👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- PostgreSQL与Python数据交互:psycopg2库实战指南
- 一、引言:数据交互的桥梁
- 1.1 psycopg2核心优势
- 二、环境准备与基础连接
- 2.1 安装配置
- 2.1.1 安装psycopg2
- 2.1.2 连接参数说明
- 2.2 建立连接实例
- 三、数据交互核心操作
- 3.1 创建示例表
- 3.2 插入数据
- 3.2.1 单条插入
- 3.2.2 批量插入(性能提升50%+)
- 3.3 查询数据
- 3.3.1 基础查询
- 3.3.2 结果处理方式对比
- 3.4 更新数据
- 3.5 删除数据
- 四、事务管理与异常处理
- 4.1 事务控制原理
- 4.2 安全操作模板
- 4.3 常见异常类型
- 五、高级特性与最佳实践
- 5.1 参数化查询(防止SQL注入)
- 5.2 处理复杂数据类型
- 5.2.1 日期时间类型
- 5.2.2 JSON类型(PostgreSQL 9.4+支持)
- 5.3 连接池优化(高并发场景)
- 5.4 性能优化策略
- 六、实战案例:销售数据交互
- 6.1 数据清洗:过滤无效数据
- 6.2 数据分析:区域销售汇总
- 七、总结与最佳实践
- 7.1 核心价值总结
- 7.2 最佳实践清单
PostgreSQL与Python数据交互:psycopg2库实战指南

一、引言:数据交互的桥梁
在数据驱动的时代,PostgreSQL以其强大的关系型数据管理能力和开放性,成为企业级数据分析的核心数据库。
- Python作为
数据分析领域的首选语言,两者的高效交互是实现数据清洗、分析到可视化全流程的关键环节。 psycopg2作为Python生态中最成熟的PostgreSQL适配器,提供了稳定、高效的数据交互解决方案。- 本文将从基础连接到高级特性,结合具体数据案例,全面解析
psycopg2的实战应用。
1.1 psycopg2核心优势
| 特性 | 优势说明 |
|---|---|
| 原生支持 | 直接调用PostgreSQL C API,确保最佳性能和功能完整性 |
| 参数化查询 | 内置SQL注入防护机制,提升数据操作安全性 |
| 事务管理 | 支持完整ACID事务控制,确保数据一致性 |
| 类型适配 | 自动映射PostgreSQL数据类型与Python类型,减少类型转换成本 |
| 批量操作 | 支持批量数据插入/更新,显著提升大数据量处理效率 |
二、环境准备与基础连接
2.1 安装配置
2.1.1 安装psycopg2
# 常规安装(适用于已安装PostgreSQL开发包的环境)
pip install psycopg2-binary# 源码安装(适用于需要自定义配置的场景)
pip install psycopg2 -i https://pypi.tuna.tsinghua.edu.cn/simple
2.1.2 连接参数说明
建立数据库连接前,需准备以下核心参数:
| 参数名 | 类型 | 说明 | 示例值 |
|---|---|---|---|
| dbname | str | 数据库名称 | “postgres” |
| user | str | 数据库用户名 | “postgres” |
| password | str | 数据库密码 | “postgres” |
| host | str | 数据库主机地址(本地为"localhost") | “192.168.1.100” |
| port | int | 数据库端口(默认5432) | 5432 |
2.2 建立连接实例
import psycopg2
from psycopg2 import OperationalErrordef list_all_databases(config):"""查询PostgreSQL所有数据库清单(过滤系统模板库)"""try:# 建立数据库连接(使用上下文管理器自动关闭连接)with psycopg2.connect(**config) as conn:# 使用游标执行查询(with语句自动关闭游标)with conn.cursor() as cur:# 查询所有非模板数据库(排除template0/template1)# pg_database是PostgreSQL系统表,存储数据库元数据# datistemplate为false表示非模板库(用户创建的库)query_sql = """SELECT datname FROM pg_database WHERE datistemplate = false ORDER BY datname;"""cur.execute(query_sql)# 获取所有查询结果(返回格式:[(dbname1,), (dbname2,), ...])db_list = cur.fetchall()# 转换为纯数据库名列表(去除元组结构)return [db[0] for db in db_list]except OperationalError as e:print(f"连接或查询失败: {str(e)}")return Noneif __name__ == "__main__":# 数据库连接配置(根据实际环境修改)db_config = {"dbname": "postgres", # 连接默认数据库以执行系统表查询"user": "postgres","password": "postgres","host": "localhost","port": 5432}# 执行查询并打印结果databases = list_all_databases(db_config)if databases:print("PostgreSQL数据库清单(非模板库):")for idx, db in enumerate(databases, 1):print(f"{idx}. {db}")else:print("未获取到数据库列表")# 注意:with语句已自动关闭连接,无需手动调用conn.close()

三、数据交互核心操作
3.1 创建示例表
我们以员工信息表employees为例,演示完整的数据操作流程:
import psycopg2
from psycopg2 import OperationalError, ProgrammingErrordb_config = {"dbname": "postgres","user": "postgres","password": "postgres","host": "192.168.232.128","port": 5432
}try:conn = psycopg2.connect(**db_config)conn.autocommit = True # 关闭自动事务(建表是DDL,自动提交)# ======================================# 步骤1:执行建表语句(确保表结构正确)# ======================================create_table_sql = """CREATE TABLE IF NOT EXISTS employees (emp_id SERIAL PRIMARY KEY,name VARCHAR(50) NOT NULL,age INTEGER,department VARCHAR(30),salary NUMERIC(10,2),hire_date DATE);"""with conn.cursor() as cur:cur.execute(create_table_sql)print("表创建/验证成功!")# ======================================# 步骤2:执行数据插入(确保表结构正确后再执行)# ======================================insert_data_sql = """INSERT INTO employees (name, age, department, salary, hire_date)SELECT name,age,department,CASE WHEN department = '技术部' THEN round( (10000 + random() * 15000)::numeric, 2 )ELSE round( (6000 + random() * 12000)::numeric, 2 )END AS salary,'2020-01-01'::date + (random() * (CURRENT_DATE - '2020-01-01'::date))::int AS hire_dateFROM (SELECT'员工_' || generate_series AS name,floor(random() * 43) + 18 AS age,CASE floor(random() * 5)WHEN 0 THEN '技术部'WHEN 1 THEN '市场部'WHEN 2 THEN '财务部'WHEN 3 THEN '人力资源部'WHEN 4 THEN '运营部'END AS departmentFROM generate_series(1, 100)) AS subquery;"""with conn.cursor() as cur:cur.execute(insert_data_sql)print("数据插入成功!")except (OperationalError, ProgrammingError) as e:print(f"执行错误: {str(e)}")
finally:if conn:conn.close()print("数据库连接已关闭")

3.2 插入数据
3.2.1 单条插入
insert_single_sql = """
INSERT INTO employees (name, age, department, salary, hire_date)
VALUES (%s, %s, %s, %s, %s);
"""data = ("张三", 30, "技术部", 15000.00, "2023-01-15")with conn.cursor() as cur:cur.execute(insert_single_sql, data)
conn.commit()
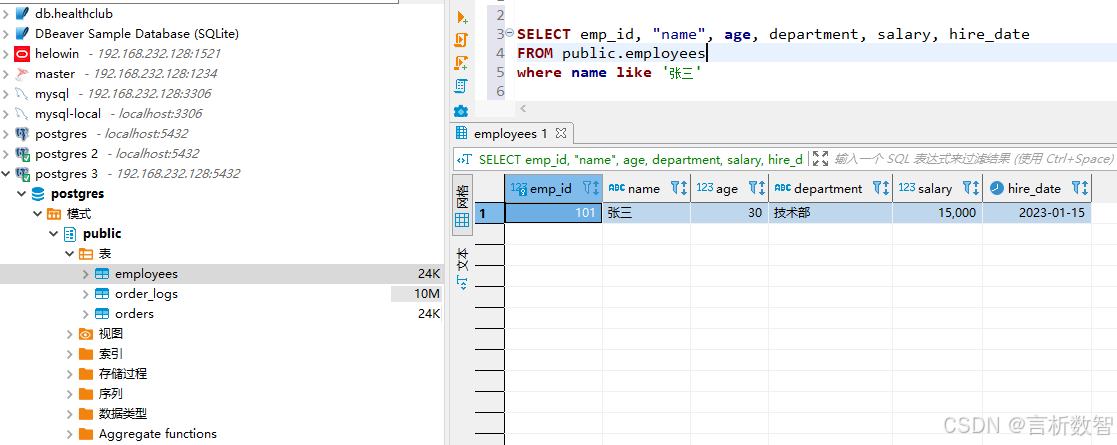
3.2.2 批量插入(性能提升50%+)
insert_batch_sql = """
INSERT INTO employees (name, age, department, salary, hire_date)
VALUES %s;
"""batch_data = [("李四", 28, "市场部", 12000.50, "2023-03-20"),("王五", 35, "研发部", 20000.00, "2022-05-10"),("赵六", 25, "财务部", 8000.75, "2023-08-01")
]# 导入psycopg2的sql模块(用于安全构建SQL语句,本示例未直接使用)
from psycopg2 import sql
# 从psycopg2扩展模块导入execute_values函数(关键批量插入工具)
from psycopg2.extras import execute_values# 使用上下文管理器创建游标(自动关闭游标,避免资源泄露)
with conn.cursor() as cur:# 执行批量插入(核心操作)execute_values(cur, # 数据库游标(用于执行SQL)insert_batch_sql, # 插入的SQL模板(需包含%s占位符,如"INSERT INTO table VALUES %s")batch_data, # 待插入的数据列表(格式:[(val1, val2), (val3, val4), ...])template=None, # 数据行的模板(默认None,自动生成%s占位符;可自定义如"(%s::int, %s::date)")page_size=100 # 分页大小(每次发送到数据库的行数,默认100;大数据量时可调整优化))# 注意:execute_values不会自动提交事务,需手动提交# 提交事务(将内存中的修改持久化到数据库)
conn.commit()
3.3 查询数据
3.3.1 基础查询
query_sql = """SELECT emp_id, name, salary FROM employees WHERE department = %s ORDER BY salary DESC;
"""department = "技术部"with conn.cursor() as cur:cur.execute(query_sql, (department,))results = cur.fetchall()# 打印查询结果
print("查询结果(技术部员工):")
for row in results:print(f"员工ID: {row[0]}, 姓名: {row[1]}, 薪资: {row[2]}")
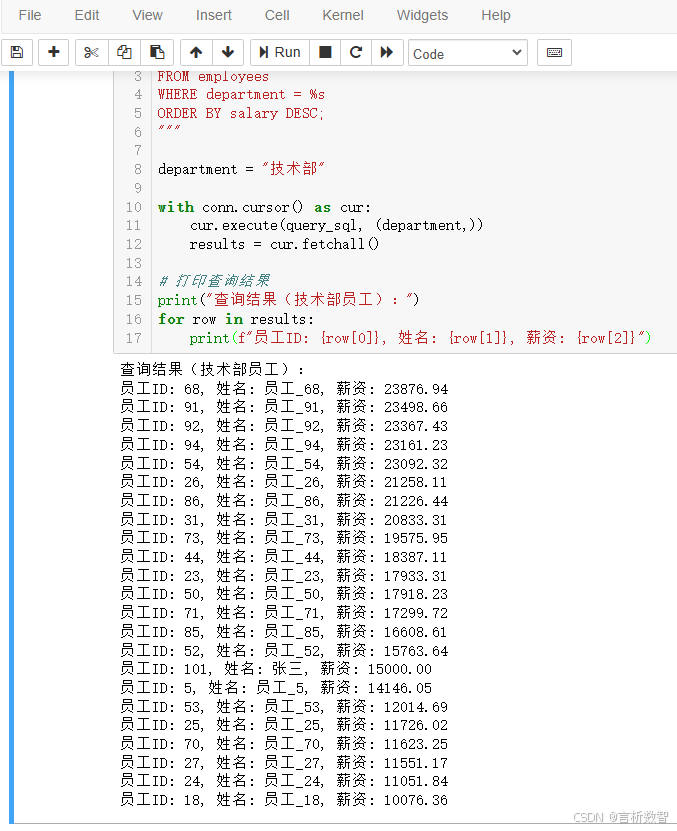
3.3.2 结果处理方式对比
| 方法 | 说明 | 内存占用 | 适用场景 |
|---|---|---|---|
fetchone() | 获取下一行记录 | 最小 | 逐条处理大量数据 |
fetchmany(size) | 获取指定数量的记录(默认size=100) | 中等 | 分页处理 |
fetchall() | 获取所有记录 | 最大 | 小数据集一次性处理 |
3.4 更新数据
update_sql = """UPDATE employees SET salary = salary * 1.1 WHERE department = %s AND age > %s;
"""params = ("研发部", 30)with conn.cursor() as cur:cur.execute(update_sql, params)print(f"更新行数:{cur.rowcount}") # 获取受影响的行数
conn.commit()

3.5 删除数据
delete_sql = """DELETE FROM employees WHERE hire_date < %s;
"""six_months_ago = "2023-01-01"with conn.cursor() as cur:cur.execute(delete_sql, (six_months_ago,))print(f"删除行数:{cur.rowcount}")
conn.commit()

四、事务管理与异常处理
4.1 事务控制原理
PostgreSQL通过事务保证数据操作的原子性,psycopg2的事务管理遵循以下流程:
-
- 自动提交模式:默认关闭(
conn.autocommit = False)
- 自动提交模式:默认关闭(
-
- 手动提交:通过
conn.commit()确认变更
- 手动提交:通过
-
- 回滚机制:通过
conn.rollback()撤销未提交变更
- 回滚机制:通过
4.2 安全操作模板
try:with conn.cursor() as cur:cur.execute("危险操作SQL", params)conn.commit()
except psycopg2.Error as e:conn.rollback()print(f"操作失败:{str(e)}")raise # 可选:向上抛出异常
finally:if conn:conn.close()
4.3 常见异常类型
| 异常类 | 说明 | 处理建议 |
|---|---|---|
| OperationalError | 连接失败、SQL语法错误等 | 检查连接参数和SQL语句 |
| IntegrityError | 唯一约束冲突、外键约束失败等 | 验证数据完整性 |
DataError | 数据类型不匹配、值超出范围等 | 检查数据格式和范围 |
ProgrammingError | 参数数量不匹配、未定义的表/列等 | 检查SQL语句结构 |
五、高级特性与最佳实践
5.1 参数化查询(防止SQL注入)
- 错误示例(直接拼接SQL):
# 危险!存在SQL注入风险
user_input = "'; DROP TABLE employees; --"cur.execute(f"SELECT * FROM employees WHERE name = '{user_input}'")
- 安全实践(使用%s占位符):
cur.execute("SELECT * FROM employees WHERE name = %s", (user_input,))
5.2 处理复杂数据类型
5.2.1 日期时间类型
from datetime import datehire_date = date(2023, 10, 1)
cur.execute("INSERT INTO employees (hire_date) VALUES (%s)", (hire_date,))
5.2.2 JSON类型(PostgreSQL 9.4+支持)
import jsonmetadata = {"title": "高级工程师", "level": "资深"}
cur.execute("INSERT INTO employees (metadata) VALUES (%s)", (json.dumps(metadata),))
5.3 连接池优化(高并发场景)
from psycopg2.pool import SimpleConnectionPool# ======================================
# 1. 配置连接池(最小2连接,最大10连接)
# ======================================
pool = SimpleConnectionPool(minconn=2, # 连接池最小保持的空闲连接数maxconn=10, # 连接池最大允许的连接数dbname="postgres", # 数据库名称user="postgres", # 数据库用户password="postgres", # 数据库密码host="192.168.232.128",# 数据库主机地址port=5432 # 数据库端口(默认5432,可省略)
)# ======================================
# 2. 从连接池获取连接并执行查询
# ======================================
try:# 获取一个数据库连接(如果池中有空闲连接则直接获取,否则新建直到maxconn)conn = pool.getconn()# 使用上下文管理器创建游标(自动关闭游标)with conn.cursor() as cur:# 执行SQL查询(统计employees表的记录数)cur.execute("SELECT COUNT(*) FROM employees")# 获取查询结果(COUNT(*)返回一行一列,使用fetchone())# fetchone()返回元组,例如:(100,),[0]获取第一个元素count_result = cur.fetchone()[0]# 打印结果print(f"employees表记录数:{count_result}")finally:# 关键:无论是否出错,都要将连接归还给连接池(而非关闭!)if conn:pool.putconn(conn)print("连接已归还至连接池")# ======================================
# 3. 关闭连接池(程序结束时执行,释放所有资源)
# ======================================
pool.closeall()
print("连接池已关闭")

5.4 性能优化策略
-
- 批量操作:使用
execute_values替代循环单条插入,性能提升约300%
- 批量操作:使用
-
- 游标优化:对大数据集使用
named cursor(cur = conn.cursor(name="large_cursor"))
- 游标优化:对大数据集使用
-
- 连接复用:使用连接池减少连接创建开销
-
- 预处理语句:通过
PREPARE和EXECUTE减少SQL解析时间
- 预处理语句:通过
六、实战案例:销售数据交互
假设我们有一张销售记录表sales_records,包含以下字段:
| 字段名 | 类型 | 说明 |
|---|---|---|
| sale_id | BIGINT | 销售记录ID(主键) |
| product_name | VARCHAR(50) | 产品名称 |
| sale_date | DATE | 销售日期 |
| amount | NUMERIC(10,2) | 销售金额 |
| region | VARCHAR(20) | 销售区域 |
6.1 数据清洗:过滤无效数据
raw_sales建表语句,并构建测试数据
-- 创建原始销售数据表(含可能不规范的数据,用于清洗)
CREATE TABLE IF NOT EXISTS raw_sales (id SERIAL PRIMARY KEY, -- 自增主键(唯一标识每条记录)product_name VARCHAR(100) NOT NULL, -- 产品名称(如"手机","笔记本电脑"等)sale_date DATE NOT NULL, -- 销售日期(格式:YYYY-MM-DD)amount NUMERIC(10,2), -- 销售金额(可能为正/负,模拟退货或错误数据)region VARCHAR(20) -- 销售区域(可能包含无效值,如"西北","国外")
);-- 向raw_sales表插入100条测试数据(包含有效和无效数据,用于验证清洗逻辑)
INSERT INTO raw_sales (product_name, sale_date, amount, region)
SELECT-- 产品名称:从预设列表中随机选择(模拟真实产品)CASE floor(random() * 5) -- 0-4对应5种产品WHEN 0 THEN '智能手机'WHEN 1 THEN '笔记本电脑'WHEN 2 THEN '平板电脑'WHEN 3 THEN '智能手表'WHEN 4 THEN '无线耳机'END AS product_name,-- 销售日期:过去1年内的随机日期(2024-05-01至2025-05-01)'2024-05-01'::date + floor(random() * 365)::int AS sale_date,-- 关键修正:将随机金额转换为numeric类型后再round(保留2位小数)CASE WHEN random() > 0.5 THEN round( (100 + random() * 4900)::numeric, 2 ) -- 正数:100-5000元(保留2位小数)ELSE round( (-100 - random() * 4900)::numeric, 2 ) -- 负数:-5000至-100元(保留2位小数)END AS amount,-- 销售区域:30%概率为有效区域(华北/华东/华南),70%为无效区域(模拟需要清洗的场景)CASE floor(random() * 10) -- 0-9共10种可能WHEN 0 THEN '华北'WHEN 1 THEN '华东'WHEN 2 THEN '华南'ELSE '无效区域' -- 包括"西北","西南","国外"等(简化为统一描述)END AS region
FROM generate_series(1, 100); -- 生成1-100的序号(控制数据量)
cleaned_sales建表语句
-- 创建清洗后销售数据表(若不存在)
CREATE TABLE IF NOT EXISTS cleaned_sales (product_name VARCHAR(100) NOT NULL, -- 产品名称(与raw_sales的product_name类型一致,假设长度100)sale_date DATE NOT NULL, -- 销售日期(与raw_sales的sale_date类型一致,日期类型)amount NUMERIC(10,2) NOT NULL, -- 销售金额(与raw_sales的amount类型一致,保留2位小数)region VARCHAR(20) NOT NULL -- 销售区域(与raw_sales的region类型一致,假设常用区域名长度20)
);
clean_sql = """
INSERT INTO cleaned_sales (product_name, sale_date, amount, region)
SELECT product_name, sale_date, amount, region
FROM raw_sales
WHERE amount > 0 AND region IN ('华北', '华东', '华南');
"""with conn.cursor() as cur:cur.execute(clean_sql)
conn.commit()
6.2 数据分析:区域销售汇总
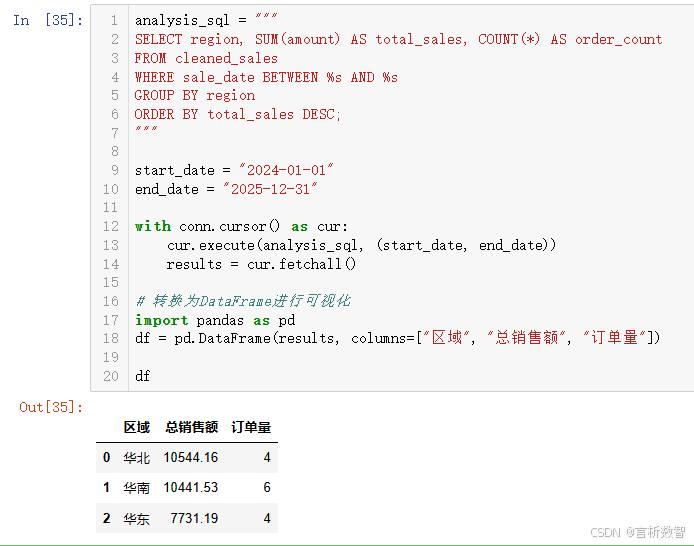
analysis_sql = """
SELECT region, SUM(amount) AS total_sales, COUNT(*) AS order_count
FROM cleaned_sales
WHERE sale_date BETWEEN %s AND %s
GROUP BY region
ORDER BY total_sales DESC;
"""start_date = "2024-01-01"
end_date = "2025-12-31"with conn.cursor() as cur:cur.execute(analysis_sql, (start_date, end_date))results = cur.fetchall()# 转换为DataFrame进行可视化
import pandas as pd
df = pd.DataFrame(results, columns=["区域", "总销售额", "订单量"])df
七、总结与最佳实践
7.1 核心价值总结
-
- 无缝集成:实现
PostgreSQL与Python的高效数据流转
- 无缝集成:实现
-
- 安全可靠:通过
参数化查询和事务管理保障数据安全
- 安全可靠:通过
-
- 性能卓越:支持
批量操作和连接池技术应对大数据量场景
- 性能卓越:支持
-
- 生态兼容:无缝对接Pandas、Matplotlib等数据分析库
7.2 最佳实践清单
-
- 始终使用参数化查询:避免SQL注入风险
-
- 合理管理连接:
使用with语句自动释放资源,高并发场景用连接池
- 合理管理连接:
-
- 明确事务边界:复杂操作使用显式事务控制
-
- 处理类型转换:对JSON、日期等复杂类型使用官方推荐转换方法
-
- 监控与日志:记录关键操作的错误信息和执行时间
这篇文章全面介绍了psycopg2库在PostgreSQL与Python数据交互中的应用。
- 你可以说说对内容的看法,比如是否需要增加更多案例或调整讲解深度,以便我进一步优化。
- 通过掌握
psycopg2的核心功能和最佳实践,数据分析师和开发人员能够高效构建从PostgreSQL到Python的数据管道,为后续的数据可视化和深度分析奠定坚实基础。无论是小规模的数据探索,还是千万级数据的批量处理,psycopg2都能提供稳定可靠的解决方案,成为PostgreSQL数据交互的首选工具。

)




