Redis的string的底层实现原理
大家好!今天我们来聊聊Redis中最基础也最常用的数据类型——string。就像我们日常生活中使用的记事本一样,Redis的string类型可以记录各种信息,从简单的"hello world"到复杂的JSON数据,甚至是二进制数据。但你知道吗?
这个看似简单的string类型,在Redis内部却有着精妙的设计和实现。
在实际工作中,我们经常会遇到这样的场景:
- 需要缓存用户信息、存储配置项或者记录计数器。
这时候Redis的string类型就是我们的首选。但为什么它能如此高效?为什么它能支持如此多样的操作?让我们一起来揭开Redis string底层实现的神秘面纱。
一、Redis string的执行流程
理解了Redis string的重要性后,我们来看它的执行流程。就像快递员送包裹一样,Redis处理string操作也有一套完整的流程。
当我们向Redis发送一个SET命令时,整个过程大致如下:
- 客户端发送命令到Redis服务器
- 服务器解析命令并验证参数
- 根据value的长度和内容选择合适的内部编码
- 分配内存并存储数据
- 返回操作结果给客户端
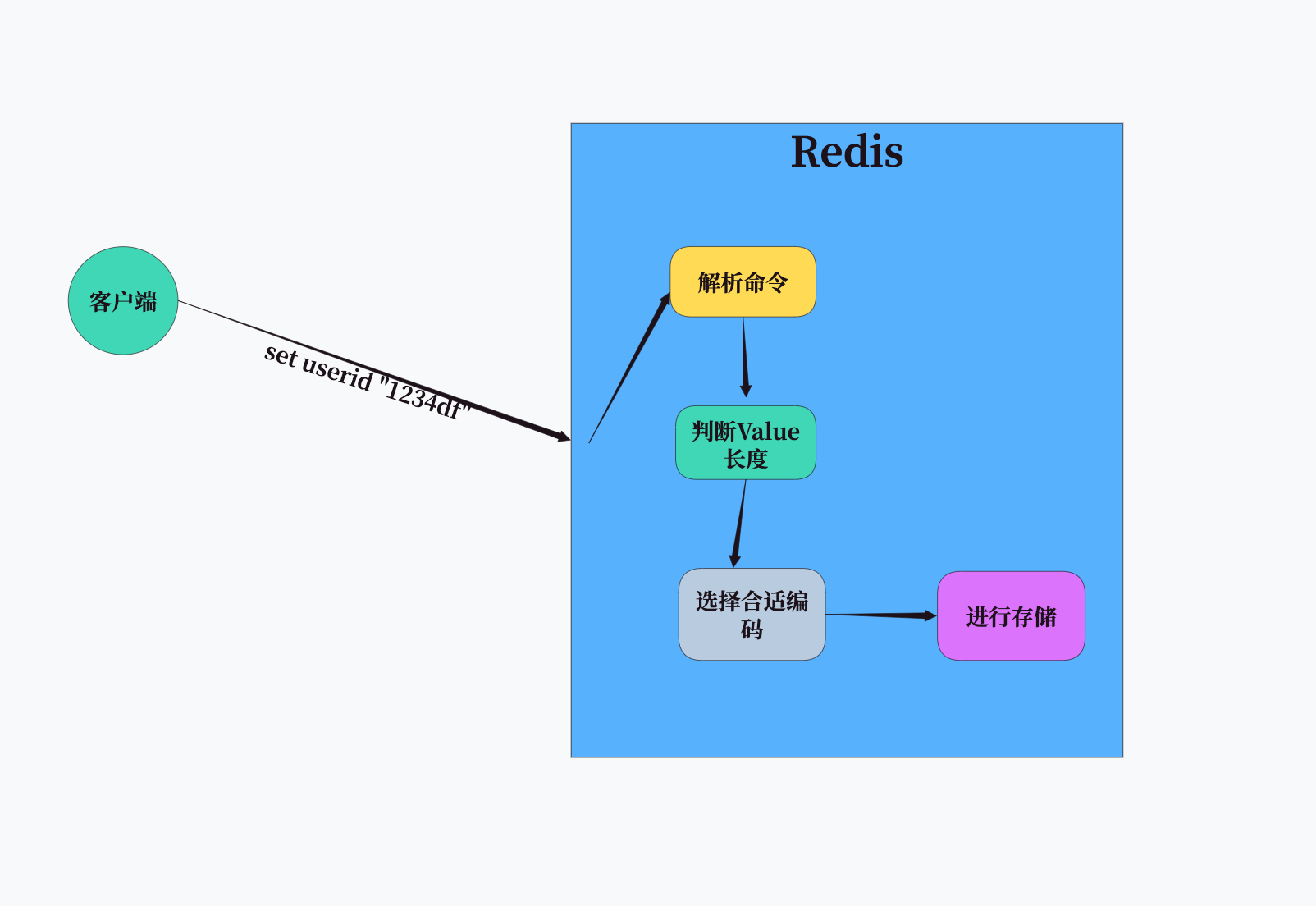
这个流程看似简单,但其中第三步"选择合适的内部编码"尤为关键。Redis会根据value的不同特性,选择最节省内存、最高效的存储方式。这就像我们整理衣柜时,会根据衣服的类型选择不同的收纳方式一样。
二、Redis string的技术原理
了解了执行流程后,我们深入探讨Redis string的技术原理。Redis string的底层实现并不是简单的C语言字符串,而是采用了多种编码方式以适应不同场景。
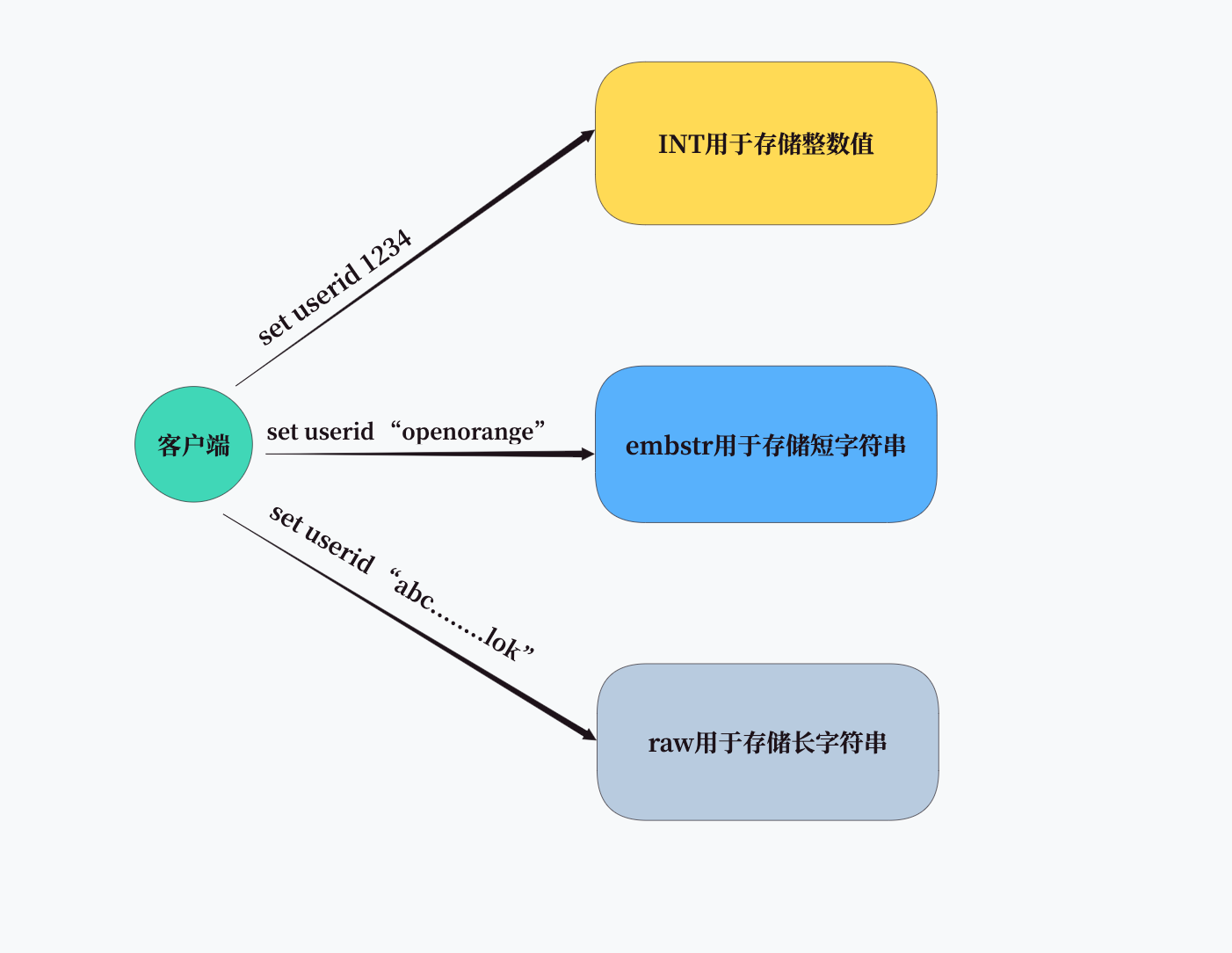
Redis string主要使用三种编码方式:
- int:用于存储整数值
- embstr:用于存储短字符串
- raw:用于存储长字符串
这种多编码的设计理念,就像我们工具箱中的不同工具,针对不同任务选择最合适的工具,以达到最高效的工作效果。
1. int编码
当存储的值是一个整数时,Redis会使用int编码。这种编码方式直接将数值存储在指针位置,不需要额外的内存分配,非常高效。
SET counter 100
OBJECT ENCODING counter // 输出"int"
上述代码展示了如何设置一个整数值并查看其编码类型。int编码的优势在于:
- 内存占用极小
- 计算操作(如INCR)非常高效
- 不需要额外的内存分配
2. embstr编码
对于长度小于等于44字节的字符串,Redis会使用embstr编码。这种编码方式将RedisObject和实际数据存储在连续的内存空间中。
SET short_str "hello"
OBJECT ENCODING short_str // 输出"embstr"
embstr编码的特点:
- 内存分配一次完成,效率高
- 数据局部性好,缓存命中率高
- 适合短字符串存储
3. raw编码
当字符串长度超过44字节时,Redis会使用raw编码。这种编码方式将RedisObject和实际数据分开存储。
SET long_str "This is a very long string that exceeds 44 bytes..."
OBJECT ENCODING long_str // 输出"raw"
raw编码虽然需要两次内存分配,但对于大字符串来说更加灵活:
- 可以处理任意长度的字符串
- 修改操作更加高效(不需要重新分配整个结构)
- 适合大文本或二进制数据
**注意:**44字节这个阈值在不同Redis版本中可能会有所变化,它是根据Redis内存分配策略和CPU缓存行大小等因素综合确定的。
三、原理详细解释
现在我们已经了解了Redis string的三种编码方式,让我们更深入地看看它们是如何工作的。
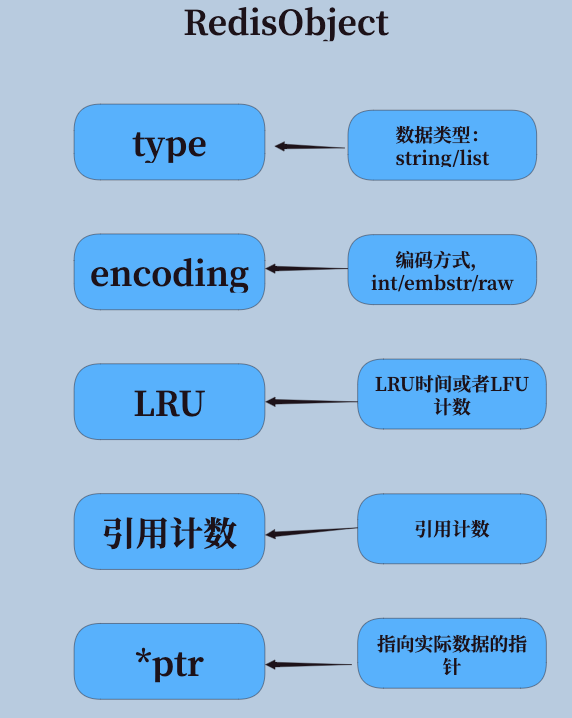
1. RedisObject结构
Redis中的所有数据都是以RedisObject的形式存储的。这个结构体包含了数据的类型、编码方式、实际数据指针等信息。
typedef struct redisObject {unsigned type:4; // 数据类型,如string/list等unsigned encoding:4; // 编码方式,如int/embstr/raw等unsigned lru:24; // LRU时间或LFU计数int refcount; // 引用计数void *ptr; // 指向实际数据的指针
} robj;
上述代码展示了RedisObject的结构定义。对于string类型,ptr字段会根据不同的编码方式存储不同的内容:
- int编码:ptr直接存储整数值
- embstr编码:ptr指向连续内存中的字符串部分
- raw编码:ptr指向独立的字符串内存
RedisObject和key的关系
- Key 是 RedisObject 的访问入口
- Redis 的 key 是一个字符串(如 “name”),它通过 全局哈希表(Key Space) 映射到对应的 RedisObject。
- 每个数据库(默认 16 个)都有一个独立的 Key Space,存储 key -> RedisObject 的映射关系。
- 当你执行 GET name 时,Redis 会:在 Key Space 中查找 “name” 对应的 RedisObject。
- 根据 RedisObject 的 type 和 encoding 解码出实际值。
- Key 本身也是 RedisObject
- 虽然 key 在逻辑上是一个字符串,但 Redis 内部同样会用 RedisObject 结构存储 key。不过 key 的 RedisObject 的 type 固定为 REDIS_STRING(即使 key 看起来像其他类型,如 “user:1000”)。
- 数据类型由 RedisObject 决定
- 当为 key 设置过期时间(如 EXPIRE name 60)时,Redis 会在过期字典中记录 key -> 过期时间,但实际数据仍通过 RedisObject 存储。
- 删除 key(如 DEL name)会释放对应的 RedisObject 内存。
2. 内存分配策略
Redis在内存分配上做了很多优化,特别是对于string类型。让我们看看不同编码的内存分配方式:
int编码: 不需要额外的内存分配,整数值直接存储在ptr中(利用指针的高位存储数据)。
embstr编码: 一次性分配连续内存,包含RedisObject和字符串数据。这种方式的优点是:
- 减少内存碎片
- 提高缓存局部性
- 减少内存分配次数
raw编码: 分两次分配内存,先分配RedisObject,再分配字符串数据。这种方式虽然分配次数多,但对于大字符串更灵活。
3. 编码转换
Redis string的编码不是一成不变的,在某些情况下会发生自动转换:
- 当对int编码的string执行APPEND操作时,会转换为raw编码
- 当对int编码的string存储的值超出long范围时,会转换为embstr或raw编码
- 当对embstr编码的string修改时,会转换为raw编码
SET num 100 // int编码
APPEND num "abc" // 转换为raw编码
OBJECT ENCODING num // 输出"raw"
上述代码展示了编码转换的过程。这种自动转换机制确保了数据始终以最合适的方式存储。
四、性能优化建议
了解了Redis string的底层原理后,我们可以根据这些知识来优化我们的使用方式:
- 尽量使用整数:对于计数器等场景,使用整数可以获得最佳性能
- 控制字符串长度:尽量将字符串控制在44字节以内,可以利用embstr编码的优势
- 避免频繁修改embstr:每次修改都会导致编码转换,影响性能
- 合理使用批量操作:如MSET/MGET可以减少网络往返时间
- 注意大字符串的内存占用:大字符串不仅占用内存多,还可能引发内存碎片
经验分享: 在实际项目中,我发现很多性能问题都源于不了解Redis的内部实现。比如有一个计数器场景,最初使用字符串存储数字,后来改为整数存储后,性能提升了近10倍。建议大家多了解底层原理,这样才能做出最优的设计决策。
五、总结
通过今天的探讨,我们对Redis string的底层实现有了深入的理解。Redis通过多种编码方式(int/embstr/raw)的灵活运用,在内存使用和性能之间取得了很好的平衡。
记住,了解这些底层原理不仅能帮助我们更好地使用Redis,还能在遇到性能问题时快速定位原因。就像了解汽车发动机原理的老司机,总能更好地驾驭自己的爱车。
本文目录总结:
- Redis string的执行流程:从命令接收到数据存储的完整过程
- Redis string的技术原理:三种编码方式(int/embstr/raw)及其适用场景
- 原理详细解释:RedisObject结构、内存分配策略和编码转换机制
- 性能优化建议:基于底层原理的实际应用技巧
希望通过这篇文章,大家对Redis string有了更深入的认识。在实际工作中遇到相关问题,不妨回想一下这些底层原理,可能会给你新的启发。
欢迎大家在评论区分享自己的Redis使用经验,我们一起学习,共同进步!



:容器存储接口 CSI)


