# 部署脚本:Ubuntu + vLLM + DeepSeek 70B
# 执行前请确保:1. 系统为 Ubuntu 20.04/22.04 2. 拥有NVIDIA显卡(显存≥24G)
# 保存两个文件 1 init.sh 初始化 2、test.sh 测试
# init.sh
#!/bin/bash
# 系统更新与基础依赖sudo apt update && sudo apt upgrade -ysudo apt install -y build-essential python3-pip curl git wget# NVIDIA驱动安装(需重启)#sudo add-apt-repository ppa:graphics-drivers/ppa -y#sudo apt update#sudo apt install -y nvidia-driver-550-serverecho "请手动重启系统后再次执行本脚本!"echo "sudo reboot "
exit 0 # 首次执行到此退出
# ---- 以下为重启后执行的第二部分 ----
#test.sh
#!/bin/bash
set -e
set -o pipefail# 模型下载示例(替换为实际模型ID)
MODEL_ID="deepseek-ai/DeepSeek-R1-Distill-Llama-70B"
python - <<EOF
from modelscope import snapshot_download
snapshot_download('$MODEL_ID', cache_dir='./models')
EOF# 启动服务
# 如报内容不够什么的,参数可根据实际做调整
#vllm serve ./models/$MODEL_ID --tensor-parallel-size 8 --gpu-memory-utilization 0.95 --port 6006 --max-model-len 8192 &
vllm serve ./models/$MODEL_ID --tensor-parallel-size 8 --gpu-memory-utilization 0.8 --max-num-seqs 128 --port 6006 --max-model-len 8192 &
SERVER_PID=$!
echo "Serve PID $SERVER_PID"
# 检查 PID 和端口的函数
check_status() {# 检查 PID 是否存在if [[ -z "$SERVER_PID" ]]; thenecho "错误:SERVER_PID未定义"exit 1fiif ! kill -0 $SERVER_PID > /dev/null 2>&1; thenecho "程序异常退出"exit 1fisleep 3# 检查端口 6006 是否在使用(注意脚本中使用的是6006,而非8000)if ss -tuln | grep -q ':6006 '; thenecho "服务已就绪"curl -i -k -X POST "http://localhost:6006/v1/chat/completions" -H "Content-Type: application/json" --data '{ "model": "./models/deepseek-ai/DeepSeek-R1-Distill-Llama-70B", "Max_tokens": 3072, "Temperature": 0.95, "messages": [ { "role": "user", "content": "请预测2025年到2027年我国给服务器GPU的市场" } ] }'echo "退出服务 kill $SERVER_PID"sleep 3kill $SERVER_PIDreturn 0elseecho "服务未就绪"return 1fi
}# 等服务成功后测试一下
while true; doif check_status; thensleep 1elseecho "程序异常退出"exit 1fi
done保存完后
chmod +x *.sh 设置为可执行
第一次也只要一次运行 init.sh 后重启服务器
后面测试 只要 test.sh ,test.sh 第一次需要下载模型会慢一些.
如果发现serve有正常启动,那可以再手动去测试一下:
用CURL:
curl -i -k -X POST "http://localhost:6006/v1/chat/completions" -H "Content-Type: application/json" --data '{ "model": "./models/deepseek-ai/DeepSeek-R1-Distill-Llama-70B", "Max_tokens": 3072, "Temperature": 0.95, "messages": [ { "role": "user", "content": "请预测2025年到2027年我国给服务器GPU的市场" } ] }'
结果:
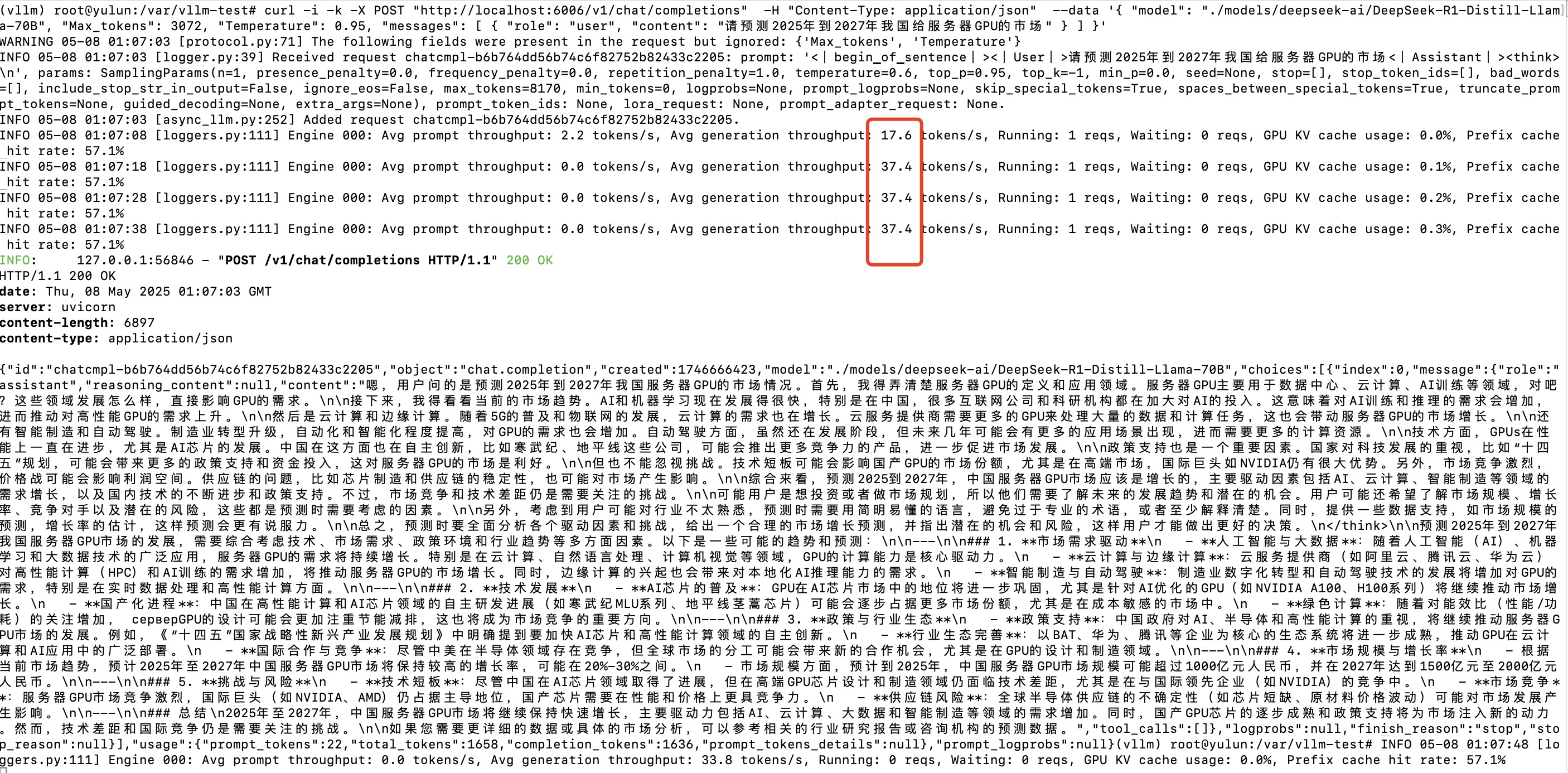
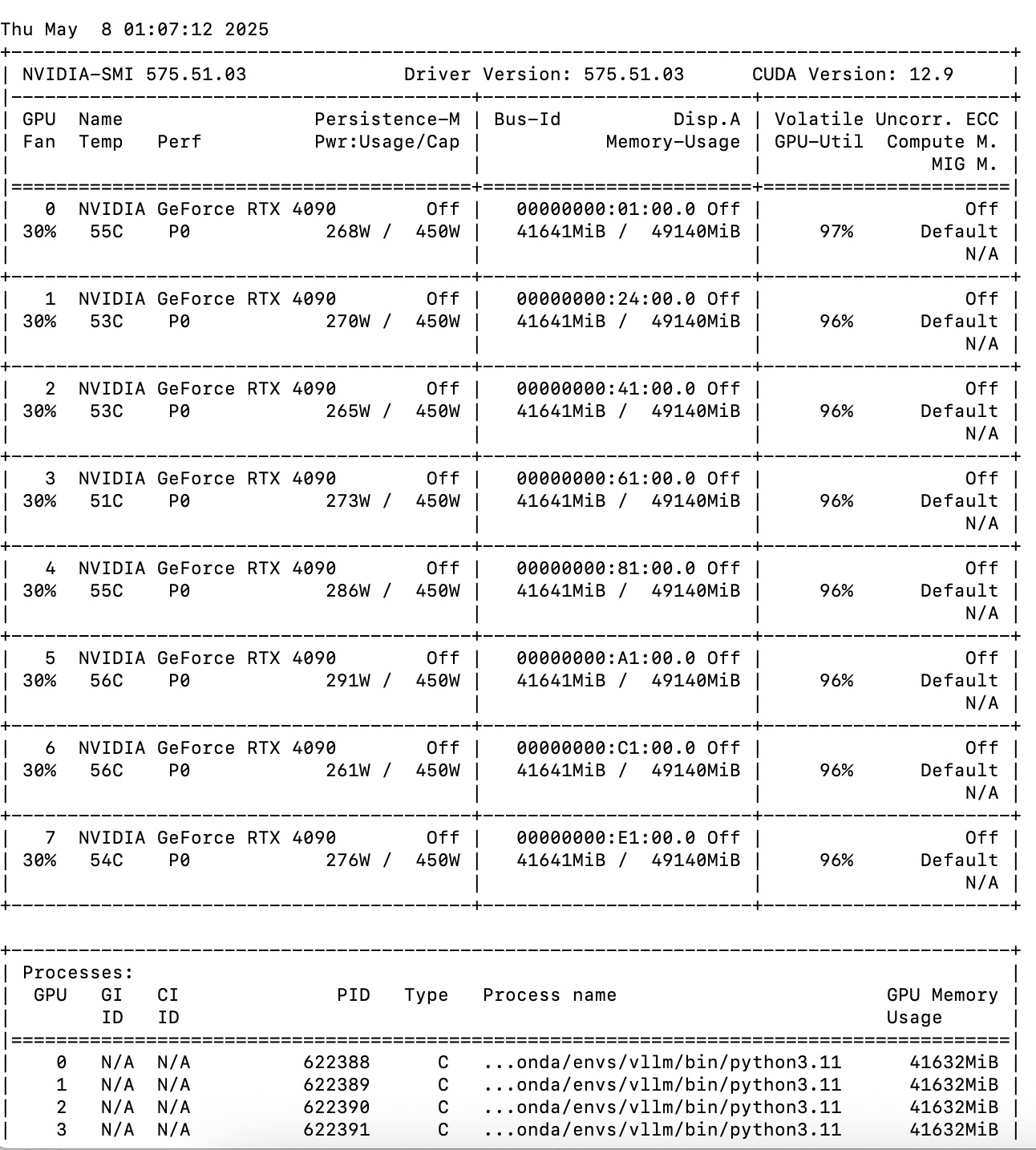
如果你要做个简单的并发可以这样:
for i in {1..1000}; do ;for i in {1..1000}; do ;curl -i -k -X POST "http://localhost:6006/v1/chat/completions" -H "Content-Type: application/json" --data '{ "model": "./models/deepseek-ai/DeepSeek-R1-Distill-Llama-70B", "Max_tokens": 3072, "Temperature": 0.95, "messages": [ { "role": "user", "content": "请预测2025年到2027年我国给服务器GPU的市场" } ] }' &donewaitdone这样提示词语是固定有可能缓存命中等,最好再来一个随机提示词.那就整理一个txt文件去一行行来做.这里就不折腾了哈






