目录
1.前言
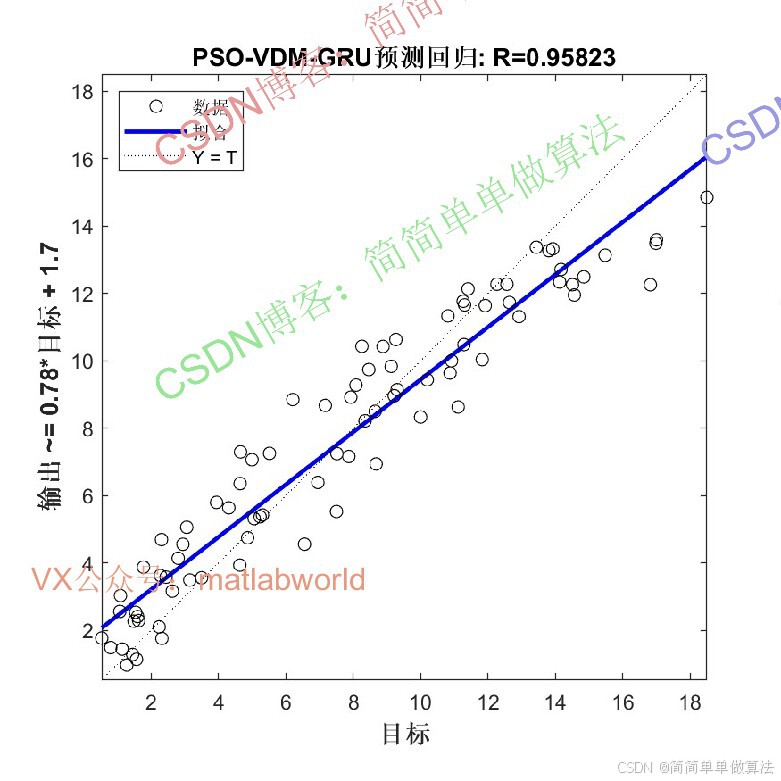
2.算法运行效果图预览
3.算法运行软件版本
4.部分核心程序
5.算法仿真参数
6.算法理论概述
6.1变分模态分解(VMD)
6.2 门控循环单元(GRU)
6.3 粒子群优化(PSO)
7.参考文献
8.算法完整程序工程
1.前言
时间序列预测在能源、气象等领域具有重要应用价值。传统方法如ARIMA、SVM等在处理非线性、非平稳序列时存在局限性,而深度学习模型(如GRU)虽能捕捉时序特征,但对初始参数敏感,且复杂序列需预处理以提升预测精度。变分模态分解(VMD)可将复杂时序分解为多个平稳模态分量,门控循环单元(GRU)可有效建模序列长期依赖关系,粒子群优化(PSO)则用于优化GRU的关键参数,形成 “分解-优化-预测” 的完整框架。该算法通过多技术协同,提升时序预测的准确性和鲁棒性。
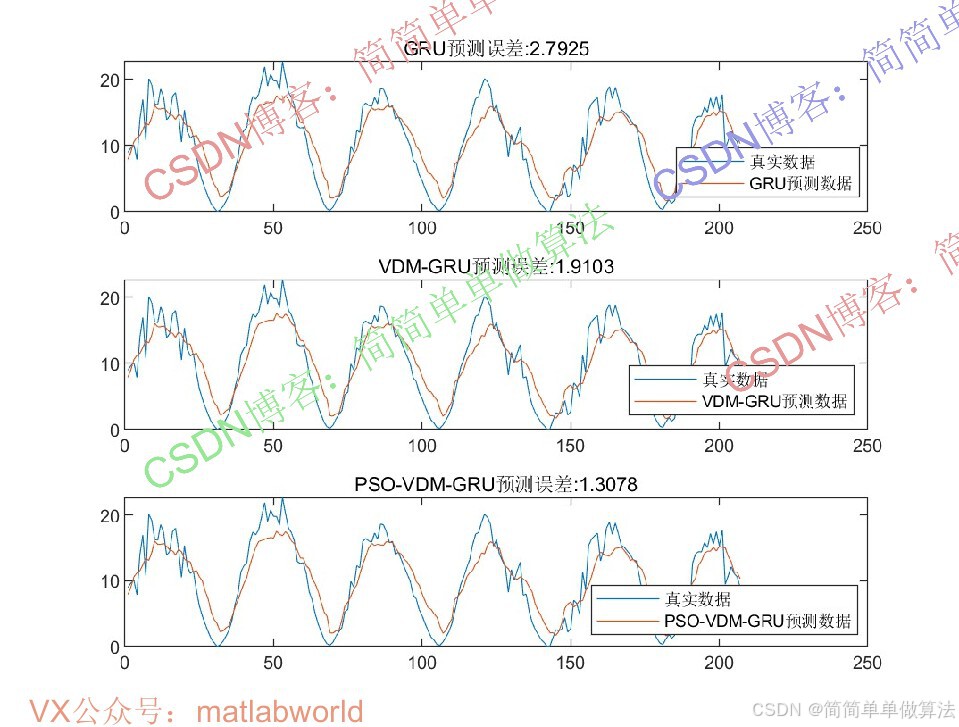
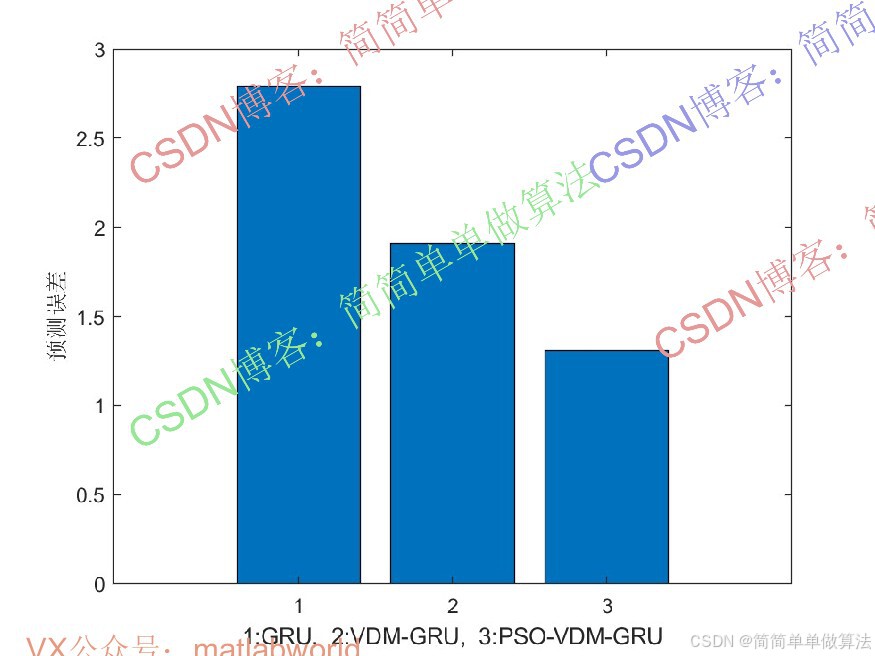
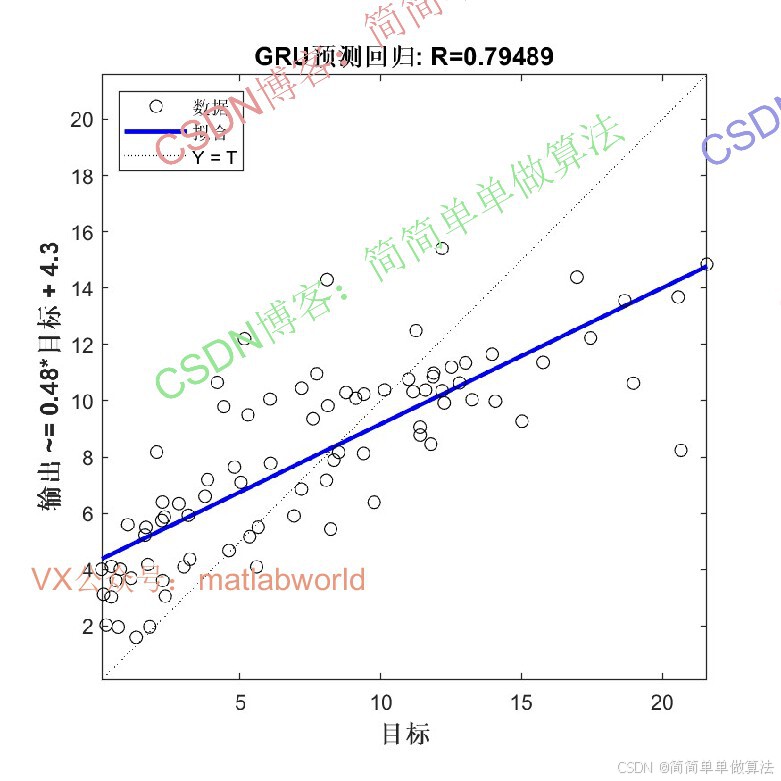
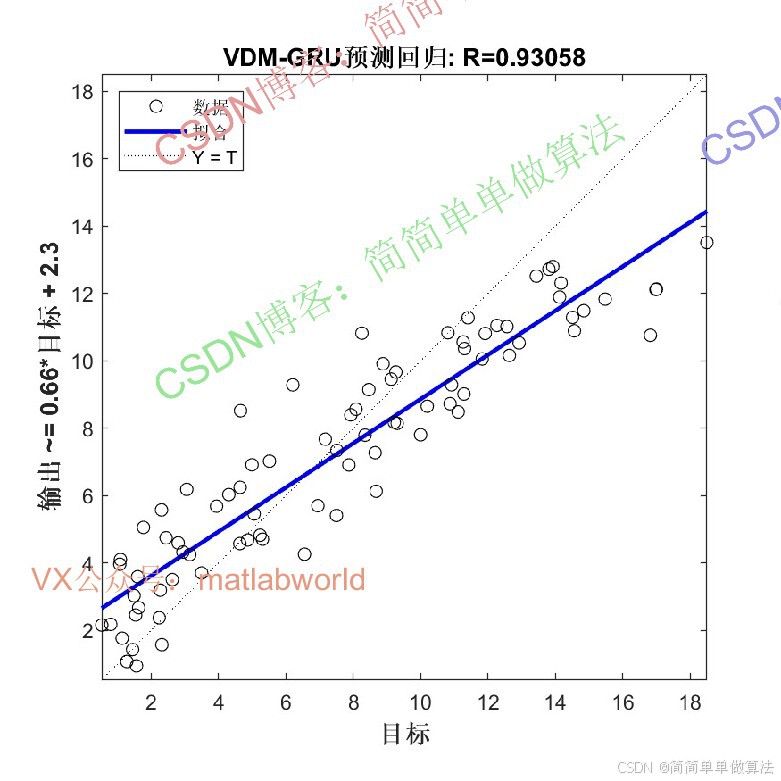
2.算法运行效果图预览
(完整程序运行后无水印)
3.算法运行软件版本
Matlab2024b(推荐)或者matlab2022a
4.部分核心程序
(完整版代码包含中文注释和操作步骤视频)
...................................................................[T_train,T_test,Pxtrain,Txtrain,Pxtest,Txtest,Norm_I,Norm_O,indim,outdim]=func_process2(X_imf,dims);%LSTM网络,layers = [ ...sequenceInputLayer(indim) gruLayer(Nlayer) reluLayer fullyConnectedLayer(outdim) regressionLayer];%参数设置options = trainingOptions('adam', ... % 优化算法Adam'MaxEpochs', 200, ... % 最大训练次数'GradientThreshold', 1, ... % 梯度阈值'InitialLearnRate', LR, ... % 初始学习率'LearnRateSchedule', 'piecewise', ... % 学习率调整'LearnRateDropPeriod', 60, ... 'LearnRateDropFactor',0.2, ... 'L2Regularization', 0.01, ... % 正则化参数'ExecutionEnvironment', 'cpu',... % 训练环境'Verbose', 0, ... % 关闭优化过程'Plots', 'training-progress'); % 画出曲线%训练[net,INFO] = trainNetwork(Pxtrain, Txtrain, layers, options);Rerr = INFO.TrainingRMSE;Rlos = INFO.TrainingLoss;%预测Tpre1 = predict(net, Pxtrain); Tpre2 = predict(net, Pxtest); %反归一化TNpre1 = mapminmax('reverse', Tpre1, Norm_O); TNpre2 = mapminmax('reverse', Tpre2, Norm_O); %数据格式转换TNpre1s(d,:) = cell2mat(TNpre1);TNpre2s(d,:) = cell2mat(TNpre2);T_trains(d,:) = T_train;T_tests(d,:) = T_test;Rerrs(d,:)=Rerr;Rloss(d,:)=Rlos;
end
2205.算法仿真参数
%pso参数
Npeop = 10; %搜索数量
Iter = 10; %迭代次数
DD = 2; %搜索空间维数%每个变量的取值范围
tmps(1,:) = [10,100]; %
tmps(2,:) = [0.0001;0.05]; %%学习因子
c1 = 2;
c2 = 2;
%用线性递减因子粒子群算法
Wmax = 1; %惯性权重最大值
Wmin = 0.8; %惯性权重最小值
%GRU参数
options = trainingOptions('adam', ... % 优化算法Adam'MaxEpochs', 200, ... % 最大训练次数'GradientThreshold', 1, ... % 梯度阈值'InitialLearnRate', LR, ... % 初始学习率'LearnRateSchedule', 'piecewise', ... % 学习率调整'LearnRateDropPeriod', 60, ... 'LearnRateDropFactor',0.2, ... 'L2Regularization', 0.01, ... % 正则化参数'ExecutionEnvironment', 'cpu',... % 训练环境'Verbose', 0, ... % 关闭优化过程'Plots', 'training-progress'); % 画出曲线6.算法理论概述
6.1变分模态分解(VMD)
VMD是一种自适应信号分解方法,通过构建变分模型将原始序列分解为若干模态分量(IMF),每个分量对应特定频率尺度,且带宽之和最小化。该过程通过交替迭代更新各模态的频率和幅值实现,无需预设分解层数(实际应用中需结合数据特性确定或优化)。


6.2 门控循环单元(GRU)
GRU是LSTM的轻量化变体,通过 “重置门” 和 “更新门” 机制控制信息流动,缓解长序列训练中的梯度消失问题。其核心结构包括:
重置门(Reset Gate):决定历史状态对当前候选状态的遗忘程度。
更新门(Update Gate):控制历史状态与当前候选状态的融合比例。
6.3 粒子群优化(PSO)
PSO模拟鸟群觅食行为,通过粒子间的信息共享搜索最优解。每个粒子代表一个候选解,通过更新自身速度和位置逼近全局最优。粒子状态由位置Xi和速度Vi表示,需跟踪个体最优位置Pbest,i和全局最优位置Gbest。
适应度函数:
针对 VMD-GRU 模型,PSO需优化的参数包括:
GRU隐藏层节点数nh
学习率η

7.参考文献
[1]皮有春,谭鋆,郭钰静,等.基于改进VMD和GRU的水轮发电机组振动故障预警[J].中国农村水利水电, 2024(3):244-249.DOI:10.12396/znsd.231143.
[2]郗涛,王锴,王莉静.基于优化VMD-GRU的滚动轴承剩余使用寿命预测[J].中国工程机械学报, 2024, 22(1):101-106.
8.算法完整程序工程
OOOOO
OOO
O

)
感知机)


