言模型的终极专家专精
[5] GShard:通过条件计算与自动分片扩展巨型模型
[6] 用哈希层扩展大型稀疏模型
[7] Switch Transformers:通过简单高效的稀疏性扩展到万亿参数模型
[8] 无辅助损失的混合专家负载均衡策略






