前言
c++的出现主要最初是为了解决c语言的不足,但随着之后逐渐的发展,成为了一门成熟的语言。因为,c++最初是为了解决c语言的不足。所以,在c++入门学习主要了解c++解决那些c语言的不足。
命名空间namespace
c语言很大的一个缺点就是,他的很多库里的函数名和我们命名的变量等数据的名字出现了冲突。而前,很多时候我们需要多个文件,这多个文件不同的变量命很容易出现名字的冲突,这就很难受。所以,c++提出了一个新的概念命名空间,它的关键词是namspace。他是独立于全局域和局部域的一个独立区域。这个域是封装起来的。就是说,如果你没有展开这部分域,它里面的成员你是无法使用的。编译器不会主动取寻找。除非你指定了这个域。
namespace cll
{int x;int Add(int a,int b){return a + b;}struct SListNode{int data;struct SListNode* next;};namespace bdd{int x;}
}//这里不需要分号这里就是一个命名空间的创建,命名空间的成员可以是变量,函数,自定义类型,还可以是命名空间,也就是说一个命名空间里面还可以有很多其他命名空间。
展开域
展开域的关键词是using,
namespace cll
{int x;int Add(int a,int b){return a + b;}struct SListNode{int data;struct SListNode* next;};namespace bdd{int x;}
}//这里不需要分号
using namespace cll;int main()
{int ret = Add(1, 2);printf("%d", ret);return 0;
}
这里如果你没有展开域,你是不能使用这个域里面的成员函数的。如果你分要使用这个成员函数,你可以指定域。
域作用限制符 ::
域作用限制符 ::使用
域名 + ::
如果前面没有域命,那就是全局域。
namespace cll
{int x;int Add(int a,int b){return a + b;}struct SListNode{int data;struct SListNode* next;};namespace bdd{int x;}
}//这里不需要分号
//using namespace cll;int main()
{int ret = cll::Add(1, 2);printf("%d", ret);return 0;
}像上面的这个代码就没有展开域,但是他还是能正常运行。这是因为他指定了域。
缺省参数
概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实 参则采用该形参的缺省值,否则使用指定的实参。缺省值必须是常量或者全局变量。
缺省参数分类
全缺省参数
int Add(int a = 1,int b = 2){return a + b;}半缺省参数(只有一部分参数缺省,不是一半参数只有一部分缺省)
int Add(int a = 1,int b)
{return a + b;
}使用
半缺省参数必须从右到左,不能跳着给。这是因为传参就是从左到右传。
int Add(int a, int b = 1, int c = 2)
{return a + b;
}
int main()
{int ret = Add(2,3); return 0;
}可不敢跳着传值,c++没有这样的语法,这时语法规定
int Add(int a = 1, int b = 1, int c = 2);
{return a + b;
}
int main()
{int ret = Add(1, , 3);return 0;
}注意
声明和定义里不能都有缺省参数,声明和定义同时出现,就像如图的代码情况,缺省参数定义在声明中。
int add(int a , int b );
int main()
{int ret = add();printf("%d ", ret);
}
int add(int a = 1, int b = 2)
{return a + b;
}这个是编译原理,当编译到调用函数,跳转到声明,声明里却没有缺省参数。就会编译错误。这是一个编译顺序问题。
函数重载
概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这 些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型 不同的问题
这里和c语言的编译原理有点不同。
c++的编译和c++编译大致一样,但是在细节上还是有区别的。
这里对上面三种类型就不多做介绍了,很简单。大家,看下面这个代码,有语法错误吗?
int add(int a = 1, int b = 2)
{return a + b;
}
int add()
{return 0;
}
int main()
{int ret = add();printf("%d ", ret);
}有语法错误。错误是调用不明确。不是函数重载的问题。这里,是由参数的,缺省参数也是参数。
大家要对于概念明确,否则就会犯这些错误。
为什么c语言不支持重载,而c++支持呢,c++如何支持呢?
c语言在编译时会把声明当作一个承诺,当链接时回去兑现承诺。总结来就是一句话,声明是一个承诺,链接兑现承诺。
c++也是这个原理,但不同之处是c语言在编译时生成的汇编指令,是只和函数名相关。c++则是和参数个数 或 类型 或 类型顺序有关。也就是说他们两个函数名修饰规则不同。
流输入和流输出
流操作符
输入 <<
输出 >>
流输入
cin<< ,就相当于scanf
流输出
cout>>,就相当于printf
注意
使用cin和cout要打开标准域std,这个域在头文件<iostream>,这两个不是函数,而是一个对象。这里先简单理解,要讲清楚比较复杂
引用
c++,提出了一种新概念,引用: 替代了实体,引用和实体共用一块内存,引用的改变会影响实体,实体的改变也会影响引用。(引用不会开辟内存,这大大提高了效率)(大对象/深拷贝类对象)
它的出现就是为了解决c语言指针的繁琐。相信刚学c语言的人会发现指针的使用很复杂。并前还很容易出现错误,尤其是野指针问题。所以我们的本贾尼老爷子(c++之父),就提出了引用。但是,在底层编译器看来他还是指针,只不过让你的使用起来变得很方便,编译器变忙了。
引用的规则
1.引用不能更改指向
2.引用必须初始化 ,int& b;这种写法是错误的
3.一个实体可以有多个引用
int a=0;
int& b=a;
引用的作用
1.做输出型参数(形参是实参的别名)(提高效率)(大对象/深拷贝类对象)
:例如swap函数
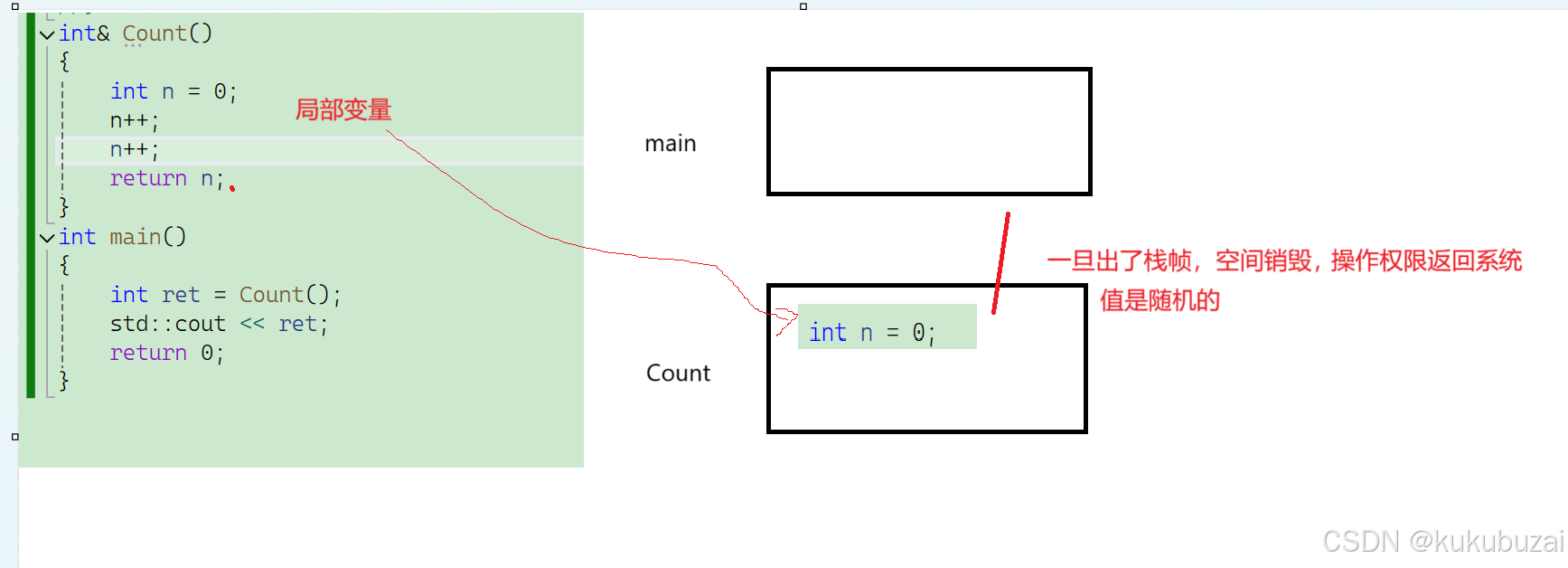
2.做返回值
:提高效率
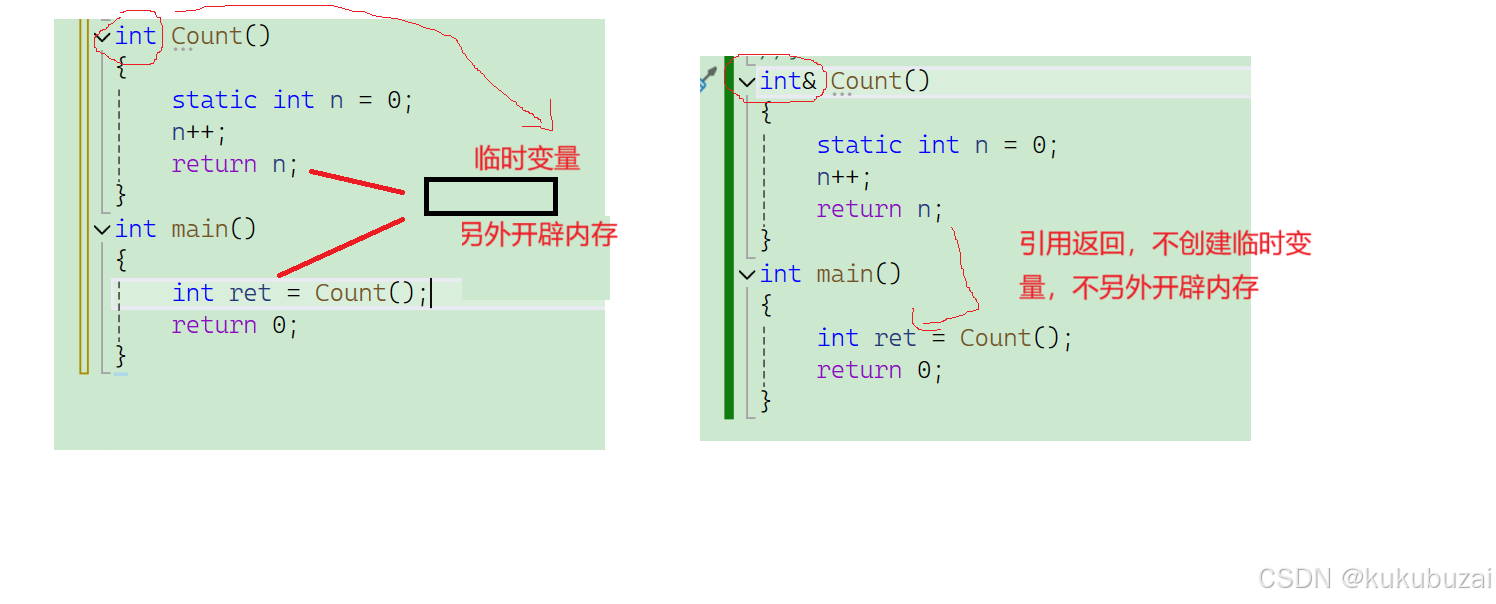
:引用返回注意域
注意
在引用时权限不能放大,可以缩小或者平移。
大家看看这个代码,有错误吗?
int main()
{double d = 1.11;int a = d;int& b = d;}错误是权限放大,注意截断时会产生一个临时变量,这个临时变量具有常性。所以这里的权限放大了。要注意函数返回值时和强制性转换时都会产生临时变量。
int fun()
{static int x = 0;return x;
}
int main()
{int& ret = fun(); //错误const int& ret = fun();//正确}上面这个代码就体现了返回值时会产生临时变量,并前临时变量是具有常性的。
auto关键字
auto自动推导类型,解决使用c语言编写代码时,会遇到类型不明确的和类型过于长时的情况。所以,auto诞生。
int main()
{int a = 0;int b = a;auto c = a;auto d = 1 + 1.11;//typeid 关键字 获取类型cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;
}注意
auto不可以做参数,因为他无法推导形参的实际类型
auto不可以用来声明数组
范围for(语法糖)
注意范围for循环范围是确定的,所以不能传指针
#include <iostream>
using namespace std;
int main()
{int arr[] = { 1,2,3,4,5 };for (auto e : arr){cout << e << " ";}
}int main()
{int a = 0;int b = a;auto c = a;auto d = 1 + 1.11;//typeid 关键字 获取类型cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;int arr[] = { 1,2,3,4,5 };//不能修改数据 改变的是e不是数组for (auto e : arr){e *= 2;}for (auto e : arr){cout << e << " ";}cout << endl;for (auto& e : arr){e *= 2;}for (auto e : arr){cout << e << " ";}
}他大大减少了我们遍历数组时的代码
内联函数
内联函数就是在函数的前面加上inline
内联函数的出现是为了解决c语言宏替换的麻烦,相信使用宏替换对于刚开始学习c语言的人来说,肯定会掉过很多坑,比如括号的少加。所以,我们的祖师爷也想到了这个问题。这么会这么麻烦呢?因此,内联函数诞生。
他和宏一样是替换,他不会占用内存。而是直接展开指令。所以,他没有开销,执行很快。但要注意,他也不能乱用。由于他是直接展开展开指令,所以这导致他如果过于长的时候,又被调用了很多次。那么这个代码的指令就会成倍增加。这就会导致你链接出来的可执行程序安装包会非常大。所以,一般情况下编译器会对内联函数的长度有要求。一般不超过3句。并且,使用内联函数是对编译器的一个申请,编译器很有可能会忽略掉你这个申请(代码过长时)
注意
递归可不能使用内联函数。否则你的代码指令会变得超级多,导致性能变差。
空指针NULL
c语言的NULL实际上是一个宏,它是直接被替换为0的。所以在有些使用的时候就会出现歧义。但是为了兼容c语言又不能删除,所以,c++里使用nullptr代替我们NULL。你可以把nullptr理解为是一个0强制性转化为了指针。




