文章目录
- 1、原生pytorch(mp.spawn)
- 2、pytorch ddp (torchrun)
- 3、lightning fabric
- 4、Hugging Face Accelerate
- 4、总结与对比
- 4.1 mp.spawn
- 4.2 torchrun
- 4.3 Lightning Fabric
- 4.4 Hugging face accelerate
pytorch 分布式训练的四种方法。
我将会产生一份伪数据0到19共20个数,batch size=10,使用两个GPU来训练,提前执行一下
export CUDA_VISIBLE_DEVICES="0,1"
1、原生pytorch(mp.spawn)
import os
import torch
import torch.distributed as dist
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDPclass CustomDataset(Dataset):"""自定义数据集类"""def __init__(self):# 创建0到19的数据self.data = torch.arange(20)def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]def setup(rank, world_size):"""初始化分布式环境"""os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '12355'dist.init_process_group("nccl", rank=rank, world_size=world_size)def cleanup():"""清理分布式环境"""dist.destroy_process_group()def run_demo(rank, world_size):print(f"Running on rank {rank}")# 设置分布式环境setup(rank, world_size)# 将进程绑定到GPU上torch.cuda.set_device(rank)# 创建数据集和分布式采样器dataset = CustomDataset()sampler = DistributedSampler(dataset, num_replicas=world_size,rank=rank,shuffle=False)# 创建数据加载器dataloader = DataLoader(dataset=dataset,batch_size=10, # 每批次10个样本sampler=sampler, # 使用分布式采样器pin_memory=True)print(f"\nGPU {rank} 开始加载数据:")for batch_idx, data in enumerate(dataloader):# 将数据移到对应的GPU上data = data.cuda(rank)print(f'GPU {rank} - 批次 {batch_idx}: {data.tolist()}')# 清理分布式环境cleanup()def main():world_size = torch.cuda.device_count() # 获取可用的GPU数量print(f"发现 {world_size} 个GPU")if world_size < 2:print("需要至少2个GPU来运行此示例")return# 使用多进程启动mp.spawn(run_demo,args=(world_size,),nprocs=world_size,join=True)if __name__ == '__main__':main()执行结果:
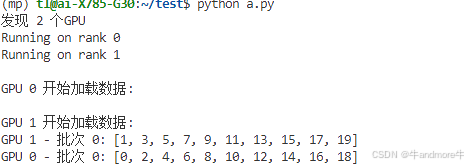
2、pytorch ddp (torchrun)
'''
Author: tianliang
Date: 2024-11-25 12:43:01
LastEditors:
LastEditTime: 2024-11-25 12:44:10
FilePath: /test/b.py
Description:
'''
import os
import torch
import torch.distributed as dist
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSamplerclass CustomDataset(Dataset):"""自定义数据集类"""def __init__(self):# 创建0到19的数据self.data = torch.arange(20)def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]def main():# 初始化分布式环境local_rank = int(os.environ["LOCAL_RANK"])world_size = int(os.environ["WORLD_SIZE"])# 初始化进程组dist.init_process_group(backend="nccl")torch.cuda.set_device(local_rank)print(f"Running on GPU {local_rank} of {world_size} GPUs")# 创建数据集和分布式采样器dataset = CustomDataset()sampler = DistributedSampler(dataset,num_replicas=world_size,rank=local_rank,shuffle=False)# 创建数据加载器dataloader = DataLoader(dataset=dataset,batch_size=10, # 每批次10个样本sampler=sampler, # 使用分布式采样器pin_memory=True)print(f"\nGPU {local_rank} 开始加载数据:")for batch_idx, data in enumerate(dataloader):# 将数据移到对应的GPU上data = data.cuda(local_rank)print(f'GPU {local_rank} - 批次 {batch_idx}: {data.tolist()}')# 清理分布式环境dist.destroy_process_group()if __name__ == '__main__':main()执行:
torchrun --nproc_per_node=2 dist_loader.py
结果

3、lightning fabric
使用前,需要安装
pip install lightning
代码:
'''
Author: tianliang
Date: 2024-11-25 12:47:44
LastEditors:
LastEditTime: 2024-11-25 12:54:12
FilePath: /test/c.py
Description:
'''
import torch
from torch.utils.data import Dataset, DataLoader
from lightning.fabric import Fabricclass CustomDataset(Dataset):"""自定义数据集类"""def __init__(self):# 创建0到19的数据self.data = torch.arange(20)def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]def main():# 初始化 Fabricfabric = Fabric(accelerator="cuda", devices=2, strategy="ddp")fabric.launch()# 创建数据集dataset = CustomDataset()# 创建数据加载器dataloader = DataLoader(dataset=dataset,batch_size=10, # 每批次10个样本shuffle=False)# 使用Fabric设置数据加载器dataloader = fabric.setup_dataloaders(dataloader)print(f"\nGPU {fabric.local_rank} 开始加载数据:")for batch_idx, data in enumerate(dataloader):# 数据已经自动移动到正确的设备上print(f'GPU {fabric.local_rank} - 批次 {batch_idx}: {data.tolist()}')if __name__ == '__main__':main()执行:
python fabric_loader.py
结果:

4、Hugging Face Accelerate
使用前要安装:
pip install accelerate
代码:
'''
Author: tianliang
Date: 2024-11-25 13:17:13
LastEditors:
LastEditTime: 2024-11-25 13:17:16
FilePath: /test/d.py
Description:
'''
import torch
from torch.utils.data import Dataset, DataLoader
from accelerate import Acceleratorclass CustomDataset(Dataset):"""自定义数据集类"""def __init__(self):# 创建0到19的数据self.data = torch.arange(20)def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]def main():# 初始化 acceleratoraccelerator = Accelerator()# 创建数据集dataset = CustomDataset()# 创建数据加载器dataloader = DataLoader(dataset=dataset,batch_size=10, # 每批次10个样本shuffle=False)# 使用 accelerator 准备数据加载器dataloader = accelerator.prepare(dataloader)# 获取当前进程的设备信息device = accelerator.deviceprocess_index = accelerator.process_indexnum_processes = accelerator.num_processesprint(f"\n进程 {process_index}/{num_processes-1} 在设备 {device} 上开始加载数据:")for batch_idx, data in enumerate(dataloader):# accelerator 已经自动将数据移动到正确的设备上print(f'进程 {process_index} - 批次 {batch_idx}: {data.tolist()}')# 确保所有进程都完成打印后再退出accelerator.wait_for_everyone()if __name__ == '__main__':main()有两种执行方式:
accelerate launch --multi_gpu accelerate_loader.py
torchrun --nproc_per_node=2 accelerate_loader.py
结果是一样的:

从结果上来看,这种方式和之前三个不同,交替分发策略可能更好,除非数成有时续性,或想保持数据局部性
4、总结与对比
4.1 mp.spawn
data_loader.py
mp.spawn(run_demo, args=(world_size,), nprocs=world_size, join=True)
优点:
- 完全控制分布式训练的每个细节
- 适合需要深度定制分布式策略的场景
- 便于调试和理解底层实现
缺点:
- 代码较为复杂
- 需要手动管理很多细节
- 容易出错
- 维护成本高
4.2 torchrun
# dist_loader.py
# 启动命令:torchrun --nproc_per_node=2 dist_loader.py
优点:
-
代码相对简洁
-
PyTorch官方推荐的方式
-
启动方式标准化
-
适合生产环境
-
便于在不同机器上部署
缺点: -
仍需要一定的分布式训练知识
-
调试相对困难
-
需要使用特定的启动命令
4.3 Lightning Fabric
# fabric_loader.py
fabric = Fabric(accelerator="cuda", devices=2, strategy="ddp")
优点:
-
代码最简洁
-
隐藏了大部分分布式训练的复杂性
-
提供了很多内置的优化和工具
-
适合快速开发和实验
-
容易扩展(可以方便地添加日志、检查点等功能)
-
调试友好
-
有完善的生态系统
缺点: -
需要额外依赖Lightning库
-
在某些特殊场景可能缺乏灵活性
-
可能会有一些性能开销
4.4 Hugging face accelerate
优点:
-
代码最简洁
-
配置系统灵活(通过accelerate config)
-
与Hugging Face生态完美集成
-
支持多种后端(DDP、DeepSpeed等)
-
适合transformer类模型
-
部署简单
缺点: -
依赖Accelerate库
-
某些PyTorch高级特性可能需要额外配置
选择:
对于算法开发和多GPU训练,我最推荐使用 Lightning Fabric,原因是:
1、开发效率
- 代码简洁,可以更专注于算法本身
- 快速实验和迭代
- 内置了很多有用的工具和优化
2、可扩展性
- 容易添加新功能(如日志记录、模型检查点等)
- 方便进行实验管理
- 支持各种训练策略的快速切换
3、调试友好
- 提供了很好的错误信息
- 有内置的调试工具
- 社区支持活跃
4、生产就绪
- 可以直接用于生产环境
- 性能优化已经内置
- 有很多最佳实践
具体的:
1、如果您的项目是:
- 研究导向
- 需要快速实验
- 需要完整的训练生态系统 → 选择 Lightning Fabric
2、如果您的项目是:
- 基于transformer架构
- 需要部署到生产环境
- 使用Hugging Face的其他工具 → 选择 Hugging Face Accelerate
3、如果您的项目是: - 需要深度定制化
- 对性能要求极高
不想引入额外依赖 → 选择 PyTorch DDP (torchrun)
如果您不确定: → 从 Lightning Fabric 开始,需要时可以轻松迁移到其他方案
总的来说,对于大多数现代深度学习项目,我最推荐 Lightning Fabric 和 Hugging Face Accelerate,它们提供了最好的开发体验和功能特性。只有在有特殊需求时,才考虑使用更底层的PyTorch DDP方案。

)




