文章目录
- 一、前言:文件流的哲学
- 🏙️正文
- 一、FILE 结构设计
- 二、函数使用及分析
- 2.1、文件打开 fopen
- 2.2、文件关闭 fclose
- 2.3、缓冲区刷新 fflush
- 2.3、数据写入 fwrite
- 2.4、数据读取 fread
- 2.6 小结
在计算机的世界里,文件如同河流,承载着数据的流动与生命的律动。今天,我们将踏上一段奇妙的旅程,探索如何在Linux系统中模拟实现C语言的文件流,揭开那看似神秘却又充满优雅的面纱。
一、前言:文件流的哲学
在C语言中,文件流是一种抽象的概念,它将复杂的文件操作简化为一系列流畅的读写动作。标准库中的FILE结构体及其相关函数如fopen()、fread()、fwrite()等,为程序员提供了一个优雅的接口,使我们能够专注于数据的处理而非底层的细节。
然而,这些优雅的接口背后,隐藏着怎样的奥秘?今天,我们将揭开这层面纱,亲手构建一个简化版的文件流系统。
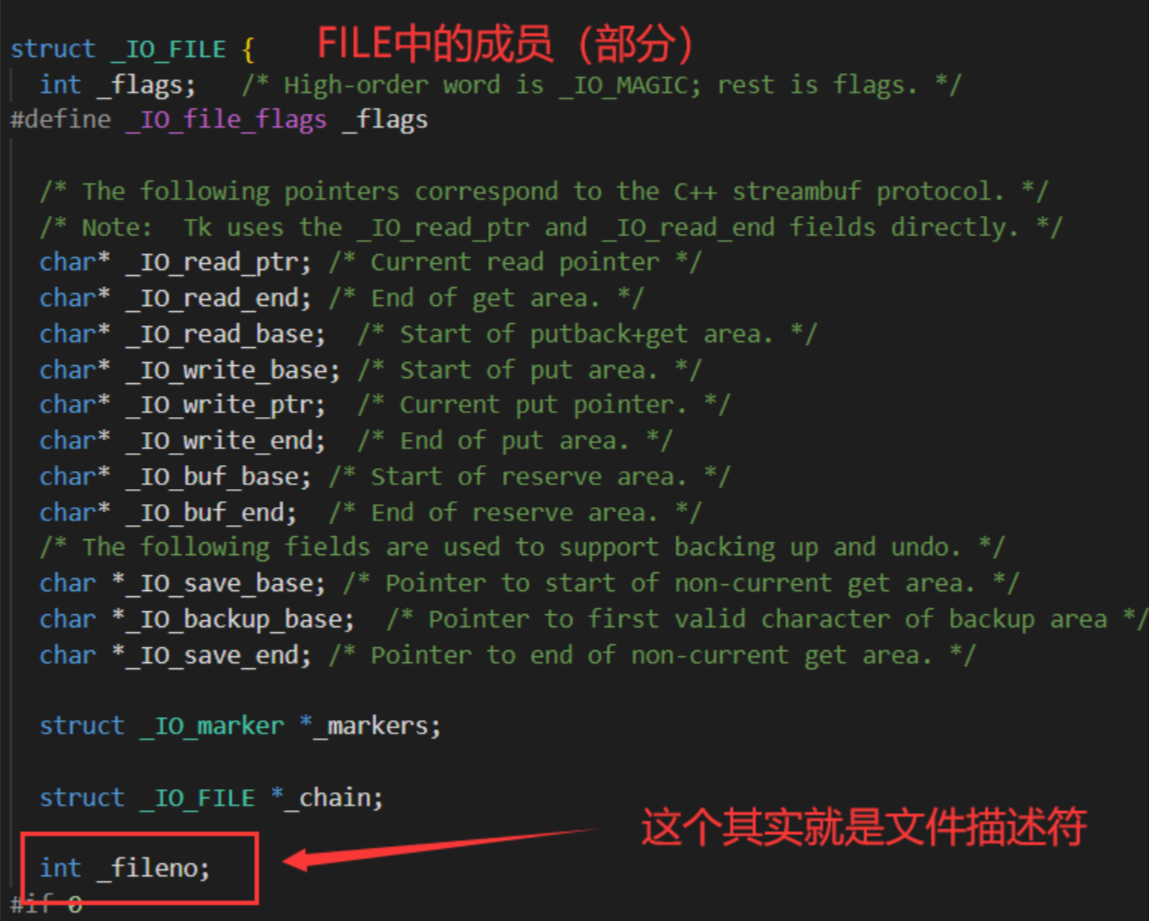
本文重点 : 模拟实现 FILE 及C语言文件操作相关函数
注意: 本文实现的只是一个简单的 demo,重点在于理解系统调用及缓冲区
🏙️正文
一、FILE 结构设计
在设计 FILE 结构体前,首先要清楚 FILE 中有自己的缓冲区及冲刷方式
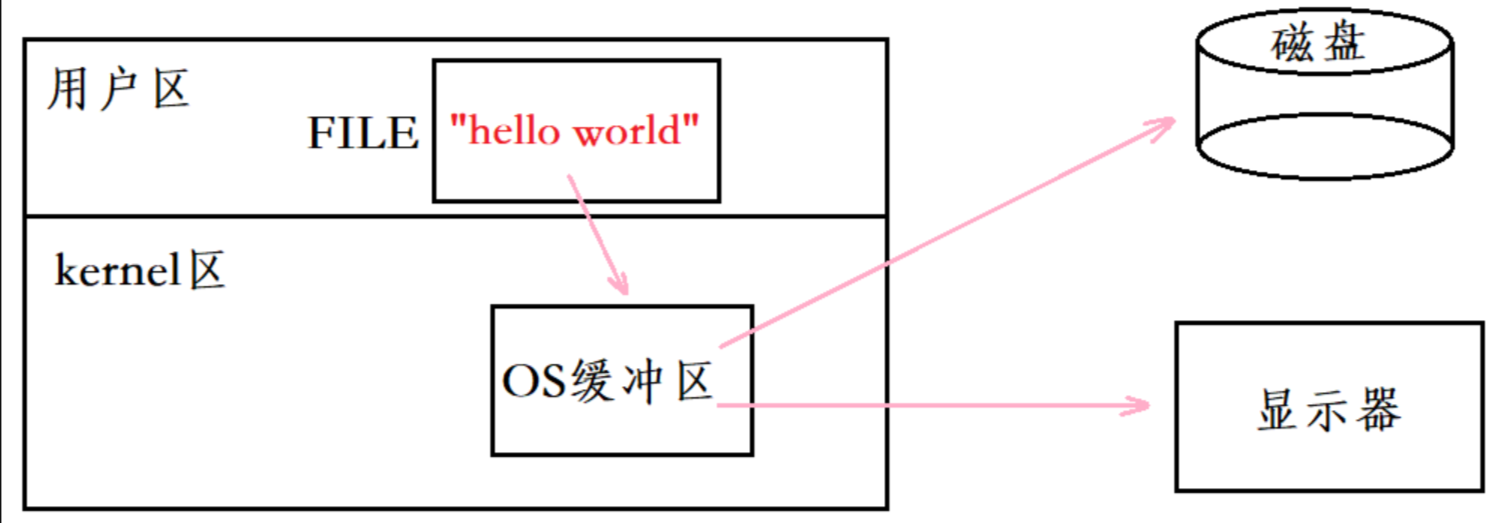
缓冲区的大小和刷新方式因平台而异,这里我们将 大小设置为 1024 刷新方式选择 行缓冲,为了方便对缓冲区进行控制,还需要一个下标 _current,当然还有 最重要的文件描述符 _fd
#define BUFFER_SIZE 1024 //缓冲区大小//通过位图的方式,控制刷新方式
#define BUFFER_NONE 0x1 //无缓冲
#define BUFFER_LINE 0x2 //行缓冲
#define BUFFER_ALL 0x4 //全缓冲typedef struct MY_FILE
{char _buffer[BUFFER_SIZE]; //缓冲区size_t _current; //缓冲区下标int _flush; //刷新方式,位图结构int _fd; //文件描述符
}MY_FILE;当前模拟实现的 FILE 只具备最基本的功能,重点在于呈现原理
在模拟实现 C语言 文件操作相关函数前,需要先来简单回顾下
二、函数使用及分析
主要实现的函数有以下几个:
- fopen 打开文件
- fclose 关闭文件
- fflush 进行缓冲区刷新
- fwrite 对文件中写入数据
- fread 读取文件数据
#include <stdio.h>
#include <assert.h>
#include <string.h>int main()
{//打开文件,写入数据FILE* fp = fopen("file.txt", "w");assert(fp);const char* str = "露易斯湖三面环山,层峦叠嶂,翠绿静谧的湖泊在宏伟山峰及壮观的维多利亚冰川的映照下更加秀丽迷人";char buff[1024] = { 0 };snprintf(buff, sizeof(buff), str);fwrite(buff, 1, sizeof(buff), fp);fclose(fp);return 0;
}
#include <stdio.h>
#include <assert.h>
#include <string.h>int main()
{//打开文件,并从文件中读取信息FILE* fp = fopen("file.txt", "r+");assert(fp);char buff[1024] = { 0 };int n = fread(buff, 1, sizeof(buff) - 1, fp);buff[n] = '\0';printf("%s", buff);fclose(fp);return 0;
}fopen
- 打开指定文件,可以以多种方式打开,若是以读方式打开时,文件不存在会报错
fclose
- 根据 FILE* 关闭指定文件,不能重复关闭
fwrite
- 对文件中写入指定数据,一般是借助缓冲区进行写入
fread
- 读取文件数据,同理一般是借助缓冲区先进行读取
不同的缓冲区有不同的刷新策略,如果未触发相应的刷新策略,会导致数据滞留在缓冲区中,比如如果内存中的数据还没有刷新就断电的话,会导致数据丢失;除了通过特定方式进行缓冲区冲刷外,还可以手动刷新缓冲区,在 C语言 中,手动刷新缓冲区的函数为 fflush
#include <stdio.h>
#include <unistd.h>int main()
{int cnt = 20;while(cnt){printf("he"); //故意不触发缓冲cnt--;if(cnt % 10 == 5) {fflush(stdout); //刷新缓冲区printf("\n当前已冲刷,cnt: %d\n", cnt);}sleep(1);}return 0;
}
在cnt=15和5时先手动冲刷两次,之后程序结束自动全部冲刷
总的来说,这些文件操作相关函数,都是在对缓冲区进行写入及冲刷,将数据拷贝给内核缓冲区,再由内核缓冲区刷给文件
2.1、文件打开 fopen
MY_FILE *my_fopen(const char *path, const char *mode); //打开文件打开文件分为以下几步:
- 根据传入的
mode确认打开方式 - 通过系统接口
open打开文件 - 创建 MY_FILE 结构体,初始化内容
- 返回创建好的 MY_FILE 类型
因为打开文件存在多种失败情况:权限不对 / open 失败 / malloc 失败等,所以当打开文件失败后,需要返回 NULL
注意: 假设是因 malloc 失败的,那么在返回之前需要先关闭 fd,否则会造成资源浪费
// 打开文件
// 打开文件
MY_FILE *my_fopen(const char *path, const char *mode)
{assert(path && mode);// 确定打开方式int flags = 0; // 打开方式// 读:O_RDONLY 读+:O_RDONLY | O_WRONLY// 写:O_WRONLY | O_CREAT | O_TRUNC 写+:O_WRONLY | O_CREAT | O_TRUNC | O_RDONLY// 追加: O_WRONLY | O_CREAT | O_APPEND 追加+:O_WRONLY | O_CREAT | O_APPEND | O_RDONLY// 注意:不考虑 b 二进制读写的情况if (*mode == 'r'){flags |= O_RDONLY;if (strcmp("r+", mode) == 0)flags |= O_WRONLY;}else if (*mode == 'w' || *mode == 'a'){flags |= (O_WRONLY | O_CREAT);if (*mode == 'w')flags |= O_TRUNC;elseflags |= O_APPEND;if (strcmp("w+", mode) == 0 || strcmp("a+", mode) == 0)flags |= O_RDONLY;}else{// 无效打开方式assert(false);}// 根据打开方式,打开文件// 注意新建文件需要设置权限int fd = 0;if (flags & O_CREAT)fd = open(path, flags, 0666);elsefd = open(path, flags);if (fd == -1){// 打开失败的情况return NULL;}// 打开成功了,创建 MY_FILE 结构体,并返回MY_FILE *new_file = (MY_FILE *)malloc(sizeof(MY_FILE));if (new_file == NULL){// 此处不能断言,需要返回空close(fd); // 需要先把 fd 关闭perror("malloc FILE fail!");return NULL;}// 初始化 MY_FILEmemset(new_file->_buffer, '\0', BUFFER_SIZE); // 初始化缓冲区new_file->_current = 0; // 下标置0new_file->_flush = BUFFER_LINE; // 行刷新new_file->_fd = fd; // 设置文件描述符return new_file;
}2.2、文件关闭 fclose
int my_fclose(MY_FILE *fp); //关闭文件文件在关闭前,需要先将缓冲区中的内容进行冲刷,否则会造成数据丢失
注意:my_fclose返回值与close一致,因此可以复用
// 关闭文件
int my_fclose(MY_FILE *fp)
{assert(fp);// 刷新残余数据if (fp->_current > 0)my_fflush(fp);// 关闭 fdint ret = close(fp->_fd);// 释放已开辟的空间free(fp);fp = NULL;return ret;
}2.3、缓冲区刷新 fflush
int my_fflush(MY_FILE *stream); //缓冲区刷新缓冲区冲刷是一个十分重要的动作,它决定着 IO 是否正确,这里的 my_fflush 是将用户级缓冲区中的数据冲刷至内核级缓冲区
冲刷的本质:拷贝,用户先将数据拷贝给用户层面的缓冲区,再系统调用将用户级缓冲区拷贝给内核级缓冲区,最后才将数据由内核级缓冲区拷贝给文件
因此IO是非常影响效率的。数据传输过程必须遵循冯诺依曼体系结构
函数 fsync
- 将内核中的数据手动拷贝给目标文件(内核级缓冲区的刷新策略极为复杂,为了确保数据能正常传输,可以选择手动刷新)
- 注意: 在冲刷完用户级缓冲区后(write),需要将缓冲区清空,否则缓冲区就一直满载了
// 缓冲区刷新
int my_fflush(MY_FILE *stream)
{assert(stream);// 将数据写给文件int ret = write(stream->_fd, stream->_buffer, stream->_current);stream->_current = 0; // 每次刷新后,都需要清空缓冲区fsync(stream->_fd); // 将内核中的数据强制刷给磁盘(文件)if (ret != -1) return 0;else return -1;
}2.3、数据写入 fwrite
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb, MY_FILE *stream); //数据写入数据写入用户级缓冲区的步骤:
- 判断当前用户级缓冲区是否满载,如果满了,需要先刷新,再进行后续操作
- 获取当前待写入的数据大小
user_size及用户级缓冲区剩余大小my_size,方便进行后续操作 - 如果
my_size >= user_size,说明缓冲区容量足够,直接进行拷贝;否则说明缓冲区容量不足,需要重复冲刷->拷贝->再冲刷的过程,直到将数据全部拷贝 - 拷贝完成后,需要判断是否触发相应的刷新策略,比如
行刷新->最后一个字符是否为 \n,如果满足条件就刷新缓冲区 - 数据写入完成,返回实际写入的字节数(简化版,即
user_size)
如果是一次写不完的情况,需要通过循环写入数据,并且在缓冲区满后进行刷新,因为循环写入时,目标数据的读取位置是在不断变化的(一次读取一部分,不断后移),所以需要对读取位置和读取大小进行特殊处理
2.4、数据读取 fread
在进行数据读取时,需要经历 文件->内核级缓冲区->用户级缓冲区->目标空间的繁琐过程,并且还要考虑 用户级缓冲区是否能够一次读取完所有数据,若不能,则需要多次读取
注意:
- 读取前,如果用户级缓冲区中有数据的话,需要先将数据刷新给文件,方便后续进行操作
- 读取与写入不同,读取结束后,需要考虑 \0 的问题(在最后一个位置加),如果不加的话,会导致识别错误;
- 系统(内核)不需要 \0,但C语言中的字符串结尾必须加 \0,现在是 系统->用户(C语言)
// 数据读取
size_t my_fread(void *ptr, size_t size, size_t nmemb, MY_FILE *stream)
{// 数据读取前,需要先把缓冲区刷新if (stream->_current > 0)my_fflush(stream);size_t user_size = size * nmemb;size_t my_size = BUFFER_SIZE;// 先将数据读取到FILE缓冲区中,再赋给 ptrif (my_size >= user_size){// 此时缓冲区中足够存储用户需要的所有数据,只需要读取一次read(stream->_fd, stream->_buffer, my_size);memcpy(ptr, stream->_buffer, my_size);*((char *)ptr + my_size - 1) = '\0';}else{int ret = 1;size_t tmp = user_size;while (ret){// 一次读不完,需要多读取几次ret = read(stream->_fd, stream->_buffer, my_size);stream->_buffer[ret] = '\0';memcpy(ptr + (tmp - user_size), stream->_buffer, my_size);stream->_current = 0;user_size -= my_size;}}size_t readn = strlen(ptr);return readn;
}2.6 小结
用户在进行文件流操作时,实际要进行至少三次的拷贝:用户->用户级缓冲区->内核级缓冲区->文件,C语言 中众多文件流操作都是在完成 用户->用户级缓冲区 的这一次拷贝动作,其他语言也是如此,最终都是通过系统调用将数据冲刷到磁盘(文件)中
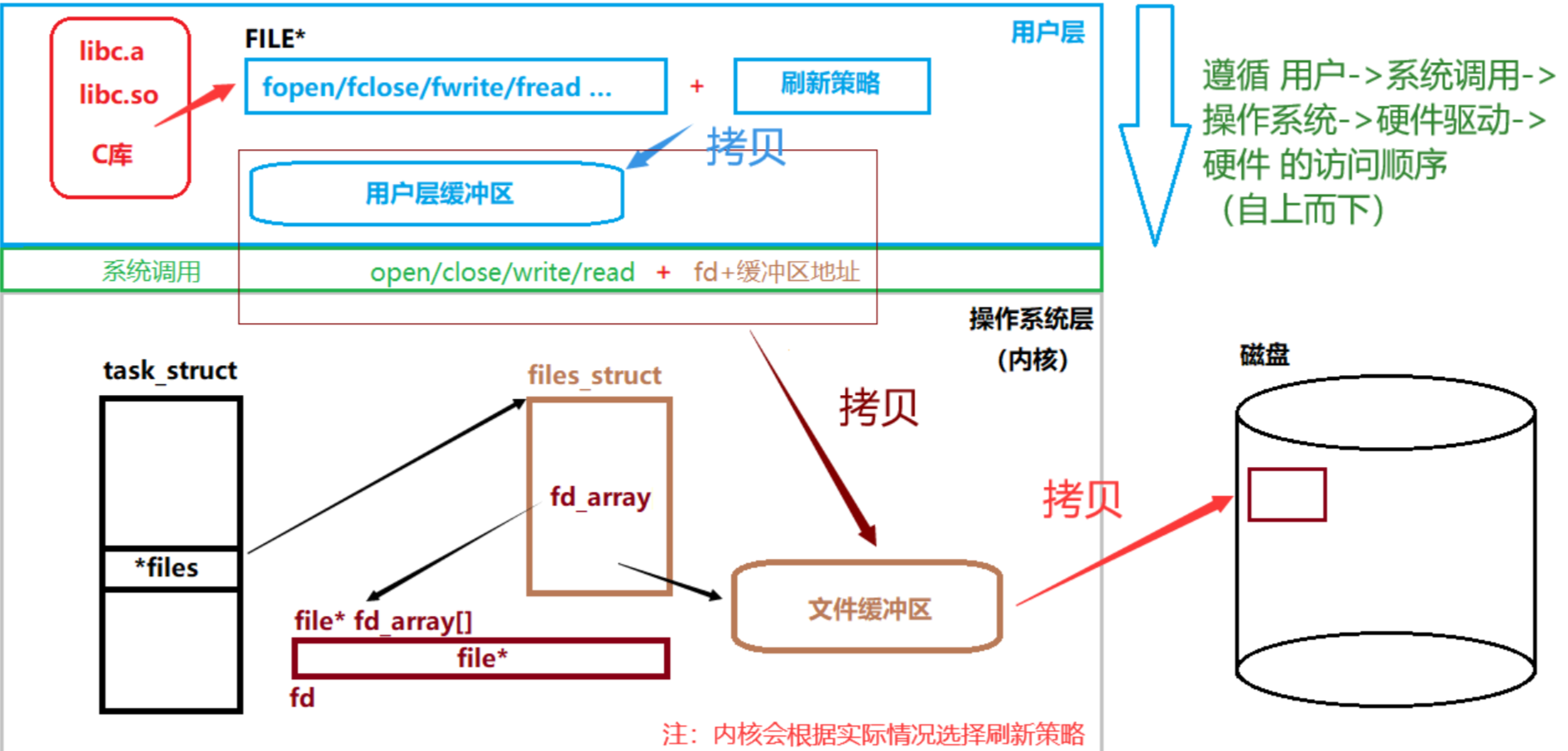
最后再简单提一下 printf 和 scanf 的工作原理
无论是什么类型,最终都要转为字符型进行存储,程序中的各种类型只是为了更好的解决问题
printf
- 根据格式读取数据,如整型、浮点型,并将其转为字符串
- 定义缓冲区,然后将字符串写入缓冲区(stdout)
- 最后结合一定的刷新策略,将数据进行冲刷
scanf
- 读取数据至缓冲区(stdin)
- 根据格式将字符串扫描分割,存入
字符指针数组 - 最后将字符串转为对应的类型,赋值给相应的变量
这也就解释了为什么要确保 输出/输入 格式与数据匹配,如果不匹配的话,会导致 读取/赋值 错误
本篇关于文件操作模拟实现的介绍就暂告段落啦,希望能对大家的学习产生帮助,欢迎各位佬前来支持斧正!!!



