第一章:哨兵模式的核心原理
1.1 设计背景与价值
- 单点风险:单节点Redis宕机导致缓存层雪崩,引发业务级联故障
- 人工运维瓶颈:主从切换需手动干预,恢复时间长(平均>5分钟),服务不可接受
- 哨兵核心价值:
- 自动化监控:秒级节点健康探测
- 智能故障转移:主节点宕机后30秒内完成切换
- 无缝服务衔接:客户端自动感知新主节点
1.2 架构组成
| 角色 | 数量要求 | 核心职责 | 数据存储 |
| 哨兵节点(Sentinel) | ≥3(奇数台) | 监控、选举、故障决策 | 无 |
| 主节点(Master) | 1 | 写操作、数据同步 | 是 |
| 从节点(Slave) | ≥2 | 读分流、数据冗余、故障接管候选 | 是 |
1.3 工作机制深度解析
(1)三大定时任务
| 任务 | 频率 | 通信对象 | 核心作用 |
| INFO命令 | 10秒/次 | 主节点+所有从节点 | 发现从节点列表、主从状态同步 |
| 发布自身信息 | 2秒/次 | 主节点+从节点+其他哨兵 | 哨兵节点自动发现与拓扑构建 |
| PING命令 | 1秒/次 | 所有节点 | 健康检测(网络可达性) |
(2)故障判断机制
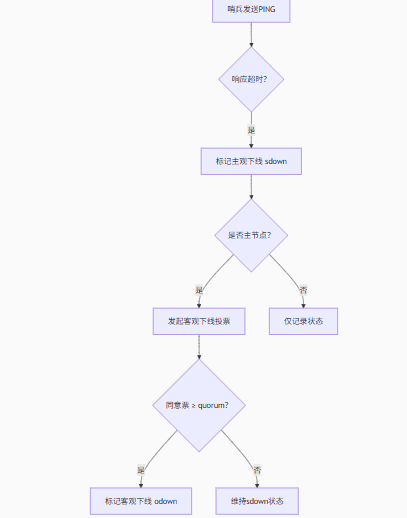
graph TDA[哨兵发送PING] --> B{响应超时?}B -->|是| C[标记主观下线 sdown]C --> D{是否主节点?}D -->|是| E[发起客观下线投票]D -->|否| F[仅记录状态]E --> G{同意票 ≥ quorum?}G -->|是| H[标记客观下线 odown]G -->|否| I[维持sdown状态]- 主观下线(SDOWN):单哨兵判定节点不可达(默认30秒超时)
- 客观下线(ODOWN):集群级故障共识(需quorum个哨兵确认)
- 关键公式:quorum≤哨兵总数/2 + 1 (例:3哨兵时quorum=2)
(3)Raft选举算法实现
# 伪代码:领导者选举流程
def elect_leader(sentinels):candidate = random.choice(sentinels) # 随机等待避免冲突votes = 1 # 自身默认投票for sentinel in sentinels:if sentinel != candidate and not sentinel.voted:sentinel.vote_for(candidate)votes += 1if votes > len(sentinels)/2 and votes >= quorum:return candidate # 成为领导者else:return None # 选举失败,随机延时后重试(4)故障转移四阶段
1. 从节点筛选(优先级排序):
- 健康状态>配置优先级>复制偏移量>RunID字典序
2. 角色切换
# 新主节点执行
redis-cli -h new_master slaveof no one
# 其他从节点指向新主
redis-cli -h slave01 slaveof new_master 6379 3. 旧主降级:故障恢复后自动成为新主节点的从节点
4. 配置纪元更新:epoch 值+1(保证配置版本全局唯一)
第二章:生产环境部署实战
2.1 环境规划
| 主机名 | IP | 角色 | 操作系统 |
| sentinel01 | 192.168.207.131 | 哨兵节点 | OpenEuler 24 |
| sentinel02 | 192.168.207.165 | 哨兵节点 | OpenEuler 24 |
| sentinel03 | 192.168.207.166 | 哨兵节点 | OpenEuler 24 |
| master | 192.168.207.167 | 主节点 | OpenEuler 24 |
| slave01 | 192.168.207.168 | 从节点 | OpenEuler 24 |
| slave02 | 192.168.207.169 | 从节点 | OpenEuler 24 |
2.2 基础环境配置
# 所有节点执行
systemctl stop firewalld && systemctl disable firewalld
setenforce 0
sed -i "s/SELINUX=.*/SELINUX=disabled/g" /etc/selinux/config
hostnamectl set-hostname <对应主机名>2.3 Redis主从群集部署
(1)编译安装Redis 6.2.4
yum -y install gcc gcc-c++ make
tar -zxvf redis-6.2.4.tar.gz -C /usr/src/
cd /usr/src/redis-6.2.4/
make && make PREFIX=/usr/local/redis install
ln -s /usr/local/redis/bin/* /usr/local/bin/(2)主节点关键配置(/etc/redis/6379.conf)
bind 127.0.0.1 192.168.207.167 # 监听内网IP
daemonize yes
logfile "/var/log/redis_6379.log"(3)从节点配置
replicaof 192.168.207.167 6379 # 指向主节点(4)服务验证
# 主节点执行
redis-cli info replication
# 输出应包含:
# role:master
# connected_slaves:22.4 哨兵集群部署
(1)哨兵节点配置(/etc/redis/6379.conf)
sentinel monitor mymaster 192.168.207.167 6379 2 # quorum=2
bind 0.0.0.0 # 允许所有IP访问
daemonize yes(2)Systemd服务脚本
[Service]
ExecStart=/usr/local/bin/redis-sentinel /etc/redis/6379.conf(3)启动与状态验证
systemctl start redis
redis-cli info sentinel
# 输出示例:
# master0:name=mymaster,status=ok,address=192.168.207.167:6379,slaves=2,sentinels=3第三章:故障转移全流程实验
3.1 模拟主节点故障
# 在master节点执行
systemctl stop redis3.2 哨兵日志分析
# sentinel01日志
+sdown master mymaster 192.168.207.167 6379 # 主观下线
+odown master mymaster #quorum 2/2 # 客观下线
+new-epoch 12 # 新配置纪元
+vote-for-leader sentinel02 12 # 选举领导者
+elected-leader master mymaster # 领导者当选
+failover-state-select-slave master mymaster # 选择新主节点
+selected-slave slave 192.168.207.169:6379 # 选中slave02
+failover-state-reconf-slaves master mymaster # 重配置从节点
+switch-master mymaster 192.168.207.167 192.168.207.169 # 主切换完成3.3 新拓扑验证
redis-cli -h sentinel01 info sentinel
# 输出:
# master0:name=mymaster,status=ok,address=192.168.207.169:6379...3.4 原主节点恢复
systemctl start redis # 原master节点自动成为新主的从节点
redis-cli info replication
# 输出:
# role:slave
# master_host:192.168.207.169第四章:进阶调优与故障排查
4.1 关键参数优化
| 参数 | 默认值 | 生产建议 | 作用 |
| down-after-milliseconds | 30000 | 20000-50000 | 主观下线判定阈值 |
| parallel-syncs | 1 | 2-5 | 新主同时同步的从节点数 |
| failover-timeout | 180000 | 120000-300000 | 故障转移超时时间 |
4.2 典型故障场景
1.脑裂问题:
- 现象:双主节点同时写入
- 决定方案
min-slaves-to-write 1 # 至少1个从节点同步
min-slaves-max-lag 10 # 同步延迟≤10秒2. 哨兵节点GC堵塞:
- 监控指标:sentinel_running_scripts>0 持续超30秒
- 优化方案:升级至Rdis 7.0+ (优化Lua引擎)
4.3 监控指标集
# Prometheus监控模板
redis_sentinel_known_sentinels{master="mymaster"} 3
redis_sentinel_ok_slaves{master="mymaster"} 2
redis_sentinel_master_status{master="mymaster"} 1 # 1=OK, 0=FAIL第五章:架构局限性与发展
5.1 哨兵模式短板
- 数据分片缺失:单主节点写性能瓶颈(10W QPS)
- 跨机房容灾弱:RTT延迟影响仲裁效率
- 配置管理分散:需人工维护sentinel.conf
5.2 演进方向
1. Redis Cluster:
-
自动分片(16384 slots)
-
多主多写架构
2.Proxy方案
-
Twemproxy:静态分片
-
Codis:动态扩缩容
3. 云托管服务
-
AWS ElastiCache
-
阿里云ApsaraDB for Redis




