想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
想快速掌握自动编程技术吗?叶老师专业培训来啦!这里用Cline把自然语言变代码,再靠DeepSeek生成逻辑严谨、注释清晰的优质代码。叶梓老师视频号上直播分享《用deepseek实现自动编程》限时回放。
视频号(直播分享):sphuYAMr0pGTk27 抖音号:44185842659
在社交推理游戏中,AI的表现逐渐接近人类水平。《Multi-agent KTO: Reinforcing Strategic Interactions of Large Language Model in Language Game》这篇文章通过狼人杀游戏的实验,展示了新的AI方法如何在复杂社交环境中实现高效决策。
理解语言游戏理论
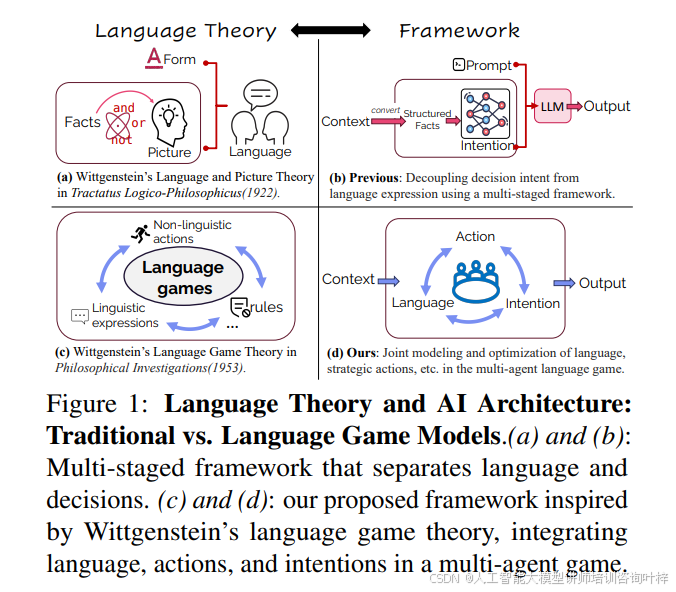
论文受到维特根斯坦语言游戏理论启发,强调语言与行动的统一性。传统方法将决策与语言生成分离,而本文提出的方法让模型通过实际互动学习,更贴近真实社交场景。图1展示了不同语言决策框架的对比,说明了新方法如何将语言、意图和行动整合在一个多智能体环境中。
多智能体KTO方法
研究者提出的“多智能体Kahneman & Tversky优化”(MaKTO)方法,解决了狼人杀中的两个主要挑战:个体行动对游戏结果的微妙影响,以及专家标注数据中决策质量的差异。MaKTO的三大创新点:
-
采用KTO算法,无需在线强化学习的复杂训练,也无需成对偏好数据。
-
多样化模型池代替自对弈,防止策略固化,提升模型泛化能力。
-
分步偏好选择,通过三种方法优化策略。
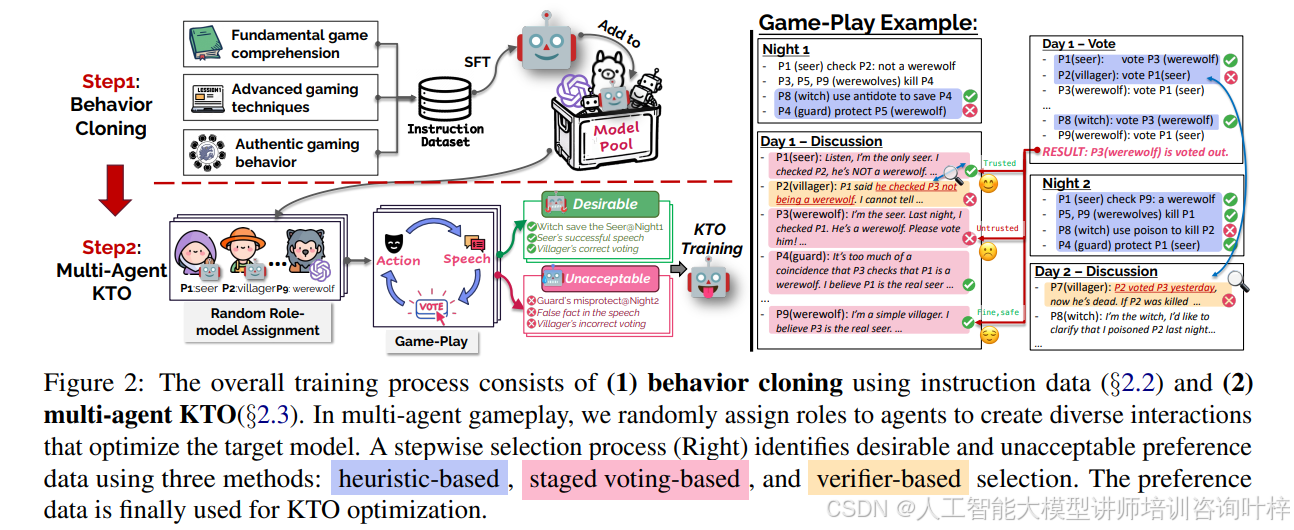
图2展示了训练过程,包括行为克隆和多智能体KTO训练。模型通过与多种模型互动,学习到更全面的游戏策略。
实验与评估
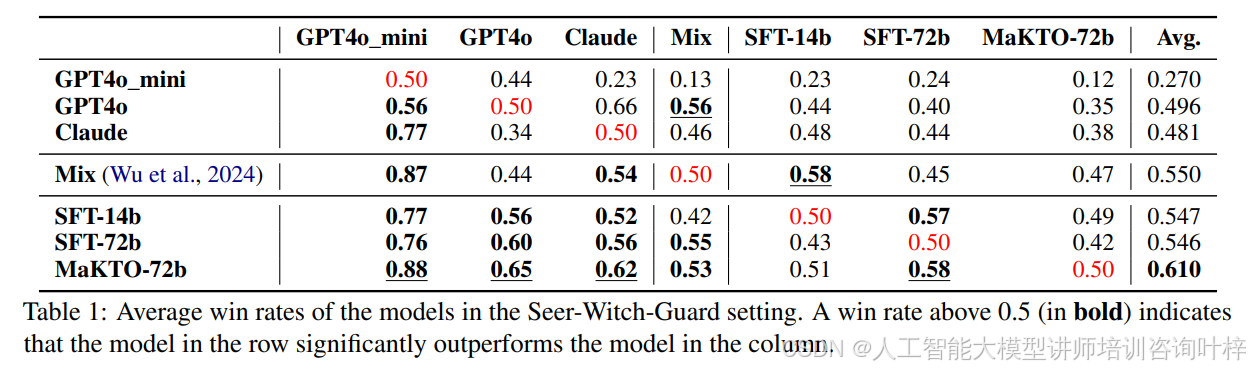
在9人狼人杀游戏中,MaKTO模型与其他强大基线(如GPT-4o和Claude-3.5)进行了对比评估。表格1显示,MaKTO在与其他模型的对抗中取得了61%的平均胜率,显著优于GPT-4o和两阶段RL智能体。
在人类对抗评估中,MaKTO与14名经验丰富的玩家进行了比赛,平均胜率达到60%,显示出与高水平人类玩家相当的竞技能力。图5展示了在随机比赛中的玩家胜率,MaKTO模型在所有玩家中排名第四,超过了人类玩家的平均胜率。
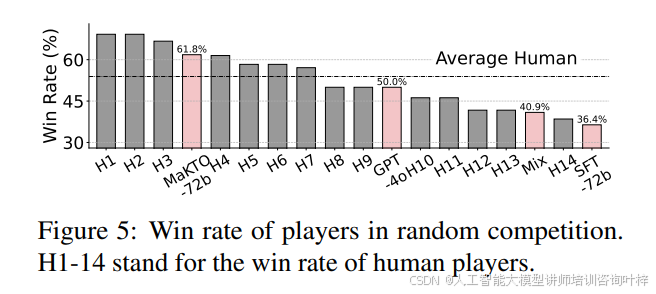
图6展示了Turing风格的可检测性测试结果。人类玩家试图区分AI和人类玩家时,MaKTO的识别准确率仅为48.9%,低于随机概率,表明其对话风格与人类极为相似,成功通过了这一特殊Turing测试。
跨游戏泛化能力
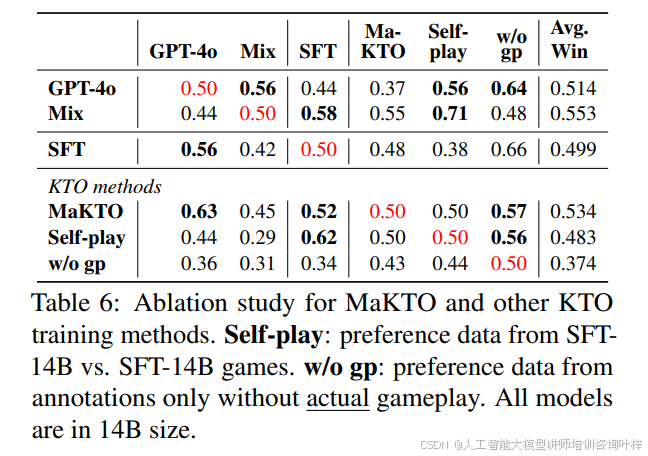
研究还测试了MaKTO在引入新角色“猎人”的游戏配置中的表现。尽管MaKTO未在包含猎人的游戏设置中训练,但它在新游戏配置中的表现仍优于仅在原始设置上训练的模型。表格6显示,在9人先知-女巫-猎人游戏中,MaKTO取得了更高的平均胜率,证明了其泛化能力。
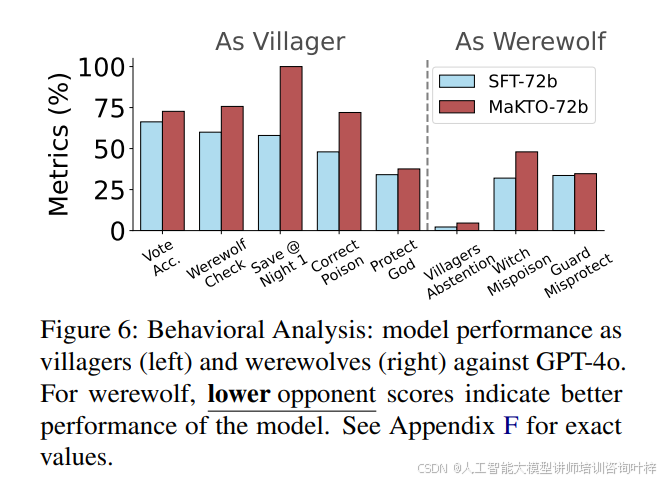
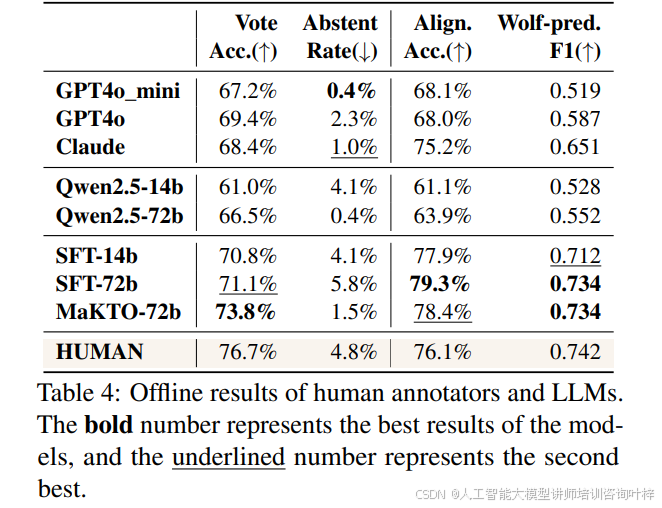
通过对比MaKTO与基线模型在比赛中的行为,研究发现MaKTO在投票准确性、弃权率等关键指标上均优于基线模型。表格3和表格4分别展示了MaKTO作为村民和狼人时的性能提升,表明其在身份识别和策略运用上更为精准。

https://arxiv.org/pdf/2501.14225
https://reneeye.github.io/MaKTO.html
https://huggingface.co/datasets/ReneeYe/werewolf_game_reasoning

)




