目录
引言
1 Hive执行引擎架构演进
1.1 Hive执行引擎发展历程
1.2 执行引擎架构对比
1.2.1 MapReduce引擎架构
1.2.2 Tez引擎架构
1.2.3 Spark引擎架构
2 执行引擎切换与配置指南
2.1 引擎切换配置方法
2.1.1 全局配置
2.1.2 会话级配置
2.2 资源管理配置
2.2.1 Tez资源配置
2.2.2 Spark资源配置
3 Spark SQL集成深度解析
3.1 Hive on Spark架构
3.2 优化器集成机制
3.3 数据交换优化
4 生产环境调优实践
4.1 执行引擎选择策略
4.2 混合引擎部署方案
4.3 关键性能参数调优
4.3.1 Spark引擎核心参数
4.3.2 Tez引擎核心参数
5 疑难问题解决方案
5.1 常见集成问题排查
5.2 高级调优技巧
6 总结
引言
在大数据生态系统中,Hive作为数据仓库基础设施,与Spark SQL作为现代分析引擎的集成已成为企业级数据平台的标配。
1 Hive执行引擎架构演进
1.1 Hive执行引擎发展历程
Hive的执行引擎经历了三个主要发展阶段:MapReduce引擎(传统):
- 最初设计基于Hadoop MapReduce
- 高延迟,适合批处理
- 缺乏高效的流水线执行
Tez引擎(过渡):
- 引入DAG(有向无环图)执行模型
- 减少中间结果落盘
- 支持任务链式执行
Spark引擎:
- 内存计算为核心
- 完善的查询优化器(Catalyst)
- 支持交互式查询和流批一体

1.2 执行引擎架构对比
1.2.1 MapReduce引擎架构

特点:
- 严格的Map-Phase和Reduce-Phase分离
- 每个阶段间数据必须持久化到HDFS
- 高延迟,适合大规模批处理
1.2.2 Tez引擎架构

特点:
- 将作业建模为DAG
- 顶点(Vertex)表示处理阶段
- 边(Edge)表示数据移动方式
- 支持内存管道传输
1.2.3 Spark引擎架构

特点:
- 基于RDD/Dataset的弹性分布式数据集
- Catalyst优化器执行逻辑和物理优化
- 全阶段代码生成(WholeStage Codegen)
- 内存优先的执行策略
2 执行引擎切换与配置指南
2.1 引擎切换配置方法
2.1.1 全局配置
- 在hive-site.xml中永久生效配置:
<!-- 使用MapReduce引擎 -->
<property><name>hive.execution.engine</name><value>mr</value>
</property><!-- 使用Tez引擎 -->
<property><name>hive.execution.engine</name><value>tez</value>
</property><!-- 使用Spark引擎 -->
<property><name>hive.execution.engine</name><value>spark</value>
</property>2.1.2 会话级配置
- 在Hive会话中临时切换:
-- 切换到Tez
SET hive.execution.engine=tez;
-- 切换到Spark
SET hive.execution.engine=spark;2.2 资源管理配置
2.2.1 Tez资源配置
<!-- tez-site.xml -->
<property><name>tez.am.resource.memory.mb</name><value>4096</value>
</property><property><name>tez.task.resource.memory.mb</name><value>2048</value>
</property>2.2.2 Spark资源配置
-- 在Hive中设置Spark参数
SET spark.executor.memory=4g;
SET spark.executor.cores=2;
SET spark.executor.instances=10;
SET spark.dynamicAllocation.enabled=true;3 Spark SQL集成深度解析
3.1 Hive on Spark架构
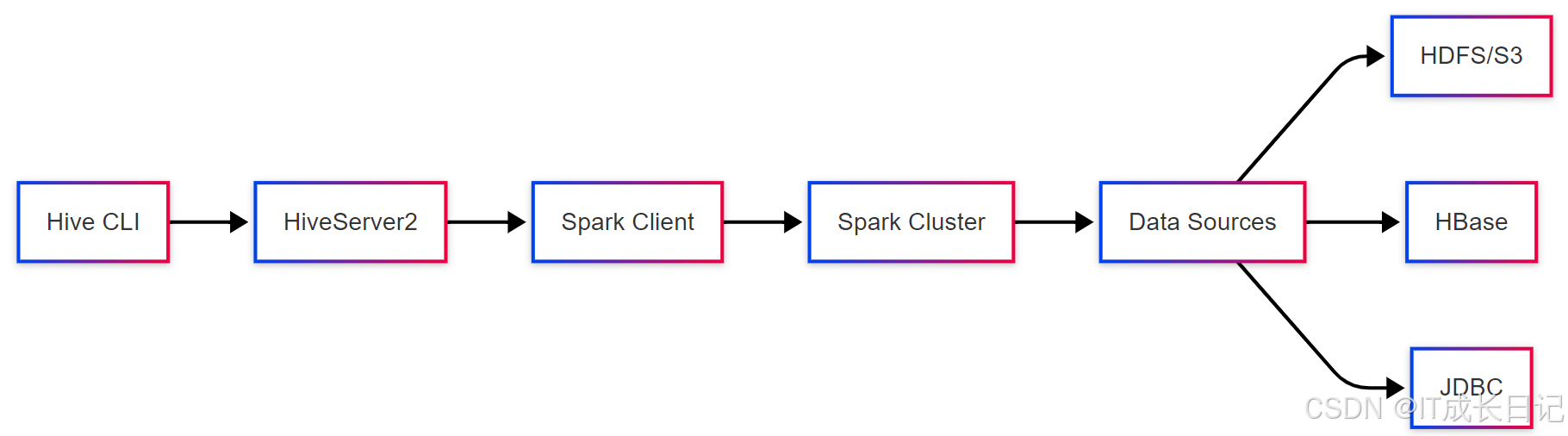
- HiveServer2:接收查询请求
- Spark Client:提交作业到集群
- Spark Cluster:执行物理计划
- Data Sources:读写外部存储
3.2 优化器集成机制
- Hive与Spark SQL的优化器协作流程:

- HiveQL解析:生成Hive抽象语法树
- AST转换:转为Spark SQL的语法树
- Catalyst优化:应用规则优化逻辑计划
- 物理执行:生成Spark RDD操作
3.3 数据交换优化
Hive与Spark间的数据传输模式:
- 直接HDFS读取:
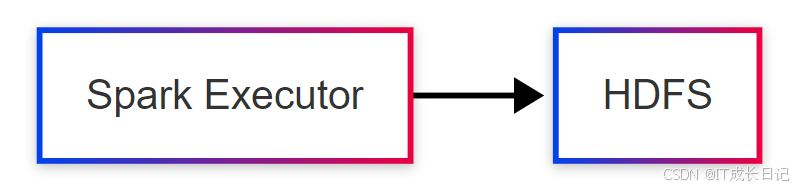
- Spark直接读取Hive表数据文件
- 零拷贝,最高效的方式
- 通过HiveServer2传输:

- 用于元数据获取和小量数据传输
- 应尽量减少这种模式
4 生产环境调优实践
4.1 执行引擎选择策略
| 场景特征 | 推荐引擎 | 理由 |
| 超大规模批处理 | MapReduce | 稳定性高,资源隔离好 |
| 中等规模ETL | Tez | 平衡资源使用和性能 |
| 交互式分析 | Spark | 亚秒级响应 |
| 机器学习特征提取 | Spark | 与MLlib无缝集成 |
| 小文件密集型查询 | Spark | 高效内存处理小文件 |
4.2 混合引擎部署方案

各层引擎选择:
- ODS层:使用MapReduce保证数据加载稳定性
- DWD层:使用Tez进行中等复杂度转换
- DWS/ADS层:使用Spark实现高性能聚合
4.3 关键性能参数调优
4.3.1 Spark引擎核心参数
-- 并行度控制
SET spark.sql.shuffle.partitions=200; -- 适合集群规模
-- 内存管理
SET spark.memory.fraction=0.6;
SET spark.memory.storageFraction=0.5;
-- 执行策略
SET spark.sql.adaptive.enabled=true; -- 开启动态调整
SET spark.sql.join.preferSortMergeJoin=true;4.3.2 Tez引擎核心参数
<!-- tez-site.xml -->
<property><name>tez.grouping.split-count</name><value>200</value>
</property><property><name>tez.runtime.io.sort.mb</name><value>1024</value>
</property>5 疑难问题解决方案
5.1 常见集成问题排查
- 问题1:Spark作业提交失败
ERROR SparkClient: Failed to submit spark job解决方案:
- 检查Spark集群资源可用性
- 验证Hive与Spark版本兼容性
- 检查spark-defaults.conf配置
- 问题2:性能不如预期
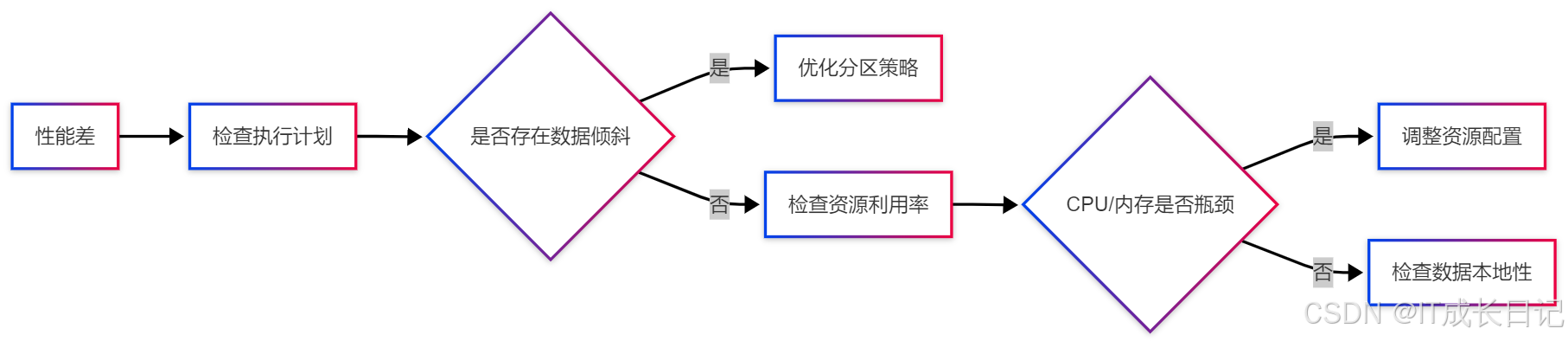
5.2 高级调优技巧
- 数据倾斜处理:
-- 倾斜键识别
SELECT key, COUNT(*)
FROM table
GROUP BY key
ORDER BY 2 DESC
LIMIT 10;
-- 倾斜处理方案
SET spark.sql.adaptive.skewJoin.enabled=true;
SET spark.sql.adaptive.skewJoin.skewedPartitionFactor=5;- 内存优化技巧:
-- 控制广播阈值
SET spark.sql.autoBroadcastJoinThreshold=10485760; -- 10MB
-- 序列化优化
SET spark.serializer=org.apache.spark.serializer.KryoSerializer;6 总结
Hive与Spark SQL的深度集成为企业数据平台提供了从传统批处理到现代交互式分析的全栈能力。Spark引擎在大多数场景下显著优于MapReduce和Tez,特别是在需要低延迟和复杂分析的场景。然而,Tez仍然在某些中等规模ETL作业中保持着资源利用率上的优势,而MapReduce在大规模稳定批处理中仍有其价值。在实际生产环境中,建议采用混合引擎策略,根据不同的数据流程阶段和工作负载特征选择最合适的执行引擎。同时,通过合理的参数调优和架构设计,可以充分发挥各引擎的优势,构建高性能、高效率的数据处理平台。

)




