「内容仅供参考学习」

准备
::: block-1
- 数据集: 《公平竞争审查条例》
- 模型: Qwen2.5-7B-Instruct-1M
- 方式: 外挂文档、rog数据检索
- 介绍: 不借助微调,使用知识库实现回答内容
:::
开始
- 准备知识库文档
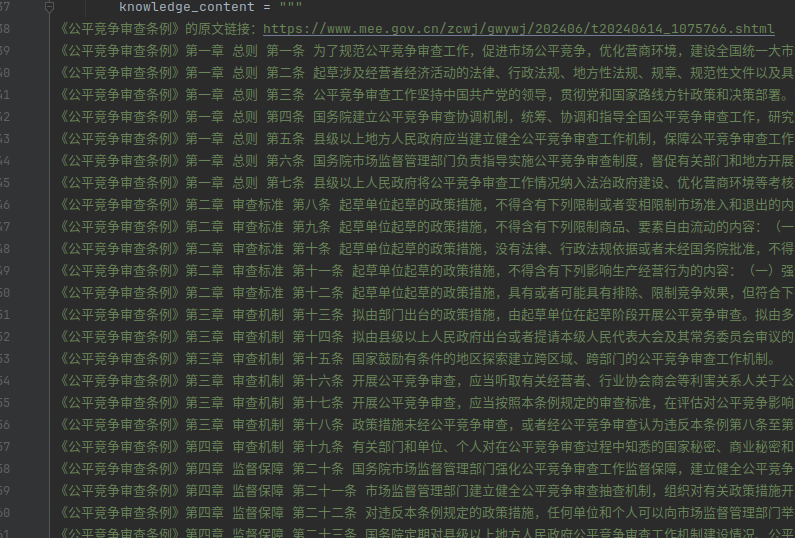
- 加载知识库
这边借助了langchain架构,内置了很多好用的方法
from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddingsdocuments = []
for data in knowledge_content.split("\n")doc = Document(page_content=data, metadata={"source": "doc1"})documents.append(doc)
embeddings = HuggingFaceEmbeddings(model) # 加载适合的NLP文本相似度识别模型
vectorStoresDB = FAISS.from_documents(documents, embeddings)
results = vectorStoresDB.similarity_search(query, k=2) # 通过比较输入文本与知识哭文本的相似度来排行,最相似的在最上面。k=2表示只取前2个文档- 将准备好的知识库放入提示词Prompt中
prompt = "根据以下文档回答问题:\n{knowledge_data}\n\n问题:{question}"
- 然后就是启动程序(省略。。。。。。)
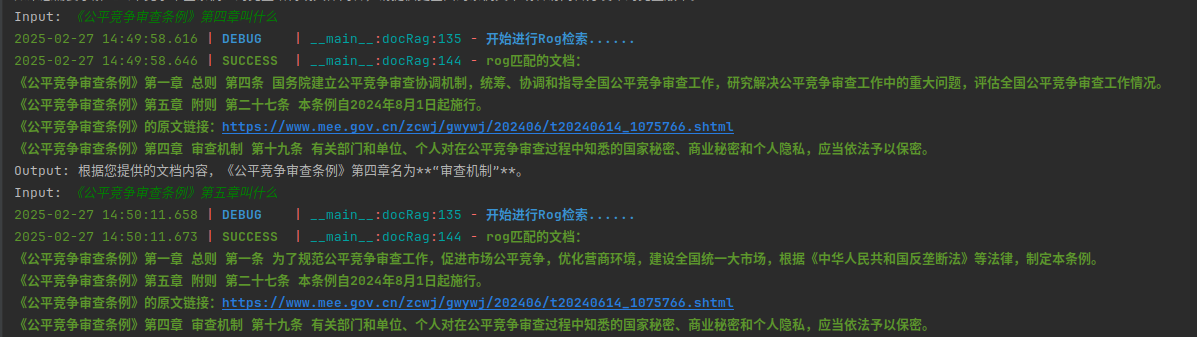
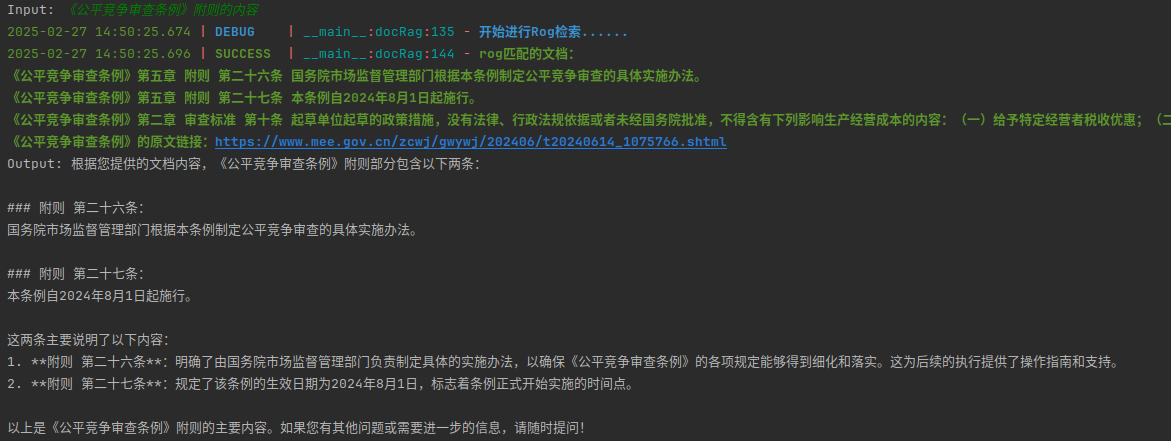
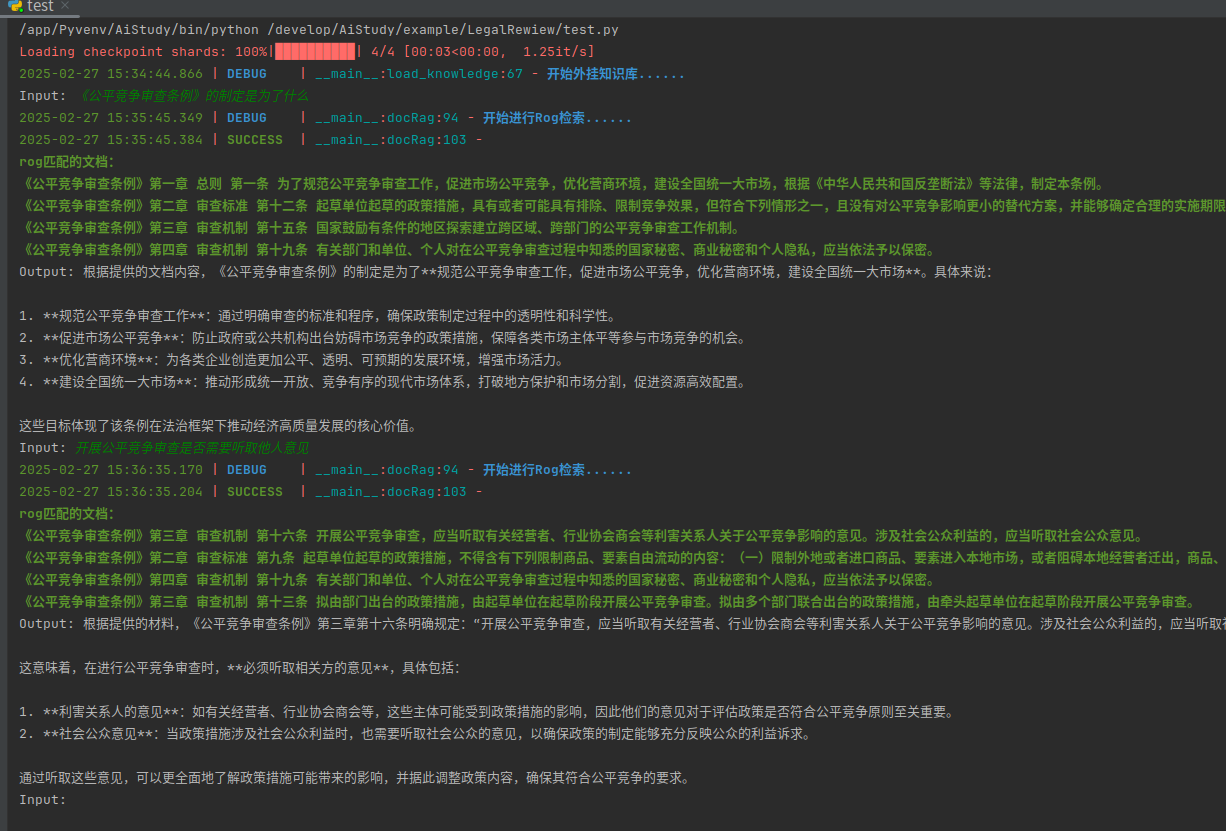
最终效果



:容器存储接口 CSI)


