本文介绍一个基于Pyraformer的时间序列预测模型,这个模型适合功率预测,风电光伏预测,负荷预测,电池预测,流量预测,浓度预测,机械领域预测等等各种时间序列直接预测。
详细教学介绍和重构简单的源码在最后!
1.介绍
原论文链接:
http://PYRAFORMER: LOW-COMPLEXITY PYRAMIDAL ATTENTION FOR LONG-RANGE TIME SERIES MODELING AND FORECASTING
在本文中,我们提出了一种新的基于金字塔注意力的Transformer(Pyraformer),以弥补捕获长距离依赖和实现低时间和空间复杂性之间的差距。具体来说,我们通过在金字塔图中传递基于注意力的信息来开发金字塔注意力机制,如图1(d)所示。该图中的边可以分为两组:尺度间连接和尺度内连接。尺度间的连接构建了原始序列的多分辨率表示:最细尺度上的节点对应于原始时间序列中的时间点(例如,每小时观测值),而较粗尺度下的节点代表分辨率较低的特征(例如,每日、每周和每月模式)。这种潜在的粗尺度节点最初是通过粗尺度构造模块引入的。另一方面,尺度内边缘通过将相邻节点连接在一起来捕获每个分辨率下的时间相关性。因此,该模型通过以较粗的分辨率捕获此类行为,从而使信号穿越路径的长度更短,从而为远距离位置之间的长期时间依赖性提供了一种简洁的表示。此外,通过稀疏的相邻尺度内连接,在不同尺度上对不同范围的时间依赖性进行建模,可以显著降低计算成本。简而言之,我们的主要贡献包括:
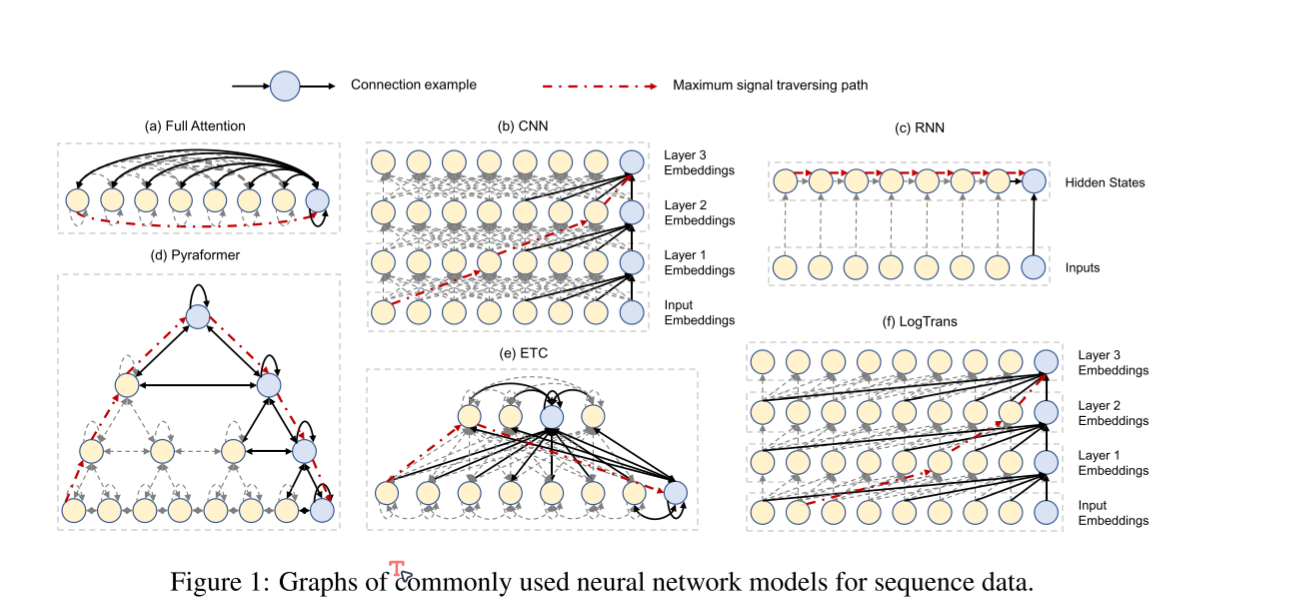
图1:序列数据的常用神经网络模型图。
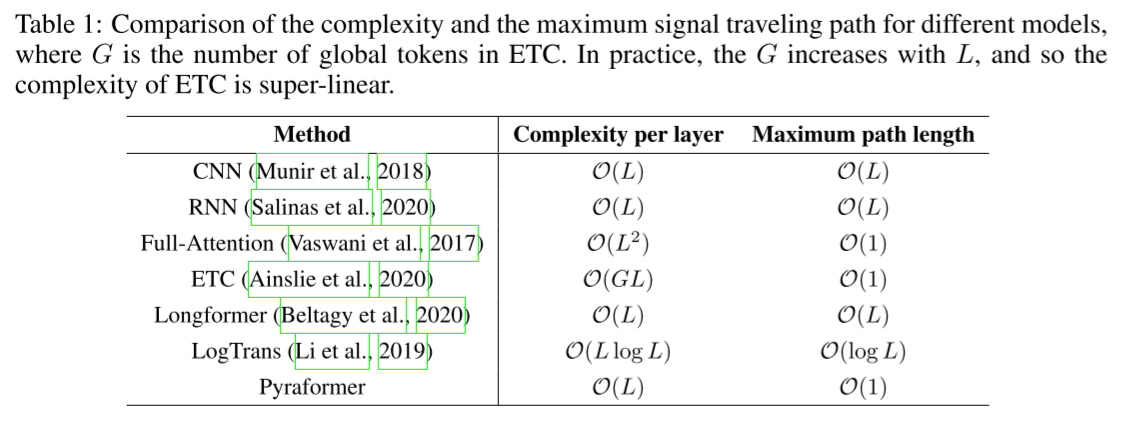
表1:不同模型的复杂度和最大信号传播路径的比较,其中G是ETC中全局令牌的数量。实际上,G随L增加,因此ETC的复杂度是超线性的。
-
我们提出Pyraformer以紧凑的多分辨率方式同时捕获不同范围的时间相关性。为了区分Pyraformer和最先进的方法,我们从图1中的图形角度总结了所有模型。
-
理论上,我们证明,通过适当选择参数,可以同时达到O(1)的最大路径长度和O(L)的时间和空间复杂性。为了突出所提出模型的吸引力,我们在表1中进一步比较了不同模型的最大路径和复杂性。
-
在实验上,我们表明,在单步和长程多步预测的情况下,与原始Transformer及其变体相比,所提出的Pyraformer在各种真实世界数据集上产生了更准确的预测,但时间和内存成本更低。
2 相关工作
2.1 时间序列预测
时间序列预测方法大致可分为统计方法和基于神经网络的方法。第一组涉及ARIMA(Box&Jenkins,1968)和Prophet(Taylor&Letham,2018)。然而,这两种方法都需要分别拟合每一个时间序列,在进行长期预测时,它们的表现都相形见绌。
最近,深度学习的发展催生了基于神经网络的时间序列预测方法的巨大增长,包括CNN(Munir等人,2018)、RNN(Salinas等人,2020)和Transformer(Li等人,2019)。如前一节所述,CNN和RNN具有较低的时间和空间复杂性(即O(L)),但需要一条O(L)的路径来描述长期依赖性。我们请读者参阅附录A,以了解有关基于RNN的模型的更详细的综述。相比之下,Transformer(Vaswani等人,2017)可以通过O(1)步的路径有效地捕获长程依赖性,而复杂性从O(L)大幅增加到O(L2)。为了减轻这种计算负担,提出了LogTrans(Li et al.,2019)和Informer(Zhou et al.,2021):前者限制序列中的每个点只能关注其前面2n步的点,其中n=1,2,···,而后者利用注意力得分的稀疏性,从而以引入更长的最大路径长度为代价显著降低复杂性(即O(L log L))。
2.2 稀疏Transformers
除了关于时间序列预测的文献外,在自然语言处理(NLP)领域,已经提出了大量方法来提高Transformer的效率。与CNN类似,Longformer(Beltagy等人,2020)计算局部滑动窗口或扩张滑动窗口内的注意力。尽管复杂性降低到O(AL),其中A是本地窗口大小,但有限的窗口大小使得难以在全局交换信息。因此,最大路径长度为O(L/A)。作为替代方案,Reformer(Kitaev等人,2019)利用位置敏感散列(LSH)将序列划分为多个桶,然后在每个桶中执行关注。它还使用可逆变换器来进一步减少内存消耗,因此可以处理非常长的序列。它的最大路径长度与桶的数量成正比,更糟糕的是,需要大量的桶来降低复杂性。另一方面,ETC(Ainslie等人,2020)为了全球信息交换引入了一组额外的全局令牌,导致O(GL)时间和空间复杂性以及O(1)最大路径长度,其中G是全局令牌的数量。然而,G通常随L增加,因此复杂性仍然是超线性的。类似于ETC,所提出的Pyraformer也引入了全局令牌,但以多尺度的方式,成功地将复杂性降低到O(L),而不增加原始Transformer中最大路径长度的阶数。
2.3 分级Transformers
最后,我们简要回顾了提高Transformer捕获自然语言层次结构能力的方法,尽管它们从未用于时间序列预测。HIBERT(Miculiich等人,2018)首先使用Sent编码器提取句子的特征,然后将文档中句子的EOS标记形成新序列,并将其输入Doc编码器。然而,它专门用于自然语言,不能推广到其他序列数据。多尺度变换器(Subramanian等人,2020)使用自上而下和自下而上的网络结构学习序列数据的多尺度表示。这样的多尺度表示有助于减少原始Transformer的时间和内存成本,但它仍然存在二次复杂性的缺陷。或者,BP Transformer(Ye等人,2019)递归地将整个输入序列分成两个,直到一个分区只包含一个令牌。然后,分割的序列形成二叉树。在关注层中,每个上尺度节点可以关注自己的子节点,而下尺度的节点可以关注相同尺度的相邻A节点和所有较粗尺度的节点。请注意,BP Transformer使用零以较粗的比例初始化节点,而Pyraformer使用构造模块以更灵活的方式引入较粗的节点。此外,BP Transformer与比Pyraformer更密集的图相关联,因此产生了更高的O(L log L)复杂性。
3 方法
时间序列预测问题可以表示为预测未来M个步zt+1:t+M,给定之前的L个观察步zt−L+1:t和相关协变量xt−L+1:t+M(例如,一天中的小时)。为了实现这一目标,我们在本文中提出了Pyraformer,其总体架构如图2所示。如图所示,我们首先分别嵌入观测数据、协变量和位置,然后将它们相加,以与Informer相同的方式(Zhou等人,2021)。接下来,我们使用粗尺度构建模块(CSCM)构建多分辨率C元树,其中较粗尺度的节点汇总相应较细尺度的C节点的信息。为了进一步捕获不同范围的时间相关性,我们通过使用金字塔图中的注意力机制传递消息来引入金字塔注意力模块(PAM)。最后,根据下游任务,我们使用不同的网络结构来输出最终预测。在续集中,我们详细阐述了拟议模型的每一部分。为了便于说明,本文中的所有符号汇总在表4中。
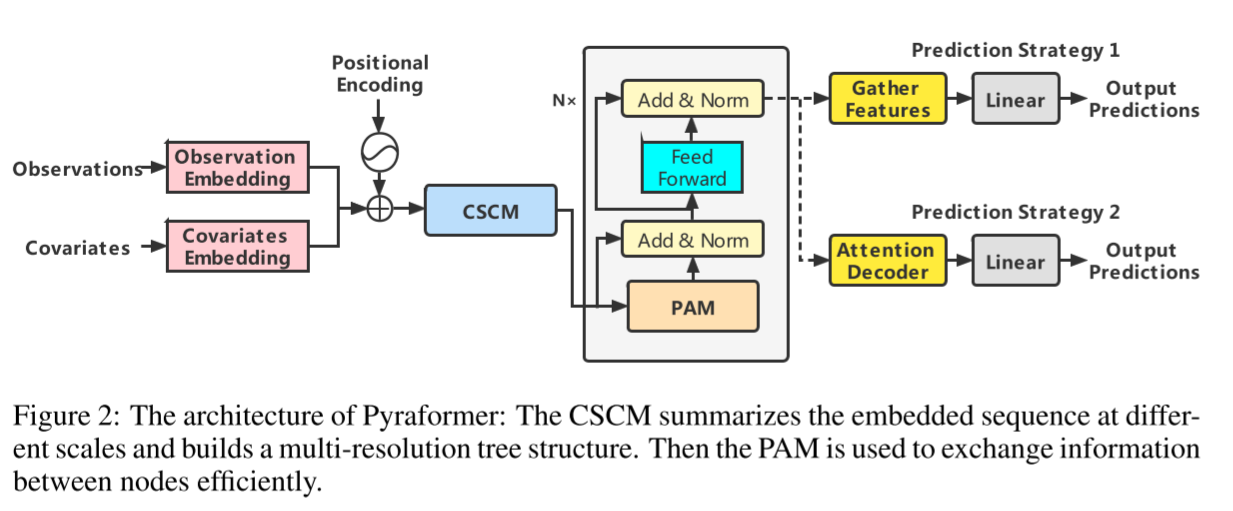
图2:Pyraformer的体系结构:CSCM总结了不同规模的嵌入序列,并构建了多分辨率树结构。然后使用PAM在节点之间高效地交换信息。
(2022年12月1日19:47,呜呜呜呜,我是废物。)
3.1 金字塔注意力模块(PAM)
我们首先介绍PAM,因为它位于Pyrafomer的核心。如图1(d)所示,我们利用金字塔图以多分辨率方式描述观察到的时间序列的时间相关性。这种多分辨率结构已被证明是计算机视觉(Sun等人,2019;Wang等人,2021)和统计信号处理(Choi等人,2008;Yu等人,2018)领域中远程交互建模的有效工具。我们可以将金字塔图分解为两个部分:尺度间连接和尺度内连接。尺度间的连接形成一个C元树,其中每个父节点都有C个子节点。例如,如果我们将金字塔图的最细尺度与原始时间序列的每小时观测值相关联,则更粗尺度的节点可以被视为时间序列的每日、每周甚至每月特征。因此,金字塔图提供了原始时间序列的多分辨率表示。此外,通过简单地经由尺度内连接来连接相邻节点,更容易在较粗尺度中捕获长距离依赖性(例如,月依赖性)。换言之,较粗的尺度有助于以一种图形化的方式描述长期相关性,这种方式远比单一的、最精细的尺度模型所能捕捉到的要简洁得多。事实上,原始的单尺度Transformer(见图1(a))采用了一个完整的图,以最精细的尺度连接每两个节点,以便对长距离依赖关系进行建模,从而产生了一个具有O(L2)时间和空间复杂性的计算负担模型(Vaswani等人,2017)。与之形成鲜明对比的是,如下图所示,所提出的Pyraformer中的金字塔图将计算成本降低到O(L),而不增加信号穿越路径的最大长度的阶数。
在深入研究PAM之前,我们首先介绍原始的注意力机制。设X和Y分别表示单个注意力头部的输入和输出。注意,可以引入多个头部来从不同的角度描述时间模式。首先将X线性变换为三个不同的矩阵,即查询Q=XWQ、关键字K=XWK和值V=XWV,其中WQ、WK、WV∈ RL×DK。对于Q中的第i行qi,它可以处理K中的任何行(即,键)。换句话说,对应的输出yi可以表示为:
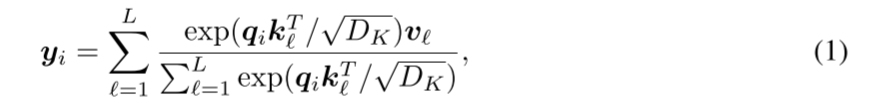
其中
![]()
表示K中行ℓ 的转置。我们强调需要计算和存储的查询关键点积(Q-K对)的数量决定了注意力机制的时间和空间复杂性。从另一个角度看,这个数字与图中的边数成比例(见图1(a))。由于所有Q-K对都被计算并存储在全注意力机制(1)中,因此产生的时间和空间复杂性为O(L2)。
3.1 金字塔注意力模块(PAM)
我们首先介绍PAM,因为它位于Pyrafomer的核心。如图1(d)所示,我们利用金字塔图以多分辨率方式描述观察到的时间序列的时间相关性。这种多分辨率结构已被证明是计算机视觉(Sun等人,2019;Wang等人,2021)和统计信号处理(Choi等人,2008;Yu等人,2018)领域中远程交互建模的有效工具。我们可以将金字塔图分解为两个部分:尺度间连接和尺度内连接。尺度间的连接形成一个C元树,其中每个父节点都有C个子节点。例如,如果我们将金字塔图的最细尺度与原始时间序列的每小时观测值相关联,则更粗尺度的节点可以被视为时间序列的每日、每周甚至每月特征。因此,金字塔图提供了原始时间序列的多分辨率表示。此外,通过简单地经由尺度内连接来连接相邻节点,更容易在较粗尺度中捕获长距离依赖性(例如,月依赖性)。换言之,较粗的尺度有助于以一种图形化的方式描述长期相关性,这种方式远比单一的、最精细的尺度模型所能捕捉到的要简洁得多。事实上,原始的单尺度Transformer(见图1(a))采用了一个完整的图,以最精细的尺度连接每两个节点,以便对长距离依赖关系进行建模,从而产生了一个具有O(L2)时间和空间复杂性的计算负担模型(Vaswani等人,2017)。与之形成鲜明对比的是,如下图所示,所提出的Pyraformer中的金字塔图将计算成本降低到O(L),而不增加信号穿越路径的最大长度的阶数。
在深入研究PAM之前,我们首先介绍原始的注意力机制。设X和Y分别表示单个注意力头部的输入和输出。注意,可以引入多个头部来从不同的角度描述时间模式。首先将X线性变换为三个不同的矩阵,即查询Q=XWQ、关键字K=XWK和值V=XWV,其中WQ、WK、WV∈ RL×DK。对于Q中的第i行qi,它可以处理K中的任何行(即,键)。换句话说,对应的输出yi可以表示为:
其中
![]()
表示K中行ℓ 的转置。我们强调需要计算和存储的查询关键点积(Q-K对)的数量决定了注意力机制的时间和空间复杂性。从另一个角度看,这个数字与图中的边数成比例(见图1(a))。由于所有Q-K对都被计算并存储在全注意力机制(1)中,因此产生的时间和空间复杂性为O(L2)。

此外,当尺度S的数量固定时,以下两个命题总结了所提出的金字塔注意力机制的时间和空间复杂性以及最大路径长度的顺序。我们请读者参阅附录C和D以获取证明。
命题1。对于给定的A和L,金字塔注意力机制的时间和空间复杂度为O(AL),当A是常数w.r.t.L时,它等于O(L)。
命题2。让图中两个节点之间的信号穿过路径表示连接它们的最短路径。那么,对于给定的A、C、L和S,金字塔图中两个任意节点之间的信号穿越路径的最大长度为O(S+L/CS−1/A),假设A和S是固定的,并且C满足方程(5),对于长度为L的时间序列,最大路径长度为O(1)。
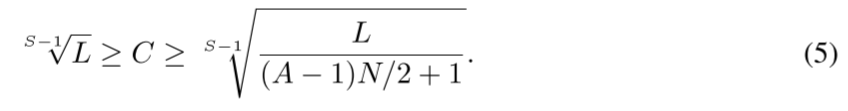
在我们的实验中,我们固定了S和N,而A只能取3或5,而不考虑序列长度L。因此,所提出的PAM实现了O(L)的复杂性,最大路径长度为O(1)。注意,在PAM中,一个节点最多可以处理A+C+1个节点。不幸的是,现有的深度学习库(如Pytorch和TensorFlow)不支持这种稀疏的注意力机制。可以充分利用张量运算框架的PAM的一个简单实现是首先计算所有Q-K对之间的乘积,比如.,
![]()
对于ℓ = 1,··,L,然后屏蔽掉
. 然而,这种实现的时间和空间复杂性仍然是O(L2)。相反,我们使用TVM构建了专门用于PAM的定制CUDA内核(Chen等人,2018),实际上减少了计算时间和内存成本,并使所提出的模型适合长时间序列。较长的历史输入通常有助于提高预测精度,因为提供了更多的信息,特别是在考虑长期相关性时。
3.2 粗尺度构建模块(CSCM)
CSCM的目标是在金字塔图的较粗尺度上初始化节点,以便于后续PAM在这些节点之间交换信息。具体地,通过对相应的子节点
![]()
执行卷积,从下到上逐尺度地引入粗尺度节点. 如图3所示,在时间维度上,具有内核大小C和步长C的几个卷积层被顺序应用于嵌入序列,产生一个长度为L/Cs的序列,其尺度为s。不同尺度下的结果序列形成一个C元树。在将这些精细到粗略的序列输入PAM之前,我们将它们连接起来。为了减少参数和计算量,我们在将序列输入到堆叠的卷积层之前,将每个节点的维度减少一个完全连接的层,并在所有卷积之后将其恢复。这种瓶颈结构显著减少了模块中的参数数量,并且可以防止过度拟合。
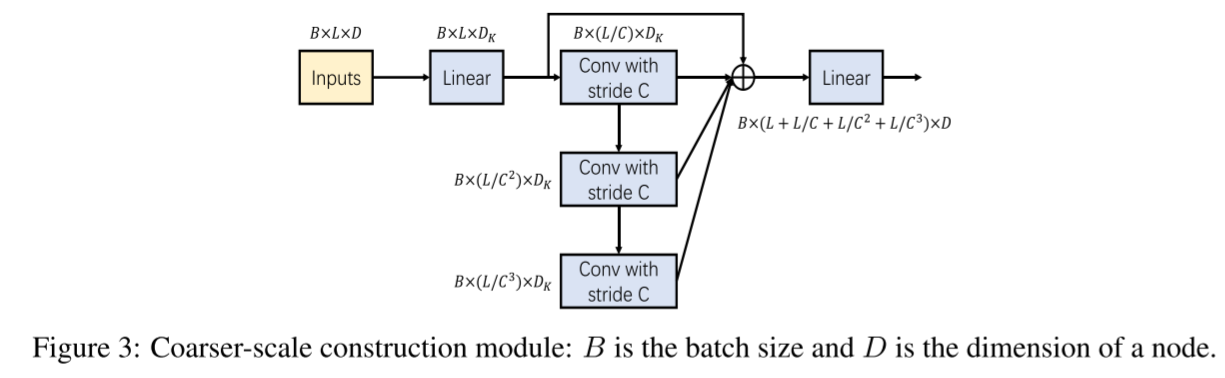
图3:更粗规模的构建模块:B是批量大小,D是节点的维度。
3.3 预测模块
对于单步预测,我们在历史序列zt−L+1:t的末尾添加一个结束标记(通过设置zt+1=0),然后将其输入到嵌入层。在序列被PAM编码后,我们收集金字塔图中所有尺度上最后一个节点给出的特征,将它们连接起来,然后输入到完全连接的层中进行预测。
对于多步预测,我们提出了两个预测模块。第一个与单步预测模块相同,但将所有尺度上的最后节点映射到批处理中的所有M个未来时间步长。另一方面,第二个解码器使用具有两个全注意力层的解码器。具体而言,与原始Transformer(Vaswani等人,2017)类似,我们将未来M个时间步长的观测值替换为0,以与历史观测值相同的方式嵌入它们,并将观测值、协方差和位置嵌入的总和作为“预测标记”Fp。然后,第一关注层将预测令牌Fp作为查询,将编码器Fe(即PAM中的所有节点)的输出作为关键字和值,并生成Fd1。第二关注层将Fd1作为查询,但将连接的Fd1和Fe作为关键字和值。历史信息Fe直接输入两个关注层,因为这些信息对于准确的长期预测至关重要。然后通过信道维度上的完全连接层获得最终预测。再次,我们一起输出所有未来预测,以避免Transformer的自回归解码器中的错误累积问题。
2.实验部分
部分实验代码
class Model(nn.Module):"""Vanilla Transformerwith O(L^2) complexityPaper link: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf"""def __init__(self, configs):super(Model, self).__init__()self.pred_len = configs.pred_lenself.output_attention = configs.output_attentionself.lstm = LSTM(input_size=configs.enc_in, hidden_size=configs.d_model, num_layers=3,batch_size=configs.batch_size)# Embeddingself.enc_embedding = DataEmbedding(configs.enc_in, configs.d_model, configs.embed, configs.freq,configs.dropout)# Encoderself.encoder = Encoder([EncoderLayer(AttentionLayer(FullAttention(False, configs.factor, attention_dropout=configs.dropout,output_attention=configs.output_attention), configs.d_model, configs.n_heads),configs.d_model,configs.d_ff,dropout=configs.dropout,activation=configs.activation) for l in range(configs.e_layers)],norm_layer=torch.nn.LayerNorm(configs.d_model))# Decoderself.dec_embedding = DataEmbedding(configs.dec_in, configs.d_model, configs.embed, configs.freq,configs.dropout)self.decoder = Decoder([DecoderLayer(AttentionLayer(FullAttention(True, configs.factor, attention_dropout=configs.dropout,output_attention=False),configs.d_model, configs.n_heads),AttentionLayer(FullAttention(False, configs.factor, attention_dropout=configs.dropout,output_attention=False),configs.d_model, configs.n_heads),configs.d_model,configs.d_ff,dropout=configs.dropout,activation=configs.activation,)for l in range(configs.d_layers)],norm_layer=torch.nn.LayerNorm(configs.d_model),projection=nn.Linear(configs.d_model, configs.c_out, bias=True))
数据集
数据集都可以,只要是时间序列格式,不限领域,类似功率预测,风电光伏预测,负荷预测,流量预测,浓度预测,机械领域预测等等各种时间序列直接预测。可以做验证模型,对比模型。格式类似顶刊ETTH的时间序列格式即可。
这里是时间列+7列影响特征+1列预测特征(也可以没有时间)

3.源码和详细讲解视频
考虑到有些同学复现不出来源码,源码报错太多,这里对源码进行了重构,保存源码的实现基础上加了很多可视化功能。
代码链接:https://www.bilibili.com/video/BV117qZYTE2m/?spm_id_from=333.999.0.0

)




