- Arxiv日期:2023.12.18
- 机构:ZJU / Donghai Laboratory / NUS
关键词
- PoT(SFT)
- 程序化复杂度
- 自动分级过滤
核心结论
1. 编程语言具有明显的优势:
-
与序列化自然语言相比,它们对复杂结构的建模更胜一筹
-
固有的面向过程的逻辑,有助于解决多步推理问题
2. 并不是任意复杂度的程序训练都对大模型的推理能力有帮助
-
当前的 LLM 对代码等符号知识的理解有限
-
低复杂度的代码块包含的知识不足
-
复杂度高的代码块对于 LLM 来说可能太难学习
3. 最佳代码级别对于 PoT 的推理能力至关重要
4. 参数数量越多,LLM 推理能力的增益就越显着
5. 当前大模型在推理能力上仍然具有局限性
主要方法
将代码抽象为AST,发现并非所有复杂的代码数据都可以被 LLM 学习或理解。
因此提出复杂度的衡量分数:complexity-impacted reasoning score (CIRS)
![]()
Score_SC 表示 Structural Complexity:
![]()
- f 表示 Z-score normalization + mean-pooling
- X_Node 表示节点个数
- X_Type 表示各种节点类型的个数(几种节点类型)
- X_Depth 表示 AST 深度
Score_LC 表示 Logical Complexity:
![]()
-
D(R_c) 表示 Difficulty
![]()
n1 表示操作符个数;n2 表示代码原理中操作数个数;N2 表示代码中操作数个数。
-
V(R_c) 表示 cyclomatic complexity
![]()
E 表示 control flow 的 edge 个数;N 表示 nodes 个数。
自动化分层过滤pipeline:
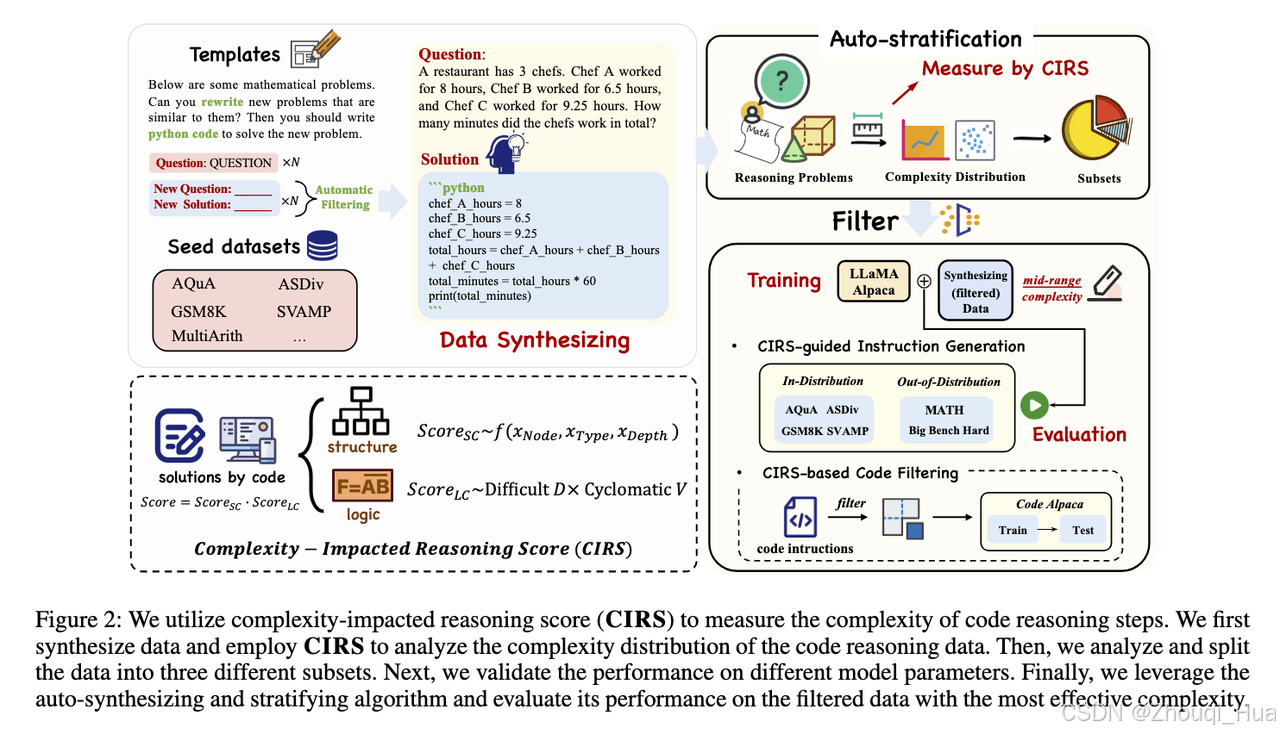
注:本系列不包括基础的知识点讲解,为笔记/大纲性质而非教程,用于论文知识点和思想和快速记忆和回顾,更多细节建议阅读论文原文

)




