引言
在当今数字化转型的浪潮中,物联网(IoT)、工业互联网和智能制造等领域正在产生海量的数据。这些数据既包含结构化的关系型数据,也包含大量的时间序列数据。传统的单一模型数据库在处理这种多模态数据时往往面临诸多挑战:要么使用多个不同类型的数据库分别存储不同类型的数据,增加了系统复杂性和维护成本;要么勉强使用单一数据库存储所有类型数据,但性能和效率大打折扣。
KWDB(开放原子开源基金会孵化的开源项目,基于浪潮KaiwuDB研发)作为一款面向AIoT场景的分布式多模数据库,通过创新的存储引擎架构设计,在同一实例中同时支持关系数据和时序数据的高效存储与处理,实现了"一库多模"的技术突破。本文将深入解析KWDB的存储引擎架构,揭示其背后的技术原理和创新设计。
1. KWDB存储引擎架构概述
1.1 多模融合的整体架构
KWDB采用了分层设计的存储引擎架构,主要包括以下几个核心层次:
- 接入层:统一SQL接口,支持标准SQL语法,同时扩展了时序数据处理的特定语法
- 解析与优化层:包含SQL解析器、查询优化器和执行计划生成器
- 执行层:负责执行计划的调度和执行
- 存储引擎层:包含关系存储引擎和时序存储引擎两大核心组件
- 持久化层:负责数据的持久化存储和管理
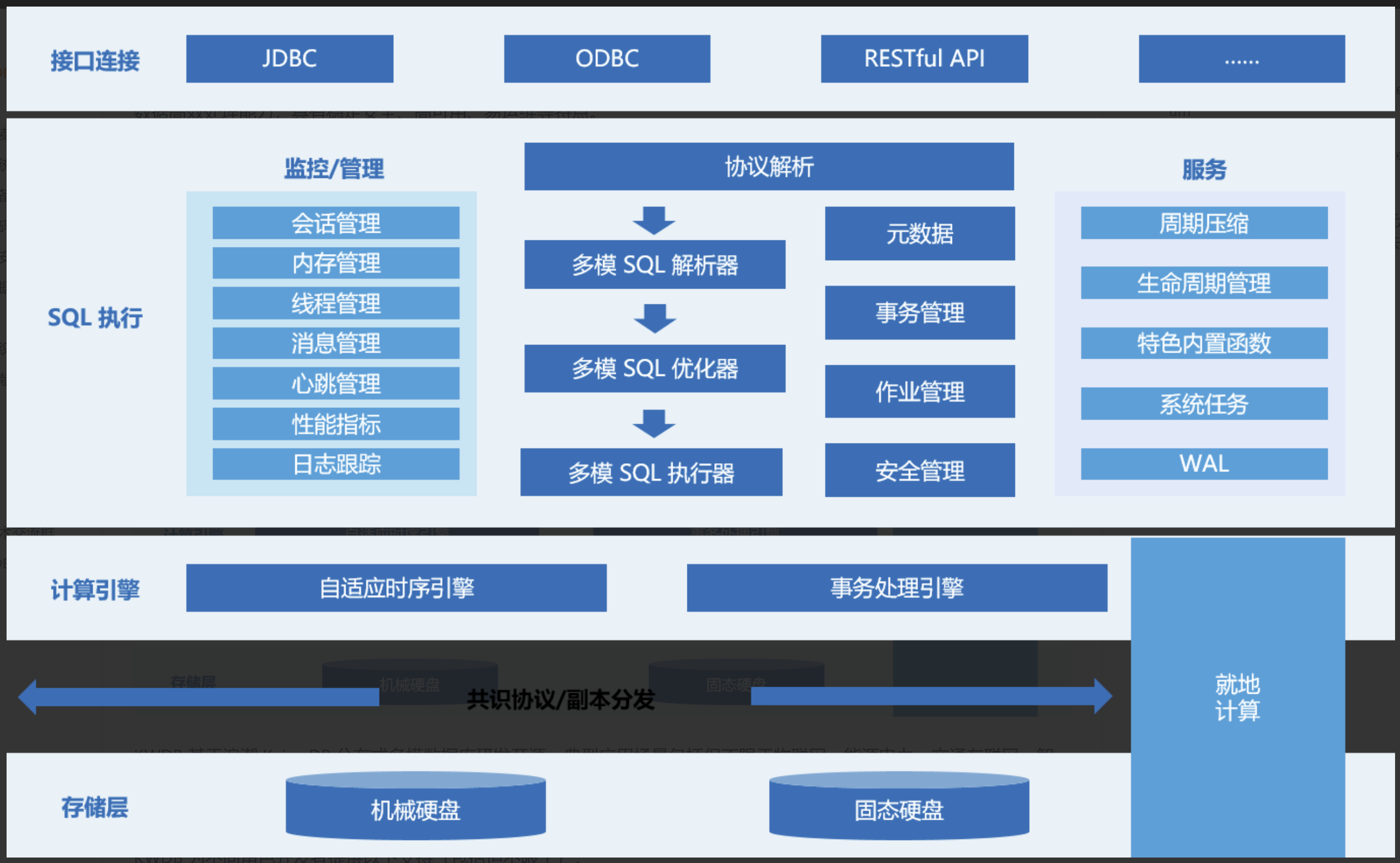
KWDB的存储引擎层是整个系统的核心,采用了"双引擎协同"的创新设计,即关系存储引擎和时序存储引擎并行工作,各自负责处理对应类型的数据,同时通过统一的元数据管理和查询优化机制实现两种引擎的无缝协作。
1.2 关系存储引擎概述
KWDB的关系存储引擎基于分布式架构设计,采用了行存储模式,主要负责处理结构化的关系型数据。其核心特点包括:
- 分布式事务处理:支持ACID特性,确保数据一致性
- 多版本并发控制(MVCC):实现高并发读写
- B+树索引:支持高效的点查询和范围查询
- 二级索引:支持多种索引类型,优化查询性能
- 行级锁:细粒度锁机制,提高并发性能
关系存储引擎采用了基于Paxos的分布式共识协议,确保在分布式环境下的数据一致性和高可用性。
1.3 时序存储引擎概述
KWDB的时序存储引擎是专为时间序列数据设计的高性能存储引擎,采用了列式存储模式,具有以下特点:
- 列式存储:针对时序数据的特点进行优化
- 高效压缩算法:采用Delta-of-Delta等压缩算法,大幅降低存储空间
- 时间分区:基于时间维度的自动分区机制
- 标签索引:高效支持多维标签查询
- 降采样与聚合:内置时序数据降采样和聚合功能
- 数据生命周期管理:自动管理冷热数据,优化存储效率
时序存储引擎基于LSM-Tree(Log-Structured Merge-Tree)架构设计,特别优化了写入性能,能够支持百万级数据的秒级写入。
2. 关系存储引擎与时序存储引擎的协同工作机制
2.1 统一元数据管理
KWDB通过统一的元数据管理系统,实现了关系存储引擎和时序存储引擎的协同工作。元数据管理系统维护了数据库中所有对象的定义和状态信息,包括:
- 数据库和表的定义
- 表结构和字段信息
- 索引定义和状态
- 分区信息
- 存储位置映射
通过统一的元数据管理,KWDB能够在逻辑层面将关系数据和时序数据统一起来,为上层应用提供一致的访问接口。
2.2 跨引擎查询处理
KWDB的一大创新在于其跨引擎查询处理能力,主要通过以下机制实现:
- 查询解析与分解:将复杂查询分解为关系子查询和时序子查询
- 并行执行:关系子查询和时序子查询并行执行,提高查询效率
- 中间结果融合:通过高效的数据交换机制,融合两种引擎的查询结果
- 最终结果组装:根据原始查询要求,组装最终结果返回给用户
这种跨引擎查询处理机制使KWDB能够高效处理同时涉及关系数据和时序数据的复杂查询,例如"查询某设备在过去一小时内的异常数据记录及其对应的设备详细信息"。
2.3 数据路由与分发
KWDB实现了智能的数据路由与分发机制,确保不同类型的数据被正确地路由到相应的存




