3.1神经网络示例
浅神经网络是函数y = f[x,ϕ],其参数将多变量输入x映射到多变量输出y。我们使用示例网络f[x,ϕ]来介绍主要思想,该网络将标量输入x映射到标量输出y,并具有十个参数ϕ = {Ф,Ф
,Ф
,Ф
,θ
,θ
,θ
,θ
,θ
,θ
}:
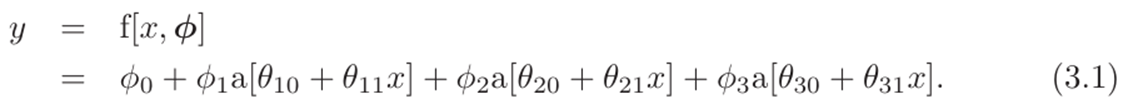
我们可以把计算分成三部分:首先我们计算输入数据的三个线性函数(θ+ θ
x, θ
+ θ
x和θ
+ θ
x)。其次我们通过激活函数a[•]传递这三个结果。最后我们用Ф
、Ф
和Ф
对三个结果激活进行加权,将它们相加并添加偏移量Ф
。
激活函数a[•]有很多可能性,但最常见的选择是整流线性单元也称为ReLU:
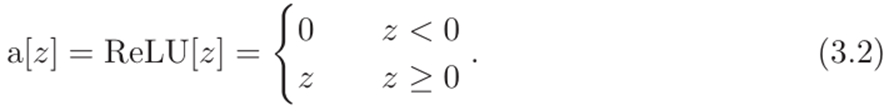
当输入为正时返回输入,否则返回零。
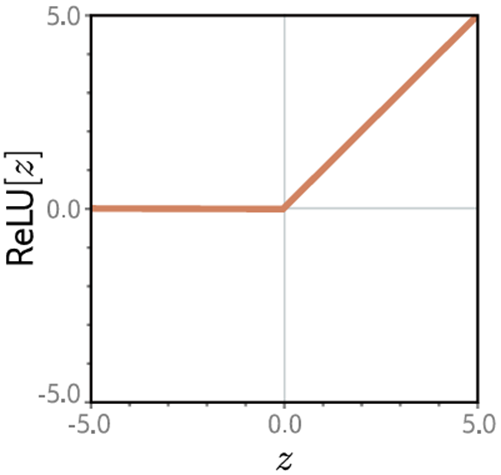
图3.1整流线性单元(ReLU)。如果输入小于零,这个激活函数返回零,否则返回输入不变。换言之,它将负值剪辑为零。激活函数还有许多选择,但ReLU是最常用也最易理解的。
3.1.1神经网络直觉
实际上方程3.1表示的是一组连续分段线性函数(图3.2),最多有四个线性区域。现在我们分解方程3.1并说明为什么它描述了这个族。为了更容易理解,我们将函数分成两部分。首先,我们介绍中间量:

我们把h h
和h
作为隐藏单位。其次,我们通过将这些隐藏单元与线性函数组合来计算输出:
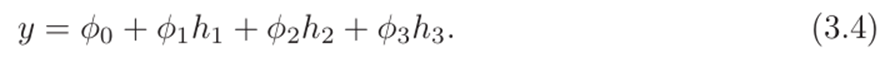
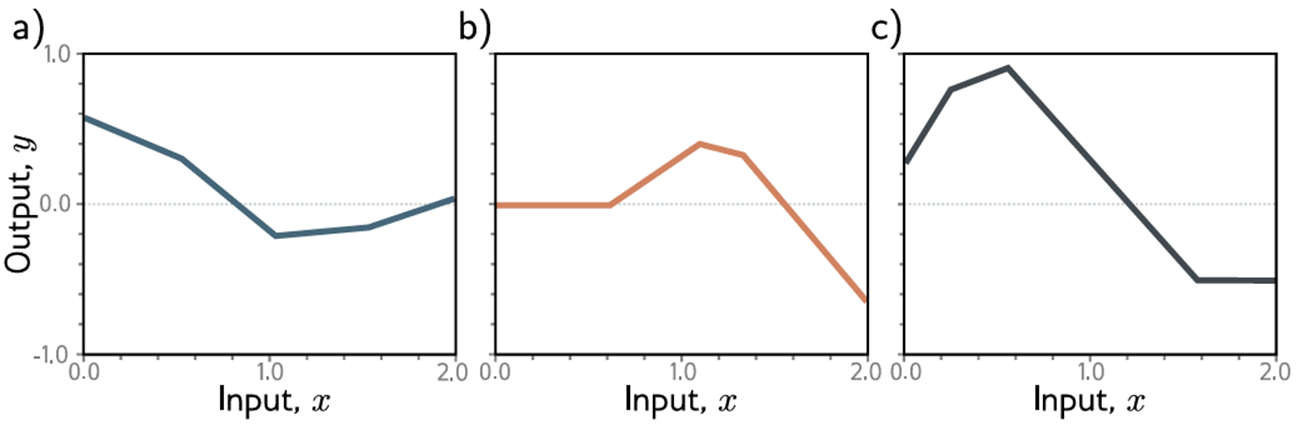
图3.2由方程3.1定义的Ф等十个参数中三种不同选择的函数。在每种情况下,输入/输出关系都是分段线性的。然而节点的位置、节点之间直线区域的斜率以及整体高度都不同。
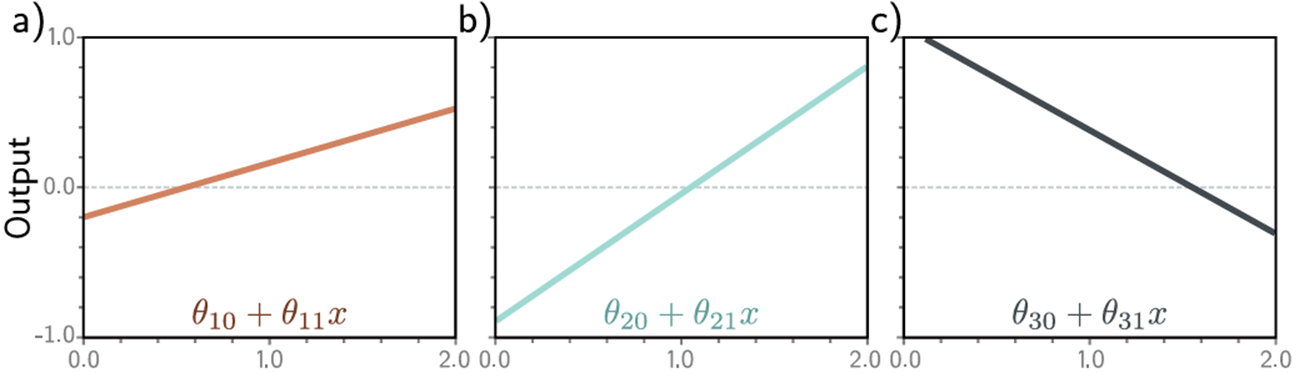
以上图为例a-c)输入x经过三个线性函数,每个函数有不同的y截距θ斜率为θ
3.1.2描述神经网络
我们一直在讨论一个有一个输入,一个输出和三个隐藏单元的神经网络。我们在图3.4a中可视化这个网络。输入在左边,隐藏单元在中间,输出在右边。每个连接代表十个参数中的一个。为了简化这种表示,我们通常不绘制截距参数,因此该网络通常如图3.4b所示。
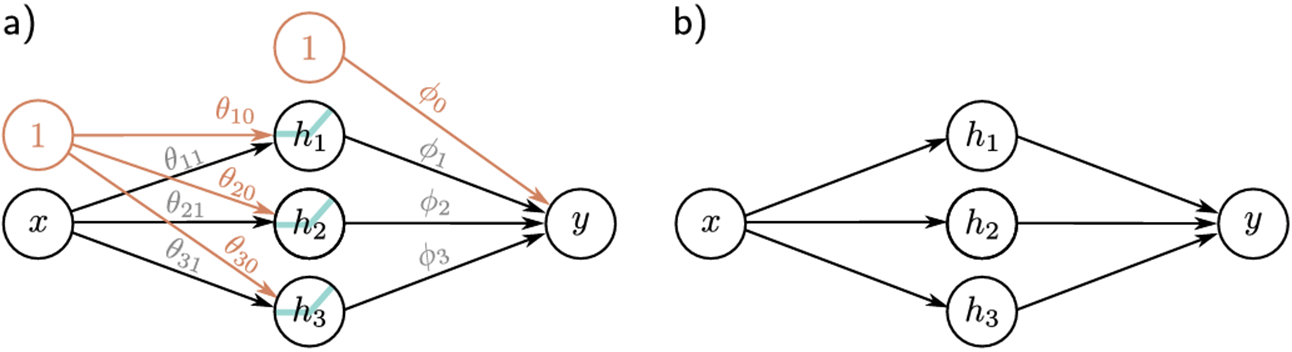
a)左侧为输入x,中间为隐藏单元h1、h2、h3,右侧为输出y。计算从左到右进行。输入用于计算隐藏单元,这些隐藏单元组合起来创建输出。十个箭头中的每一个都代表一个参数(橙色为截距,黑色为斜率)。每个参数乘以其源并将结果添加到其目标。
b) 省略了截距、ReLU函数和参数名,更简单描述网络。
3.2普遍近似定理
在上一小节中,我们介绍了一个示例神经网络,它具有一个输入、一个输出、ReLU激活函数和三个隐藏单元。现在让我们稍微推广一下,考虑有D个隐藏单位的情况,其中第D个隐藏单位是:

这些被线性组合起来产生输出:

浅层网络中隐藏单元的数量是衡量网络容量的一个指标。对于ReLU激活函数,具有D个隐藏单元的网络的输出最多有D个节点,因此是一个至多有D+1个线性区域的分段线性函数。随着隐藏单元的增加,模型可以逼近更复杂的函数。
事实上,只要有足够的隐藏单元,浅层网络就可以以任意精度描述任何连续1D函数。想象每次我们添加一个隐藏单元时,我们都会向函数添加另一个线性区域。随着区域越来越多,它们代表了函数的较小部分,这些部分越来越好地近似于一条线(图3.5)。普遍逼近定理证明了对于任意连续函数,存在一个能将该函数逼近到任意精度的浅层网络。
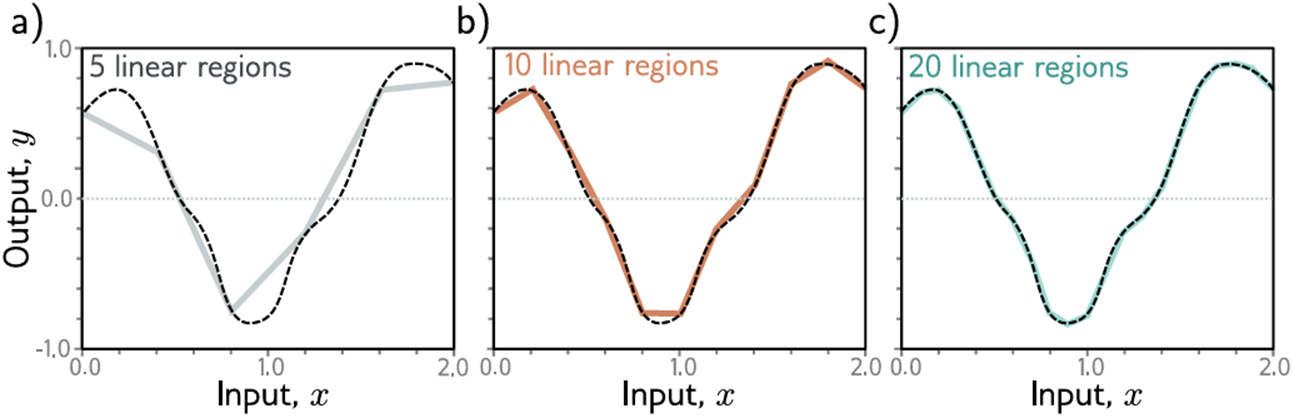
图3.5用分段线性模型逼近一维函数(虚线)。
a-c)随着区域数量的增加,模型越来越接近连续函数。
具有标量输入的神经网络为每个隐藏单元创建一个额外的线性区域。这个想法可以推广到i维函数。普遍逼近定理证明,只要有足够的隐藏单元,就存在一个浅层神经网络,它可以将定义在R的紧子集上的任意连续函数描述到任意精度。
3.3.1多变量输出可视化
为了将网络扩展到多元输出y,我们只需对每个输出使用隐藏单元的不同线性函数。因此,一个具有标量输入x、四个隐藏单元h1、h2、h3、h4和一个二维多元输出y = 的网络定义为:

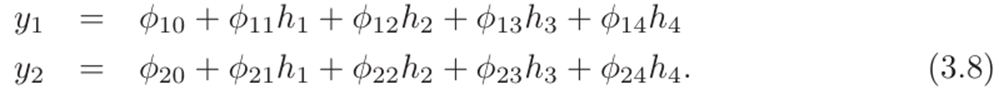 这两个输出是隐藏单元的两个不同的线性函数。
这两个输出是隐藏单元的两个不同的线性函数。
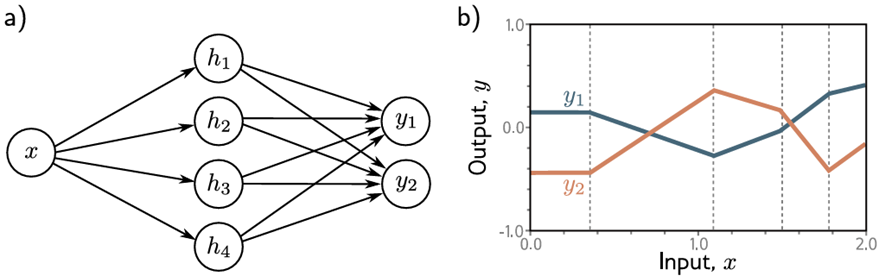
图3.6一个输入,四个隐藏单元,两个输出的网络。
a)网络结构可视化。
b)该网络产生两个分段线性函数和
。这些功能的四个“连接点”(在垂直虚线处)被限制在相同的位置,因为它们共享相同的隐藏单元,但斜率和整体高度可能不同。
3.3.2可视化多变量输入
为了处理多元输入x,我们扩展了输入和隐藏单元之间的线性关系。因此具有两个输入x=和标量输出y(图3.7)的网络可能有三个隐藏单元定义为:
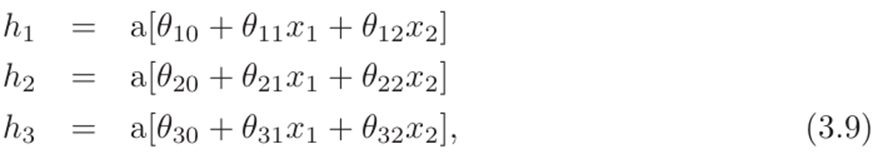
现在每个输入都有一个斜率参数。隐藏单元以通常的方式组合形成输出:
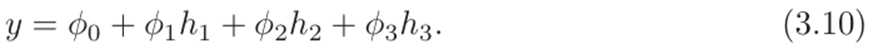
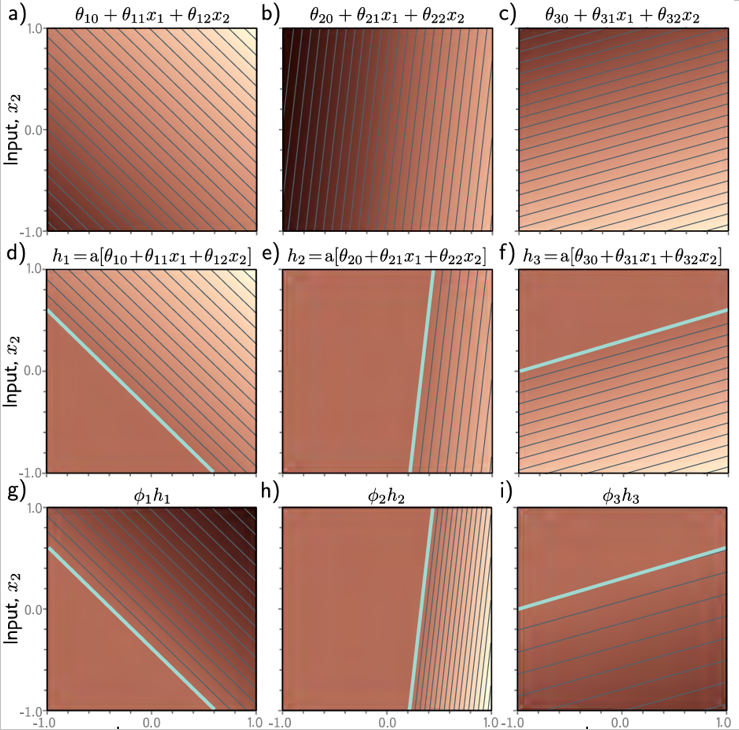
图3.8两个输入x=,三个隐藏单元h1,h2,h3,一个输出y (a-c)的网络处理,每个隐藏单元的输入是两个输入的线性函数,对应一个有向平面。亮度表示功能输出。
a)中亮度表示为θ+ θ
+θ
。细线是轮廓。
d-f)每个平面被ReLU激活函数剪辑,青色线相当于图3.3df中的“关节”。
g-i)然后对被剪切的平面进行加权,
j)与确定表面总体高度的偏移量相加。结果是一个由凸分段线性多边形区域组成的连续曲面。
3.4浅神经网络:一般情况
我们描述了几个浅层网络的例子,以帮助培养对它们如何工作的直觉。我们现在定义了一个浅层神经网络y = f[x, Ф]的一般方程,它将一个多维输入x∈R映射到一个多维输出y ∈R
,使用h ∈R
隐藏单元。每个隐藏单元计算如下:

这些被线性组合起来产生输出:

其中a[•]为非线性激活函数。模型参数d = {θ..,d..}。图3.11显示了一个具有三个输入、三个隐藏单元和两个输出的示例。
激活函数允许模型描述输入和输出之间的非线性关系,它本身必须是非线性的;如果没有激活函数或线性激活函数,那么从输入到输出的整体映射将被限制为线性。已经尝试了许多不同的激活函数(参见图3.13),但最常见的选择是ReLU(图3.1),它具有易于解释的优点。通过ReLU激活,网络将输入空间划分为凸多面体,这些凸多面体由ReLU函数中的“关节”计算的超平面相交定义。每个凸多面体包含一个不同的线性函数。对于每个输出,多面体是相同的,但是它们包含的线性函数可能不同。
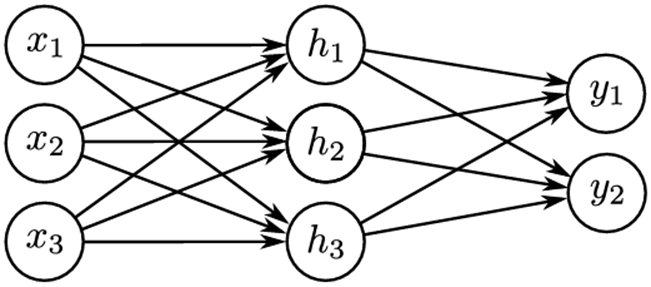
图3.11三输入二输出神经网络可视化。这个网络有二十个参数。有15个斜坡(箭头表示)和5个偏移(未显示)。
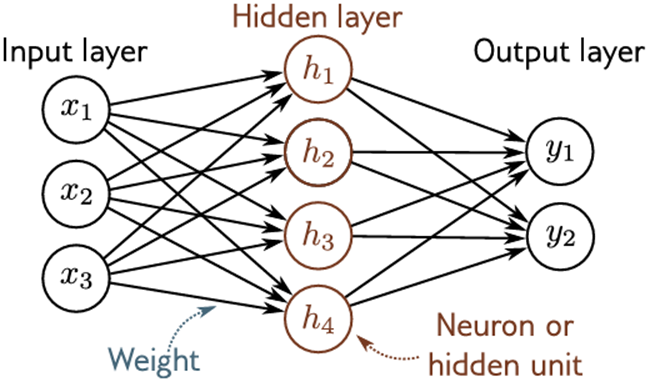
图3.12术语。浅层网络由输入层、隐藏层和输出层组成。每一层通过前向连接(箭头)连接到下一层。由于这个原因,这些模型被称为前馈网络。当一层中的每个变量都连接到下一层中的每个变量时,我们称之为全连接网络。每个连接代表底层方程中的一个斜率参数,这些参数称为权重。隐藏层中的变量被称为神经元或隐藏单元。输入到隐藏单元的值称为预激活,而隐藏单元的值(即在应用ReLU函数之后)称为激活。




