Pose 识别模型介绍
Pose 识别是计算机视觉领域的一个重要研究方向,其目标是从图像或视频中检测出人体的关键点位置,从而估计出人体的姿态。这项技术在许多领域都有广泛的应用,如动作捕捉、人机交互、体育分析、安防监控等。
Pose 识别模型的发展历程
Pose 识别技术的发展经历了多个阶段,从早期的基于手工特征的方法,到后来的基于深度学习的方法,性能不断提升。以下是一些具有代表性的 Pose 识别模型:
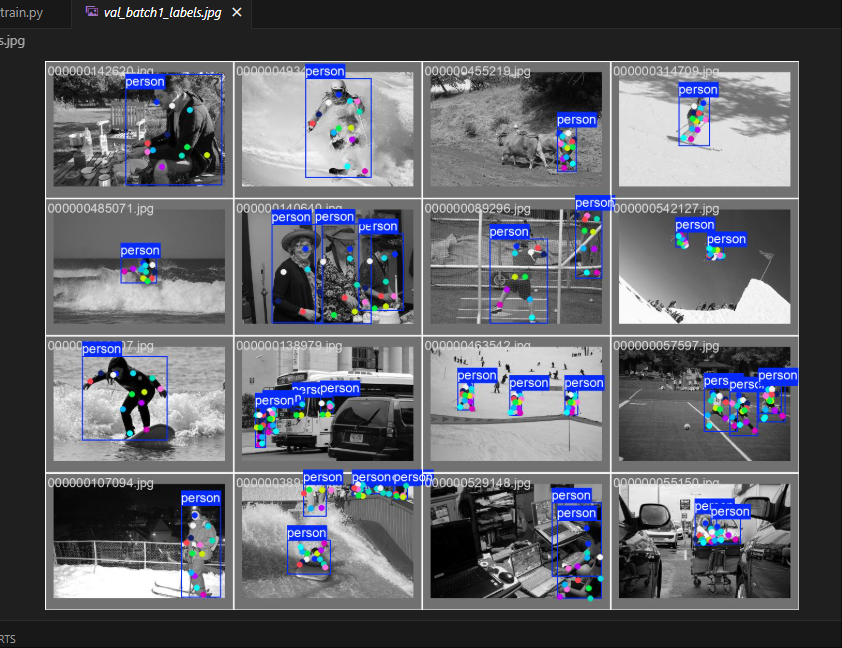
-
OpenPose:由 CMU 团队开发,是第一个实现多人实时姿态估计的系统。它采用了自下而上的方法,先检测图像中的所有关键点,再通过 Part Affinity Fields (PAFs) 将关键点关联到不同的人身上。
-
AlphaPose:在 OpenPose 的基础上进行了改进,提出了参数化姿态非极大值抑制 (Parametric Pose NMS) 方法,提高了姿态估计的精度。
-
HRNet:通过高分辨率表征网络,能够在整个网络处理过程中保持高分辨率表征,从而获得更精确的关键点定位。
-
SimpleBaseline:证明了简单的卷积神经网络架构在姿态估计任务上也能取得很好的效果,强调了数据增强和模型集成的重要性。
-
DETR:将 Transformer 引入姿态估计任务,提出了 End-to-End 的姿态估计方法,避免了传统方法中的后处理步骤。
Pose 识别模型的原理
Pose 识别模型的原理可以分为两种主要方法:自下而上 (bottom-up) 和自上而下 (top-down)。
自下而上方法
自下而上方法先检测图像中的所有关键点,然后将这些关键点分组到不同的人身上。这种方法的优点是处理速度快,适合处理多人场景;缺点是关键点分组的准确性可能较低。
以 OpenPose 为例,其核心原理如下:
-
特征提取:使用卷积神经网络提取图像的特征。
-
关键点检测:网络输出两个分支,一个分支用于检测关键点的置信度图 (confidence maps),另一个分支用于检测 Part Affinity Fields (PAFs)。
-
关键点关联:通过 PAFs 将检测到的关键点关联到不同的人身上。PAFs 是一种二维向量场,表示两个关键点之间的关联程度和方向。
自上而下方法
自上而下方法先检测图像中的人,然后对每个人分别进行姿态估计。这种方法的优点是精度高,缺点是处理速度较慢,特别是在处理多人场景时。
以 SimpleBaseline 为例,其核心原理如下:
-
人体检测:使用目标检测算法检测图像中的人。
-
区域裁剪:根据检测到的人体边界框,裁剪出人体区域。
-
关键点估计:将裁剪出的人体区域输入到关键点估计网络中,输出人体关键点的位置。
Pose 识别模型的应用场景
Pose 识别技术在许多领域都有广泛的应用:
-
动作捕捉:在电影制作、游戏开发和虚拟现实中,用于捕捉演员或用户的动作。
-
人机交互:通过识别人体姿态,实现无需控制器的人机交互,如手势控制、姿态识别等。
-
体育分析:分析运动员的动作姿态,帮助教练和运动员改进技术,预防受伤。
-
健康监测:监测老年人或病人的姿态和动作,及时发现跌倒等异常情况。
-
安防监控:通过分析人员的姿态和行为,检测异常行为,如入侵、斗殴等。
Pose 识别模型的代码实现
下面我们将使用 Python 和 PyTorch 实现一个基于 HRNet 的 Pose 识别模型。HRNet 是一个高性能的姿态估计模型,能够保持高分辨率的特征表示,从而获得更精确的关键点定位。
首先,我们需要安装必要的库:
pip install torch torchvision torchaudio
pip install opencv-python numpy matplotlib
pip install pycocotools
接下来,我们实现 HRNet 模型的代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import cv2
import matplotlib.pyplot as plt
from torchvision import transforms
from pycocotools.coco import COCO
import os# 定义HRNet的基本模块
class BasicBlock(nn.Module):expansion = 1def __init__(self, inplanes, planes, stride=1, downsample=None):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride,padding=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1,padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.downsample = downsampleself.stride = stridedef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return outclass Bottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, downsample=None):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(planes * self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return out# 定义HRNet的多分辨率模块
class HighResolutionModule(nn.Module):def __init__(self, num_branches, blocks, num_blocks, num_inchannels,num_channels, multi_scale_output=True):super(HighResolutionModule, self).__init__()self._check_branches(num_branches, blocks, num_blocks, num_inchannels, num_channels)self.num_inchannels = num_inchannelsself.num_branches = num_branchesself.multi_scale_output = multi_scale_outputself.branches = self._make_branches(num_branches, blocks, num_blocks, num_channels)self.fuse_layers = self._make_fuse_layers()self.relu = nn.ReLU(True)def _check_branches(self, num_branches, blocks, num_blocks,num_inchannels, num_channels):if num_branches != len(num_blocks):error_msg = 'NUM_BRANCHES({}) <> NUM_BLOCKS({})'.format(num_branches, len(num_blocks))raise ValueError(error_msg)if num_branches != len(num_channels):error_msg = 'NUM_BRANCHES({}) <> NUM_CHANNELS({})'.format(num_branches, len(num_channels))raise ValueError(error_msg)if num_branches != len(num_inchannels):error_msg = 'NUM_BRANCHES({}) <> NUM_INCHANNELS({})'.format(num_branches, len(num_inchannels))raise ValueError(error_msg)def _make_one_branch(self, branch_index, block, num_blocks, num_channels,stride=1):downsample = Noneif stride != 1 or \self.num_inchannels[branch_index] != num_channels[branch_index] * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.num_inchannels[branch_index],num_channels[branch_index] * block.expansion,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(num_channels[branch_index] * block.expansion),)layers = []layers.append(block(self.num_inchannels[branch_index],num_channels[branch_index], stride, downsample))self.num_inchannels[branch_index] = \num_channels[branch_index] * block.expansionfor i in range(1, num_blocks[branch_index]):layers.append(block(self.num_inchannels[branch_index],num_channels[branch_index]))return nn.Sequential(*layers)def _make_branches(self, num_branches, block, num_blocks, num_channels):branches = []for i in range(num_branches):branches.append(self._make_one_branch(i, block, num_blocks, num_channels))return nn.ModuleList(branches)def _make_fuse_layers(self):if self.num_branches == 1:return Nonenum_branches = self.num_branchesnum_inchannels = self.num_inchannelsfuse_layers = []for i in range(num_branches if self.multi_scale_output else 1):fuse_layer = []for j in range(num_branches):if j > i:fuse_layer.append(nn.Sequential(nn.Conv2d(num_inchannels[j],num_inchannels[i],1,1,0,bias=False),nn.BatchNorm2d(num_inchannels[i]),nn.Upsample(scale_factor=2**(j-i), mode='nearest')))elif j == i:fuse_layer.append(None)else:conv3x3s = []for k in range(i-j):if k == i-j-1:num_outchannels_conv3x3 = num_inchannels[i]conv3x3s.append(nn.Sequential(nn.Conv2d(num_inchannels[j],num_outchannels_conv3x3,3, 2, 1, bias=False),nn.BatchNorm2d(num_outchannels_conv3x3)))else:num_outchannels_conv3x3 = num_inchannels[j]conv3x3s.append(nn.Sequential(nn.Conv2d(num_inchannels[j],num_outchannels_conv3x3,3, 2, 1, bias=False),nn.BatchNorm2d(num_outchannels_conv3x3),nn.ReLU(True)))fuse_layer.append(nn.Sequential(*conv3x3s))fuse_layers.append(nn.ModuleList(fuse_layer))return nn.ModuleList(fuse_layers)def get_num_inchannels(self):return self.num_inchannelsdef forward(self, x):if self.num_branches == 1:return [self.branches[0](x[0])]for i in range(self.num_branches):x[i] = self.branches[i](x[i])x_fuse = []for i in range(len(self.fuse_layers)):y = x[0] if i == 0 else self.fuse_layers[i][0](x[0])for j in range(1, self.num_branches):if i == j:y = y + x[j]else:y = y + self.fuse_layers[i][j](x[j])x_fuse.append(self.relu(y))return x_fuse# 定义HRNet模型
class PoseHighResolutionNet(nn.Module):def __init__(self, cfg, **kwargs):self.inplanes = 64super(PoseHighResolutionNet, self).__init__()# stem netself.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1,bias=False)self.bn1 = nn.BatchNorm2d(64)self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1,bias=False)self.bn2 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.layer1 = self._make_layer(Bottleneck, 64, 4)# build stage 2self.stage2_cfg = cfg['MODEL']['EXTRA']['STAGE2']num_channels = self.stage2_cfg['NUM_CHANNELS']block = self._get_block(self.stage2_cfg['BLOCK'])num_channels = [num_channels[i] * block.expansion for i in range(len(num_channels))]self.transition1 = self._make_transition_layer([256], num_channels)self.stage2, pre_stage_channels = self._make_stage(self.stage2_cfg, num_channels)# build stage 3self.stage3_cfg = cfg['MODEL']['EXTRA']['STAGE3']num_channels = self.stage3_cfg['NUM_CHANNELS']block = self._get_block(self.stage3_cfg['BLOCK'])num_channels = [num_channels[i] * block.expansion for i in range(len(num_channels))]self.transition2 = self._make_transition_layer(pre_stage_channels, num_channels)self.stage3, pre_stage_channels = self._make_stage(self.stage3_cfg, num_channels)# build stage 4self.stage4_cfg = cfg['MODEL']['EXTRA']['STAGE4']num_channels = self.stage4_cfg['NUM_CHANNELS']block = self._get_block(self.stage4_cfg['BLOCK'])num_channels = [num_channels[i] * block.expansion for i in range(len(num_channels))]self.transition3 = self._make_transition_layer(pre_stage_channels, num_channels)self.stage4, pre_stage_channels = self._make_stage(self.stage4_cfg, num_channels, multi_scale_output=False)# final layerself.final_layer = nn.Conv2d(in_channels=pre_stage_channels[0],out_channels=cfg['MODEL']['NUM_JOINTS'],kernel_size=cfg['MODEL']['EXTRA']['FINAL_CONV_KERNEL'],stride=1,padding=1 if cfg['MODEL']['EXTRA']['FINAL_CONV_KERNEL'] == 3 else 0)self.pretrained_layers = cfg['MODEL']['EXTRA']['PRETRAINED_LAYERS']def _get_block(self, name):if name == 'BASIC':return BasicBlockelif name == 'BOTTLENECK':return Bottleneckelse:raise ValueError('Block name {} not supported'.format(name))def _make_transition_layer(self, num_channels_pre_layer, num_channels_cur_layer):num_branches_cur = len(num_channels_cur_layer)num_branches_pre = len(num_channels_pre_layer)transition_layers = []for i in range(num_branches_cur):if i < num_branches_pre:if num_channels_cur_layer[i] != num_channels_pre_layer[i]:transition_layers.append(nn.Sequential(nn.Conv2d(num_channels_pre_layer[i],num_channels_cur_layer[i],3,1,1,bias=False),nn.BatchNorm2d(num_channels_cur_layer[i]),nn.ReLU(inplace=True)))else:transition_layers.append(None)else:conv3x3s = []for j in range(i+1-num_branches_pre):inchannels = num_channels_pre_layer[-1]outchannels = num_channels_cur_layer[i] \if j == i-num_branches_pre else inchannelsconv3x3s.append(nn.Sequential(nn.Conv2d(inchannels, outchannels, 3, 2, 1, bias=False),nn.BatchNorm2d(outchannels),nn.ReLU(inplace=True)))transition_layers.append(nn.Sequential(*conv3x3s))return nn.ModuleList(transition_layers)def _make_layer(self, block, planes, blocks, stride=1):downsample = Noneif stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(planes * block.expansion),)layers = []layers.append(block(self.inplanes, planes, stride, downsample))self.inplanes = planes * block.expansionfor i in range(1, blocks):layers.append(block(self.inplanes, planes))return nn.Sequential(*layers)def _make_stage(self, layer_config, num_inchannels,multi_scale_output=True):num_modules = layer_config['NUM_MODULES']num_branches = layer_config['NUM_BRANCHES']num_blocks = layer_config['NUM_BLOCKS']num_channels = layer_config['NUM_CHANNELS']block = self._get_block(layer_config['BLOCK'])fuse_method = layer_config['FUSE_METHOD']modules = []for i in range(num_modules):# multi_scale_output is only used last moduleif not multi_scale_output and i == num_modules - 1:reset_multi_scale_output = Falseelse:reset_multi_scale_output = Truemodules.append(HighResolutionModule(num_branches,block,num_blocks,num_inchannels,num_channels,reset_multi_scale_output))num_inchannels = modules[-1].get_num_inchannels()return nn.Sequential(*modules), num_inchannelsdef forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.conv2(x)x = self.bn2(x)x = self.relu(x)x = self.layer1(x)x_list = []for i in range(self.stage2_cfg['NUM_BRANCHES']):if self.transition1[i] is not None:x_list.append(self.transition1[i](x))else:x_list.append(x)y_list = self.stage2(x_list)x_list = []for i in range(self.stage3_cfg['NUM_BRANCHES']):if self.transition2[i] is not None:if i < self.stage2_cfg['NUM_BRANCHES']:x_list.append(self.transition2[i](y_list[i]))else:x_list.append(self.transition2[i](y_list[-1]))else:x_list.append(y_list[i])y_list = self.stage3(x_list)x_list = []for i in range(self.stage4_cfg['NUM_BRANCHES']):if self.transition3[i] is not None:if i < self.stage3_cfg['NUM_BRANCHES']:x_list.append(self.transition3[i](y_list[i]))else:x_list.append(self.transition3[i](y_list[-1]))else:x_list.append(y_list[i])y_list = self.stage4(x_list)x = self.final_layer(y_list[0])return xdef init_weights(self, pretrained=''):print('=> init weights from normal distribution')for m in self.modules():if isinstance(m, nn.Conv2d):# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')nn.init.normal_(m.weight, std=0.001)for name, _ in m.named_parameters():if name in ['bias']:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.ConvTranspose2d):nn.init.normal_(m.weight, std=0.001)for name, _ in m.named_parameters():if name in ['bias']:nn.init.constant_(m.bias, 0)if os.path.isfile(pretrained):pretrained_state_dict = torch.load(pretrained)print('=> loading pretrained model {}'.format(pretrained))need_init_state_dict = {}for name, m in pretrained_state_dict.items():if name.split('.')[0] in self.pretrained_layers \or self.pretrained_layers[0] is '*':need_init_state_dict[name] = mself.load_state_dict(need_init_state_dict, strict=False)elif pretrained:print('=> unable to load pretrained model {}'.format(pretrained))# 配置文件
def get_cfg():cfg = {'MODEL': {'NAME': 'pose_hrnet','NUM_JOINTS': 17,'EXTRA': {'PRETRAINED_LAYERS': ['*'],'STEM_INPLANES': 64,'FINAL_CONV_KERNEL': 1,'STAGE2': {'NUM_MODULES': 1,'NUM_BRANCHES': 2,'BLOCK': 'BASIC','NUM_BLOCKS': [4, 4],'NUM_CHANNELS': [32, 64],'FUSE_METHOD': 'SUM',},'STAGE3': {'NUM_MODULES': 4,'NUM_BRANCHES': 3,'BLOCK': 'BASIC','NUM_BLOCKS': [4, 4, 4],'NUM_CHANNELS': [32, 64, 128],'FUSE_METHOD': 'SUM',},'STAGE4': {'NUM_MODULES': 3,'NUM_BRANCHES': 4,'BLOCK': 'BASIC','NUM_BLOCKS': [4, 4, 4, 4],'NUM_CHANNELS': [32, 64, 128, 256],'FUSE_METHOD': 'SUM',},}}}return cfg# 创建HRNet模型
def get_pose_net(cfg, is_train=True):model = PoseHighResolutionNet(cfg)if is_train and cfg['MODEL']['INIT_WEIGHTS']:model.init_weights(cfg['MODEL']['PRETRAINED'])return model# 加载COCO数据集
class COCODataset(torch.utils.data.Dataset):def __init__(self, root_dir, json_file, transform=None):self.root_dir = root_dirself.coco = COCO(json_file)self.img_ids = list(self.coco.imgs.keys())self.transform = transformself.joints_name = ['nose', 'left_eye', 'right_eye', 'left_ear', 'right_ear','left_shoulder', 'right_shoulder', 'left_elbow', 'right_elbow','left_wrist', 'right_wrist', 'left_hip', 'right_hip','left_knee', 'right_knee', 'left_ankle', 'right_ankle']def __len__(self):return len(self.img_ids)def __getitem__(self, idx):img_id = self.img_ids[idx]img_info = self.coco.loadImgs(img_id)[0]img_path = os.path.join(self.root_dir, img_info['file_name'])img = cv2.imread(img_path)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 获取人体标注ann_ids = self.coco.getAnnIds(imgIds=img_id)anns = self.coco.loadAnns(ann_ids)# 只考虑第一个人if len(anns) > 0:ann = anns[0]bbox = ann['bbox']joints = ann['keypoints']# 裁剪人体区域x, y, w, h = bboximg_crop = img[int(y):int(y+h), int(x):int(x+w)]# 调整关节点坐标joints = np.array(joints).reshape(-1, 3)joints[:, 0] -= xjoints[:, 1] -= y# 应用变换if self.transform:img_crop = self.transform(img_crop)# 生成热图heatmaps = self._generate_heatmaps(joints, img_crop.shape[1:])return img_crop, heatmaps# 如果没有检测到人体,返回全零热图if self.transform:img = self.transform(img)heatmaps = torch.zeros(17, img.shape[1], img.shape[2])return img, heatmapsdef _generate_heatmaps(self, joints, img_size, sigma=2):"""生成关键点的热图"""num_joints = joints.shape[0]heatmaps = np.zeros((num_joints, img_size[0], img_size[1]), dtype=np.float32)for joint_id in range(num_joints):# 如果关键点不可见,跳过if joints[joint_id, 2] == 0:continue# 计算高斯核x, y = int(joints[joint_id, 0]), int(joints[joint_id, 1])if x < 0 or y < 0 or x >= img_size[1] or y >= img_size[0]:continue# 生成高斯热图xx, yy = np.meshgrid(np.arange(img_size[1]), np.arange(img_size[0]))heatmap = np.exp(-((xx - x) ** 2 + (yy - y) ** 2) / (2 * sigma ** 2))heatmap[heatmap > np.finfo(heatmap.dtype).eps] = 1# 将热图添加到结果中heatmaps[joint_id] = heatmapreturn torch.from_numpy(heatmaps)# 训练函数
def train_model(model, train_loader, criterion, optimizer, device, epochs):model.train()for epoch in range(epochs):running_loss = 0.0for i, (images, heatmaps) in enumerate(train_loader):images = images.to(device)heatmaps = heatmaps.to(device)# 前向传播outputs = model(images)loss = criterion(outputs, heatmaps)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()running_loss += loss.item()# 打印训练信息print(f'Epoch {epoch+1}/{epochs}, Loss: {running_loss/len(train_loader):.4f}')print('Training finished.')# 测试函数
def test_model(model, test_loader, device):model.eval()with torch.no_grad():for images, heatmaps in test_loader:images = images.to(device)outputs = model(images)# 可视化结果for i in range(images.size(0)):img = images[i].cpu().permute(1, 2, 0).numpy()pred_heatmaps = outputs[i].cpu().numpy()# 显示原图plt.figure(figsize=(10, 5))plt.subplot(121)plt.imshow(img)plt.title('Input Image')# 显示预测的关键点plt.subplot(122)plt.imshow(img)for j in range(pred_heatmaps.shape[0]):# 找到热图中的最大值位置max_idx = np.unravel_index(np.argmax(pred_heatmaps[j]), pred_heatmaps[j].shape)plt.plot(max_idx[1], max_idx[0], 'ro', markersize=5)plt.title('Predicted Keypoints')plt.show()# 主函数
def main():# 设置设备device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 获取配置cfg = get_cfg()# 创建模型model = get_pose_net(cfg, is_train=True)model = model.to(device)# 定义数据变换transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])# 加载数据集# 注意:这里需要替换为实际的COCO数据集路径train_dataset = COCODataset(root_dir='path/to/coco/train2017',json_file='path/to/coco/annotations/person_keypoints_train2017.json',transform=transform)test_dataset = COCODataset(root_dir='path/to/coco/val2017',json_file='path/to/coco/annotations/person_keypoints_val2017.json',transform=transform)# 创建数据加载器train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, shuffle=True, num_workers=4)test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=4, shuffle=False, num_workers=4)# 定义损失函数和优化器criterion = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 训练模型train_model(model, train_loader, criterion, optimizer, device, epochs=10)# 测试模型test_model(model, test_loader, device)# 保存模型torch.save(model.state_dict(), 'hrnet_pose_estimation.pth')if __name__ == '__main__':main()
以上代码实现了一个基于 HRNet 的姿态估计模型,包括模型定义、数据加载、训练和测试等功能。这个模型可以从图像中检测出人体的 17 个关键点,包括鼻子、眼睛、耳朵、肩膀、肘部、手腕、臀部、膝盖和脚踝。
模型训练和评估
要训练这个模型,你需要准备 COCO 数据集,这是一个广泛用于姿态估计的数据集,包含约 20 万张图像和 80 个类别。你可以从 COCO 官方网站下载数据集,并按照上面代码中的路径设置进行配置。
训练过程中,模型会学习预测每个关键点的热图 (heatmap),热图中的峰值表示关键点的位置。训练完成后,你可以使用测试函数来评估模型的性能,并可视化预测结果。
模型应用
训练好的姿态估计模型可以应用于各种场景,如动作分析、体育训练、人机交互等。你可以根据自己的需求,将这个模型集成到更大的系统中,实现更复杂的功能。

)




