需求背景
网盘面向大量C端用户 1000w用户 DAU 20% 每天10次
QPS: 1000w * 0.2 * 10 / 100k = 500
峰值估计:500 * 5 = 2500
功能需求
支持上传,下载,多端共同在线编辑,数据冲突处理
非功能需求
1.latency 20s左右
2.可用性与一致性,可以是弱后版本的,先保障可用性
3.扩展性,大量C端用户
4.稳定性 多副本,raft之类的
架构设计
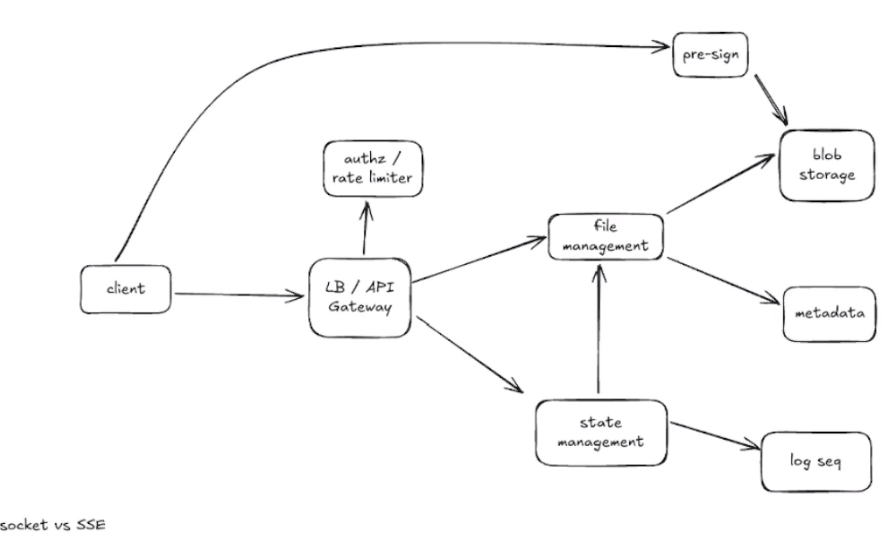
fileMeta:1.file_id 2.owner_id 3.file_type 4. create_time 5.update_time 6. isdelete 7.chunk_ids (一对多),8. access url 9.last_access_time
chunk: chunk_id, chunk_size, file_id, create_time, updatetime, isDelete, md5
冲突更新 first commit wins, 或者保留两份交给用户修改
statement的事件感知,推送客户端 long pull, websocket, sse,生态兼容与时间
版本回退,压缩 log seq
md5是不是重复了,如何重复了可以节省空间
冷热分离,数据归档
md5校验重组和传输过程
1.冷数据归档事件实践
冷数据归档事件实践总结
冷数据归档是优化存储成本、提升数据库性能的关键技术手段,其实践需结合业务场景和技术方案综合设计。以下是基于行业实践的技术要点总结:
一、归档必要性
-
业务场景驱动
- 高频增长的业务数据(如票务系统每月新增300G数据)导致传统数据库性能瓶颈,冷数据归档可释放主库压力并提升查询效率1。
- 合规性要求长期保留历史数据时,归档可避免主库因数据膨胀导致的运维复杂度增加15。
-
性能与成本平衡
- 冷数据迁移至低成本存储介质(如HDD或对象存储)可降低存储成本,最高达原成本的5%1。
二、技术实现方案
-
分层存储架构
- 热数据层:使用SSD或内存存储高频访问数据,保障实时性3。
- 冷数据层:采用HDD、纠删码(EC)存储或对象存储(如S3),结合数据压缩和去重技术减少空间占用37。
-
自动化生命周期管理
- 基于访问频率或时间戳自动分类数据(如6个月未访问数据标记为冷数据)5。
- 通过定时任务(如MySQL事件调度器)或分布式数据库内置功能(如PolarDB-X)实现定期归档25。
-
数据迁移与查询兼容性
- 归档表需与原表结构一致,并提供统一查询接口,确保业务无感知访问归档数据5。
- PolarDB-X支持通过冷数据源配置实现透明化归档查询2。
三、典型实践步骤(以MySQL/PolarDB-X为例)
-
数据分类与策略制定
sqlCopy Code
-- 示例:筛选6个月未访问的冷数据 SELECT * FROM orders WHERE last_accessed < NOW() - INTERVAL 6 MONTH; -
归档执行
- MySQL:通过事件调度器定期迁移数据至归档表5。
- PolarDB-X:创建冷数据源并配置归档规则,例如:
bashCopy Code
# 创建冷数据源 CREATE STORAGE cold_storage TYPE='LOCAL_DISK' ...
-
存储介质优化
- 使用低成本存储池(如Ceph bulk存储池)并启用压缩功能7。
四、成本优化策略
- 压缩与去重:冷数据采用高压缩比算法(如ZSTD)和去重技术降低存储占用37。
- 对象存储选择:利用云厂商S3兼容存储实现弹性扩容和按需付费8。
五、注意事项
- 备份与恢复流程:归档前需制定备份策略,确保灾难恢复时RTO/RPO可控6。
- 数据一致性:归档过程中需保证事务完整性,避免数据丢失或损坏8。
六、未来趋势
- 智能化工具:结合机器学习预测数据访问模式,动态调整归档策略4。
- 云原生集成:通过容器化和微服务架构实现弹性归档能力8。
通过以上实践,企业可有效平衡数据存储成本与系统性能,适应业务长期发展需求
冷数据归档事件实践总结
冷数据归档是优化存储成本、提升数据库性能的关键技术手段,其实践需结合业务场景和技术方案综合设计。以下是基于行业实践的技术要点总结:
一、归档必要性
-
业务场景驱动
- 高频增长的业务数据(如票务系统每月新增300G数据)导致传统数据库性能瓶颈,冷数据归档可释放主库压力并提升查询效率1。
- 合规性要求长期保留历史数据时,归档可避免主库因数据膨胀导致的运维复杂度增加15。
-
性能与成本平衡
- 冷数据迁移至低成本存储介质(如HDD或对象存储)可降低存储成本,最高达原成本的5%1。
二、技术实现方案
-
分层存储架构
- 热数据层:使用SSD或内存存储高频访问数据,保障实时性3。
- 冷数据层:采用HDD、纠删码(EC)存储或对象存储(如S3),结合数据压缩和去重技术减少空间占用37。
-
自动化生命周期管理
- 基于访问频率或时间戳自动分类数据(如6个月未访问数据标记为冷数据)5。
- 通过定时任务(如MySQL事件调度器)或分布式数据库内置功能(如PolarDB-X)实现定期归档25。
-
数据迁移与查询兼容性
- 归档表需与原表结构一致,并提供统一查询接口,确保业务无感知访问归档数据5。
- PolarDB-X支持通过冷数据源配置实现透明化归档查询2。
三、典型实践步骤(以MySQL/PolarDB-X为例)
-
数据分类与策略制定
sqlCopy Code
-- 示例:筛选6个月未访问的冷数据 SELECT * FROM orders WHERE last_accessed < NOW() - INTERVAL 6 MONTH; -
归档执行
- MySQL:通过事件调度器定期迁移数据至归档表5。
- PolarDB-X:创建冷数据源并配置归档规则,例如:
bashCopy Code
# 创建冷数据源 CREATE STORAGE cold_storage TYPE='LOCAL_DISK' ...
-
存储介质优化
- 使用低成本存储池(如Ceph bulk存储池)并启用压缩功能7。
四、成本优化策略
- 压缩与去重:冷数据采用高压缩比算法(如ZSTD)和去重技术降低存储占用37。
- 对象存储选择:利用云厂商S3兼容存储实现弹性扩容和按需付费8。
五、注意事项
- 备份与恢复流程:归档前需制定备份策略,确保灾难恢复时RTO/RPO可控6。
- 数据一致性:归档过程中需保证事务完整性,避免数据丢失或损坏8。
六、未来趋势
- 智能化工具:结合机器学习预测数据访问模式,动态调整归档策略4。
- 云原生集成:通过容器化和微服务架构实现弹性归档能力8。
通过以上实践,企业可有效平衡数据存储成本与系统性能,适应业务长期发展需求。
归档表需与原表结构一致,并提供统一查询接口,确保业务无感知访问归档数据 这步怎么做的
![]()
DeepSeek-R1满血版 回答完成
深度思考完成 用时12秒,搜索全网28篇资料
在冷数据归档实践中,实现归档表与原表结构一致并提供统一查询接口,需通过以下步骤完成:
一、归档表结构一致性设计
-
表结构克隆
- 使用与原表相同的字段定义、索引和约束创建归档表,例如通过SQL语句克隆空表结构:
sqlCopy Code
(此方法仅复制表结构,不迁移数据2)CREATE TABLE archive_table AS SELECT * FROM main_table WHERE 1=0;
- 使用与原表相同的字段定义、索引和约束创建归档表,例如通过SQL语句克隆空表结构:
-
分布式场景兼容
- 在PolarDB-X等分布式数据库中,需同步主表的分区规则、索引类型(如列存索引CCI)到归档表,避免因结构差异导致查询异常8。
二、统一查询接口实现
-
视图或中间件路由
- 视图层封装:通过数据库视图将主表与归档表合并查询,例如:
sqlCopy Code
CREATE VIEW combined_view AS SELECT * FROM main_table UNION ALL SELECT * FROM archive_table; - 中间件路由:利用分布式数据库的透明路由功能(如PolarDB-X冷数据源配置),自动将查询分发到主表或归档表18。
- 视图层封装:通过数据库视图将主表与归档表合并查询,例如:
-
查询优化策略
- 在归档表上建立与原表一致的索引,确保查询性能不因数据迁移而下降3。
- 针对高频查询字段(如时间范围字段)优化归档表索引,减少跨表查询时的性能损耗8。
三、数据迁移与一致性保障
-
分批迁移降低风险
- 通过分批次执行
INSERT INTO archive_table SELECT ...和DELETE FROM main_table操作,避免单次迁移数据量过大导致的锁表或事务超时25。
- 通过分批次执行
-
事务完整性控制
- 在迁移过程中启用事务,确保数据从主表删除前已成功写入归档表,避免数据丢失5。
- 采用低峰期执行迁移任务,降低对业务实时操作的影响6。
四、业务无感知设计要点
-
前端接口透明化
- 保持业务代码中原有的SQL查询语句不变,通过数据库层(视图或路由规则)屏蔽底层数据分布细节18。
-
动态数据访问策略
- 结合冷热分离规则,优先查询主表,仅当数据不存在时自动查询归档表,例如:
sqlCopy Code
SELECT * FROM main_table WHERE id=100 UNION ALL SELECT * FROM archive_table WHERE id=100 LIMIT 1;
- 结合冷热分离规则,优先查询主表,仅当数据不存在时自动查询归档表,例如:
-
兼容性测试
- 归档完成后验证业务场景(如历史订单查询、报表生成),确保联合查询结果与原表一致58。
五、典型实现案例(以PolarDB-X为例)
-
配置冷数据源
sqlCopy Code
-- 创建冷数据存储源 CREATE STORAGE cold_storage TYPE='OSS' ... -- 绑定归档规则 ALTER TABLE main_table SET ARCHIVE POLICY = 'AFTER 6 MONTHS' STORAGE cold_storage;(系统自动将过期数据迁移至OSS,并提供统一查询接口18)
-
查询示例
- 业务直接执行
SELECT * FROM main_table WHERE create_time < '2024-01-01',数据库自动路由到主表或归档表8。
- 业务直接执行
通过以上设计,可确保业务层无需感知数据存储位置差异,同时满足归档数据的低成本存储与高效访问需求12。
在冷数据归档实践中,实现归档表与原表结构一致并提供统一查询接口,需通过以下步骤完成:
一、归档表结构一致性设计
表结构克隆
使用与原表相同的字段定义、索引和约束创建归档表,例如通过SQL语句克隆空表结构:
sql
Copy Code
CREATE TABLE archive_table AS SELECT * FROM main_table WHERE 1=0;
(此方法仅复制表结构,不迁移数据)
分布式场景兼容
在PolarDB-X等分布式数据库中,需同步主表的分区规则、索引类型(如列存索引CCI)到归档表,避免因结构差异导致查询异常。
二、统一查询接口实现
视图或中间件路由
视图层封装:通过数据库视图将主表与归档表合并查询,例如:
sql
Copy Code
CREATE VIEW combined_view AS
SELECT * FROM main_table
UNION ALL
SELECT * FROM archive_table;
中间件路由:利用分布式数据库的透明路由功能(如PolarDB-X冷数据源配置),自动将查询分发到主表或归档表。
查询优化策略
在归档表上建立与原表一致的索引,确保查询性能不因数据迁移而下降。
针对高频查询字段(如时间范围字段)优化归档表索引,减少跨表查询时的性能损耗。
三、数据迁移与一致性保障
分批迁移降低风险
通过分批次执行INSERT INTO archive_table SELECT ...和DELETE FROM main_table操作,避免单次迁移数据量过大导致的锁表或事务超时。
事务完整性控制
在迁移过程中启用事务,确保数据从主表删除前已成功写入归档表,避免数据丢失。
采用低峰期执行迁移任务,降低对业务实时操作的影响。
四、业务无感知设计要点
前端接口透明化
保持业务代码中原有的SQL查询语句不变,通过数据库层(视图或路由规则)屏蔽底层数据分布细节。
动态数据访问策略
结合冷热分离规则,优先查询主表,仅当数据不存在时自动查询归档表,例如:
sql
Copy Code
SELECT * FROM main_table WHERE id=100
UNION ALL
SELECT * FROM archive_table WHERE id=100 LIMIT 1;
兼容性测试
归档完成后验证业务场景(如历史订单查询、报表生成),确保联合查询结果与原表一致。
五、典型实现案例(以PolarDB-X为例)
配置冷数据源
sql
Copy Code
-- 创建冷数据存储源
CREATE STORAGE cold_storage TYPE='OSS' ...
-- 绑定归档规则
ALTER TABLE main_table
SET ARCHIVE POLICY = 'AFTER 6 MONTHS' STORAGE cold_storage;
(系统自动将过期数据迁移至OSS,并提供统一查询接口)
查询示例
业务直接执行SELECT * FROM main_table WHERE create_time < '2024-01-01',数据库自动路由到主表或归档表。
通过以上设计,可确保业务层无需感知数据存储位置差异,同时满足归档数据的低成本存储与高效访问需求。
2.long pull, websocket, sse,生态兼容与时间
长轮询(Long Polling)、WebSocket、SSE 的核心区别与生态兼容性总结
一、本质差异
-
长轮询(Long Polling)
- 本质:HTTP 轮询的优化版本,客户端发起请求后,服务器挂起直到数据更新或超时才响应,减少无效请求57。
- 通信模式:单向(客户端主动拉取),但通过挂起连接模拟“准实时”效果57。
-
WebSocket
- 本质:基于 TCP 的全双工协议,通过 HTTP 握手升级建立持久连接,支持双向实时通信37。
- 通信模式:双向(客户端与服务器均可主动发送数据),适用于高实时性交互场景38。
-
SSE(Server-Sent Events)
- 本质:基于 HTTP 的单向数据流协议,服务器主动向客户端推送数据,客户端仅需建立一次连接35。
- 通信模式:单向(仅服务器向客户端推送),适合事件驱动型场景35。
二、生态兼容性对比
| 技术 | 浏览器兼容性 | 协议依赖 | 移动端支持 |
|---|---|---|---|
| 长轮询 | 全浏览器支持(包括 IE)67 | 纯 HTTP | 良好,兼容所有移动设备6 |
| WebSocket | 现代浏览器支持,部分老版本 Android 不兼容78 | 独立 TCP 协议(HTTP 升级) | 主流支持,需处理兼容性78 |
| SSE | 支持 HTML5 的浏览器,IE 不支持58 | HTTP 长连接流 | iOS/Android 主流支持58 |
三、时间特性与性能
-
延迟
- 长轮询:延迟中等(取决于数据更新频率)7。
- WebSocket:延迟极低(全双工,无需重复握手)37。
- SSE:延迟低(单向流式推送),但弱于 WebSocket37。
-
资源消耗
- 长轮询:服务器需维护挂起连接,高并发时资源压力大57。
- WebSocket:连接建立后开销小,适合高频交互38。
- SSE:轻量级,服务器单向推送,适合低频事件场景35。
四、适用场景与选择建议
-
长轮询
- 场景:兼容性要求高、实时性要求中等的通知类应用(如配置中心更新)57。
- 缺点:服务器资源占用较高,不适合大规模并发57。
-
WebSocket
- 场景:双向实时交互(如聊天室、在线游戏、协同编辑)37。
- 缺点:实现复杂,需处理连接状态与兼容性问题78。
-
SSE
- 场景:服务器单向推送(如实时新闻、股票行情、日志流)35。
- 优势:自动重连、轻量级,适合 HTTP 生态集成35。
总结
- 协议本质:长轮询是 HTTP 的变种,WebSocket 是独立协议,SSE 是 HTTP 流37。
- 核心差异:通信方向(单向/双向)、实时性、资源开销35。
- 选型原则:根据实时性需求、技术栈兼容性、服务器资源综合决策57。
3.md5在判断什么完整性
MD5在文件分片传输场景中用于验证分片数据完整性及整体文件一致性:每个传输分片生成独立的MD5校验值,接收方逐片比对哈希值确保分片数据无损坏;全部分片传输完成后,重新合并文件并计算整体MD5值,与源文件哈希匹配则证明分片顺序正确且合并无误,从而同时保障分片级与文件级的完整性,防止传输过程中的数据篡改或丢包问题。

)
感知机)


