在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数估计产生显著偏差。本文通过实证研究,系统比较了MSE损失函数和Cauchy损失函数在线性回归中的表现,重点分析了两种损失函数在噪声数据环境下的差异。研究结果表明,Cauchy损失函数通过其对数惩罚机制有效降低了异常值的影响,在处理含噪声数据时展现出更强的稳定性。
理论基础
均方误差(MSE)损失函数
均方误差损失函数是回归问题中最为常用的损失函数,其数学定义为:
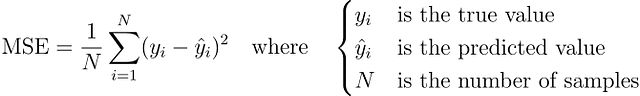
MSE损失函数的优势在于其良好的数学性质。首先,MSE函数处处可微,便于使用基于梯度的优化算法进行参数更新。其次,平方项的引入确保了较大误差获得相应的高权重,驱动模型向更高精度的方向优化。此外,MSE损失函数具有凸函数性质,保证了优化过程能够收敛到全局最优解。
然而,MSE损失函数的主要局限性在于其对异常值的高度敏感性。由于采用二次惩罚机制,远离回归线的数据点会产生较大的平方误差,从而在损失函数中占据主导地位。这种特性使得模型参数估计容易被异常值所"拖拽",偏离真实的数据分布特征,特别是在处理包含噪声或异常值的实际数据时表现尤为明显。
Cauchy损失函数
Cauchy损失函数属于鲁棒性损失函数家族,其设计目标是降低模型对异常值的敏感性。该损失函数基于Cauchy分布(也称为Lorentz分布)的概率密度函数,其数学表达式为:

其中,δ为尺度参数,控制损失函数的形状和对异常值的容忍度。
Cauchy损失函数的核心优势在于其对数惩罚机制。与MSE的二次增长不同,Cauchy损失函数在残差增大时呈现对数增长特性,这意味着大残差虽然仍会受到惩罚,但其影响程度相对有限。这种特性使得模型在面对异常值时能够保持相对稳定的参数估计,避免被极端值过度影响。
参数δ的选择对Cauchy损失函数的性能具有重要影响。较小的δ值使得损失函数对残差变化更为敏感,而较大的δ值则增强了模型对异常值的容忍度。在实际应用中,δ值通常需要根据数据特性和问题需求进行调整。
实验设计与实现
本节详细介绍了MSE和Cauchy损失函数在线性回归中的实现过程。所有实验均在Google Colab环境中执行,为交互式编程和结果可视化提供了便利的平台。
实验环境配置
实验开始前,需要导入必要的Python库以支持数值计算、优化求解和数据可视化功能:
importnumpyasnp importmatplotlib.pyplotasplt fromscipy.optimizeimportminimize fromabcimportABC, abstractmethod fromsklearn.metricsimportmean_squared_error, mean_absolute_error
各库的具体功能如下:numpy作为Python科学计算的基础库,负责数组操作、数值计算和合成数据生成;matplotlib.pyplot提供数据可视化功能,用于绘制数据分布、回归拟合结果和损失函数曲面;scipy.optimize.minimize实现数值优化功能,支持多种优化算法的参数估计;abc模块提供抽象基类功能,用于构建统一的回归模型接口;sklearn.metrics提供标准化的模型评估指标。
噪声数据生成器设计
为了系统评估不同损失函数的性能,设计了一个综合的数据生成器,能够模拟包含高斯噪声和异常值的线性关系数据:
classDataGenerator: def__init__(self, n_samples=100, noise_std=1.0, outlier_fraction=0.1, outlier_magnitude=20.0, seed=None): self.n_samples=n_samples self.noise_std=noise_std self.outlier_fraction=outlier_fraction self.outlier_magnitude=outlier_magnitude self.seed=seed # 随机种子,用于可复现性self.X=None self.y=None self.true_a=None # 真实的 a 值self.true_b=None # 真实的 b 值defgenerate_data(self, a=2.0, b=5.0): ifself.seedisnotNone: np.random.seed(self.seed) self.true_a=a self.true_b=b self.X=np.random.uniform(-10, 10, self.n_samples) # 在 [-10, 10] 范围内生成 Xnoise=np.random.normal(0, self.noise_std, self.n_samples) # 生成高斯噪声self.y=a*self.X+b+noise # 根据线性模型 y = aX + b + noise 计算 yreturnself.X, self.y defadd_outliers(self): n_outliers=int(self.n_samples*self.outlier_fraction) # 计算异常点数量indices=np.random.choice(self.n_samples, size=n_outliers, replace=False) # 随机选择异常点索引self.y[indices] +=np.random.choice([-1, 1], size=n_outliers) *self.outlier_magnitude # 添加异常值returnindices # 返回异常点的索引,用于可视化defplot_data(self, outlier_indices=None): plt.figure(figsize=(8, 5)) plt.scatter(self.X, self.y, label="Data", alpha=0.7) # 绘制数据点ifoutlier_indicesisnotNone: plt.scatter(self.X[outlier_indices], self.y[outlier_indices], color="red", label="Outliers", s=80, edgecolors='black') # 标记异常点plt.title("Generated Data with Outliers") plt.xlabel("X") plt.ylabel("y") plt.grid(True) plt.legend() plt.tight_layout() plt.show()
DataGenerator类采用模块化设计,支持灵活的参数配置。初始化方法定义了样本数量、噪声标准差、异常值比例、异常值幅度以及随机种子等关键参数。generate_data方法在指定范围内生成均匀分布的输入变量X,并根据预设的线性关系y = aX + b添加高斯噪声生成目标变量y。add_outliers方法通过随机选择部分数据点并施加大幅度扰动来模拟异常值,为评估模型鲁棒性提供了可控的测试环境。plot_data方法实现数据可视化,异常值通过红色标记进行突出显示。
合成数据集构建
基于DataGenerator类,构建包含噪声和异常值的合成数据集:
generator=DataGenerator( n_samples=100, noise_std=2, outlier_fraction=0.1, outlier_magnitude=25, seed=42
) X, y=generator.generate_data(a=2.5, b=1.0)
outlier_indices=generator.add_outliers() generator.plot_data(outlier_indices)
数据集配置参数经过精心设计:样本总数设为100,在保证统计意义的同时保持计算效率;高斯噪声标准差设为2.0,模拟实际测量中的随机误差;异常值比例设为10%,符合实际数据中异常值的典型分布;异常值幅度设为±25,确保异常值与正常数据点存在显著差异。潜在的线性关系定义为y = 2.5x + 1.0,为后续的参数估计提供了明确的基准。
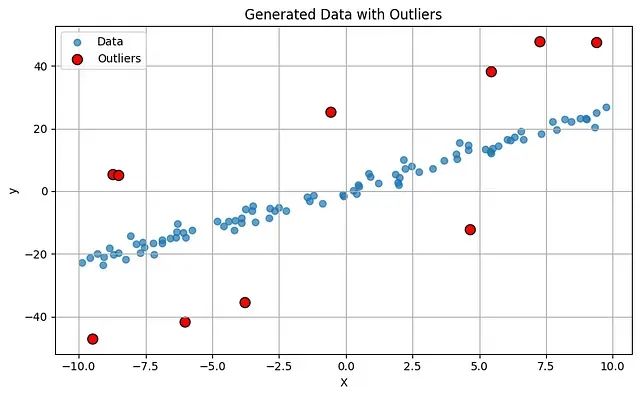
生成的数据可视化结果清晰展示了数据的结构特征:大部分数据点呈现明显的线性趋势,而少数红色标记的异常值显著偏离主要分布,为评估不同损失函数的鲁棒性提供了理想的测试环境。
回归模型框架设计
为了便于不同损失函数的实现和比较,设计了基于抽象基类的回归模型框架:
classBaseRegressor(ABC): def__init__(self): self.coef_=None # [a, b] → y = ax + b 回归系数@abstractmethod defloss_function(self, params, X, y): # 抽象损失函数pass deffit(self, X, y, initial_guess=[1.0, 0.0]): # 拟合方法X=np.array(X) y=np.array(y) ifX.ndim==1: X=X.reshape(-1) result=minimize( fun=self.loss_function, # 目标函数x0=initial_guess, # 初始猜测值args=(X, y), # 传递给目标函数的额外参数method='L-BFGS-B' # 优化算法) self.coef_=result.x # 存储优化后的系数returnself defpredict(self, X): # 预测方法a, b=self.coef_ returna*X+b
BaseRegressor抽象基类为不同损失函数的回归模型提供了统一的接口。该类定义了loss_function抽象方法,强制子类实现特定的损失函数计算逻辑。fit方法采用SciPy的minimize函数实现参数优化,使用L-BFGS-B算法求解线性回归方程y = ax + b中的斜率a和截距b。predict方法基于训练得到的参数进行预测计算。这种设计模式确保了不同损失函数实现之间的一致性和可比性。
MSE回归器实现
基于BaseRegressor框架,实现使用均方误差损失的回归模型:
classMSERegressor(BaseRegressor): defloss_function(self, params, X, y): a, b=params y_pred=a*X+b returnnp.mean((y-y_pred) **2) # 计算均方误差
MSERegressor类继承自BaseRegressor并实现了loss_function抽象方法。该方法根据当前参数计算预测值,然后计算真实值与预测值之间平方误差的均值,体现了MSE损失函数的核心特征。
Cauchy回归器实现
为了解决MSE对异常值敏感的问题,实现基于Cauchy损失的鲁棒回归模型:
classCauchyRegressor(BaseRegressor): def__init__(self, delta=1.0): super().__init__() self.delta=delta # 柯西损失的参数 deltadefloss_function(self, params, X, y): a, b=params y_pred=a*X+b residual=y-y_pred # 计算残差delta=self.delta returnnp.mean(delta**2*np.log(1+ (residual/delta)**2)) # 计算柯西损失
CauchyRegressor类在BaseRegressor基础上引入了尺度参数delta,该参数控制Cauchy损失函数对大残差的敏感程度。损失函数实现遵循Cauchy分布的数学形式,通过对数变换实现对异常值的鲁棒性处理。较小的delta值增强对残差变化的敏感性,而较大的delta值则提升对异常值的容忍度。
实验结果与分析
MSE回归器训练结果
使用合成数据集对MSE回归器进行训练:
mse_model=MSERegressor() mse_model.fit(X, y) y_pred_mse=mse_model.predict(X) print("coefficient:", mse_model.coef_)
训练完成后,MSE回归器的参数估计结果为:斜率a ≈ 2.5976,截距b ≈ 1.5560。
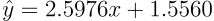
对比真实参数(a=2.5, b=1.0),可以观察到MSE模型的参数估计存在一定偏差,特别是截距b的估计偏差较为明显。这种偏差主要源于异常值对MSE损失函数的显著影响,异常值的大残差被二次放大,导致模型参数向异常值方向偏移。
Cauchy回归器训练结果
使用相同数据集对Cauchy回归器进行训练:
cauchy_model=CauchyRegressor(delta=1.0) cauchy_model.fit(X, y) y_pred_cauchy=cauchy_model.predict(X) print("coefficient:", cauchy_model.coef_)
Cauchy回归器的参数估计结果为:斜率a ≈ 2.4411,截距b ≈ 1.0254。
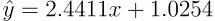
相比MSE回归器,Cauchy回归器的参数估计更接近真实值,特别是截距b的估计精度显著提升。这一结果验证了Cauchy损失函数在抑制异常值影响方面的有效性,通过其对数惩罚机制成功降低了异常值对参数估计的干扰。
回归拟合效果比较
为了直观比较两种回归方法的拟合效果,将MSE和Cauchy回归线与原始数据同时展示:
plt.figure(figsize=(8,5))
plt.scatter(X, y, label='Data', alpha=0.5) # 绘制原始数据点
plt.plot(X, y_pred_mse, color='blue', label='MSE Fit', linewidth=2) # 绘制 MSE 拟合线
plt.plot(X, y_pred_cauchy, color='green', label='Cauchy Fit', linewidth=2) # 绘制柯西拟合线
plt.title("MSE vs Cauchy")
plt.xlabel("X")
plt.ylabel("y")
plt.legend()
plt.grid(True)
plt.tight_layout() plt.show()
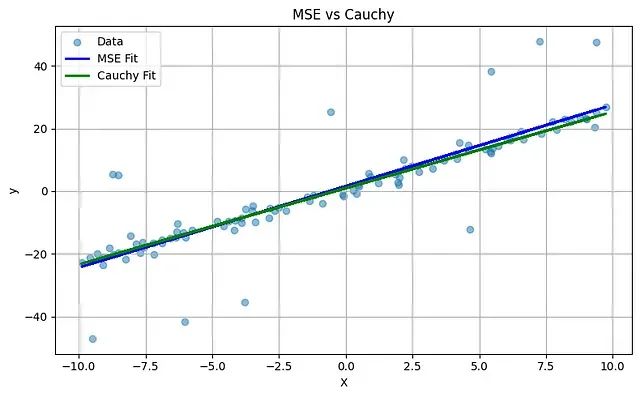
可视化结果清晰展现了两种方法的差异:MSE回归线(蓝色)明显受到异常值的影响,其走向被拉向极端数据点,偏离了数据的主要线性趋势。相比之下,Cauchy回归线(绿色)表现出更强的稳定性,能够更好地捕捉数据的核心分布特征,有效抵抗异常值的干扰。这种差异体现了Cauchy损失函数在处理含噪声数据时的优越性。
损失函数曲面分析
为了深入理解两种损失函数的优化特性,构建参数空间内的损失曲面可视化:
defplot_loss_surface(X, y, model_class, name="Loss Surface", delta=1.0, a_range=(-1, 6), b_range=(-5, 5), steps=100): a_vals=np.linspace(*a_range, steps) # a 值的范围b_vals=np.linspace(*b_range, steps) # b 值的范围A, B=np.meshgrid(a_vals, b_vals) # 创建网格Loss=np.zeros_like(A) # 初始化损失矩阵foriinrange(steps): forjinrange(steps): a=A[i, j] b=B[i, j] # 根据模型类型实例化模型model=model_class(delta=delta) ifmodel_class==CauchyRegressorelsemodel_class() loss=model.loss_function([a, b], X, y) # 计算损失Loss[i, j] =loss fig=plt.figure(figsize=(10, 6)) ax=fig.add_subplot(111, projection='3d') # 创建 3D 子图ax.plot_surface(A, B, Loss, cmap='viridis', alpha=0.9, edgecolor='none') # 绘制损失曲面ax.set_xlabel('a (slope)') # 设置 x 轴标签 (斜率)ax.set_ylabel('b (intercept)') # 设置 y 轴标签 (截距)ax.set_zlabel('Loss') # 设置 z 轴标签 (损失)ax.set_title(name) # 设置标题plt.tight_layout() plt.show()plot_loss_surface(X, y, MSERegressor, name="MSE Loss Surface", a_range=(1, 4), b_range=(-1, 3))plot_loss_surface(X, y, CauchyRegressor, name="Cauchy Loss Surface", delta=1.0, a_range=(1, 4), b_range=(-1, 3))
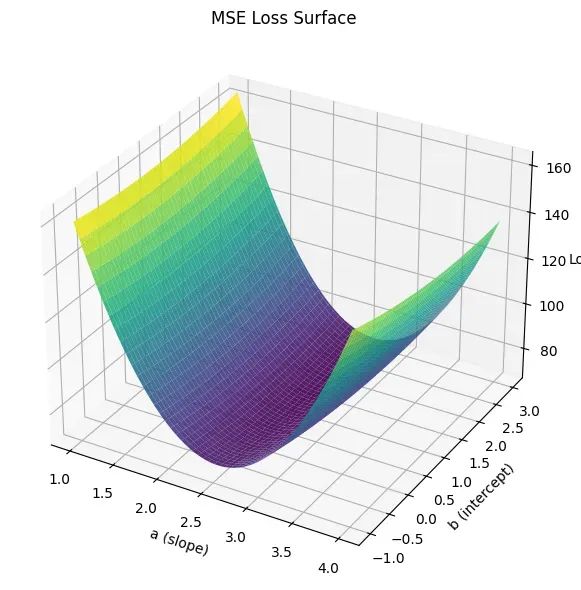
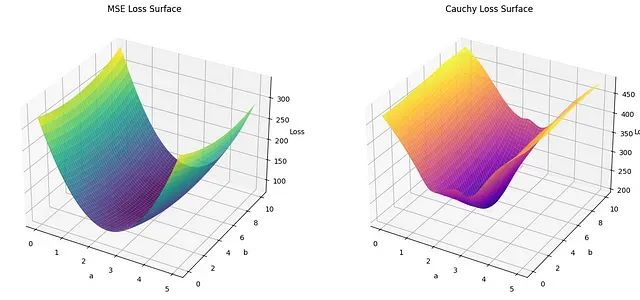
MSE损失曲面呈现典型的凸函数特征,具有明确的碗状结构和唯一的全局最小值。这种几何特性使其易于优化,但同时也使得损失函数对异常值高度敏感。异常值产生的大残差会显著改变曲面形状,将最小值位置从理想位置偏移。

相比之下,Cauchy损失曲面在最优解附近表现出更加平缓的特征,整体梯度变化相对温和。这种特性是Cauchy损失函数对大残差相对不敏感的直接体现。函数不会因为异常值的存在而产生急剧的损失增长,而是呈现出逐渐饱和的趋势,从而在参数空间中形成更宽的低损失区域。这种特性使得优化过程对参数初值的依赖性降低,同时提升了对噪声数据的鲁棒性。
总结讨论
本研究通过系统的实证分析,揭示了MSE和Cauchy损失函数在处理含噪声数据时的本质差异。实验结果表明,MSE损失函数虽然在数学性质上具有优势,如凸性和可微性,但其对异常值的高度敏感性在实际应用中构成了显著限制。当数据集包含异常值时,MSE的二次惩罚机制会放大这些极端值的影响,导致参数估计产生系统性偏差。
Cauchy损失函数通过引入对数惩罚机制,有效缓解了这一问题。其损失函数在残差增大时表现出饱和特性,避免了异常值对整体拟合过程的过度干扰。实验结果显示,在相同的噪声环境下,Cauchy回归器的参数估计精度明显优于MSE回归器,特别是在截距参数的估计上表现尤为突出。
实际应用意义
这些发现对实际机器学习项目具有重要的指导意义。在现实世界的数据科学项目中,数据质量往往不够理想,异常值和噪声的存在是常态而非例外。传统的MSE损失函数可能不是最优选择,特别是在数据清洗资源有限或异常值具有实际意义的场景下。
Cauchy损失函数为这类问题提供了一个有效的解决方案。它不仅能够维持较好的拟合精度,还能显著提升模型的鲁棒性。这种特性在金融数据分析、传感器数据处理、医疗诊断等对异常值敏感的应用领域中具有特别重要的价值。
方法选择建议
基于本研究的结果,我们建议在选择损失函数时考虑以下因素:
当数据质量较高、异常值较少时,MSE损失函数仍然是优秀的选择,其优化特性和计算效率优势明显。然而,当数据存在明显的异常值或噪声污染时,Cauchy损失函数能够提供更加稳定和可靠的结果。
此外,Cauchy损失函数中的尺度参数δ需要根据具体问题进行调优。较小的δ值适用于对精度要求较高的场景,而较大的δ值则适用于异常值较多的鲁棒性要求较高的场景。
研究局限性与未来工作
本研究主要集中在一维线性回归问题上,未来的工作可以扩展到多维回归和非线性问题。此外,还可以探索其他鲁棒性损失函数,如Huber损失、Tukey损失等,进行更全面的比较分析。
在实际应用中,还需要考虑计算复杂度、收敛性和参数调优等工程化问题。这些因素对于损失函数的实际部署和应用具有重要影响。
https://avoid.overfit.cn/post/0db1639503ed43cba8f53b5e8b3ad8f9
作者: A. Rafli Pamungkas


)



