DeepSeek大模型高性能核心技术与多模态融合开发 - 商品搜索 - 京东
图像的加噪与模型训练
在扩散模型的训练过程中,首先需要对输入的信号进行加噪处理,经典的加噪过程是在图像进行向量化处理后在其中添加正态分布,而正态分布的值也是与时间步相关的。这样逐步向图像中添加噪声,直到图像变得完全噪声化。
import torch T = 1000 # Diffusion过程的总步数 # 前向diffusion计算参数
# (T,) 生成一个线性间隔的tensor,用于计算每一步的噪声水平
betas = torch.linspace(0.0001, 0.02, T)
alphas = 1 - betas # (T,) 计算每一步的保留率
# alpha_t累乘 (T,),计算每一步累积的保留率
alphas_cumprod = torch.cumprod(alphas, dim=-1)
# alpha_t-1累乘(T,),为计算方差做准备
alphas_cumprod_prev = torch.cat((torch.tensor([1.0]), alphas_cumprod[:-1]), dim=-1)
# denoise用的方差(T,),计算每一步的去噪方差
variance = (1 - alphas) * (1 - alphas_cumprod_prev) / (1 - alphas_cumprod) # 执行前向加噪
def forward_add_noise(x, t): # batch_x: (batch,channel,height,width), batch_t: (batch_size,) noise = torch.randn_like(x) # 为每幅图片生成第t步的高斯噪声 (batch,channel,height,width) # 根据当前步数t,获取对应的累积保留率,并调整其形状以匹配输入x的形状 batch_alphas_cumprod = alphas_cumprod[t].view(x.size(0), 1, 1, 1) # 基于公式直接生成第t步加噪后的图片 x = torch.sqrt(batch_alphas_cumprod) * x + torch.sqrt(1 - batch_alphas_cumprod) * noise return x, noise # 返回加噪后的图片和生成的噪声
上面这段代码首先定义了扩散模型的前向过程中需要的参数,包括每一步的噪声水平betas、保留率alphas、累积保留率alphas_cumprod以及用于去噪的方差variance。然后定义了一个函数forward_add_noise,该函数接受一个图像x和步数t作为输入。根据扩散模型的前向过程,向图像中添加噪声,并返回加噪后的图像和生成的噪声。
读者可以采用以下代码尝试完成为图像添加噪声的演示:
import matplotlib.pyplot as plt
from dataset import MNISTdataset=MNIST()
# 两幅图片拼batch, (2,1,48,48)
x=torch.stack((dataset[0][0],dataset[1][0]),dim=0) # 原图
plt.figure(figsize=(10,10))
plt.subplot(1,2,1)
plt.imshow(x[0].permute(1,2,0))
plt.subplot(1,2,2)
plt.imshow(x[1].permute(1,2,0))
plt.show()# 随机时间步
t=torch.randint(0,T,size=(x.size(0),))
print('t:',t)# 加噪
x=x*2-1 # [0,1]像素值调整到[-1,1]之间,以便与高斯噪声值范围匹配
x,noise=forward_add_noise(x,t)
print('x:',x.size())
print('noise:',noise.size())# 加噪图
plt.figure(figsize=(10,10))
plt.subplot(1,2,1)
plt.imshow(((x[0]+1)/2).permute(1,2,0))
plt.subplot(1,2,2)
plt.imshow(((x[0]+1)/2).permute(1,2,0))
plt.show()
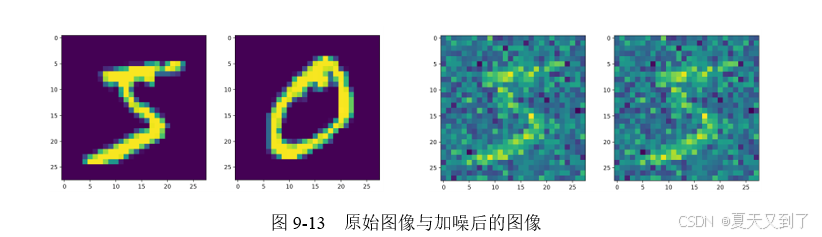
运行结果如图9-13所示。
在此基础上,我们可以完成对Dit模型的训练,代码如下:
from torch.utils.data import DataLoader # 导入PyTorch的数据加载工具
from dataset import MNIST # 从dataset模块导入MNIST数据集类
from diffusion import forward_add_noise # 从diffusion模块导入forward_add_noise函数,用于向图像添加噪声
import torch # 导入PyTorch库
from torch import nn # 从PyTorch导入nn模块,包含构建神经网络所需的工具
import os # 导入os模块,用于处理文件和目录路径
from dit import DiT # 从dit模块导入DiT模型
# 判断是否有可用的CUDA设备,如果有则使用GPU,否则使用CPU
DEVICE='cuda' if torch.cuda.is_available() else 'cpu' dataset=MNIST() # 实例化MNIST数据集对象 T = 1000 # 设置扩散过程中的总时间步数
model=DiT(img_size=28,patch_size=4,channel=1,emb_size=64,label_num=10,dit_num=3,head=4).to(DEVICE) # 实例化DiT模型并移至指定设备
#model.load_state_dict(torch.load('./saver/model.pth')) # 可选:加载预训练模型参数 # 使用Adam优化器,学习率设置为0.001
optimzer=torch.optim.Adam(model.parameters(),lr=1e-3)
loss_fn=nn.L1Loss() # 使用L1损失函数(即绝对值误差均值) '''训练模型'''
EPOCH=300 # 设置训练的总轮次
BATCH_SIZE=300 # 设置每个批次的大小 if __name__ == '__main__': from tqdm import tqdm # 导入tqdm库,用于在训练过程中显示进度条 dataloader=DataLoader(dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=10,persistent_workers=True) # 创建数据加载器 iter_count=0 for epoch in range(EPOCH): # 遍历每个训练轮次 pbar = tqdm(dataloader, total=len(dataloader)) # 初始化进度条 for imgs,labels in pbar: # 遍历每个批次的数据 x=imgs*2-1 # 将图像的像素范围从[0,1]转换到[-1,1],与噪声高斯分布的范围对应 t=torch.randint(0,T,(imgs.size(0),)) # 为每幅图片生成一个随机的t时刻 y=labels # 向图像添加噪声,返回加噪后的图像和添加的噪声x,noise=forward_add_noise(x,t) # 模型预测添加的噪声pred_noise=model(x.to(DEVICE),t.to(DEVICE),y.to(DEVICE)) # 计算预测噪声和实际噪声之间的L1损失loss=loss_fn(pred_noise,noise.to(DEVICE)) optimzer.zero_grad() # 清除之前的梯度 loss.backward() # 反向传播,计算梯度 optimzer.step() # 更新模型参数 # 更新进度条描述pbar.set_description(f"epoch:{epoch + 1}, train_loss:{loss.item():.5f}") if epoch % 20 == 0: # 每20轮保存一次模型 torch.save(model.state_dict(),'./saver/model.pth') print("base diffusion saved")
读者自行查看代码运行结果。
基于注意力模型的可控图像生成
DiT模型的可控图像生成是在我们训练的基础上,逐渐对正态分布的噪声图像进行按步骤的脱噪过程。这一过程不仅要求模型具备精准的噪声预测能力,还需确保脱噪步骤的细腻与连贯,从而最终实现从纯粹噪声到目标图像的华丽蜕变。
完整的可控图像生成代码如下:
import torch from dit import DiT
import matplotlib.pyplot as plt
# 导入diffusion模块中的所有内容,这通常包含一些与扩散模型相关的预定义变量和函数
from diffusion import * # 设置设备为GPU或CPU
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
DEVICE = "cpu" # 强制使用CPU T = 1000 # 扩散步骤的总数 def backward_denoise(model,x,y): steps=[x.clone(),] # 初始化步骤列表,包含初始噪声图像 global alphas,alphas_cumprod,variance # 这些是从diffusion模块导入的全局变量 x=x.to(DEVICE) # 将输入x移动到指定的设备 alphas=alphas.to(DEVICE) alphas_cumprod=alphas_cumprod.to(DEVICE) variance=variance.to(DEVICE) y=y.to(DEVICE) # 将标签y移动到指定的设备 model.eval() # 设置模型为评估模式 with torch.no_grad(): # 在不计算梯度的情况下运行,节省内存和计算资源 for time in range(T-1,-1,-1): # 从T-1到0逆序迭代 t=torch.full((x.size(0),),time).to(DEVICE) # 创建一个包含当前时间步的tensor # 预测x_t时刻的噪声 noise=model(x,t,y) # 生成t-1时刻的图像 shape=(x.size(0),1,1,1) mean=1/torch.sqrt(alphas[t].view(*shape))* \ ( x- (1-alphas[t].view(*shape))/torch.sqrt(1-alphas_cumprod[t].view(*shape))*noise ) if time!=0: x=mean+ \ torch.randn_like(x)* \ torch.sqrt(variance[t].view(*shape)) else: x=mean x=torch.clamp(x, -1.0, 1.0).detach() # 确保x的值在[-1,1]之间,并分离计算图 steps.append(x) return steps # 初始化DiT模型
model=DiT(img_size=28,patch_size=4,channel=1,emb_size=64,label_num=10,dit_num=3,head=4).to(DEVICE)
model.load_state_dict(torch.load('./saver/model.pth')) # 加载模型权重 # 生成噪声图
batch_size=10
x=torch.randn(size=(batch_size,1,28,28)) # 生成随机噪声图像
y=torch.arange(start=0,end=10,dtype=torch.long) # 生成标签 # 逐步去噪得到原图
steps=backward_denoise(model,x,y) # 绘制数量
num_imgs=20 # 绘制还原过程
plt.figure(figsize=(15,15))
for b in range(batch_size): for i in range(0,num_imgs): idx=int(T/num_imgs)*(i+1) # 计算要绘制的步骤索引 # 像素值还原到[0,1] final_img=(steps[idx][b].to('cpu')+1)/2 # tensor转回PIL图 final_img=final_img.permute(1,2,0) # 调整通道顺序以匹配图像格式 plt.subplot(batch_size,num_imgs,b*num_imgs+i+1)plt.imshow(final_img)
plt.show() # 显示图像
上面的代码展示了使用DiT进行图像去噪的完整过程。首先,它导入了必要的库和模块,包括PyTorch、DiT模型、matplotlib绘图模块,以及从diffusion模块导入的一些预定义变量和函数,这些通常与扩散模型相关。然后,代码设置了计算设备为CPU(尽管提供了检测GPU可用性的选项),并定义了扩散步骤的总数。
backward_denoise函数是实现图像去噪的核心。它接受一个DiT模型、一批噪声图像以及对应的标签作为输入。在这个函数内部,它首先将输入移动到指定的计算设备,然后将模型设置为评估模式,并开始一个不计算梯度的循环,从最后一个扩散步骤开始逆向迭代至第一步。在每一步中,它使用模型预测当前步骤的噪声,然后根据扩散模型的公式计算上一步的图像。这个过程一直持续到生成原始图像。
接下来,代码初始化了DiT模型,并加载了预训练的权重。然后,它生成了一批随机噪声图像和对应的标签,并使用backward_denoise函数对这些噪声图像进行去噪,逐步还原出原始图像。运行结果如图9-14所示。

图9-14 基于DiT模型的可控图像生成
可见,我们使用生成代码绘制了去噪过程的图像,展示了从完全噪声的图像逐步还原为清晰图像的过程。通过调整通道顺序和像素值范围,它将tensor格式的图像转换为适合绘制的格式,并使用matplotlib库的subplot函数在一个大图中展示了所有步骤的图像。


)




