
pandas操作CSV文件
CSV后缀的文件是标准文件格式,可以通过文本编辑器或者excel表格打开,
使用非常广泛;使用文本编辑器打开后,每一行都以英文逗号隔开,如下所示:

之前文章我们介绍了使用python自带的csv库读取和写入(
python之csv文件读取和写入),本章主要介绍使用pandas库读取和写入csv文件。
读取csv文件
使用pandas的read_csv函数,读取csv文件,默认返回DataFrame数据格式(pandas定义的一个二维数据结构,类似于excel表格有行和列的数据)
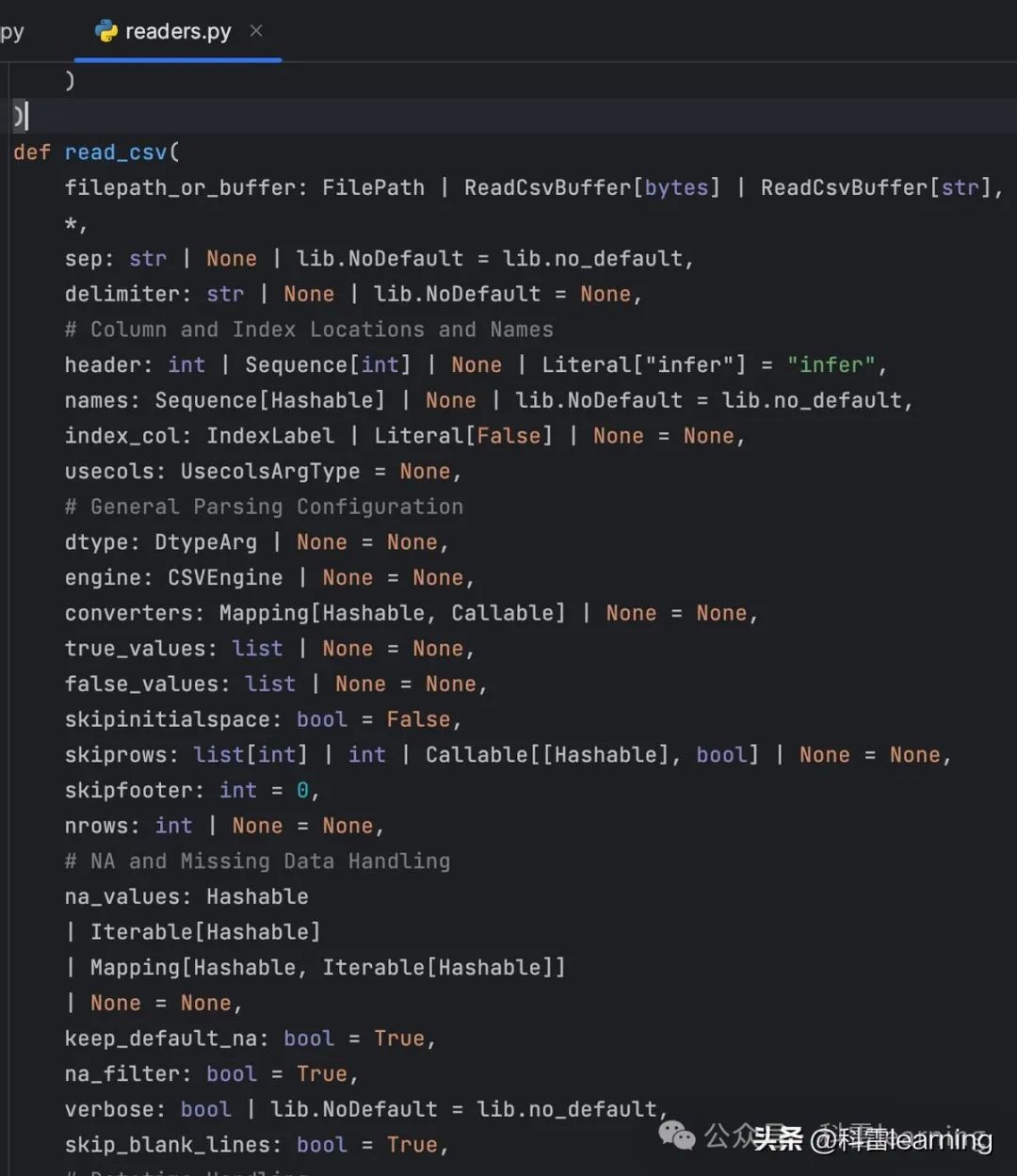
函数参数有很多,主要介绍下常用的参数:
-
1) filepath_or_buffer:要读取的文件路径或对象。比如文件路径,文件对象(如通过open函数打开的文件句柄),或者URL,有效的URL包括http、ftp、file等。
-
2) sep(或delimiter):字段分隔符,默认为英文逗号。如果CSV文件使用其他字符作为分隔符,可以通过此参数指定。
-
3) header:用作列名的行号,默认为0(第一行)。如果没有列名,则设为None。也可以指定多行作为多级列名,例如header=[0, 1]。
-
4) names:列名列表,当header=None时,可以使用此参数自定义列名。
-
5) index_col:用作索引的列编号或列名。默认为None,使用CSV文件中的行索引作为DataFrame的索引。
-
6) usecols:返回的列,可以是列名的列表或由列索引组成的列表。用于选择性地读取CSV文件中的某些列。
-
7) dtype:字典或列表,指定某些列的数据类型。例如,dtype={'column1': int, 'column2': float}。
-
8) skiprows:需要忽略的行数(从文件开头算起),或需要跳过的行号列表。用于跳过CSV文件开头的某些行。
-
9) nrows:需要读取的行数(从文件开头算起)。用于从大文件中提取部分数据。
-
10) skipfooter:文件尾部需要忽略的行数。
-
11) encoding:文件编码(如'utf-8'、'latin-1'等)。用于指定文件的字符编码。
-
12) parse_dates:将某些列解析为日期。可以是列名的列表或由列索引组成的列表,还可以是布尔值True(尝试解析所有列)。
-
13) infer_datetime_format:如果True且parse_dates未指定,则尝试解析日期。
-
14) iterator:如果True,则返回TextFileReader对象,用于迭代循环读取文件。与chunksize参数配合使用,可以实现数据的分段读取。
-
15) chunksize:每个块的行数,用于逐块读取文件。与iterator=True配合使用。
-
16) compression:压缩格式,例如'gzip'或'xz'。用于读取压缩格式的CSV文件。
测试代码:读取csv文件为DataFrame对象,并打印对象的数据
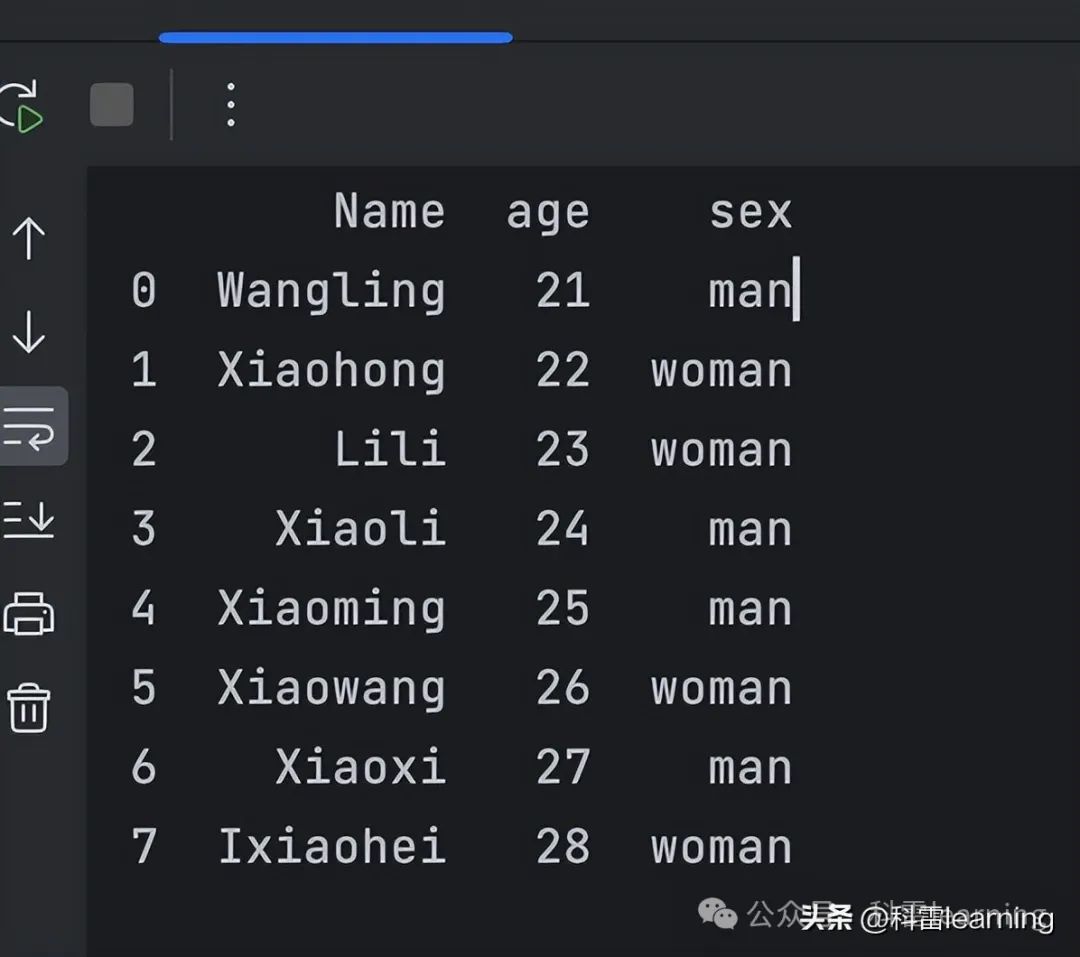
准备一个csv文件如下:

读取csv文件并打印
import pandas as pd dataframe = pd.read_csv("1.csv")print(dataframe)展示结果:这个结果跟excel表格中的数据结构很类似。
读取文件后,通过DataFrame对象的多种多样的函数,可以对读取的csv文件数据做各类操作(具体可参考上一篇文章介绍
python数据分析:介绍pandas库的数据类型Series和DataFrame)
保存为csv文件
使用pandas的to_csv函数将DataFrame格式数据保存为csv文件
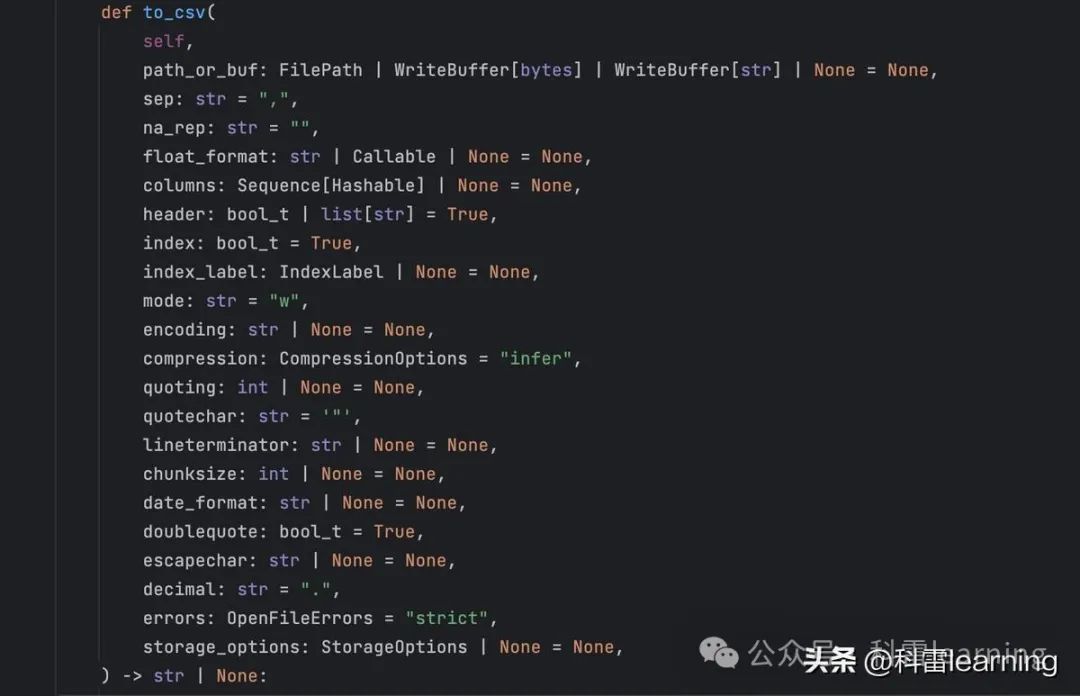
常用参数介绍:
-
1) path_or_buf: 保存的文件路径或者文件对象
-
2) sep: 指定每行不同列值之间的分隔符,默认为 ','。
-
3)columns: sequence,:指定要写入的列名列表。如果为 None,则写入所有列。
-
4)index: 默认为 True。表示是否将行(索引)标签写入文件。
-
5)header: 默认为 True。是否将列名(表头)写入文件。如果为 False,则不写入列名;也可以是一个字符串列表,指定列名的别名。
-
6)mode: str, 默认为 'w',表示文件打开模式。'w':写模式(覆盖);'a':追加模式;'r+':读写模式(文件必须存在)。
-
7)encoding: 字符串编码格式。例如:'utf-8'。
-
8) compression: {'infer', 'gzip', 'bz2', 'zip', 'xz', None}, 可选,默认为 'infer'。指定压缩方式。如果为 'infer',则根据文件扩展名推断压缩方式。
-
9)line_terminator: 默认为 '\n'。指定行终止符。
-
10)chunksize: 指定每次写入文件的行数。这对于处理大文件很有用,可以节省内存。
-
11)date_format: 日期时间对象的格式化字符串。
-
12)doublequote: 默认为 True,表示字段中的双引号将被双写。
-
13)errors:指定错误处理方式。'strict':引发异常;'ignore':忽略错误;'replace':用替换字符替换错误字符。
测试代码:直接保存文件,不添加其他参数。
import pandas as pddataframe = pd.read_csv("1.csv")#插入2行数据dataframe.insert(2,'area','China')dataframe.insert(3,'area',['China','America','korea','japan','China','America','korea','japan'],allow_duplicates=True)#保存文件dataframe.to_csv('2.csv')
结果:将行索引和所有的行和列的值都写入了

当然也可以像上面的参数介绍一样。添加一些参数的示例:
1)不写入行索引,只写入Name这一列的数据
dataframe.to_csv('3.csv',index=False,columns=['Name'])
2)不写入表头,并且做追加写入
dataframe.to_csv('3.csv',header=False,mode='a+')
共勉: 东汉·班固《汉书·枚乘传》:“泰山之管穿石,单极之绠断干。水非石之钻,索非木之锯,渐靡使之然也。”
-----指水滴不断地滴,可以滴穿石头;
-----比喻坚持不懈,集细微的力量也能成就难能的功劳。
----感谢读者的阅读和学习,谢谢大家。






