本文是 AI 推理系列的第一篇,近期将更新与 vLLM 的相关内容。本篇从 vLLM 的部署开始,介绍 vLLM GPU/CPU 后端的安装方式,后续将陆续讲解 vLLM 的核心特性,如 PD 分离、Speculative Decoding、Prefix Caching 等,敬请关注。
1 什么是 vLLM?
vLLM 是一个高效、易用的大语言模型(LLM)推理和服务框架,专注于优化推理速度和吞吐量,尤其适合高并发的生产环境。它由加州大学伯克利分校的研究团队开发,并因其出色的性能成为当前最受欢迎的 LLM 推理引擎之一。

vLLM 同时支持在 GPU 和 CPU 上运行,本文将会分别介绍 vLLM 使用 GPU 和 CPU 作为后端时的安装与运行方法。
2 前提准备
2.1 购买虚拟机
如果本地不具备 GPU 环境,可考虑通过云服务提供商(如阿里云、腾讯云等)购买 GPU 服务器。
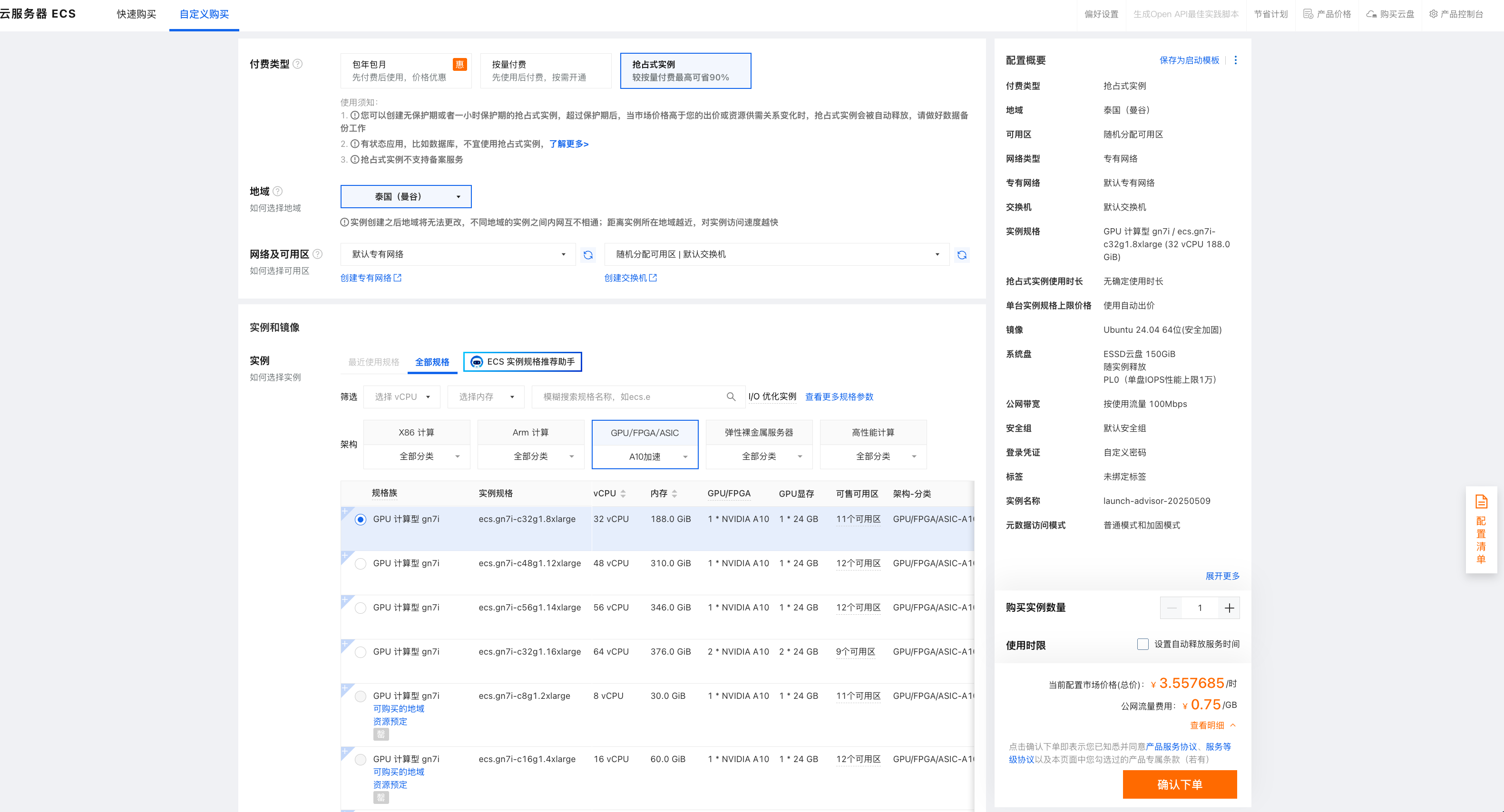
操作系统建议选择 Ubuntu 22.04,GPU 型号可根据实际需求进行选择。由于大语言模型通常占用较多磁盘空间,建议适当增加磁盘容量。
2.2 虚拟环境
推荐使用 uv 来管理 python 虚拟环境,执行以下命令安装 uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
3 安装
3.1 使用 GPU 作为 vLLM 后端
3.1.1 系统要求
vLLM 包含预编译的 C++ 和 CUDA (12.6) 二进制文件,需满足以下条件:
- 操作系统:Linux
- Python 版本:3.9 ~ 3.12
- GPU:计算能力 7.0 或更高(如 V100、T4、RTX20xx、A10、A100、L4、H100 等)
注:计算能力(Compute capability)定义了每个 NVIDIA GPU 架构的硬件特性和支持的指令。计算能力决定你是否可以使用某些 CUDA 或 Tensor 核心功能(如 Unified Memory、Tensor Core、动态并行等),并不直接代表 GPU 的计算性能。
3.1.2 安装和配置 GPU 依赖
可以使用以下命令一键安装相关依赖,该脚本会安装 NVIDIA GPU Driver,NVIDIA Container Toolkit,以及配置 NVIDIA Container Runtime(后续通过 Docker 运行 vLLM 时需要)。
curl -sS https://raw.githubusercontent.com/cr7258/hands-on-lab/refs/heads/main/ai/gpu/setup/docker-only-install.sh | bash
3.1.3 安装 vLLM
创建 Python 虚拟环境:
# (Recommended) Create a new uv environment. Use `--seed` to install `pip` and `setuptools` in the environment.
uv venv --python 3.12 --seed
source .venv/bin/activate
安装 vLLM:
uv pip install vllm
3.2 使用 CPU 作为 vLLM 后端
3.3 系统要求
- 操作系统:Linux
- Python 版本:3.9 ~ 3.12
- 编译器: gcc/g++ >= 12.3.0 (可选,建议)
3.4 安装编译依赖
vLLM 当前并没有为 CPU 提供预构建的安装包或者镜像,需要自己根据源码进行编译。
uv venv vllm-cpu --python 3.12 --seed
source vllm-cpu/bin/activate
首先,安装推荐的编译器。建议使用 gcc/g++ >= 12.3.0 作为默认编译器以避免潜在问题。例如,在 Ubuntu 22.4 上,你可以运行:
sudo apt-get update -y
sudo apt-get install -y gcc-12 g++-12 libnuma-dev python3-dev
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-12 10 --slave /usr/bin/g++ g++ /usr/bin/g++-12
然后克隆 vLLM 仓库:
git clone https://github.com/vllm-project/vllm.git vllm_source
cd vllm_source
接着,安装用于构建 vLLM CPU 后端的 Python 包:
pip install --upgrade pip
pip install "cmake>=3.26" wheel packaging ninja "setuptools-scm>=8" numpy
pip install -v -r requirements/cpu.txt --extra-index-url https://download.pytorch.org/whl/cpu
pip install intel-extension-for-pytorch
3.5 安装 vLLM
最后,构建并安装 vLLM CPU 后端:
VLLM_TARGET_DEVICE=cpu python setup.py install
3.3 使用 Docker 运行 vLLM
vLLM 官方提供了 Docker 镜像用于部署。执行以下命令使用 Docker 来运行 GPU 后端的 vLLM:
docker run --runtime nvidia --gpus all \-v ~/.cache/huggingface:/root/.cache/huggingface \-p 8000:8000 \--ipc=host \vllm/vllm-openai:latest \--model Qwen/Qwen2.5-1.5B-Instruct
以下是命令参数的解释:
--runtime nvidia: 指定使用 NVIDIA 容器运行时,这是运行需要 GPU 的容器的必要设置。--gpus all: 允许容器访问主机上的所有 GPU 资源。如果你只想使用特定的 GPU,可以指定 GPU ID,例如使用--gpus '"device=0,1"'指定使用 0 和 1 号 GPU(注意:device前后还有个单引号,否则会看到这个报错:cannot set both Count and DeviceIDs on device request.)。如果想直接设置指定数量的 GPU,例如可以使用--gpus 2,使用 2 个 GPU。-v ~/.cache/huggingface:/root/.cache/huggingface: 将主机上的 Hugging Face 缓存目录挂载到容器内。这样可以在容器重启后重用已下载的模型,避免重复下载,节省时间和网络流量。-p 8000:8000: 将容器内的 8000 端口映射到主机的 8000 端口,使得可以通过http://localhost:8000访问 vLLM 服务。- 你可以使用
ipc=host标志或--shm-size标志,让容器访问宿主机的共享内存。vLLM 使用 PyTorch,而 PyTorch 在底层通过共享内存在进程之间传递数据,尤其是在进行张量并行推理时。在使用多个 GPU 进行推理时需要设置该参数。 vllm/vllm-openai:latest: 使用的 Docker 镜像,latest表示最新版本的 vLLM OpenAI 兼容服务器镜像。--model Qwen/Qwen2.5-1.5B-Instruct: 传递给 vLLM 服务的参数,指定要加载的模型为Qwen/Qwen2.5-1.5B-Instruct。
如果要使用 CPU 作为后端来运行 vLLM 可以使用这个仓库的镜像。
docker run --rm \-v ~/.cache/huggingface:/root/.cache/huggingface \-p 8000:8000 \--ipc=host \public.ecr.aws/q9t5s3a7/vllm-cpu-release-repo:v0.8.5 \--model=Qwen/Qwen2.5-1.5B-Instruct
vLLM 提供了两种主要的推理模式:离线推理(Offline Inference)和在线推理(Online Serving),适用于不同的应用场景和需求。这两种模式的区别如下:
4 离线推理和在线推理的区别
离线推理(offline inference)和在线推理(online inference)的主要区别在于使用场景、延迟要求、资源调度方式等方面,简单总结如下:
4.1 离线推理
定义: 对一批输入数据进行集中处理,通常不要求实时返回结果。特点如下:
- 批处理:常用于处理大量输入,如日志分析、推荐系统预计算。
- 低延迟要求:结果可以晚些返回,不影响用户体验。
- 资源利用高:系统可以在空闲时充分利用 GPU/CPU 资源。
- 示例场景:每天夜间跑用户兴趣画像、预生成广告文案等。
4.2 在线推理
定义: 针对用户实时请求进行推理,立即返回结果。特点如下:
- 实时响应:响应时间通常要求在几百毫秒以内。
- 延迟敏感:高并发、低延迟是核心指标。
- 资源分配稳定:服务需长时间在线、资源预留固定。
- 示例场景:聊天机器人、搜索联想、智能客服等。
5 离线推理
安装好 vLLM 后,你可以开始对一系列输入提示词进行文本生成(即离线批量推理)。以下代码是 vLLM 官网提供的示例:
# basic.py
# https://github.com/vllm-project/vllm/blob/main/examples/offline_inference/basic/basic.pyfrom vllm import LLM, SamplingParams# Sample prompts.
prompts = ["Hello, my name is","The president of the United States is","The capital of France is","The future of AI is",
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)def main():# Create an LLM.llm = LLM(model="facebook/opt-125m")# Generate texts from the prompts.# The output is a list of RequestOutput objects# that contain the prompt, generated text, and other information.outputs = llm.generate(prompts, sampling_params)# Print the outputs.print("\nGenerated Outputs:\n" + "-" * 60)for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}")print(f"Output: {generated_text!r}")print("-" * 60)if __name__ == "__main__":main()
在上面的代码中,使用了 SamplingParams 来指定采样过程的参数。采样温度设置为 0.8,核采样概率设置为 0.95。下面解释一下这两个参数的用途:
Sampling Temperature(采样温度) 和 Nucleus Sampling Probability(核采样概率/Top-p) 是大语言模型生成文本时常用的两个采样参数,用于控制输出文本的多样性和质量。
-
采样温度(Sampling Temperature)
- 作用:控制生成文本的“随机性”或“创造性”。
- 原理:温度会对模型输出的概率分布进行缩放。温度越低(如0.5),高概率的词更容易被选中,生成结果更确定、重复性更高;温度越高(如1.2),低概率的词被选中的机会增加,文本更有多样性但可能更混乱。
- 具体来说,temperature=0.8 表示在概率分布上做了一定程度的“平滑”,比默认的 1.0 更偏向于选择高概率词,但仍保留一定的多样性。
-
核采样概率(Nucleus Sampling Probability / Top-p)
- 作用:控制每一步生成时考虑的候选词集合大小,动态平衡文本的多样性和合理性。
- 原理:Top-p(核采样)会将所有词按概率从高到低排序,累加概率,直到总和首次超过 0.95 为止,只在这部分“核心”词中随机采样。
这里用一个例子来解释这两个采样参数之间的关系,假设模型下一步可以说 “猫 狗 老虎 大象 猴子 乌龟 老鹰 鳄鱼 蚂蚁 …”(有上万个词):
Temperature是调整每个词出现的概率(“猫”的概率是 30%,你可以把它调得更大或更小);Top-p是把所有词排序后,只保留累计概率达到 95% 的前几个词,比如前 7 个,然后从中挑一个。
输出是通过 llm.generate 方法生成的。该方法会将输入提示加入 vLLM 引擎的等待队列,并调用 vLLM 引擎以高吞吐量生成输出。最终输出会以 RequestOutput 对象列表的形式返回,每个对象包含完整的输出 token。
执行以下代码运行程序:
python basic.py# 输出
INFO 05-09 22:19:49 [__init__.py:239] Automatically detected platform cuda.
INFO 05-09 22:20:08 [config.py:717] This model supports multiple tasks: {'embed', 'classify', 'reward', 'generate', 'score'}. Defaulting to 'generate'.
INFO 05-09 22:20:13 [config.py:2003] Chunked prefill is enabled with max_num_batched_tokens=8192.
tokenizer_config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 685/685 [00:00<00:00, 6.99MB/s]
vocab.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 899k/899k [00:00<00:00, 1.90MB/s]
merges.txt: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 456k/456k [00:00<00:00, 13.1MB/s]
special_tokens_map.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 441/441 [00:00<00:00, 5.21MB/s]
generation_config.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 137/137 [00:00<00:00, 1.70MB/s]
INFO 05-09 22:20:18 [core.py:58] Initializing a V1 LLM engine (v0.8.5.post1) with config: model='facebook/opt-125m', speculative_config=None, tokenizer='facebook/opt-125m', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.float16, max_seq_len=2048, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='auto', reasoning_backend=None), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=facebook/opt-125m, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=True, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"level":3,"custom_ops":["none"],"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output"],"use_inductor":true,"compile_sizes":[],"use_cudagraph":true,"cudagraph_num_of_warmups":1,"cudagraph_capture_sizes":[512,504,496,488,480,472,464,456,448,440,432,424,416,408,400,392,384,376,368,360,352,344,336,328,320,312,304,296,288,280,272,264,256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":512}
WARNING 05-09 22:20:19 [utils.py:2522] Methods determine_num_available_blocks,device_config,get_cache_block_size_bytes,initialize_cache not implemented in <vllm.v1.worker.gpu_worker.Worker object at 0x78d0197039e0>
INFO 05-09 22:20:21 [parallel_state.py:1004] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0
INFO 05-09 22:20:21 [cuda.py:221] Using Flash Attention backend on V1 engine.
WARNING 05-09 22:20:21 [topk_topp_sampler.py:69] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
INFO 05-09 22:20:21 [gpu_model_runner.py:1329] Starting to load model facebook/opt-125m...
INFO 05-09 22:20:22 [weight_utils.py:265] Using model weights format ['*.bin']
pytorch_model.bin: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 251M/251M [00:27<00:00, 8.96MB/s]
INFO 05-09 22:20:51 [weight_utils.py:281] Time spent downloading weights for facebook/opt-125m: 28.962338 seconds
Loading pt checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading pt checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 5.84it/s]
Loading pt checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 5.83it/s]INFO 05-09 22:20:51 [loader.py:458] Loading weights took 0.17 seconds
INFO 05-09 22:20:51 [gpu_model_runner.py:1347] Model loading took 0.2389 GiB and 29.934842 seconds
INFO 05-09 22:20:53 [backends.py:420] Using cache directory: /root/.cache/vllm/torch_compile_cache/4f59edd943/rank_0_0 for vLLM's torch.compile
INFO 05-09 22:20:53 [backends.py:430] Dynamo bytecode transform time: 2.05 s
INFO 05-09 22:20:55 [backends.py:136] Cache the graph of shape None for later use
INFO 05-09 22:20:59 [backends.py:148] Compiling a graph for general shape takes 6.06 s
INFO 05-09 22:21:02 [monitor.py:33] torch.compile takes 8.11 s in total
INFO 05-09 22:21:02 [kv_cache_utils.py:634] GPU KV cache size: 549,216 tokens
INFO 05-09 22:21:02 [kv_cache_utils.py:637] Maximum concurrency for 2,048 tokens per request: 268.17x
INFO 05-09 22:21:17 [gpu_model_runner.py:1686] Graph capturing finished in 15 secs, took 0.20 GiB
INFO 05-09 22:21:17 [core.py:159] init engine (profile, create kv cache, warmup model) took 26.22 seconds
INFO 05-09 22:21:17 [core_client.py:439] Core engine process 0 ready.
Processed prompts: 100%|████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 32.86it/s, est. speed input: 213.68 toks/s, output: 525.96 toks/s]Generated Outputs:
------------------------------------------------------------
Prompt: 'Hello, my name is'
Output: " Paul D. I'm 28 years old. I'm a girl, but I"
------------------------------------------------------------
Prompt: 'The president of the United States is'
Output: ' facing the same problems as a former CIA director, who has been accused of repeatedly'
------------------------------------------------------------
Prompt: 'The capital of France is'
Output: ' exploding with touristy people.\nWhat do you mean? Did you mean'
------------------------------------------------------------
Prompt: 'The future of AI is'
Output: ' set for a big shift in the near term. The world is in the hands'
------------------------------------------------------------
默认情况下,vLLM 会从 Hugging Face 下载模型。如果你想使用来自 ModelScope 的模型,请设置 VLLM_USE_MODELSCOPE 环境变量。
6 在线推理
vLLM 可以部署为实现 OpenAI API 协议的服务器。默认情况下,服务器在 http://localhost:8000 启动。你可以通过 --host 和 --port 参数指定地址。服务器目前一次只能托管一个模型,实现了 list models,create chat completion 等端点。
运行以下命令以启动 vLLM 服务器,并使用 Qwen/Qwen2.5-1.5B-Instruct 模型:
vllm serve Qwen/Qwen2.5-1.5B-Instruct
启动后的输出如下(GPU 后端):
INFO 05-09 22:51:11 [__init__.py:239] Automatically detected platform cuda.
INFO 05-09 22:51:18 [api_server.py:1043] vLLM API server version 0.8.5.post1
INFO 05-09 22:51:18 [api_server.py:1044] args: Namespace(subparser='serve', model_tag='Qwen/Qwen2.5-1.5B-Instruct', config='', host=None, port=8000, uvicorn_log_level='info', disable_uvicorn_access_log=False, allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, chat_template_content_format='auto', response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, enable_ssl_refresh=False, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_request_id_headers=False, enable_auto_tool_choice=False, tool_call_parser=None, tool_parser_plugin='', model='Qwen/Qwen2.5-1.5B-Instruct', task='auto', tokenizer=None, hf_config_path=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=False, allowed_local_media_path=None, load_format='auto', download_dir=None, model_loader_extra_config={}, use_tqdm_on_load=True, config_format=<ConfigFormat.AUTO: 'auto'>, dtype='auto', max_model_len=None, guided_decoding_backend='auto', reasoning_parser=None, logits_processor_pattern=None, model_impl='auto', distributed_executor_backend=None, pipeline_parallel_size=1, tensor_parallel_size=1, data_parallel_size=1, enable_expert_parallel=False, max_parallel_loading_workers=None, ray_workers_use_nsight=False, disable_custom_all_reduce=False, block_size=None, gpu_memory_utilization=0.9, swap_space=4, kv_cache_dtype='auto', num_gpu_blocks_override=None, enable_prefix_caching=None, prefix_caching_hash_algo='builtin', cpu_offload_gb=0, calculate_kv_scales=False, disable_sliding_window=False, use_v2_block_manager=True, seed=None, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, hf_token=None, hf_overrides=None, enforce_eager=False, max_seq_len_to_capture=8192, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config={}, limit_mm_per_prompt={}, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=None, enable_lora_bias=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=None, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', speculative_config=None, ignore_patterns=[], served_model_name=None, qlora_adapter_name_or_path=None, show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, max_num_batched_tokens=None, max_num_seqs=None, max_num_partial_prefills=1, max_long_partial_prefills=1, long_prefill_token_threshold=0, num_lookahead_slots=0, scheduler_delay_factor=0.0, preemption_mode=None, num_scheduler_steps=1, multi_step_stream_outputs=True, scheduling_policy='fcfs', enable_chunked_prefill=None, disable_chunked_mm_input=False, scheduler_cls='vllm.core.scheduler.Scheduler', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', worker_extension_cls='', generation_config='auto', override_generation_config=None, enable_sleep_mode=False, additional_config=None, enable_reasoning=False, disable_cascade_attn=False, disable_log_requests=False, max_log_len=None, disable_fastapi_docs=False, enable_prompt_tokens_details=False, enable_server_load_tracking=False, dispatch_function=<function ServeSubcommand.cmd at 0x7e5c1f36b740>)
config.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 660/660 [00:00<00:00, 6.78MB/s]
INFO 05-09 22:51:33 [config.py:717] This model supports multiple tasks: {'reward', 'classify', 'generate', 'score', 'embed'}. Defaulting to 'generate'.
INFO 05-09 22:51:38 [config.py:2003] Chunked prefill is enabled with max_num_batched_tokens=2048.
tokenizer_config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7.30k/7.30k [00:00<00:00, 6.34MB/s]
vocab.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.78M/2.78M [00:00<00:00, 3.32MB/s]
merges.txt: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.67M/1.67M [00:00<00:00, 2.64MB/s]
tokenizer.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7.03M/7.03M [00:00<00:00, 8.10MB/s]
generation_config.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 242/242 [00:00<00:00, 2.76MB/s]
INFO 05-09 22:51:51 [__init__.py:239] Automatically detected platform cuda.
INFO 05-09 22:51:56 [core.py:58] Initializing a V1 LLM engine (v0.8.5.post1) with config: model='Qwen/Qwen2.5-1.5B-Instruct', speculative_config=None, tokenizer='Qwen/Qwen2.5-1.5B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=32768, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='auto', reasoning_backend=None), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=Qwen/Qwen2.5-1.5B-Instruct, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=True, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"level":3,"custom_ops":["none"],"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output"],"use_inductor":true,"compile_sizes":[],"use_cudagraph":true,"cudagraph_num_of_warmups":1,"cudagraph_capture_sizes":[512,504,496,488,480,472,464,456,448,440,432,424,416,408,400,392,384,376,368,360,352,344,336,328,320,312,304,296,288,280,272,264,256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":512}
WARNING 05-09 22:51:57 [utils.py:2522] Methods determine_num_available_blocks,device_config,get_cache_block_size_bytes,initialize_cache not implemented in <vllm.v1.worker.gpu_worker.Worker object at 0x78bea674d970>
INFO 05-09 22:51:58 [parallel_state.py:1004] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0
INFO 05-09 22:51:58 [cuda.py:221] Using Flash Attention backend on V1 engine.
WARNING 05-09 22:51:58 [topk_topp_sampler.py:69] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
INFO 05-09 22:51:58 [gpu_model_runner.py:1329] Starting to load model Qwen/Qwen2.5-1.5B-Instruct...
INFO 05-09 22:51:59 [weight_utils.py:265] Using model weights format ['*.safetensors']
model.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3.09G/3.09G [03:44<00:00, 13.8MB/s]
INFO 05-09 22:55:44 [weight_utils.py:281] Time spent downloading weights for Qwen/Qwen2.5-1.5B-Instruct: 225.167288 seconds
INFO 05-09 22:55:45 [weight_utils.py:315] No model.safetensors.index.json found in remote.
Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 2.23it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 2.23it/s]INFO 05-09 22:55:45 [loader.py:458] Loading weights took 0.50 seconds
INFO 05-09 22:55:45 [gpu_model_runner.py:1347] Model loading took 2.8871 GiB and 226.791553 seconds
INFO 05-09 22:55:52 [backends.py:420] Using cache directory: /root/.cache/vllm/torch_compile_cache/c822c41d5a/rank_0_0 for vLLM's torch.compile
INFO 05-09 22:55:52 [backends.py:430] Dynamo bytecode transform time: 6.61 s
INFO 05-09 22:55:54 [backends.py:136] Cache the graph of shape None for later use
INFO 05-09 22:56:17 [backends.py:148] Compiling a graph for general shape takes 24.18 s
INFO 05-09 22:56:26 [monitor.py:33] torch.compile takes 30.79 s in total
INFO 05-09 22:56:27 [kv_cache_utils.py:634] GPU KV cache size: 567,984 tokens
INFO 05-09 22:56:27 [kv_cache_utils.py:637] Maximum concurrency for 32,768 tokens per request: 17.33x
INFO 05-09 22:56:47 [gpu_model_runner.py:1686] Graph capturing finished in 21 secs, took 0.45 GiB
INFO 05-09 22:56:47 [core.py:159] init engine (profile, create kv cache, warmup model) took 62.02 seconds
INFO 05-09 22:56:47 [core_client.py:439] Core engine process 0 ready.
WARNING 05-09 22:56:48 [config.py:1239] Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
INFO 05-09 22:56:48 [serving_chat.py:118] Using default chat sampling params from model: {'repetition_penalty': 1.1, 'temperature': 0.7, 'top_k': 20, 'top_p': 0.8}
INFO 05-09 22:56:48 [serving_completion.py:61] Using default completion sampling params from model: {'repetition_penalty': 1.1, 'temperature': 0.7, 'top_k': 20, 'top_p': 0.8}
INFO 05-09 22:56:48 [api_server.py:1090] Starting vLLM API server on http://0.0.0.0:8000
INFO 05-09 22:56:48 [launcher.py:28] Available routes are:
INFO 05-09 22:56:48 [launcher.py:36] Route: /openapi.json, Methods: HEAD, GET
INFO 05-09 22:56:48 [launcher.py:36] Route: /docs, Methods: HEAD, GET
INFO 05-09 22:56:48 [launcher.py:36] Route: /docs/oauth2-redirect, Methods: HEAD, GET
INFO 05-09 22:56:48 [launcher.py:36] Route: /redoc, Methods: HEAD, GET
INFO 05-09 22:56:48 [launcher.py:36] Route: /health, Methods: GET
INFO 05-09 22:56:48 [launcher.py:36] Route: /load, Methods: GET
INFO 05-09 22:56:48 [launcher.py:36] Route: /ping, Methods: POST, GET
INFO 05-09 22:56:48 [launcher.py:36] Route: /tokenize, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /detokenize, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /v1/models, Methods: GET
INFO 05-09 22:56:48 [launcher.py:36] Route: /version, Methods: GET
INFO 05-09 22:56:48 [launcher.py:36] Route: /v1/chat/completions, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /v1/completions, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /v1/embeddings, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /pooling, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /score, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /v1/score, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /v1/audio/transcriptions, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /rerank, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /v1/rerank, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /v2/rerank, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /invocations, Methods: POST
INFO 05-09 22:56:48 [launcher.py:36] Route: /metrics, Methods: GET
INFO: Started server process [49305]
INFO: Waiting for application startup.
INFO: Application startup complete.
启动后的输出如下(CPU 后端):
INFO 05-10 11:48:14 [__init__.py:248] Automatically detected platform cpu.
INFO 05-10 11:48:27 [config.py:760] This model supports multiple tasks: {'classify', 'generate', 'embed', 'score', 'reward'}. Defaulting to 'generate'.
INFO 05-10 11:48:27 [config.py:1857] Disabled the custom all-reduce kernel because it is not supported on current platform.
WARNING 05-10 11:48:27 [config.py:2019] max_model_len was is not set. Defaulting to arbitrary value of 8192.
WARNING 05-10 11:48:27 [config.py:2025] max_num_seqs was is not set. Defaulting to arbitrary value of 128.
INFO 05-10 11:48:29 [config.py:760] This model supports multiple tasks: {'classify', 'generate', 'embed', 'score', 'reward'}. Defaulting to 'generate'.
INFO 05-10 11:48:29 [config.py:1857] Disabled the custom all-reduce kernel because it is not supported on current platform.
INFO 05-10 11:48:30 [config.py:760] This model supports multiple tasks: {'classify', 'generate', 'embed', 'score', 'reward'}. Defaulting to 'generate'.
INFO 05-10 11:48:30 [config.py:1857] Disabled the custom all-reduce kernel because it is not supported on current platform.
INFO 05-10 11:48:31 [config.py:760] This model supports multiple tasks: {'classify', 'generate', 'embed', 'score', 'reward'}. Defaulting to 'generate'.
INFO 05-10 11:48:31 [config.py:1857] Disabled the custom all-reduce kernel because it is not supported on current platform.
INFO 05-10 11:48:31 [api_server.py:1044] vLLM API server version 0.8.5.dev572+g246e3e0a3
INFO 05-10 11:48:32 [config.py:760] This model supports multiple tasks: {'classify', 'generate', 'embed', 'score', 'reward'}. Defaulting to 'generate'.
INFO 05-10 11:48:32 [config.py:1857] Disabled the custom all-reduce kernel because it is not supported on current platform.
INFO 05-10 11:48:32 [cli_args.py:297] non-default args: {'model': 'Qwen/Qwen2.5-1.5B-Instruct'}
INFO 05-10 11:48:41 [config.py:760] This model supports multiple tasks: {'classify', 'generate', 'embed', 'score', 'reward'}. Defaulting to 'generate'.
WARNING 05-10 11:48:41 [arg_utils.py:1533] device type=cpu is not supported by the V1 Engine. Falling back to V0.
INFO 05-10 11:48:41 [config.py:1857] Disabled the custom all-reduce kernel because it is not supported on current platform.
WARNING 05-10 11:48:41 [cpu.py:118] Environment variable VLLM_CPU_KVCACHE_SPACE (GiB) for CPU backend is not set, using 4 by default.
WARNING 05-10 11:48:41 [cpu.py:131] uni is not supported on CPU, fallback to mp distributed executor backend.
INFO 05-10 11:48:41 [api_server.py:247] Started engine process with PID 23528
INFO 05-10 11:48:45 [__init__.py:248] Automatically detected platform cpu.
INFO 05-10 11:48:47 [llm_engine.py:240] Initializing a V0 LLM engine (v0.8.5.dev572+g246e3e0a3) with config: model='Qwen/Qwen2.5-1.5B-Instruct', speculative_config=None, tokenizer='Qwen/Qwen2.5-1.5B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config={}, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=32768, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=True, quantization=None, enforce_eager=True, kv_cache_dtype=auto, device_config=cpu, decoding_config=DecodingConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_backend=''), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None), seed=None, served_model_name=Qwen/Qwen2.5-1.5B-Instruct, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=None, chunked_prefill_enabled=False, use_async_output_proc=False, pooler_config=None, compilation_config={"compile_sizes": [], "inductor_compile_config": {"enable_auto_functionalized_v2": false}, "cudagraph_capture_sizes": [256, 248, 240, 232, 224, 216, 208, 200, 192, 184, 176, 168, 160, 152, 144, 136, 128, 120, 112, 104, 96, 88, 80, 72, 64, 56, 48, 40, 32, 24, 16, 8, 4, 2, 1], "max_capture_size": 256}, use_cached_outputs=True,
INFO 05-10 11:48:49 [cpu.py:57] Using Torch SDPA backend.
INFO 05-10 11:48:49 [parallel_state.py:1004] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0
INFO 05-10 11:48:49 [weight_utils.py:257] Using model weights format ['*.safetensors']
INFO 05-10 11:48:50 [weight_utils.py:307] No model.safetensors.index.json found in remote.
Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 6.57it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 6.56it/s]INFO 05-10 11:48:50 [default_loader.py:278] Loading weights took 0.19 seconds
INFO 05-10 11:48:50 [executor_base.py:112] # cpu blocks: 9362, # CPU blocks: 0
INFO 05-10 11:48:50 [executor_base.py:117] Maximum concurrency for 32768 tokens per request: 4.57x
INFO 05-10 11:48:50 [llm_engine.py:435] init engine (profile, create kv cache, warmup model) took 0.15 seconds
WARNING 05-10 11:48:51 [config.py:1283] Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
INFO 05-10 11:48:51 [serving_chat.py:116] Using default chat sampling params from model: {'repetition_penalty': 1.1, 'temperature': 0.7, 'top_k': 20, 'top_p': 0.8}
INFO 05-10 11:48:51 [serving_completion.py:61] Using default completion sampling params from model: {'repetition_penalty': 1.1, 'temperature': 0.7, 'top_k': 20, 'top_p': 0.8}
INFO 05-10 11:48:51 [api_server.py:1091] Starting vLLM API server on http://0.0.0.0:8000
INFO 05-10 11:48:51 [launcher.py:28] Available routes are:
INFO 05-10 11:48:51 [launcher.py:36] Route: /openapi.json, Methods: GET, HEAD
INFO 05-10 11:48:51 [launcher.py:36] Route: /docs, Methods: GET, HEAD
INFO 05-10 11:48:51 [launcher.py:36] Route: /docs/oauth2-redirect, Methods: GET, HEAD
INFO 05-10 11:48:51 [launcher.py:36] Route: /redoc, Methods: GET, HEAD
INFO 05-10 11:48:51 [launcher.py:36] Route: /health, Methods: GET
INFO 05-10 11:48:51 [launcher.py:36] Route: /load, Methods: GET
INFO 05-10 11:48:51 [launcher.py:36] Route: /ping, Methods: GET, POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /tokenize, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /detokenize, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /v1/models, Methods: GET
INFO 05-10 11:48:51 [launcher.py:36] Route: /version, Methods: GET
INFO 05-10 11:48:51 [launcher.py:36] Route: /v1/chat/completions, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /v1/completions, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /v1/embeddings, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /pooling, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /score, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /v1/score, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /v1/audio/transcriptions, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /rerank, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /v1/rerank, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /v2/rerank, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /invocations, Methods: POST
INFO 05-10 11:48:51 [launcher.py:36] Route: /metrics, Methods: GET
INFO: Started server process [23290]
INFO: Waiting for application startup.
INFO: Application startup complete.
这个服务器可以像 OpenAI API 一样以相同的格式进行请求。例如,要列出模型:
curl -sS http://localhost:8000/v1/models | jq# 输出
{"object": "list","data": [{"id": "Qwen/Qwen2.5-1.5B-Instruct","object": "model","created": 1746802639,"owned_by": "vllm","root": "Qwen/Qwen2.5-1.5B-Instruct","parent": null,"max_model_len": 32768,"permission": [{"id": "modelperm-63355d89a63946e58de0095fa60cd62b","object": "model_permission","created": 1746802639,"allow_create_engine": false,"allow_sampling": true,"allow_logprobs": true,"allow_search_indices": false,"allow_view": true,"allow_fine_tuning": false,"organization": "*","group": null,"is_blocking": false}]}]
}
6.1 使用 vLLM 的 OpenAI Completions API
你可以使用输入提示词查询模型:
curl -sS http://localhost:8000/v1/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen/Qwen2.5-1.5B-Instruct","prompt": "San Francisco is a"}' | jq# 输出
{"id": "cmpl-8bca6ac3579a41178ae70c6c5ba1d6c6","object": "text_completion","created": 1746802658,"model": "Qwen/Qwen2.5-1.5B-Instruct","choices": [{"index": 0,"text": " city in the state of California, United States. It is the county seat of","logprobs": null,"finish_reason": "length","stop_reason": null,"prompt_logprobs": null}],"usage": {"prompt_tokens": 4,"total_tokens": 20,"completion_tokens": 16,"prompt_tokens_details": null}
}
由于服务器与 OpenAI API 兼容,你也可以直接使用 openai 的 Python SDK 进行请求。
from openai import OpenAI# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)
completion = client.completions.create(model="Qwen/Qwen2.5-1.5B-Instruct",prompt="San Francisco is a")
print("Completion result:", completion)
执行以上代码的输出如下:
Completion result: Completion(id='cmpl-4b2b13ce66c24de3afc73ee67dc94607',
choices=[CompletionChoice(finish_reason='length', index=0, logprobs=None,
text=' city of contrasts. It has its share of luxury and wealth, but it also',
stop_reason=None, prompt_logprobs=None)], created=1746802708,
model='Qwen/Qwen2.5-1.5B-Instruct', object='text_completion', system_fingerprint=None,
usage=CompletionUsage(completion_tokens=16, prompt_tokens=4, total_tokens=20,
completion_tokens_details=None, prompt_tokens_details=None))
6.2 使用 vLLM 的 OpenAI Chat Completions API
vLLM 还支持 OpenAI 的 Chat Completions API。该 API 提供了一种更加动态、交互式的模型交流方式,支持往返对话并在聊天历史中保存上下文。这种方式特别适用于需要保持上下文连贯性或需要更详细解释的任务,能够让模型理解之前的对话内容,从而提供更加连贯、个性化的响应。
curl -sS http://localhost:8000/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen/Qwen2.5-1.5B-Instruct","messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Who won the world series in 2020?"}]}' | jq# 输出
{"id": "chatcmpl-ff58ca762837455e8388a033245dc254","object": "chat.completion","created": 1746802744,"model": "Qwen/Qwen2.5-1.5B-Instruct","choices": [{"index": 0,"message": {"role": "assistant","reasoning_content": null,"content": "The New York Yankees won the World Series in 2020, defeating the Tampa Bay Rays in seven games.","tool_calls": []},"logprobs": null,"finish_reason": "stop","stop_reason": null}],"usage": {"prompt_tokens": 31,"total_tokens": 56,"completion_tokens": 25,"prompt_tokens_details": null},"prompt_logprobs": null
}
你同样可以使用 OpenAI 的 Python SDK 进行请求。
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)chat_response = client.chat.completions.create(model="Qwen/Qwen2.5-1.5B-Instruct",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Tell me a joke."},]
)
print("Chat response:", chat_response)
响应如下:
Chat response: ChatCompletion(id='chatcmpl-3ba198d6ca6649ea8e621d6e51abc30a',
choices=[Choice(finish_reason='stop', index=0, logprobs=None,
message=ChatCompletionMessage(content="Sure, here's one for you:\n\nWhy couldn't the bicycle stand up by itself?\n\nBecause it was two-tired!",
refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[],
reasoning_content=None), stop_reason=None)], created=1746802826, model='Qwen/Qwen2.5-1.5B-Instruct',
object='chat.completion', service_tier=None, system_fingerprint=None,
usage=CompletionUsage(completion_tokens=26, prompt_tokens=24, total_tokens=50,
completion_tokens_details=None, prompt_tokens_details=None), prompt_logprobs=None)
7 vLLM 在使用 GPU 和 CPU 后端时的性能对比
CPU 后端与 GPU 后端在性能上存在显著差距,因为 vLLM 的架构最初是专为 GPU 优化设计的。若使用 CPU 后端,需要进行一系列优化以提升其运行效率。此外,GPU 拥有更强的并行计算能力,在大语言模型推理任务中相较于 CPU 更具优势。下面我们将简要对比 vLLM 在使用 CPU 和 GPU 后端时的推理性能差距。
当前进行测试的服务器配置参数如下:
- CPU:32 vCPU
- 内存:188 GiB
- GPU:NVIDIA A10
客户端使用以下命令循环向 vLLM 服务器发送请求:
for i in {1..100}; doecho "Request: $i"curl -sS http://localhost:8000/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen/Qwen2.5-1.5B-Instruct","messages": [{"role": "user", "content": "Tell me a joke"}]}'echo ""
done
vLLM 在 CPU 后端下的启动命令如下:
vllm serve Qwen/Qwen2.5-1.5B-Instruct
vLLM CPU 后端每秒生成的 token 数大概在 10 几个左右。
INFO 05-10 11:54:24 [metrics.py:486] Avg prompt throughput: 18.1 tokens/s, Avg generation throughput: 12.4 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
INFO 05-10 11:54:29 [metrics.py:486] Avg prompt throughput: 6.5 tokens/s, Avg generation throughput: 15.1 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
在 GPU 后端中,vLLM 默认启用 Prefix Caching(v1 版本默认启用,v0 默认禁用),以提升推理性能;而在 CPU 后端中,该功能默认关闭。为确保对比的公平性,添加 --no-enable-prefix-caching 参数手动禁用该功能。
vllm serve Qwen/Qwen2.5-1.5B-Instruct --no-enable-prefix-caching
vLLM GPU 后端每秒生成的 token 数大概在 130 几个左右,性能大概是 CPU 后端的 10 倍左右。
INFO 05-11 11:31:38 [loggers.py:111] Engine 000: Avg prompt throughput: 135.3 tokens/s, Avg generation throughput: 108.7 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
INFO 05-11 11:31:48 [loggers.py:111] Engine 000: Avg prompt throughput: 135.3 tokens/s, Avg generation throughput: 108.7 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
总结
本文系统介绍了高性能 LLM 推理框架 vLLM 的部署实践,涵盖环境准备、GPU/CPU 后端配置、离线推理与在线推理部署等环节。最后通过实际测试,深入比较了两种后端在推理吞吐量和响应速度方面的性能差异。
欢迎关注





