selenium学习实战【Python爬虫】

文章目录
- selenium学习实战【Python爬虫】
- 一、声明
- 二、学习目标
- 三、安装依赖
- 3.1 安装selenium库
- 3.2 安装浏览器驱动
- 3.2.1 查看Edge版本
- 3.2.2 驱动安装
- 四、代码讲解
- 4.1 配置浏览器
- 4.2 加载更多
- 4.3 寻找内容
- 4.4 完整代码
- 五、报告文件爬取
- 5.1 提取下载链接
- 5.2 下载报告
- 六、总结
一、声明
本爬虫项目仅用于学习用途。严禁将本项目用于任何非法目的,包括但不限于恶意攻击网站、窃取用户隐私数据、破坏网站正常运营、商业侵权等行为。
二、学习目标
1.爬取网站链接:https://report.iresearch.cn;
2.爬取不付费的报告信息,标题、行业、作者、摘要和报告原件;
三、安装依赖
3.1 安装selenium库
只介绍主要的,别的库百度自行安装。
打开vscode终端,运行下面命令:
pip install -i https://pypi.douban.com/simple selenium
3.2 安装浏览器驱动
针对不同的浏览器,需要安装不同的驱动。下面列举了常见的浏览器与对应的驱动程序下载链接,部分网址需要 “科学上网” 才能打开哦(dddd)。
Firefox 浏览器驱动:https://github.com/mozilla/geckodriver/releases
Chrome 浏览器驱动:https://chromedriver.storage.googleapis.com/index.html
IE 浏览器驱动:http://selenium-release.storage.googleapis.com/index.html
Edge 浏览器驱动:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
PhantomJS 浏览器驱动:https://phantomjs.org/
Opera 浏览器驱动:https://github.com/operasoftware/operachromiumdriver/releases
我用的时Edge浏览器,所以安装Edge驱动
3.2.1 查看Edge版本
点击三个点,再点击设置
点击左侧最下面关于Edge
3.2.2 驱动安装
下载好双击安装就行。
四、代码讲解
4.1 配置浏览器
# 创建 EdgeOptions 对象,用于配置浏览器选项
edge_options = Options()
# 添加参数忽略证书错误
edge_options.add_argument('--ignore-certificate-errors')
# 添加参数禁用扩展
edge_options.add_argument('--disable-extensions')
# 添加参数禁用沙盒模式
edge_options.add_argument('--no-sandbox')
# 添加参数禁用 GPU 加速
edge_options.add_argument('--disable-gpu')# 创建 Edge 浏览器驱动实例
driver = webdriver.Edge(options=edge_options)
4.2 加载更多
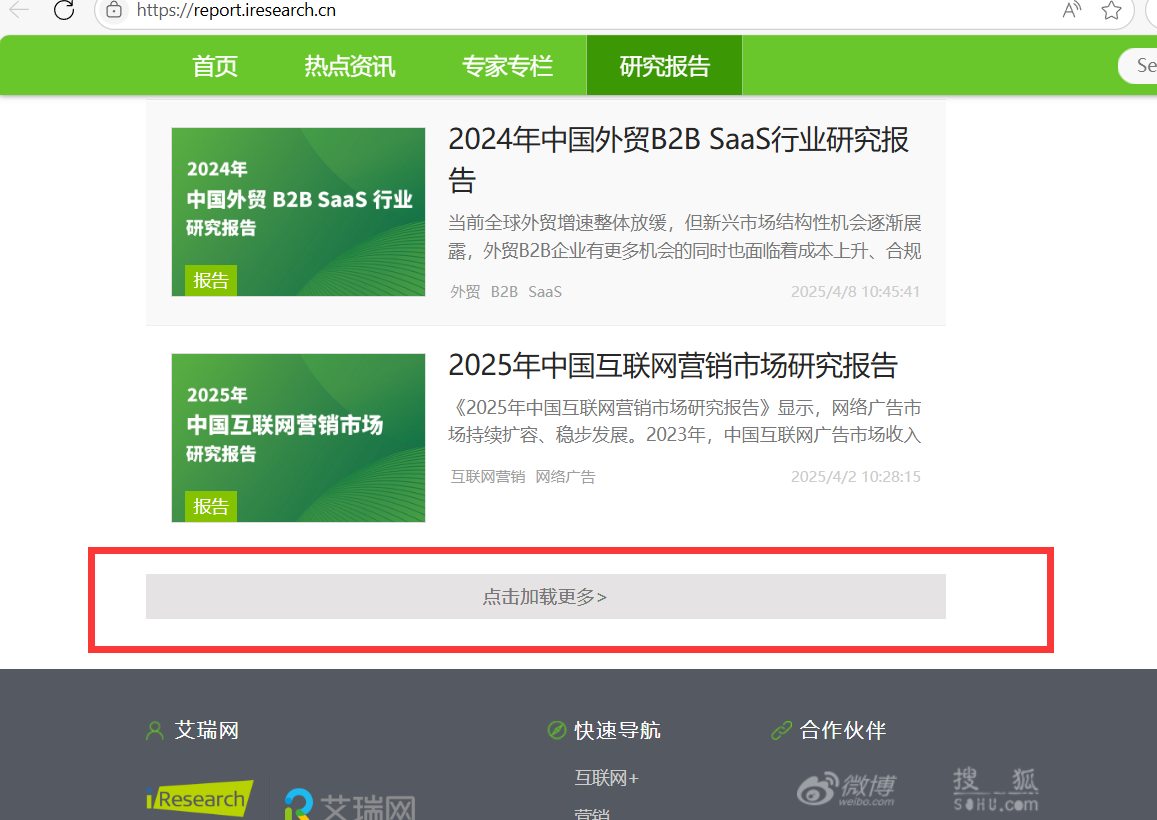
打开艾瑞网的报告页面,我们会发现加载更多这个按钮,我们可以用代码点击按钮加载,直到自己需要的数量,我这里设置加载10次
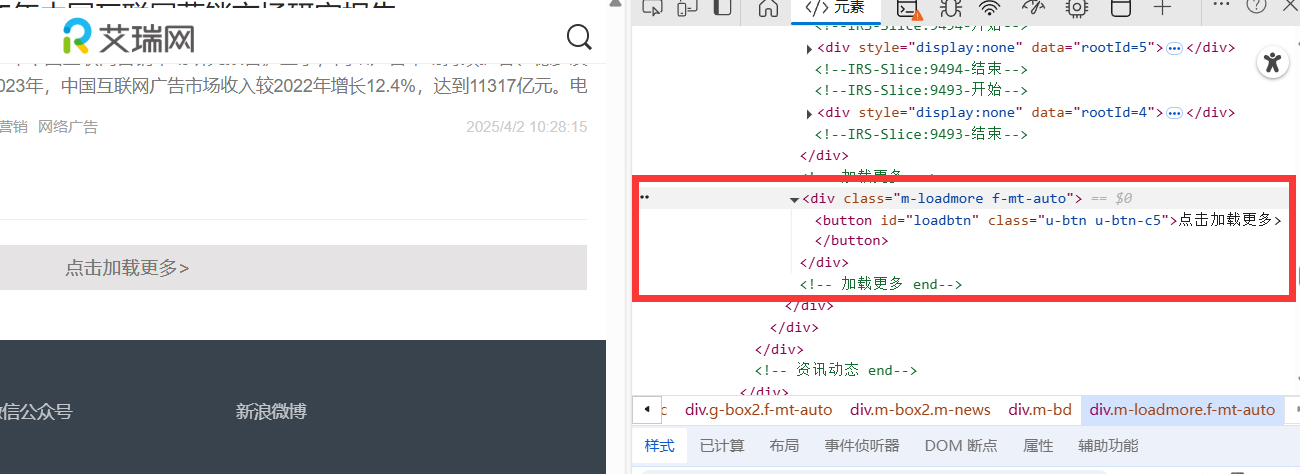
鼠标右键点击页面–>点击检查,加载更多按钮定义在这里
# 打开指定 URL 的网页
driver.get(url)try:# 用于保存找到的元素信息found_elements_info = []found_links = []wait = WebDriverWait(driver, 10)# 1. 点击"加载更多"按钮10次load_count = 0while load_count < 10:try:# 定位"加载更多"按钮load_more_btn = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'button#loadbtn') # 根据实际页面调整选择器))# 点击按钮load_more_btn.click()load_count += 1print(f"已点击加载更多 {load_count}/10 次")# 等待新内容加载(根据页面加载速度调整)time.sleep(2)except Exception as e:print(f"点击加载更多失败: {e}")break# 2. 等待所有内容加载完成print("等待内容加载完成...")time.sleep(3) # 额外等待确保所有内容加载完成
4.3 寻找内容
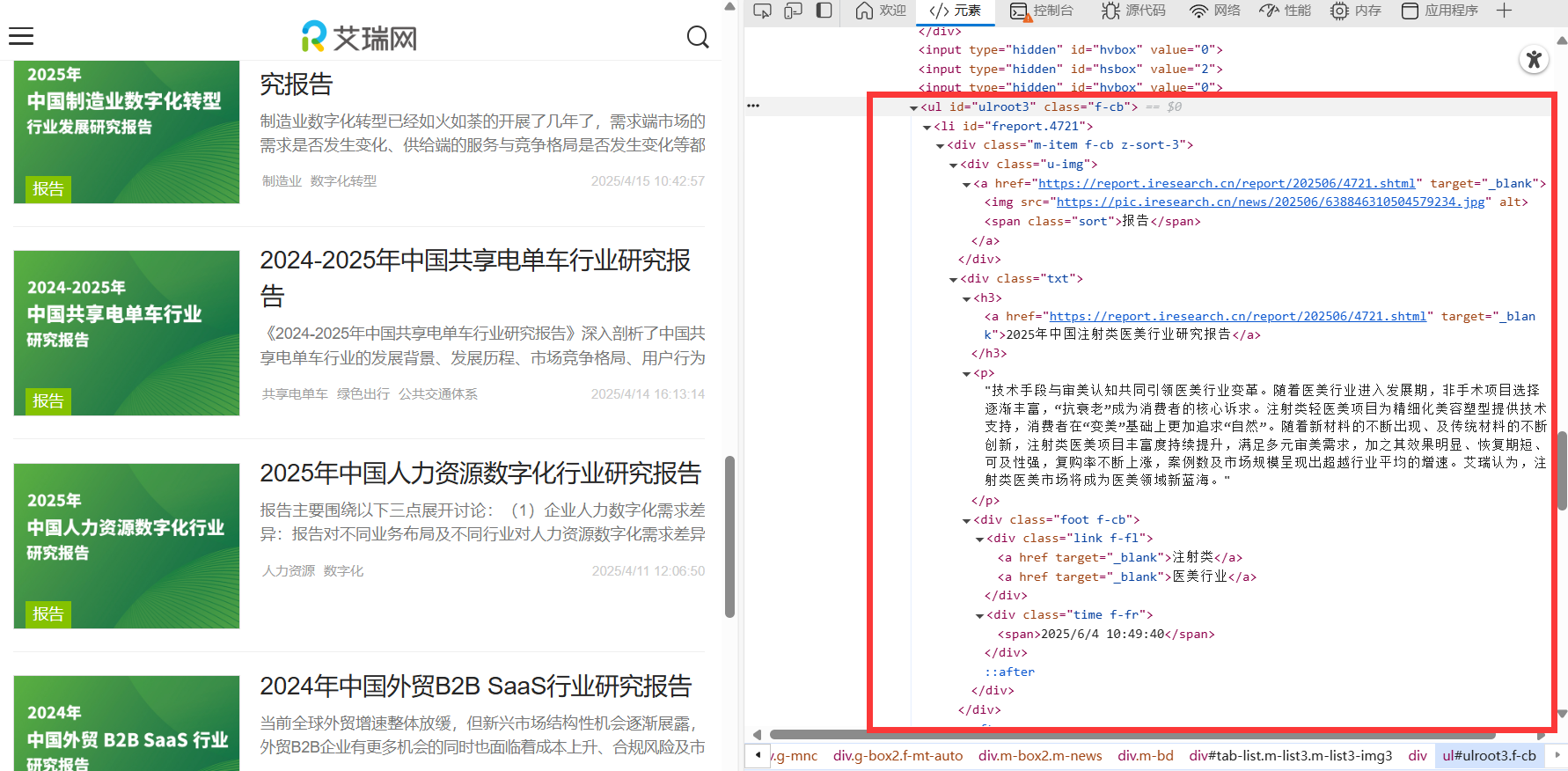
4.4 完整代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pandas as pd# 创建 EdgeOptions 对象,用于配置浏览器选项
edge_options = Options()
edge_options.add_argument('--ignore-certificate-errors')
edge_options.add_argument('--disable-extensions')
edge_options.add_argument('--no-sandbox')
edge_options.add_argument('--disable-gpu')# 创建 Edge 浏览器驱动实例
driver = webdriver.Edge(options=edge_options)url = 'https://report.iresearch.cn/'# 打开指定 URL 的网页
driver.get(url)try:data_list = [] # 用于保存字典数据wait = WebDriverWait(driver, 10)load_count = 0# 点击"加载更多"按钮10次while load_count < 11:try:load_more_btn = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'button#loadbtn')))load_more_btn.click()load_count += 1print(f"已点击加载更多 {load_count}/10 次")time.sleep(2)except Exception as e:print(f"点击加载更多失败: {e}")breakprint("等待内容加载完成...")time.sleep(3)# 定位所有目标元素elements = driver.find_elements(By.CSS_SELECTOR, 'li[id^="freport."]')print(f"共找到 {len(elements)} 个元素")found_links = []if elements:for elem in elements:try:# 提取元素信息title = elem.find_element(By.CSS_SELECTOR, 'h3').text.strip() # 标题link = elem.find_element(By.CSS_SELECTOR, 'a').get_attribute('href') # 链接desc = elem.find_element(By.CSS_SELECTOR, 'p').text.strip() if elem.find_elements(By.CSS_SELECTOR, 'p') else "" # 摘要tags = [tag.text for tag in elem.find_elements(By.CSS_SELECTOR, '.link a')] # 标签timestamp = elem.find_element(By.CSS_SELECTOR, '.time span').text.strip() # 时间戳found_links.append(link)# 构建字典data_dict = {"标题": title,"链接": link,"描述": desc,"标签": ", ".join(tags),"时间": timestamp}data_list.append(data_dict)print(f"找到元素:{title[:30]}...") except Exception as e:print(f"处理元素失败: {e}")continue# 将找到的链接信息保存到文件with open('found_links.txt', 'w', encoding='utf-8') as f:for link in found_links:f.write(link + '\n')print("已将找到的链接信息保存到 found_links.txt")# 将列表转换为DataFramedf = pd.DataFrame(data_list)# 保存为CSV文件(也可改为Excel等其他格式)df.to_csv('iresearch_reports.csv', encoding='utf-8-sig', index=False)print(f"\n成功保存 {len(data_list)} 条数据到 iresearch_reports.csv")# 打印DataFrame前5行(可选)print("\n数据预览:")print(df.head())else:print("未找到符合条件的元素。")except Exception as e:print("定位元素失败:", e)with open('page_source.html', 'w', encoding='utf-8') as f:f.write(driver.page_source)print("已保存页面源代码到 page_source.html")finally:time.sleep(2)driver.quit()
运行后我们得到两个文件,报告链接文件和报告信息
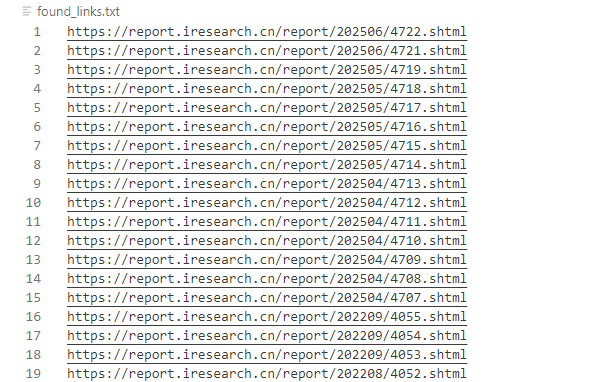
内容格式如下:

五、报告文件爬取
通过前面的学习,我们已经得到了链接文件,从中提取出我们需要的下载链接,然后通过爬虫去遍历这些链接,下载报告原件
5.1 提取下载链接
import re# 读取文件内容
with open('found_links.txt', 'r', encoding='utf-8') as f:links = f.readlines()# 定义正则表达式
pattern = re.compile(r'https?://[^/]+/report/.+?/(\d+)\.shtml')# 提取数字ID
extracted_ids = []
for link in links:link = link.strip() # 去除换行符match = pattern.search(link)if match:extracted_ids.append(match.group(1)) # 取第一个捕获组else:print(f"未匹配到ID:{link}")# 输出结果
print("提取的数字ID列表:")
print(extracted_ids)link_template = 'https://report.iresearch.cn/include/ajax/user_ajax.ashx?reportid={}&work=rdown&url=https%3A%2F%2Freport.iresearch.cn%2Freport%2F202505%2F{}.shtml'# 生成替换后的链接列表
new_links = []
for report_id in extracted_ids:new_link = link_template.format(report_id, report_id)new_links.append(new_link)print(f"生成链接: {new_link}")# 保存结果到文件
with open('generated_links.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(new_links))
print("已保存生成的链接到 generated_links.txt")

5.2 下载报告
下载报告需要登录,cookie值的设置绕过登录操作
from selenium import webdriver
from selenium.webdriver.edge.options import Options
import random
import time# 创建 EdgeOptions 对象,用于配置浏览器选项
edge_options = Options()
# 添加参数忽略证书错误
edge_options.add_argument('--ignore-certificate-errors')
# 添加参数禁用扩展
edge_options.add_argument('--disable-extensions')
# 添加参数禁用沙盒模式
edge_options.add_argument('--no-sandbox')
# 添加参数禁用 GPU 加速
edge_options.add_argument('--disable-gpu')# 创建 Edge 浏览器驱动实例
driver = webdriver.Edge(options=edge_options)# 先访问站点基础页面(比如首页),让浏览器先有站点的基础上下文,再设置 Cookie 更有效
driver.get('https://report.iresearch.cn/') # 替换为实际站点域名# 逐个设置关键 Cookie
cookies = [{'name': 'iRsUserType', 'value': '49'},{'name': 'iRsUserPhoto', 'value': ''}, # 替换为完整真实值{'name': 'iRsUserPassword', 'value': ''},{'name': 'iRsUserNick', 'value': ''}, # 补全真实值{'name': 'iRsUserRName', 'value': ''},{'name': 'iRsUserId', 'value': ''},{'name': 'iRsUserGroup', 'value': '48'},{'name': 'iRsUserDate', 'value': ''},{'name': 'iRsUserAccount', 'value': ''},{'name': 'Hm_lvt_c33e4c1e69eca76a2e522c20e59773f6', 'value': '‘},{'name': 'Hm_lpvt_c33e4c1e69eca76a2e522c20e59773f6', 'value': ''},{'name': 'HMACCOUNT', 'value': ''},
]for cookie in cookies:try:driver.add_cookie(cookie)except Exception as e:print(f"设置 Cookie {cookie['name']} 失败:{e}")# 重新加载页面,让设置的 Cookie 生效,尝试绕过登录
driver.refresh()
time.sleep(3) # 等待页面加载# 读取文件中的链接(假设链接文件为当前目录下的generated_links.txt)
def read_links():with open("generated_links.txt", "r", encoding="utf-8") as f:links = [line.strip() for line in f if line.strip()]return list(set(links)) # 去重处理# 模拟浏览器遍历链接
def browse_links(links):try:for idx, link in enumerate(links, 1):try:driver.get(link)print(f"{idx}/{len(links)}正在访问:{link}")# 模拟真实用户行为time.sleep(random.uniform(3, 7)) # 随机停留3-7秒scroll_height = driver.execute_script("return document.body.scrollHeight")driver.execute_script(f"window.scrollTo(0, {random.randint(0, scroll_height)})") # 随机滚动# 偶尔模拟刷新(增加随机性)if random.random() < 0.2:driver.refresh()time.sleep(2)except Exception as e:print(f"访问失败:{link} | 错误:{str(e)[:50]}...")continue # 跳过当前链接finally:time.sleep(2)driver.quit()print("\n所有链接遍历完成!")# 主程序入口
if __name__ == "__main__":links = read_links()if links:print(f"检测到 {len(links)} 个链接,开始遍历...")browse_links(links)else:print("未找到有效链接")
六、总结
基本完成了任务目标,但是并没有进行模块化处理。


》逐章精华笔记第五章)
)


