转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
翻译来自:
Streams And Concurrency Webinar
可以看原版pdf,本博客只是挑选并翻译一下。
支持同时执行多个CUDA操作的能力 (超越了多线程并行性)
- CUDA Kernel <<<>>>
- cudaMemcpyAsync (HostToDevice)
- cudaMemcpyAsync (DeviceToHost)
- CPU上的操作
Fermi架构可以同时支持 (要求计算能力2.0+)
- 在GPU上最多有16个CUDA Kernel
- 2个cudaMemcpyAsyncs(必须是在不同的方向上)
- CPU上的计算
Stream:在GPU上按问题顺序执行的一系列操作。用于影响并发性的编程模型:
- 不同流中的CUDA操作可以并发地进行
- 来自不同流的CUDA操作可以交错进行


默认Stream (又称为 Stream 0),即未指定流时使用的流。
并发性要求
- CUDA操作必须在不同的、非0的流中;
- cudaMemcpyAsync时是主机中的'pinned' memory;
- 必须有足够的资源:
- cudaMemcpyAsyncs在不同的方向上;
- 设备资源(SMEM、registers、blocks等);
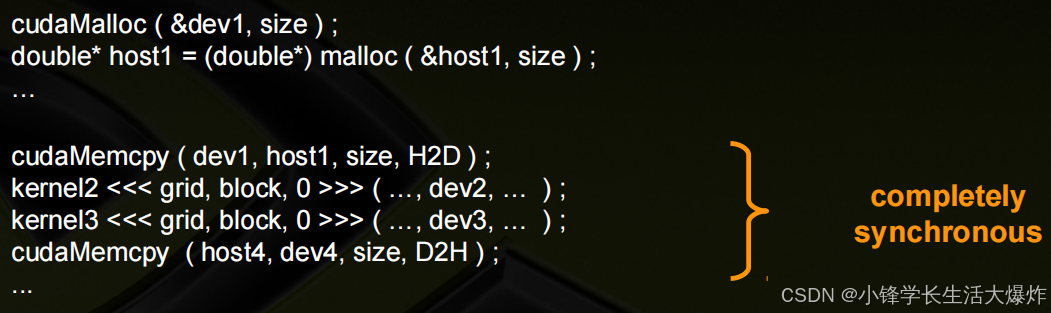
简单的同步示例:默认流中的所有CUDA操作都是同步的
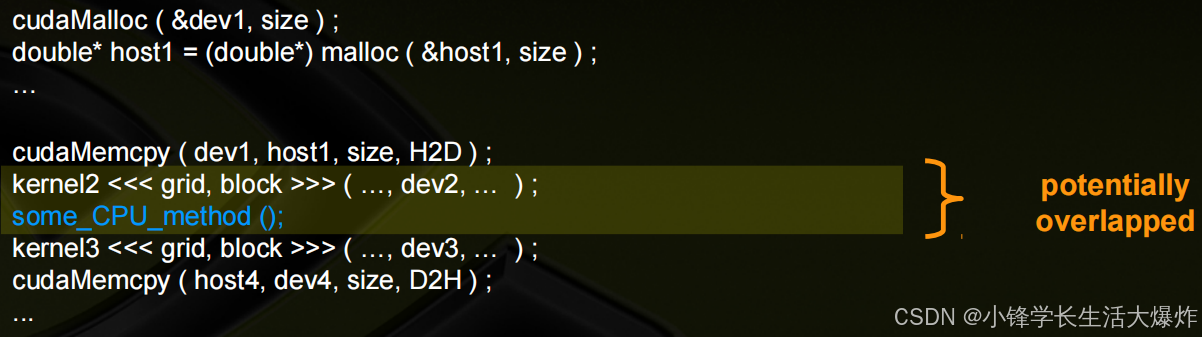
简单的异步且没有流的示例:默认情况下,GPU内核与主机是异步的
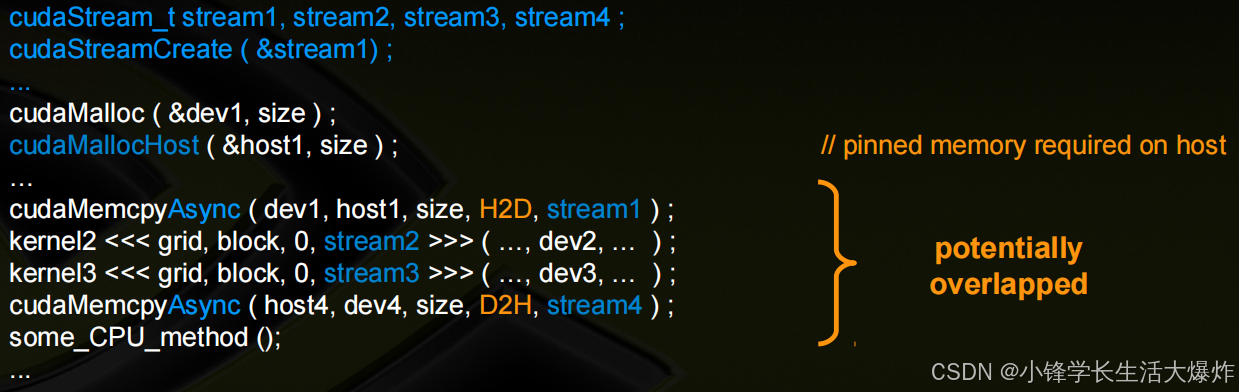
简单的使用了流的异步示例:完全异步/并发,并发操作所使用的数据需要是独立的
显式同步的情况
- 同步所有内容
- cudaDeviceSynchronize ()
- 阻止主机,直到所有发出的CUDA调用都完成
- 特定的流中同步w.r.t.
- cudaStreamSynchronize ( streamid )
- 阻塞主机,直到流中的所有CUDA调用完成
- 使用事件同步
- 在流中创建特定的“事件”,以用于同步
- cudaEventRecord ( event, streamid )
- cudaEventSynchronize ( event )
- cudaStreamWaitEvent ( stream, event )
- cudaEventQuery ( event )
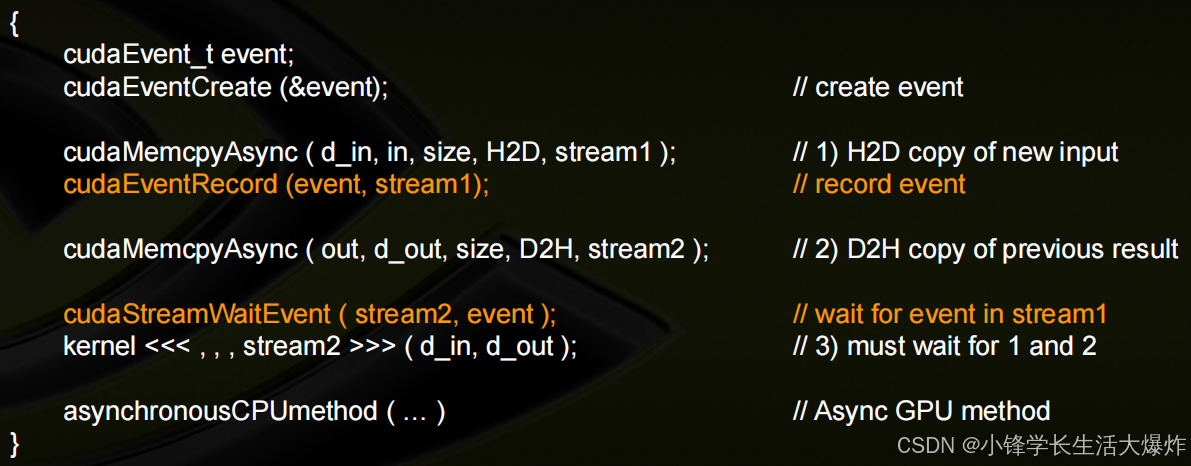
显式同步示例:使用事件解决
隐式同步:这些操作会隐式地同步所有其他CUDA操作
- 锁定页面的内存分配
- cudaMallocHost
- cudaHostAlloc
- 设备内存分配
- cudaMalloc
- 内存操作的非异步版本
- cudaMemcpy* (no Async suffix)
- cudaMemset* (no Async suffix)
- 更改为L1/共享内存配置
- cudaDeviceSetCacheConfig
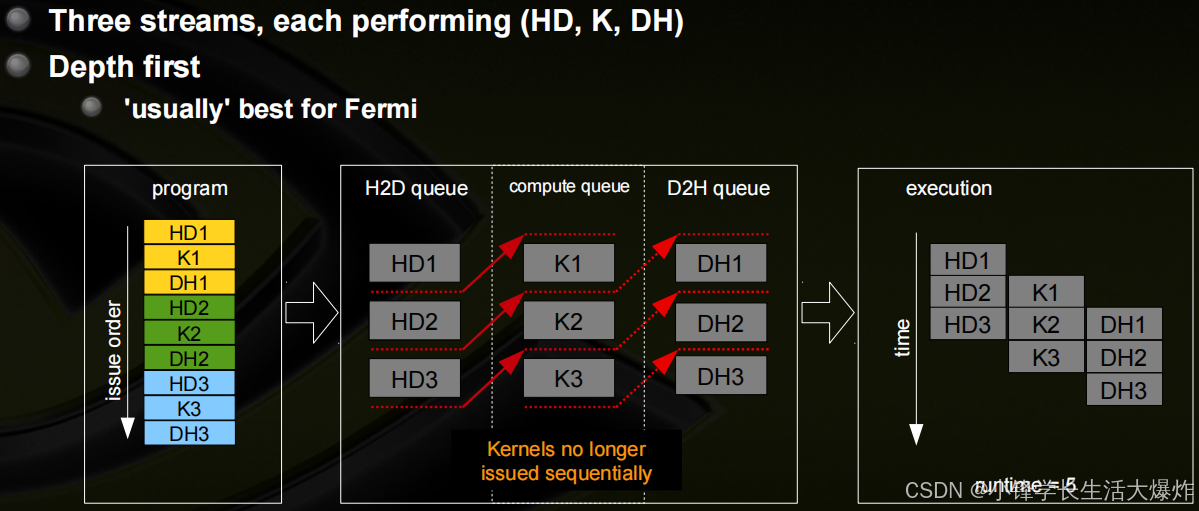
流的调度
- Fermi硬件有3个队列
- 1个计算引擎队列
- 2个复制引擎队列:一个用于H2D,一个用于D2H
- CUDA操作按它们被发布的顺序被发送到HW
- 被放置在相关的队列中
- 维护了引擎队列之间的流依赖关系,但在引擎队列中丢失
- 如果出现以下情况,则将从引擎队列分派CUDA操作:
- 在同一流中的先前的调用已经完成
- 在同一流中的先前的调用已经分派
- 资源可用
- 如果CUDA内核在不同的流中,则可以并发地执行它们
- 如果前面内核的所有线程块都已调度,并且仍然有SM资源可用,则调度给定内核的线程块
- 请注意,一个被阻塞的操作会阻止队列中的所有其他操作,甚至在其他流中
Blocked Queue的示例
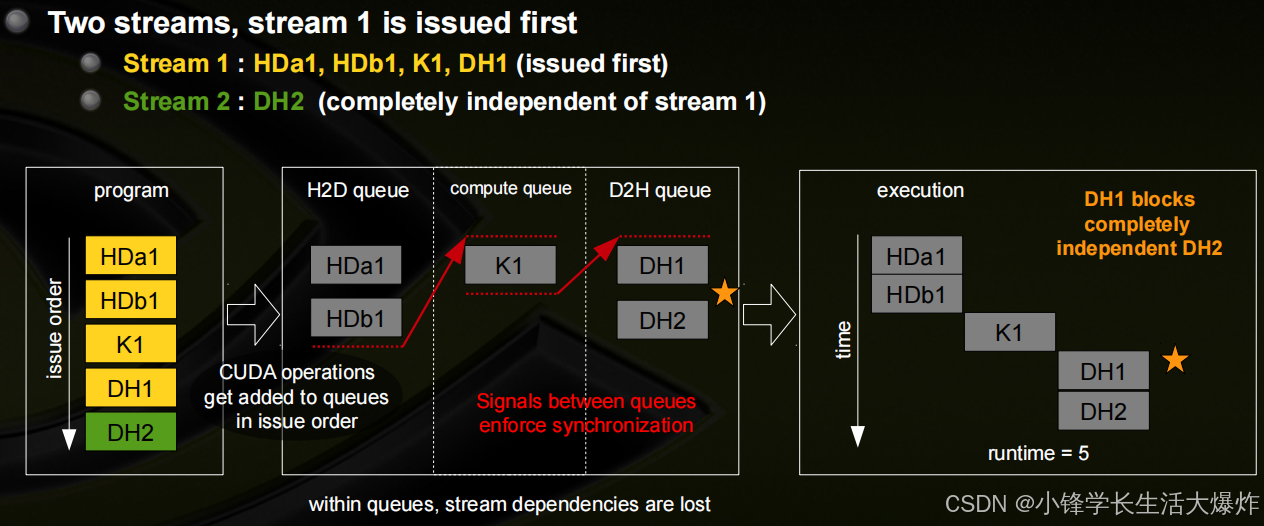
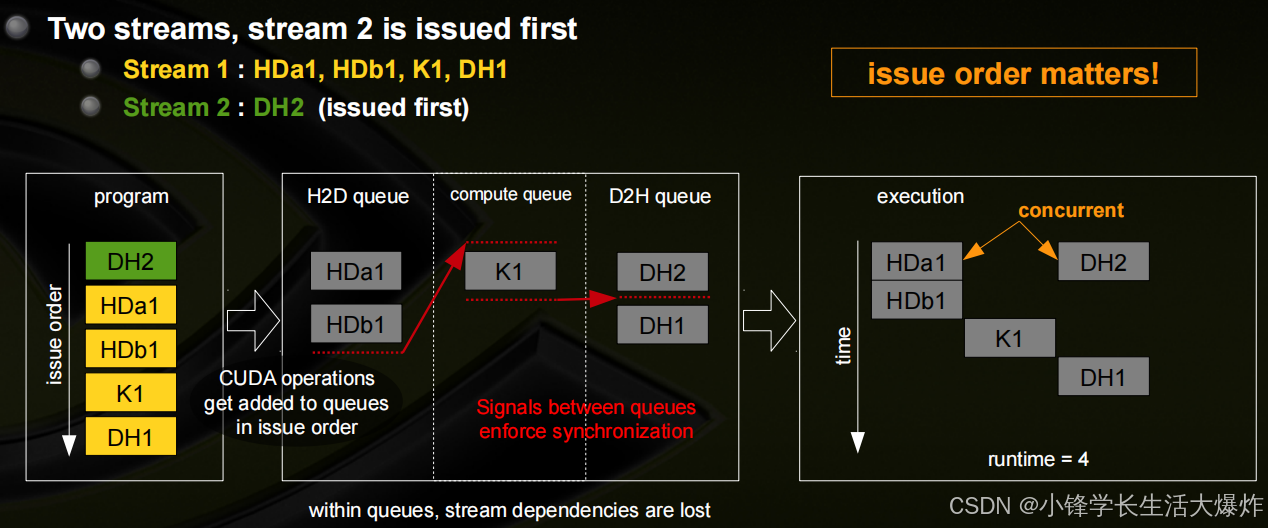
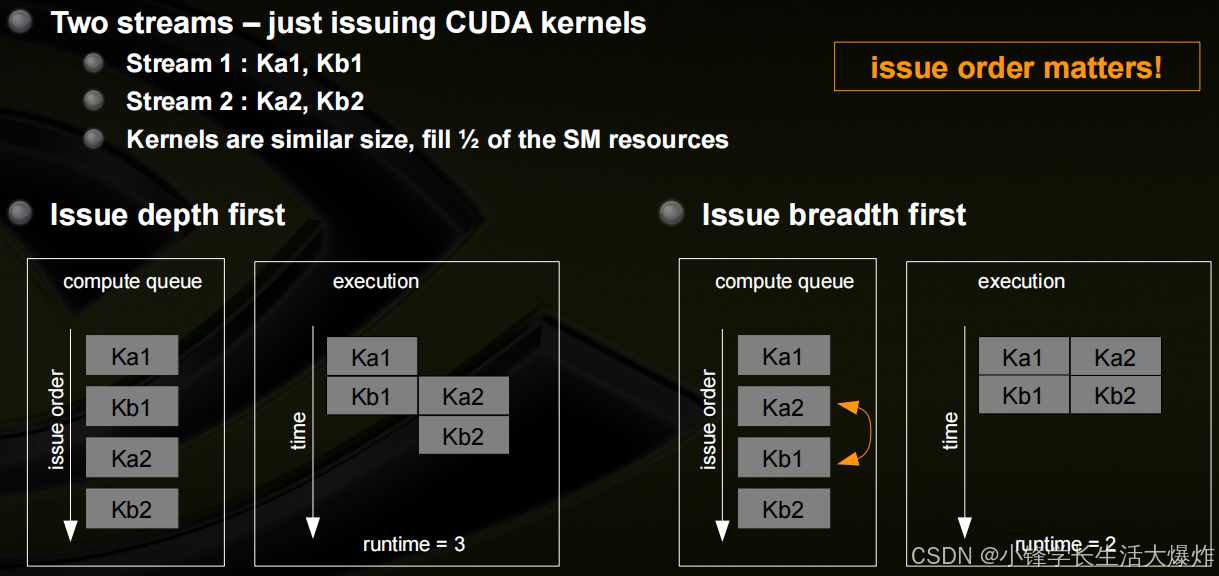
最优并发性可能取决于内核的执行时间

并发内核的调度
- 并发内核调度很特殊
- 通常,在操作后将信号插入队列,在同一流中启动下一个操作
- 对于计算引擎队列,若要启用并发内核,当计算内核按顺序发出时,该信号将延迟到最后一个顺序计算内核之后
- 在某些情况下,这种信号的延迟可能会阻塞其他队列
并发内核和阻塞的示例
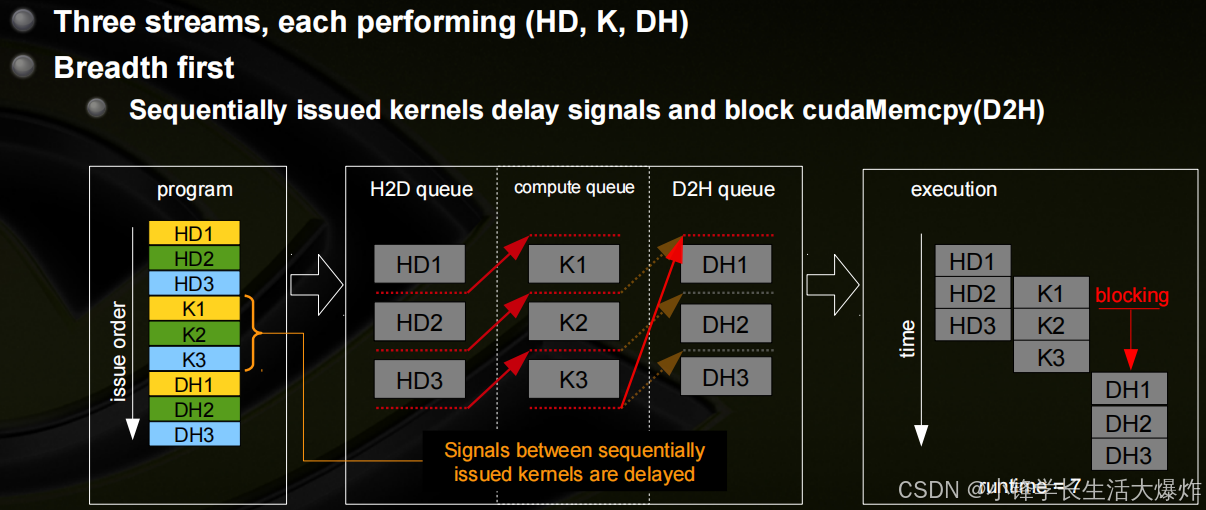
其他的详细信息
- 很难同时运行超过4个内核
- 可以使用环境变量禁用并发性:CUDA_LAUNCH_BLOCKING
- cudaStreamQuery可以用来分离连续的核,防止延迟信号
- 使用超过8个textures的内核不能并发运行
- 切换L1/共享配置将破坏并发性
- 要并发运行,CUDA操作必须有不超过62个介入的CUDA操作。也就是说,按照“问题顺序”,它们不能被超过62个其他问题分开,进一步的操作会被序列化。
- cudaEvent_t对于计时很有用,但对于性能的使用可以用cudaEventCreateWithFlags ( &event, cudaEventDisableTiming )

)




