目录
- 一、背景
- 二、脚本方法
- 三、并行计算
一、背景
有3000份PDF需要OCR解析,原有的项目是用命令行来执行的。每次只能解析一个文件,速度很慢,赶不上项目进度要求。光是100份文件解析就要四五个小时了。最好就是能够最大化利用服务器的算力。
二、脚本方法
此脚本仍然是串行的方式,这里讲解如何来使用脚本。
1.将上述代码保存为 run.sh。
2.添加可执行权限:
chmod +x run.sh
3.运行脚本:
./run.sh
#!/bin/bash# 定义 GPU ID 列表
gpus_id=(2 3 4 5 6 7)# 遍历 GPU ID 列表
for i in "${gpus_id[@]}"; doexport CUDA_VISIBLE_DEVICES=$ipython exec.py --num $i
done
这里脚本会给函数传入一个参数
在函数中,导入获取参数的模块
import argparse
将初始的数据文件等分成10份,用args来获取外部给的参数,并切换到对应的第几份文件上
# 将PDF文件列表分成10份
num_splits = 10
split_size = len(pdf_files) // num_splits
pdf_file_splits = [pdf_files[i:i+split_size] for i in range(0, len(pdf_files), split_size)]# 如果有剩余文件,添加到最后一份
if len(pdf_files) % num_splits != 0:pdf_file_splits[-1].extend(pdf_files[num_splits * split_size:])# 解析命令行参数,选择处理哪一份
parser = argparse.ArgumentParser(description='PDF批量处理')
parser.add_argument('--num', type=int, default=0, help='处理第几份文件(0-9)')
args = parser.parse_args()# 选择要处理的文件列表
pdf_files = pdf_file_splits[args.num]
三、并行计算
之前的还是串行,是因为在for循环中,每次执行下一个python文件都需要等待上一批的处理做完,这里可以有一种异步的方式,就是选定了GPU张数之后让命令在后台运行,这样就不用等待,会迅速接下一个python文件的执行。每次执行python文件都是新开一个进程用不一样的GPU环境,互相不冲突。
#!/bin/bash# 定义 GPU ID 列表
gpus_id=(2 3 4 5 6 7)# 并行运行在不同的 GPU 上
for i in "${gpus_id[@]}"; doexport CUDA_VISIBLE_DEVICES=$ipython exec.py --num $i & # 添加 & 使命令在后台运行
done# 等待所有后台进程完成
waitecho "所有 GPU 任务已完成"
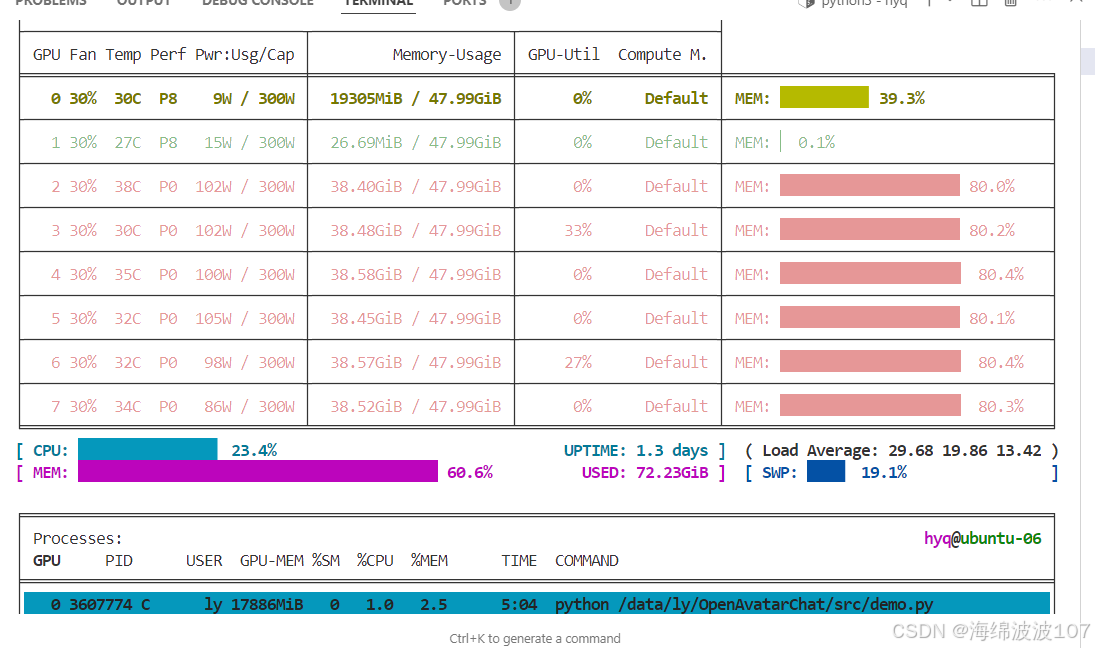

都跑起来了,不浪费一点两台服务器的算力资源,全是中国红。

)
感知机)


