摘要:大型语言模型(LLMs)已经显示出非凡的能力,优化它们的输入提示在最大化它们的性能方面起着关键作用。 然而,尽管LLM提示包括任务无关的系统提示和任务特定的用户提示,但现有的提示优化工作主要集中在针对单个查询或任务的用户提示上,而很大程度上忽视了系统提示,即一旦优化,适用于不同的任务和领域。 受此启发,我们引入了双层系统提示优化的新问题,其目标是设计对不同用户提示具有鲁棒性并可转移到未见过的任务的系统提示。 为了解决这个问题,我们提出了一个元学习框架,该框架通过在多个数据集上的各种用户提示上优化系统提示来对系统提示进行元学习,同时以迭代方式更新用户提示,以确保它们之间的协同作用。 我们在14个跨5个不同领域的未知数据集上进行了实验,实验结果表明,我们的方法产生的系统提示可以有效地泛化到不同的用户提示。 此外,我们的研究结果表明,优化的系统提示能够快速适应甚至看不见的任务,在实现性能改进的同时,需要更少的优化步骤来测试时间用户提示。Huggingface链接:Paper page,论文链接:2505.09666
研究背景和目的
研究背景
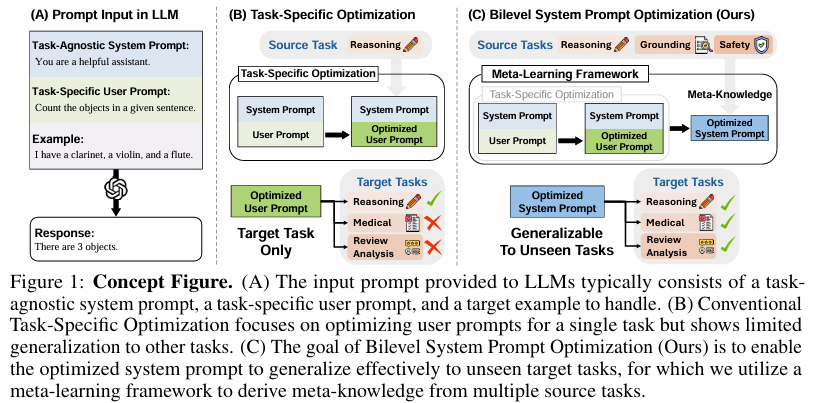
近年来,大型语言模型(LLMs)在各种任务和领域中展示了卓越的能力。这些模型通过接收输入提示(prompts)来指导其行为,并确保其输出与用户目标一致。输入提示通常包括系统提示(system prompts)和用户提示(user prompts)两部分。系统提示是任务无关的指令,定义了LLM的基础行为和约束,适用于多个任务和领域;而用户提示则是针对特定查询或任务设计的,旨在引出针对特定问题的响应。
随着LLMs的发展,其性能对提供的提示高度敏感,因此设计有效的提示变得至关重要。传统上,手动提示设计是主流方法,但这种方法劳动密集且可扩展性差。为了克服这些限制,自动提示优化领域应运而生,旨在通过利用LLMs本身或结合算法来自动改进提示,探索和生成更有效的提示变体。
然而,现有的提示优化研究主要集中在用户提示上,而忽视了系统提示的重要性。系统提示一旦优化,可以跨多个任务和领域应用,具有更广泛的适用性。此外,优化系统提示还可以为LLMs提供一个稳健的行为框架,使其能够更稳健地适应未见过的用户提示和领域,同时有可能与用户提示产生协同作用。
研究目的
本研究旨在填补现有研究在系统提示优化方面的空白,通过引入双层系统提示优化(Bilevel System Prompt Optimization, BSPO)问题,设计一种对多样用户提示具有鲁棒性且可转移到未见任务的系统提示。具体而言,本研究的目标包括:
- 提出双层系统提示优化问题:定义一个双层优化框架,其中上层优化目标是设计一个对多样用户提示具有鲁棒性的系统提示,下层优化目标是通过特定用户提示最大化任务性能。
- 开发元学习框架:提出一种基于元学习的框架,通过在多个数据集上的各种用户提示上优化系统提示,同时迭代更新用户提示以确保它们之间的协同作用。
- 验证系统提示的泛化能力:在多个未见过的数据集和领域上验证优化后的系统提示的有效性,展示其能够快速适应未见任务,并在测试时用户提示上实现改进的性能。
研究方法
双层优化框架
本研究将系统提示优化问题形式化为一个双层优化问题。上层优化旨在发现一个系统提示 s∗,该提示能够最大化跨任务分布 T 的性能,同时确保与针对特定任务 Ti 优化的用户提示 ui∗ 协同工作。下层优化则专注于为每个特定任务 Ti 更新用户提示 ui,以最大化任务特定性能,同时固定上层优化的系统提示 s。
形式化地,双层优化问题可以表示为:
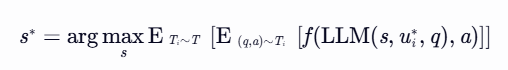
其中 ![]() 。
。
元学习框架
为了解决上述双层优化问题,本研究提出了一种基于元学习的框架,称为元级系统提示优化器(Meta-level System Prompt Optimizer, MetaSPO)。MetaSPO包含两个优化循环:内循环和外循环。
- 内循环:针对每个特定任务 Ti,通过分析当前用户提示在目标任务上的表现,识别错误响应,并进行失败分析。然后,基于分析结果生成多个候选用户提示,并通过性能评估选择性能最佳的用户提示。
- 外循环:通过聚合所有任务上的错误响应,分析当前系统提示的问题,并生成多个候选系统提示。然后,评估这些系统提示在多样用户提示和任务上的性能,选择性能最佳的系统提示。
MetaSPO通过迭代执行内循环和外循环,逐步优化系统提示和用户提示,确保它们之间的协同作用。
实验设置
本研究在14个未见过的数据集上进行了实验,这些数据集跨越了5个不同的领域:医疗、评论分析、推理、基础和安全。对于每个领域,收集了4个源任务来优化系统提示,并使用了未见过的目标任务来评估系统提示。实验中使用了Llama 3.2(3B)作为基础模型来生成响应,并使用GPT-4o mini作为提示优化器。
研究结果
泛化能力
实验结果表明,MetaSPO在未见过的泛化场景中显著优于基线方法。具体而言,在全局系统提示优化设置和领域系统提示优化设置下,MetaSPO在所有领域上的平均性能均优于默认系统提示和其他基线方法。这表明优化后的系统提示能够有效地泛化到多样的用户提示和未见过的任务。
源任务与目标任务的相似性
本研究还分析了源任务与目标任务之间的相似性对系统提示优化效果的影响。实验结果表明,当源任务与目标任务更相似时,优化后的系统提示效果更好。然而,即使源任务与目标任务相似性较低,MetaSPO仍然能够产生性能提升,表明其能够学习到一般化的知识,适用于多样的任务。
跨领域泛化
在更具挑战性的跨领域泛化场景中,MetaSPO同样表现优异。即使源任务和目标任务来自完全不同的领域,MetaSPO仍然能够产生性能提升,进一步证明了其稳健性和适应性。
测试时适应
在测试时适应场景中,本研究展示了优化后的系统提示能够加速用户提示的优化过程。具体而言,使用MetaSPO优化的系统提示在测试时用户提示上实现了更快的收敛和更好的性能,减少了优化步骤的数量。
研究局限
尽管MetaSPO在系统提示优化方面取得了显著成果,但本研究仍存在一些局限:
- 优化器LLM的能力依赖:MetaSPO的性能依赖于优化器LLM的能力。尽管本研究展示了即使使用小型开源优化器LLM,MetaSPO也能有效工作,但其上限性能仍然受到优化器能力的限制。
- 计算成本:虽然MetaSPO在测试时适应阶段具有高效性,但在系统提示优化阶段仍然需要较高的计算成本。这限制了其在资源受限环境中的应用。
- 泛化能力的局限性:尽管MetaSPO在多种场景下展示了强大的泛化能力,但在某些极端情况下,如源任务与目标任务差异极大时,其性能可能会受到影响。
未来研究方向
针对本研究的局限和现有研究的不足,未来研究可以关注以下几个方面:
- 提升优化器LLM的能力:探索更先进的优化器LLM,以进一步提升MetaSPO的上限性能。这可以通过使用更大的模型、更先进的训练技术或结合其他优化方法来实现。
- 降低计算成本:研究如何降低MetaSPO在系统提示优化阶段的计算成本,使其更适用于资源受限环境。这可以通过优化算法、减少迭代次数或使用更高效的计算资源来实现。
- 增强泛化能力:进一步探索如何增强MetaSPO在极端情况下的泛化能力。这可以通过引入更多的多样性到源任务中、使用更复杂的元学习策略或结合其他迁移学习方法来实现。
- 多模态系统提示优化:将MetaSPO扩展到多模态领域,研究如何优化适用于文本、图像、音频等多种模态的系统提示。这将为LLMs在更广泛的应用场景中提供更强大的支持。
- 可解释性和安全性:研究如何提升MetaSPO优化后的系统提示的可解释性和安全性。这可以通过引入可解释性技术、设计安全性约束或结合人类反馈来实现,以确保LLMs的行为符合用户期望和社会规范。



