一、模型介绍
- Baichuan 2 是百川智能推出的新一代开源大语言模型 ,采用 2.6 万亿 Tokens 的高质量语料训练。
- Baichuan 2 在多个权威的中文、英文和多语言的通用领域 benchmark 上取得同尺寸最佳的效果。
- 包含 7B 、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化 。
更多详细信息见 Github仓库
二、模型搭建流程
1. 选择主机和镜像
Baichuan2 项目自带了 Web 交互界面,并在项目运行中自动下载所需的模型参数,因此,克隆项目后,安装项目所需环境,然后直接运行即可,下面将以Baichuan2-13B-Chat模型进行部署,由于模型较大,建议使用RTX3090及以上显卡。
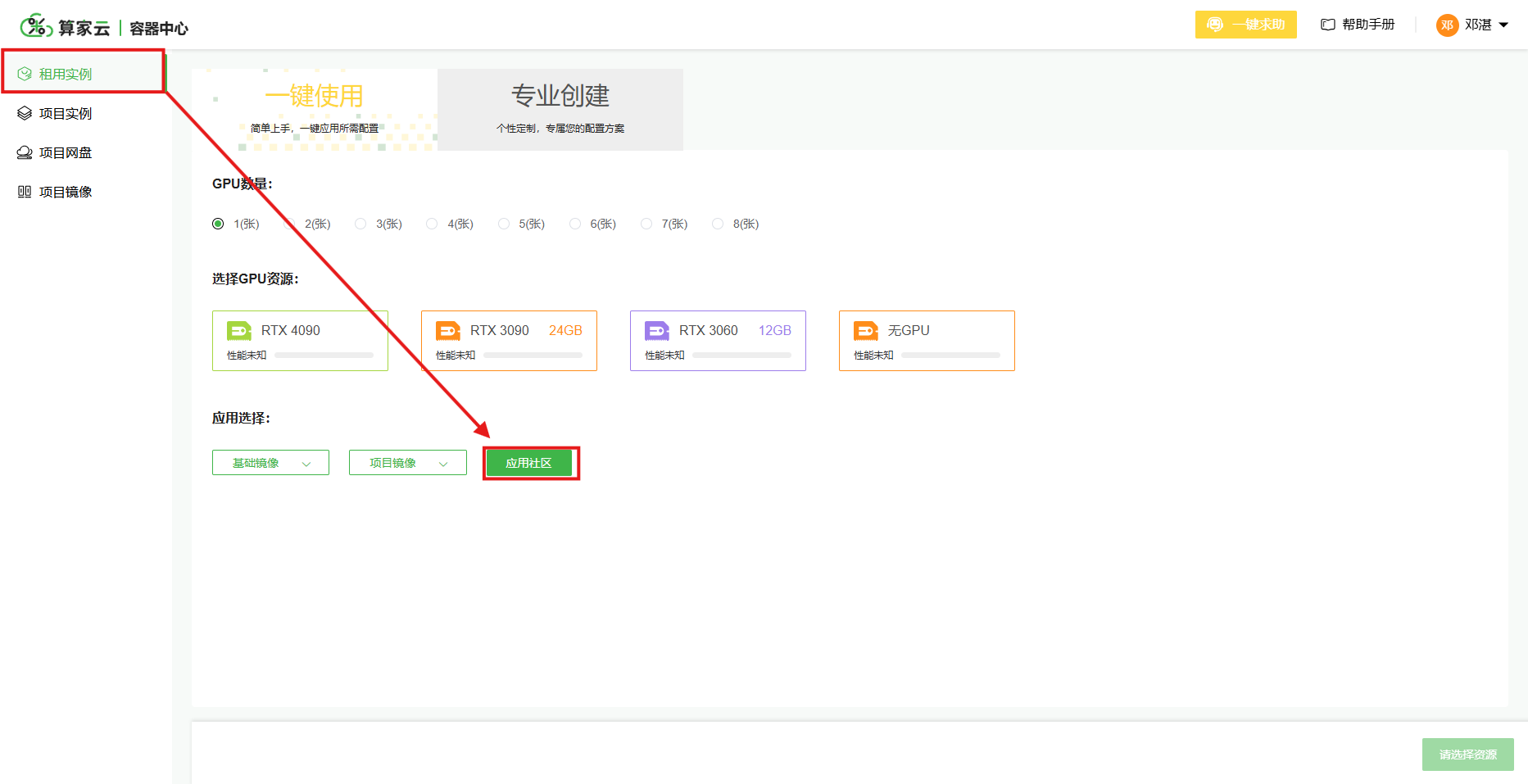
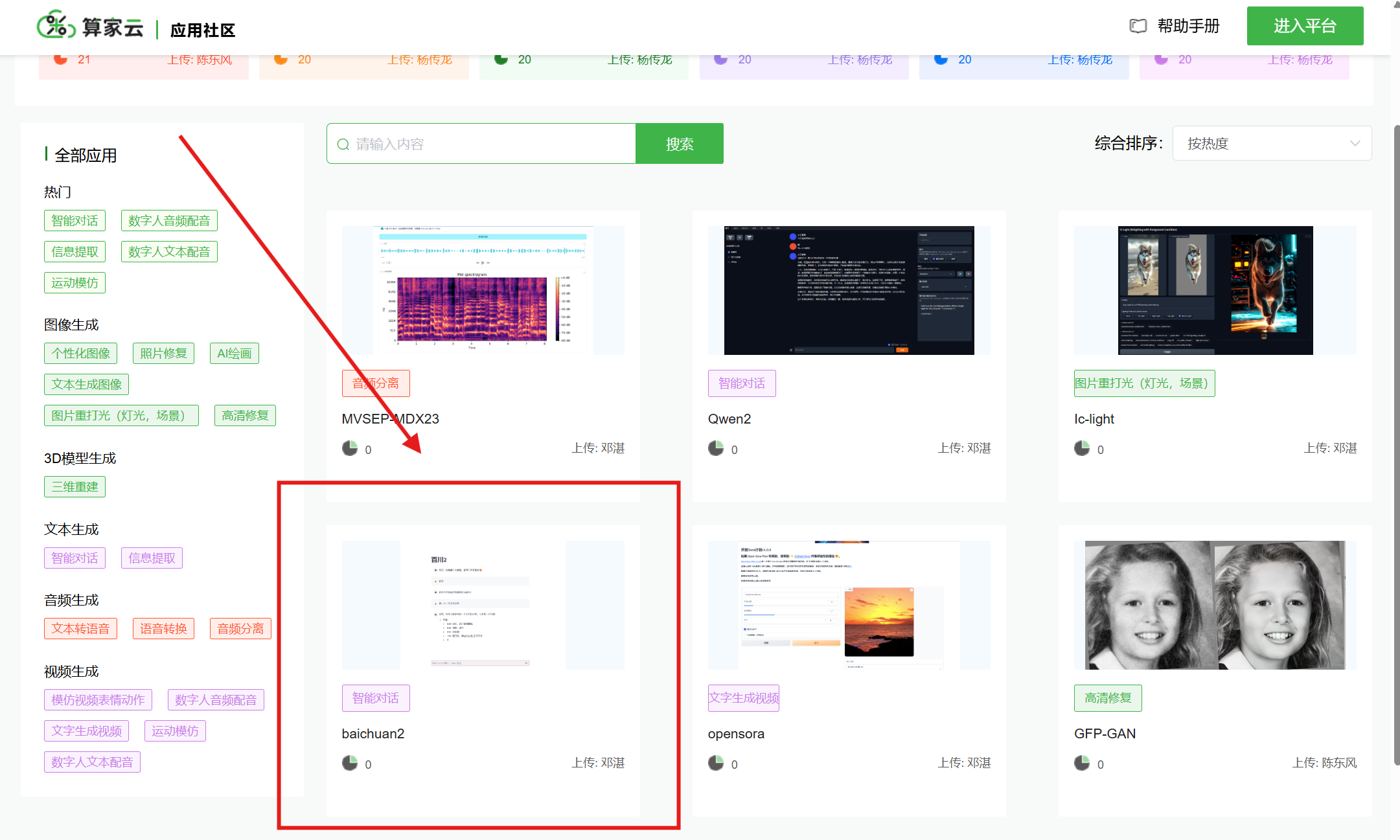
(1)在“租用实例”页面点击进入应用社区,选择相应的模型
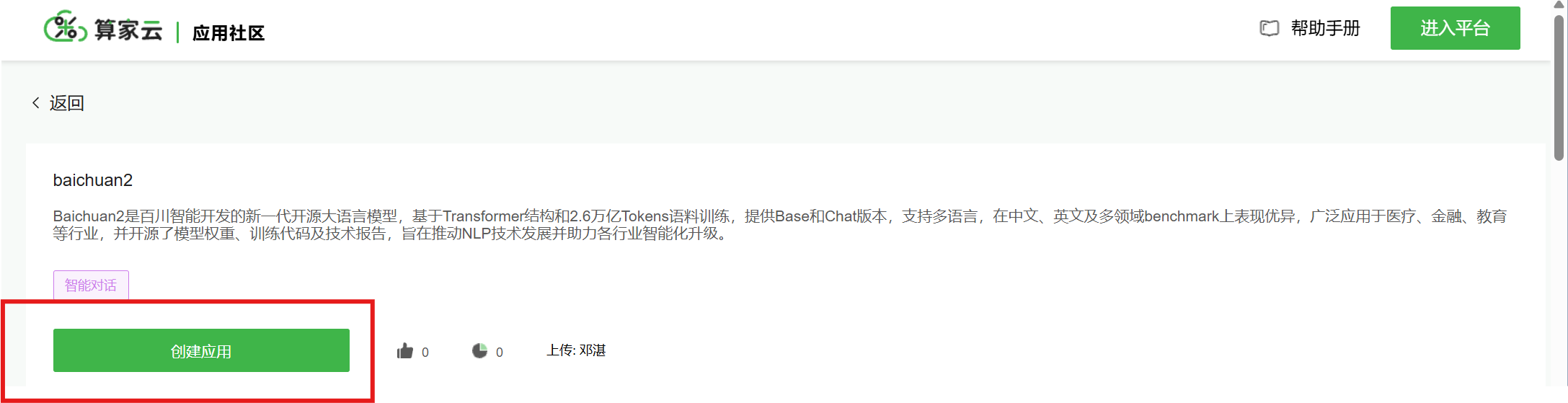
(2)选择模型后,点击“创建应用“,进入“租用实例“页面,选择3090或4090显卡,点击“立即创建“即可创建成功
立即创建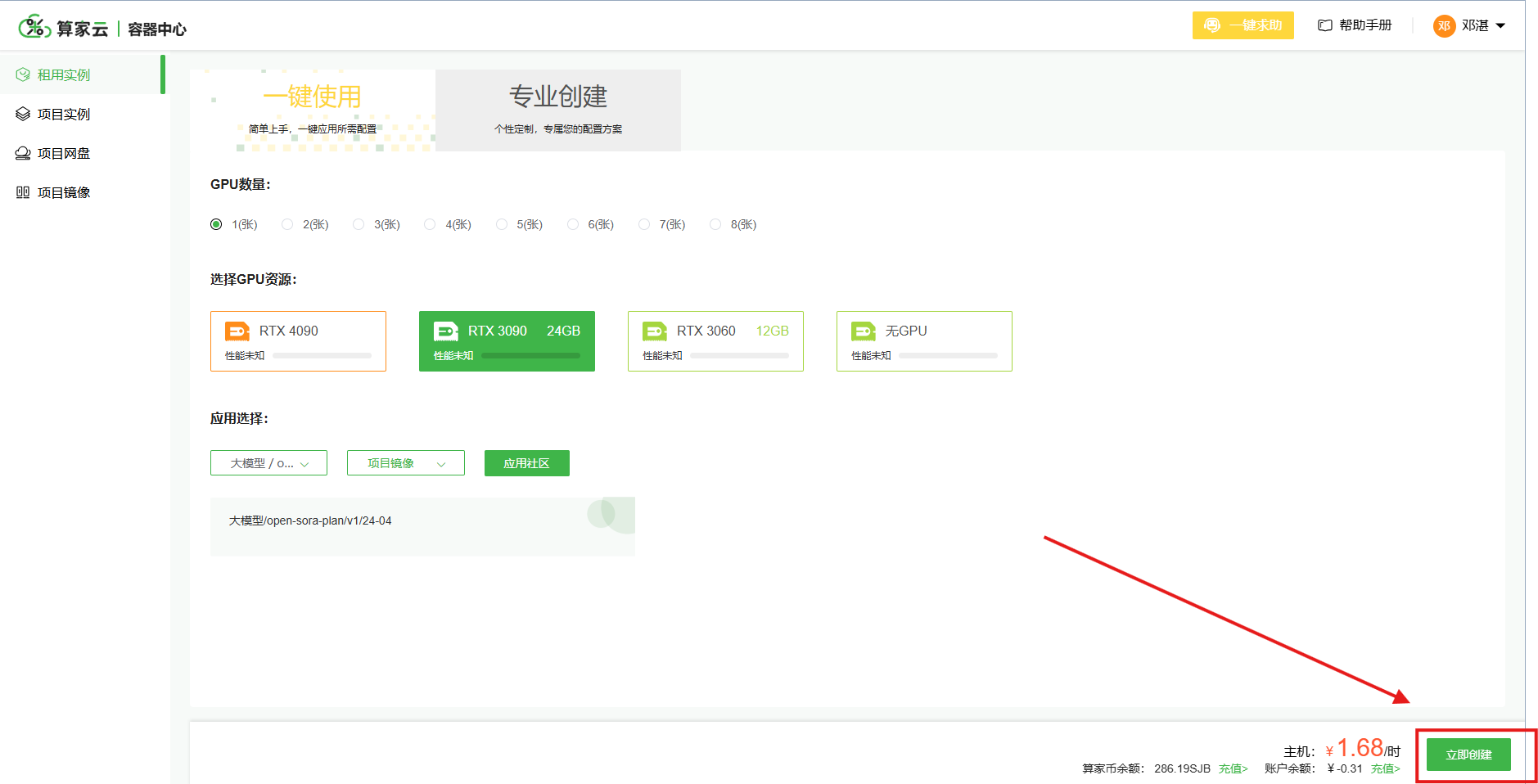
2.进入创建的实例
在“项目实例”页面点击对应实例的“Web SSH”进入终端操作
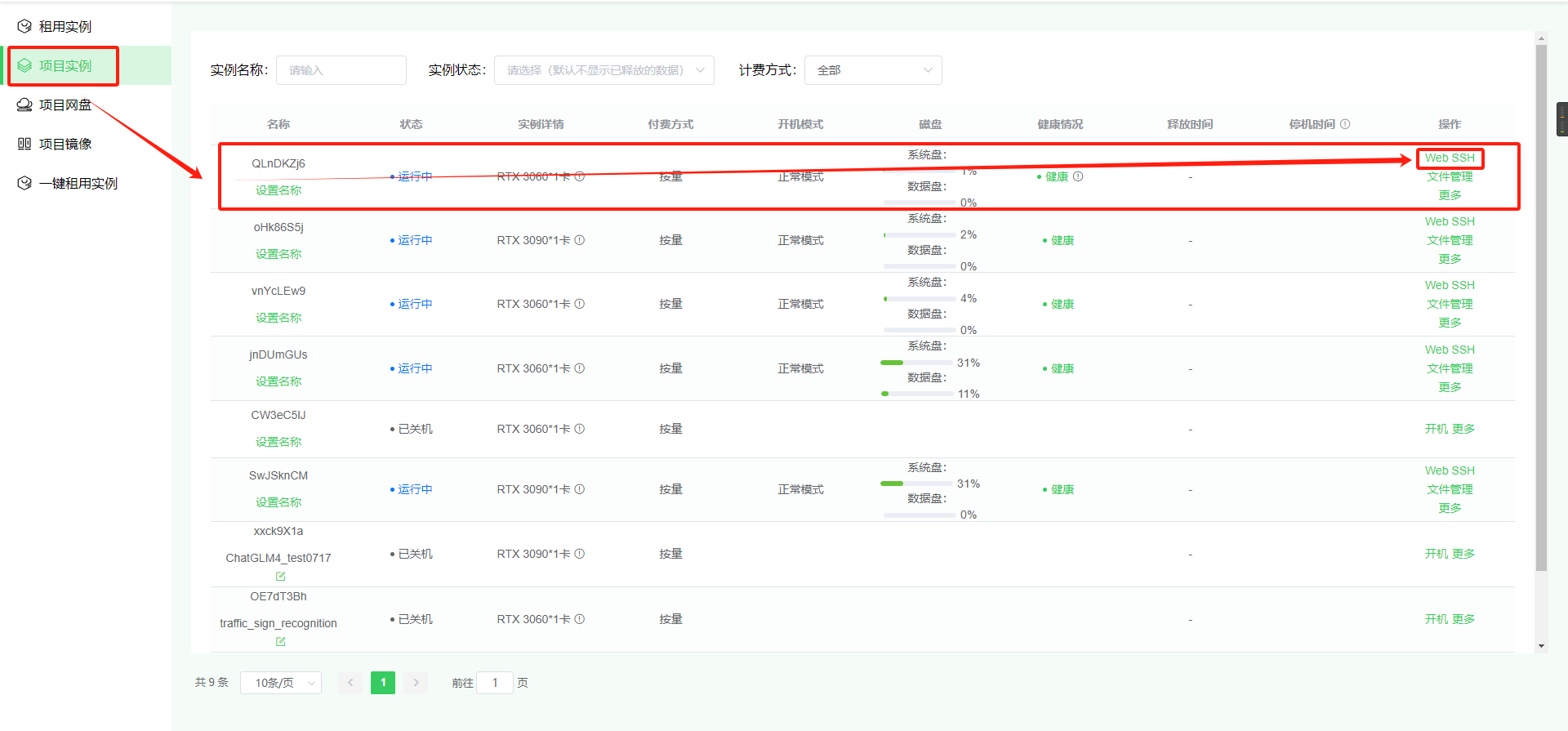
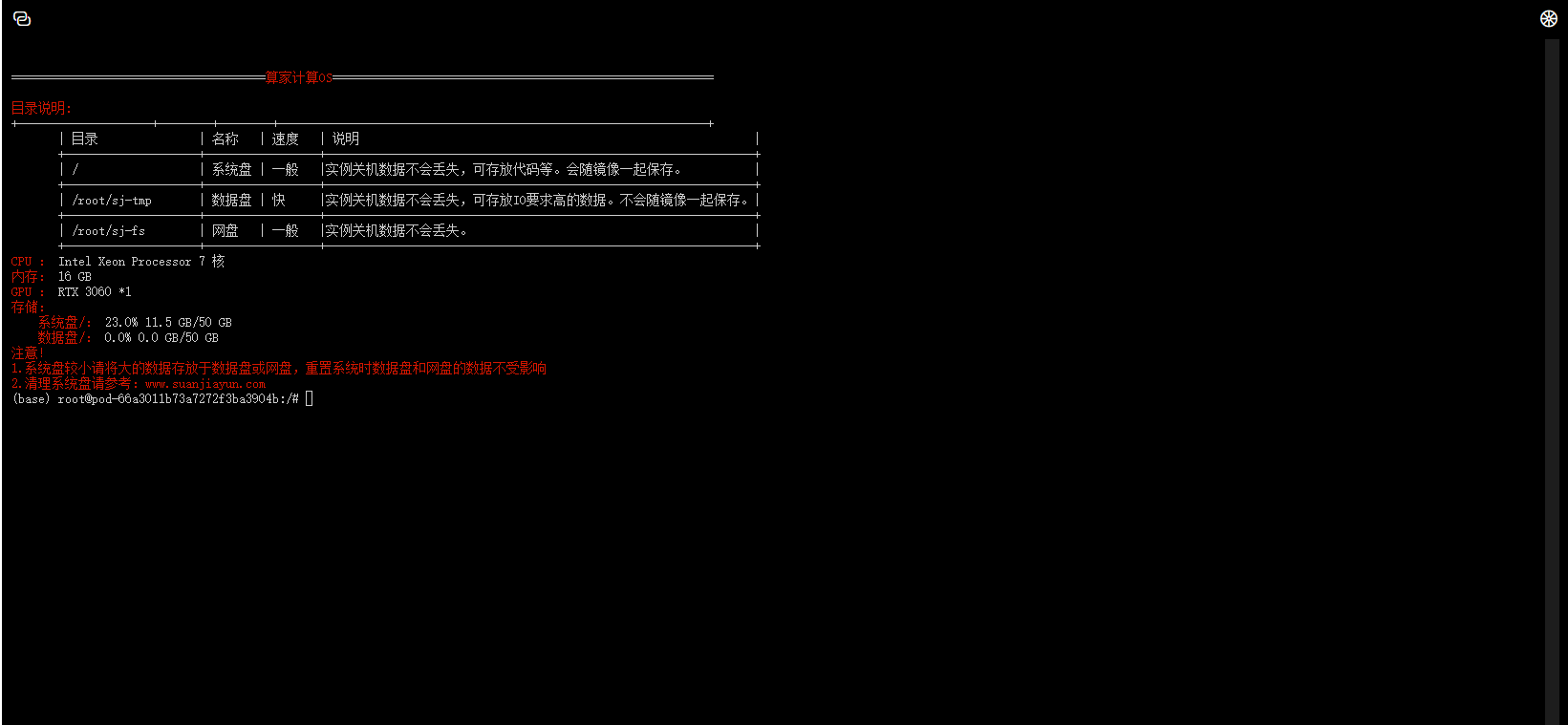
以下命令均在该页面进行:
(1)打开文件
cd Baichuan2
(2)激活虚拟环境Baichuan2
conda activate Baichuan2
(3)指定端口,运行py文件
streamlit run --server.address 0.0.0.0 --server.port 8080 web_demo.py
出现以下页面即为运行成功(使用了RTX3090)

若使用RTX3060则会出现以下运行不成功页面

3.开启外部访问获取访问链接
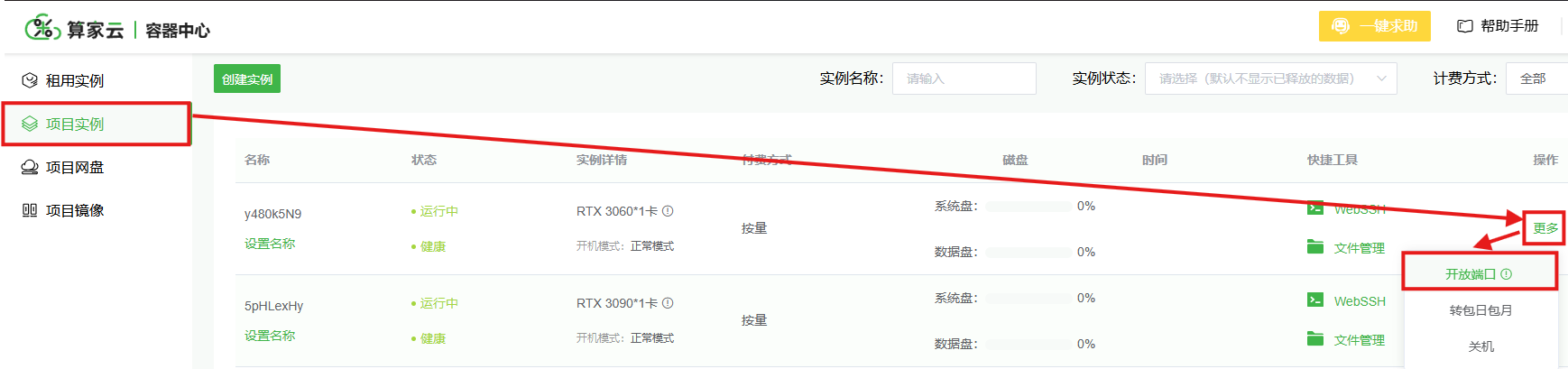
返回“项目实例”列表,选择并点击对应实例的“更多”-“开放端口”操作。
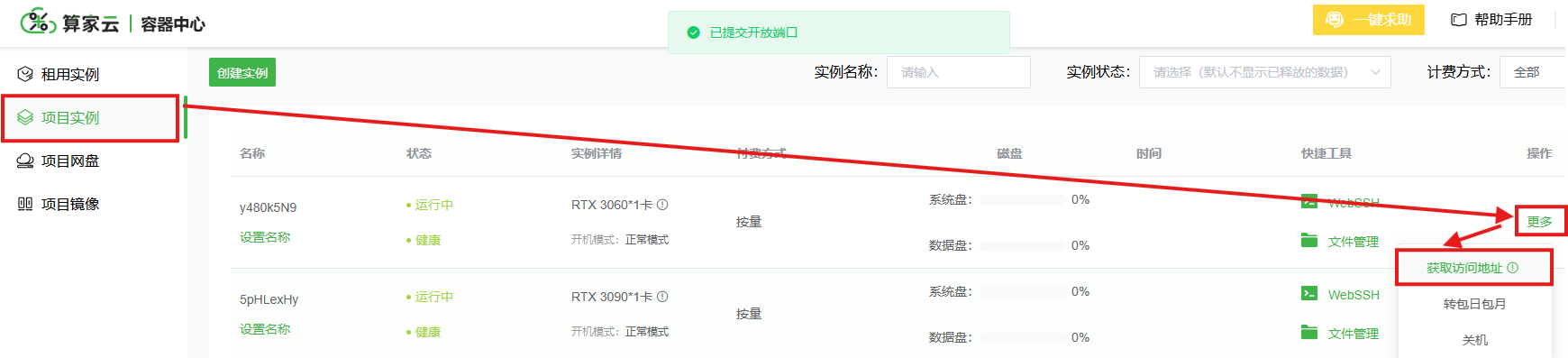
等待页面刷新后,选择并点击对应实例的“更多”–>“开放端口”–>“获取访问地址”操作。访问的网址就已经复制到剪切板。
4.进入 webUI 界面后即可操作
将复制的访问网址复制到新网页即可开始 ui 界面的使用
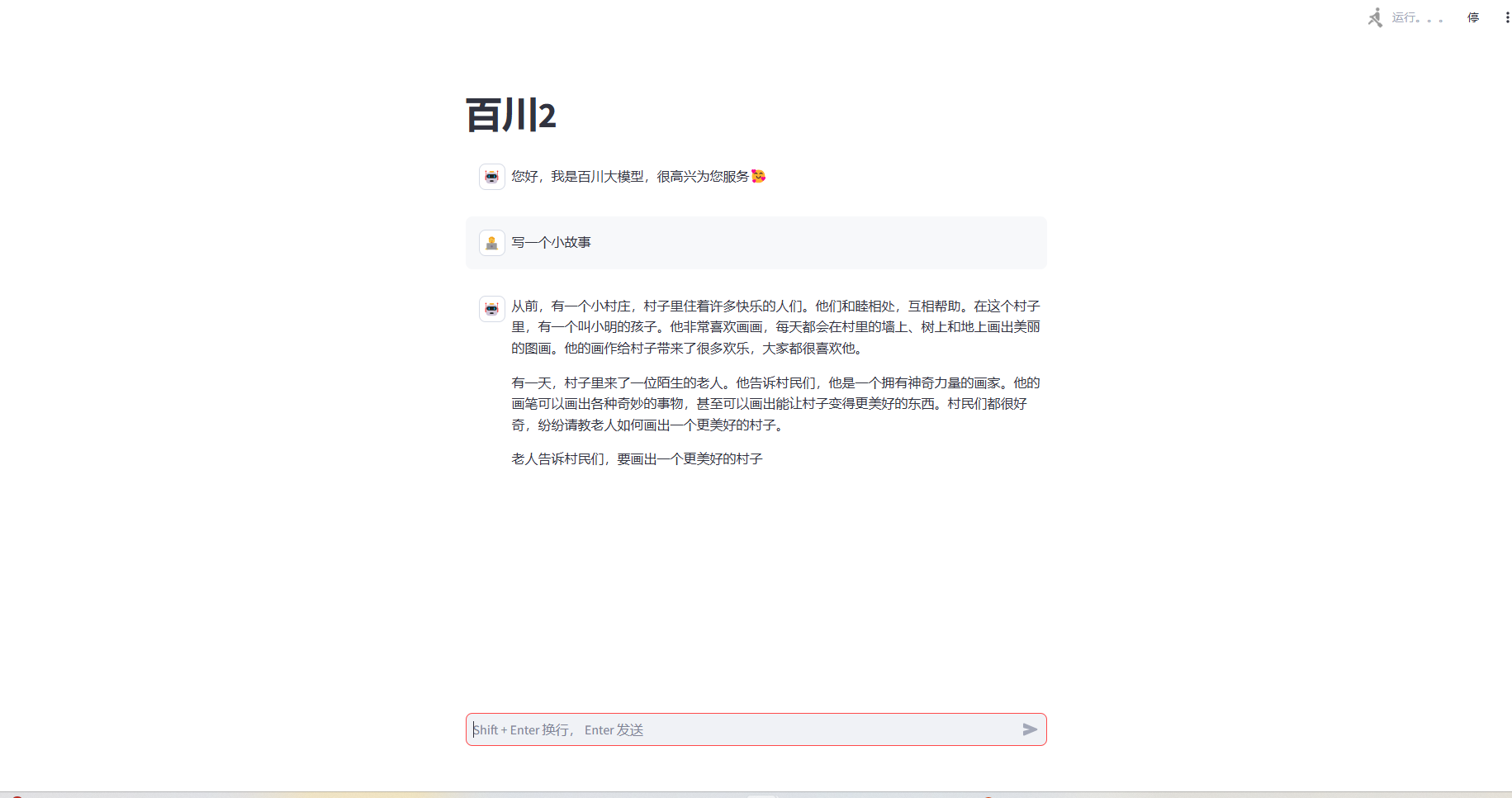
5.注意
RTX3090在运行Baichuan2-13B-Chat模型时仅仅只是运行成功,文字生成的速度大概是一秒钟两个字左右,若想要速度更快,则需要更换更加轻量化模型,可以使用在线量化,以下用Baichuan2-13B-Chat模型的4bits量化模型作为示例
打开web_demo.py文件,替换相应代码
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(4).cuda()
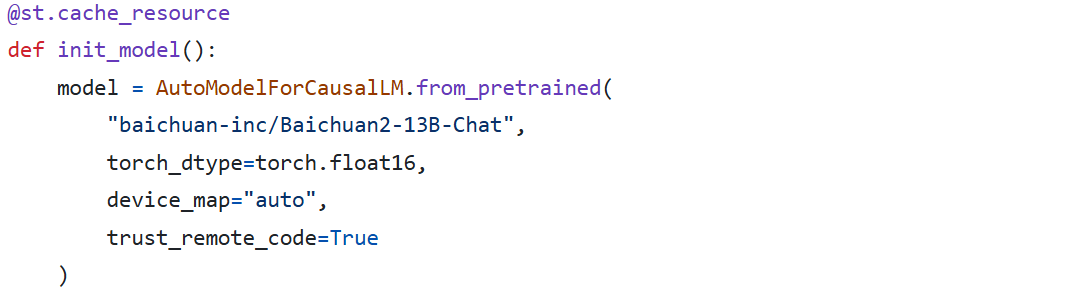

重新运行后速度每秒达到十多字!
)

)



