大模型时代下的文档智能 | 文档解析(大模型版)
- 为什么有文档智能
- 产品架构
- 产品能力
- 文档解析(大模型版)
- 在线体验
- API接口调用
- 添加依赖
- 身份认证
- 示例代码
- 资源使用情况
- 体验总结
- 在体验过程中是否得到足的产品内引导以及文档帮助?
- 产品功能是否满足预期?
- 针对大模型建设的场景,有哪些可以改进的地方?
- 文档解析-大模型版是否有与其他产品联动组合的可能?
对于文档智能这款产品,没有听过或者没有接触过、没有用过的小伙伴可能不太能猜到这样一款产品具体是做什么用的,那么下面先来从日常工作入手来简单引入一下文档智能的应用场景。
为什么有文档智能
文档智能,用官方的描述就是:【文档智能(Document Mind),基于阿里巴巴达摩院多年技术积累打造的多模态文档识别与理解引擎,为用户提供通用文档智能、行业文档智能和文档自学习能力,可满足各种场景下的智能文档处理需求。】
看了官方的描述,是不是对于文档智能有了一个大概的理解,主要是文档识别和理解这样的。其实在企业中,文档智能能发挥着重大的作用。【企业数据大多数都以文本、图片、扫描件、电子表格、在线文档、邮件等文档的形式存在,难以流通和处理,大量有价值的信息都被锁定在非结构化的文档中,无法充分发挥出数据价值。】这样是不是就对文档智能的认识更深刻了,下面我再来继续看看文档智能的产品架构。
产品架构
文档智能平台以非结构化文档为输入,依托文档智能预训练技术和产品,输出处理后的结构化数据。
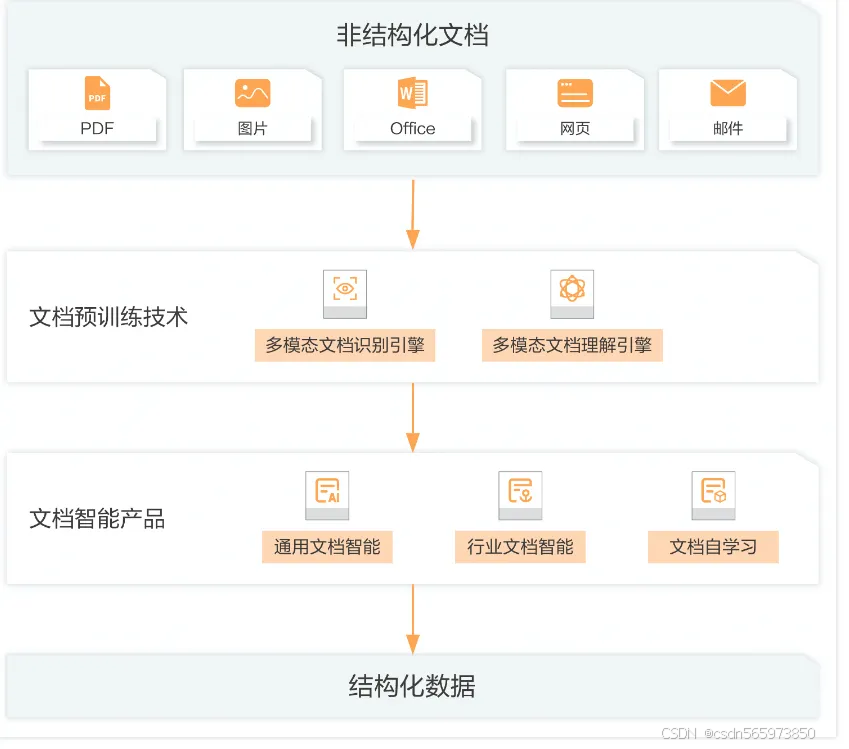
产品能力
目前的文档智能主要包括两个方向的产品能力:【通用文档智能产品】、【文档自学习】产品,这里我们主要说的是通用文档智能产品能力。而通用文档智能产品能力又包括了:文档理解、文档格式转换。详细的产品能力可以在文档智能控制台:https://docmind.console.aliyun.com/doc-overview 看到
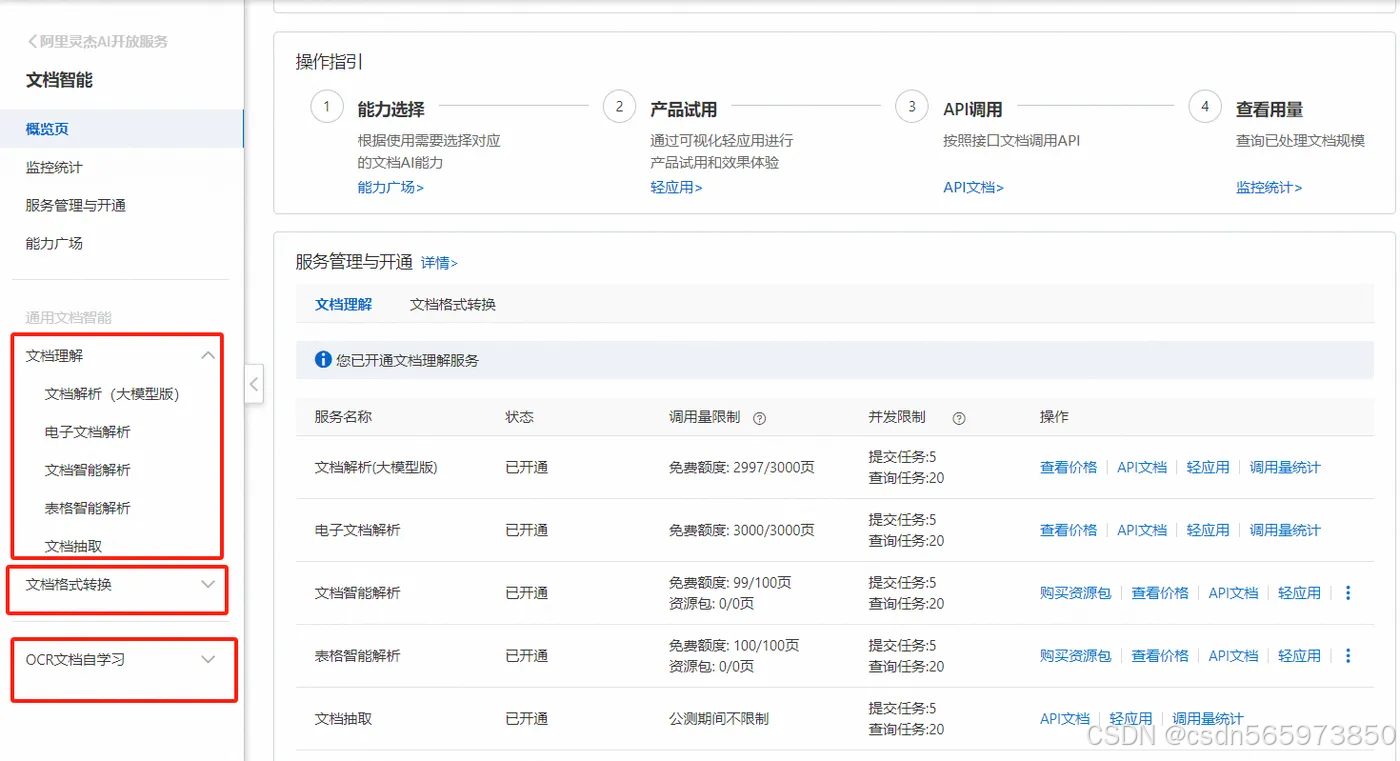
过去我也体验过,用过文档智能产品能力,对于文档理解和文档格式转换的使用效果还是比较满意的。今天我们的测评主角主要是 【文档解析(大模型版)】,那么对于【文档解析(大模型版)】我也是比较疑问,这个产品能力该用在哪儿呢?
文档解析(大模型版)
最初看到【文档解析(大模型版)】,其实不太能理解这个产品能力的应用场景。基于现在的文档智能的通用文档理解来看,现有的几个能力场景足够应付日常的工作所需,为什么还要继续研发一款 【文档解析(大模型版)】) 这样一款产品能力,于是我查阅了文档,通过文档我找到了 【文档解析(大模型版)】与另外两个文档解析能力的区别
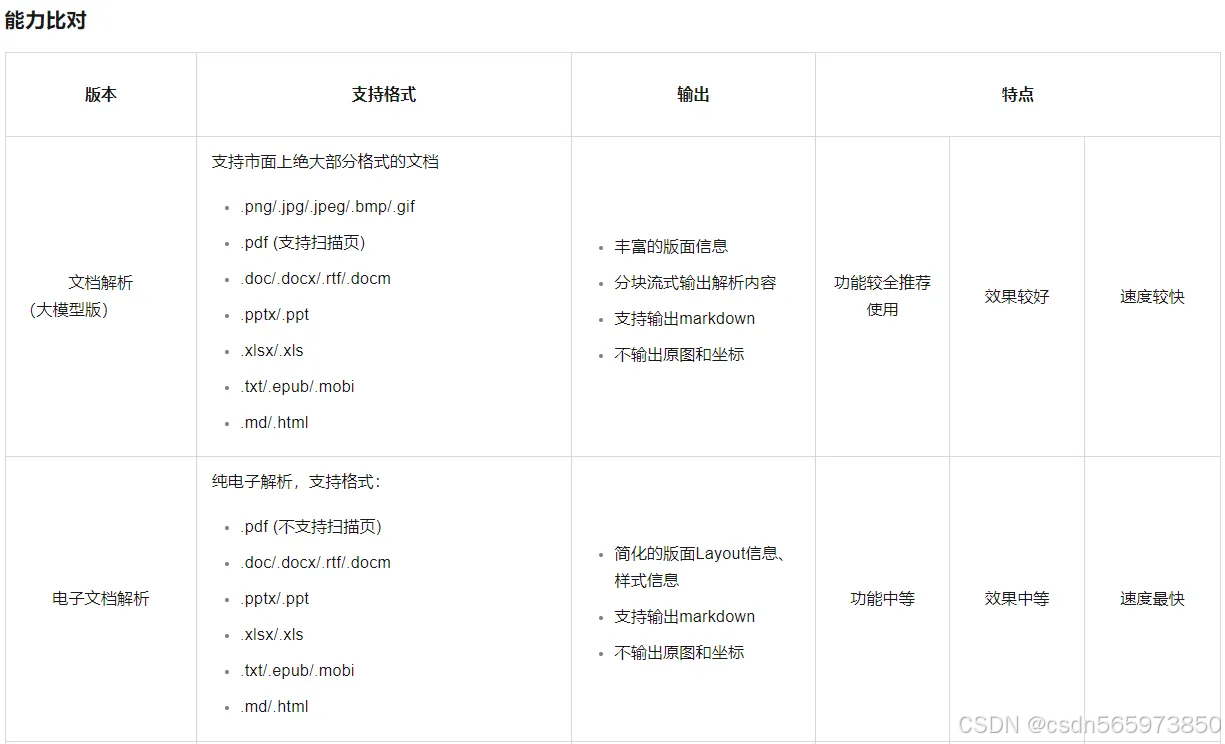
从支持格式上来说,【文档解析(大模型版)】涵盖市面上绝大多数格式文档,是另外两种文档解析产品能力的【加和】;从输出上来说,比另外两种文档解析产品能力的输出更强大,整体上来说就是对于文档解析功能更全面,效果更好,速度更快。过去你使用文档解析能力时,可能需要根据具体的文档格式或者识别速度方面因素来考虑选择哪一个文档解析能力,但是现在你可以不再纠结,直接选择 【文档解析(大模型版)】即可,无需选择,无脑用即可,这样对于客户的使用体验上是不是就更亲和了呢?
在线体验
文档智能控制台对于目前支持的文档解析产品能力都提供了对应的在线体验功能,那么对于文档解析应用场景,你可以直接闭眼选择【文档解析(大模型版)】,不用在根据文件格式来区分选择 【电子文档解析】 或者 【文档智能解析】了。过去你需要解析 图片格式的文档,那么你只能选择【文档智能解析】,或者你需要解析 excel 格式文档你只能选择【电子文档解析】。那么现在,不管你是什么格式文档,你都可以不用考虑直接选择 【文档解析(大模型版)】。下面先来再先体验一下,登录控制台:https://docmind.console.aliyun.com/doc-overview 点击选择 【文档解析(大模型版)】
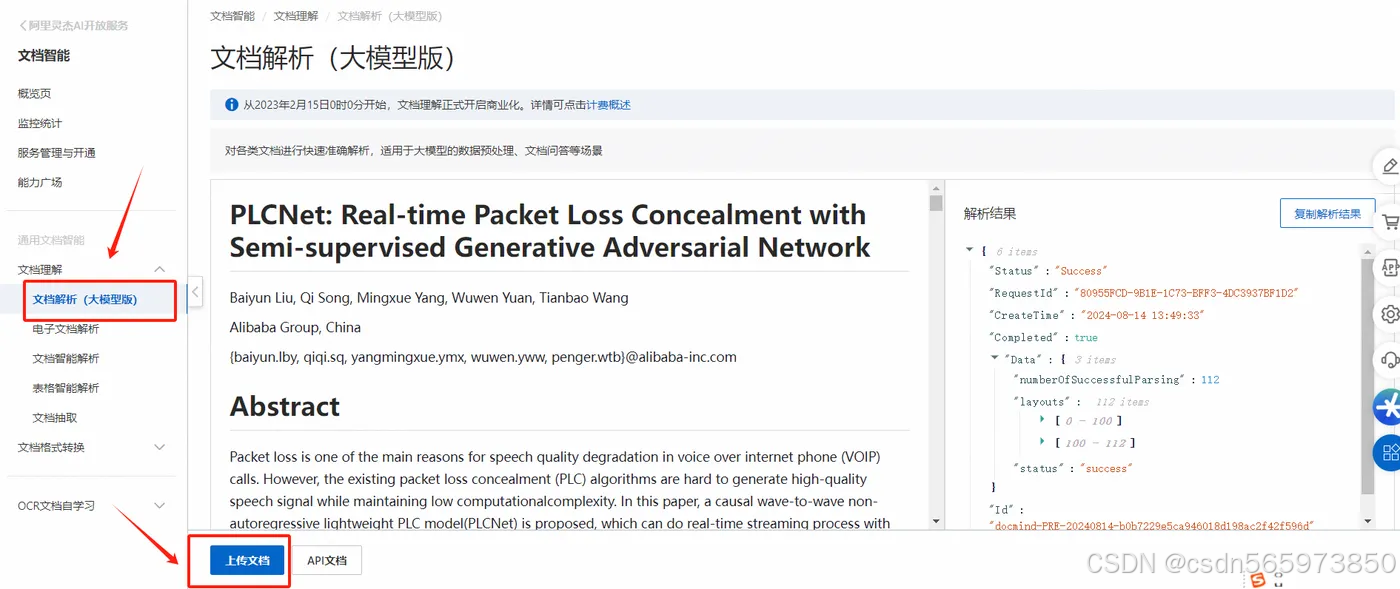
这里我先上传一个图片看一下识别文档解析效果,点击【上传文档】,上传图片格式文档,
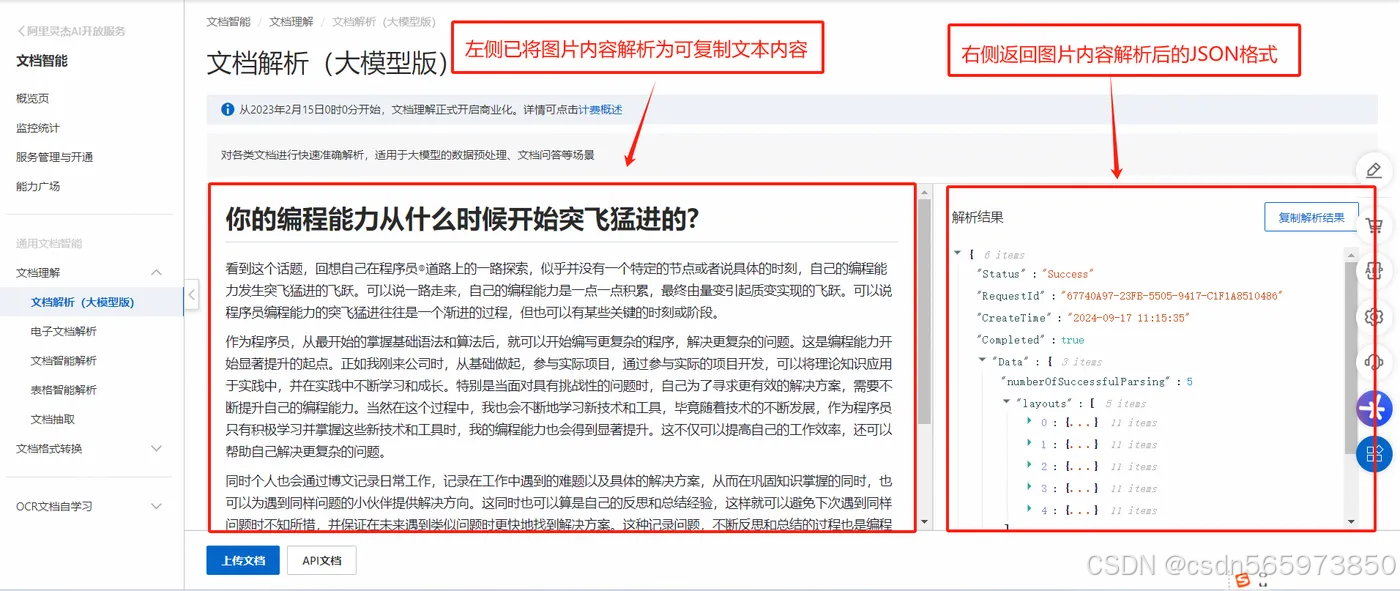
点击【确定】可以看到,在左侧已经我上传的图片内容直接解析为可复制文本内容,右侧将图片内容解析为JSON格式
同样的操作流程,我再体验一下 excel 文档的智能解析效果,点击【上传文档】选择需要解析的 excel 文档,
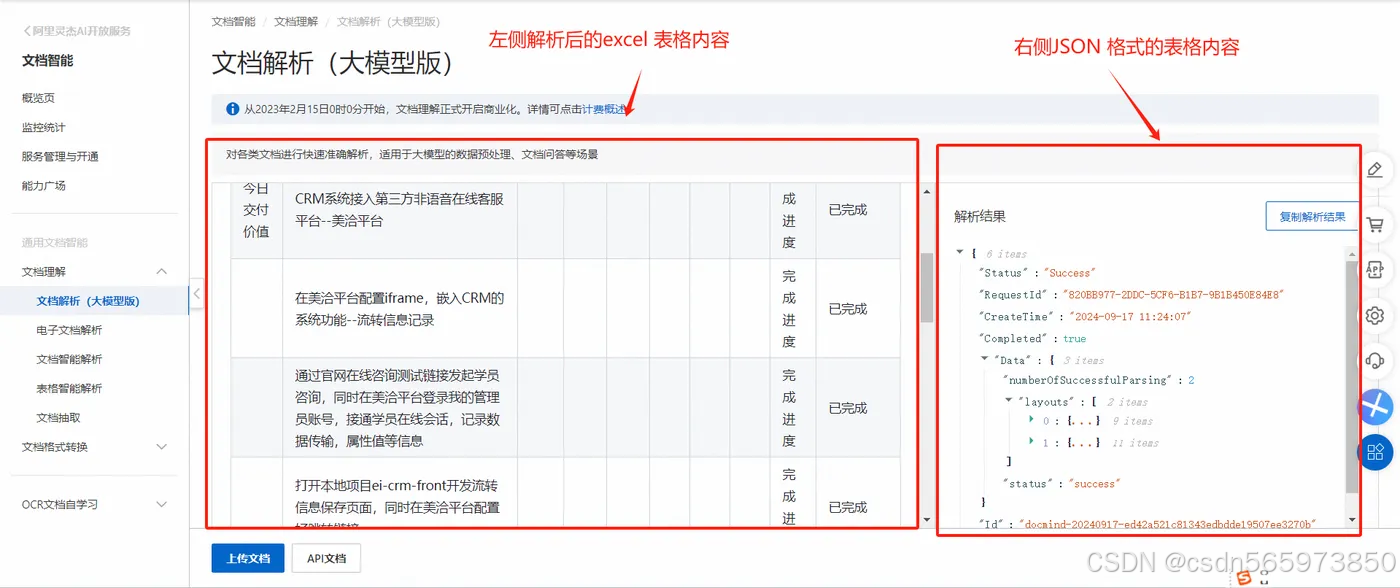
点击【确定】后同样可以在左侧看到直接解析后的可复制的excel 表格内容以及右侧返回对应的JSON格式内容
API接口调用
在体验了在线文档智能解析之后,想要接入项目怎么办?那么你可以通过API接口调用的方式进行操作。
添加依赖
在开始调用API接口之前,你需要配置好Java SDK环境,Java版本要求Java 8及以上,在Maven项目的pom.xml文件中添加如下依赖
<dependencies><dependency><groupId>com.aliyun</groupId><artifactId>tea-openapi</artifactId><version>0.2.5</version></dependency><dependency><groupId>com.aliyun</groupId><artifactId>docmind_api20220711</artifactId><version>2.0.0</version></dependency>
</dependencies>
身份认证
在添加依赖的同时,需要在阿里云平台配置身份认证信息,首先创建AccessKey,然后在项目中通过安全的方式配置AccessKey ID和AccessKey Secret,同时在Maven 配置文件 pom.xml中添加如下依赖
<dependency><groupId>com.aliyun</groupId><artifactId>credentials-java</artifactId><version>0.2.11</version>
</dependency>
其他详细的接入操作你也可以直接参考官方提供的文档,文档中描述的很详细,按照步骤一步一步来就可以了,文档地址:https://help.aliyun.com/zh/document-mind/developer-reference/api-overview
那么具体的接口调用怎么操作呢,文档中对于每个接口的具体操作以及示例代码都给出了详细的说明,比如我们今天的主角 【文档解析(大模型版)】API接口,如何操作呢,请往下看。。。
示例代码
【文档解析(大模型版)】接口调用属于异步调用,根据入参文件的来源不同,分为本地文件和URL文件两种方式,不同的方式调用不同的接口。
URL上传的异步提交服务接口为:SubmitDocParserJob接口。
本地文件上传的异步提交服务接口为:SubmitDocParserJobAdvance接口。
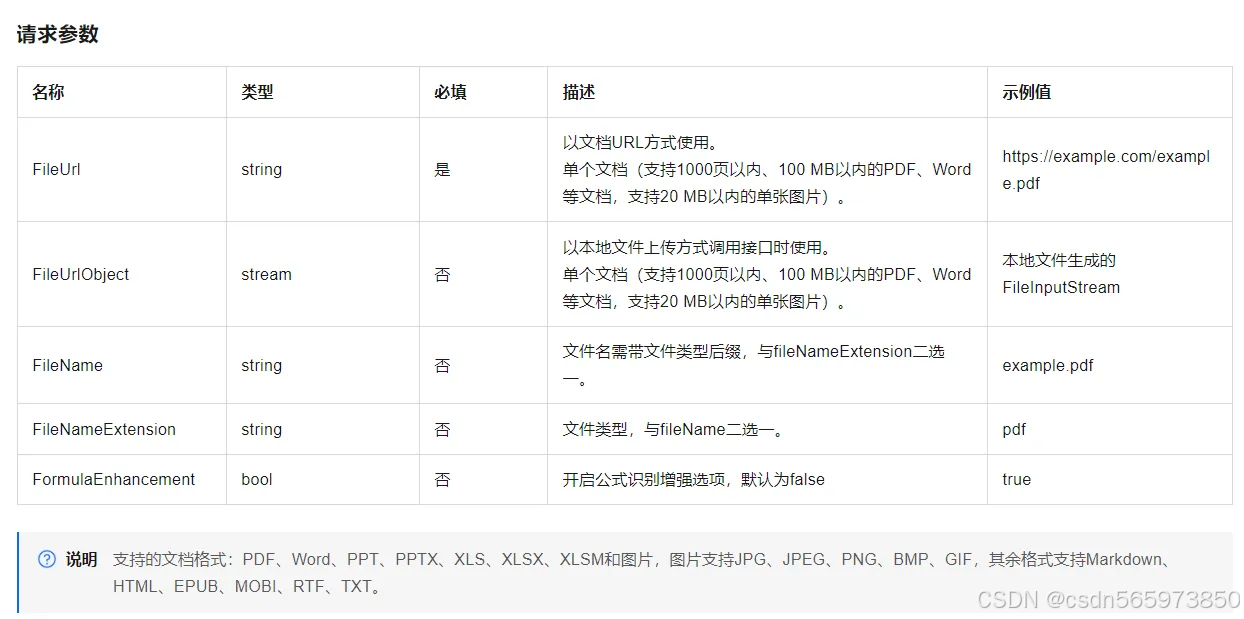
其中,对于本地文档上传调用方式的请求示例代码,调用submitDocStructureJobAdvance接口,通过fileUrlObject参数实现本地文档上传,参考代码:
import com.aliyun.docmind_api20220711.models.*;
import com.aliyun.teaopenapi.models.Config;
import com.aliyun.docmind_api20220711.Client;
import com.aliyun.teautil.models.RuntimeOptions;
import java.io.File;
import java.io.FileInputStream;public static void submit() throws Exception {// 使用默认凭证初始化Credentials Client。com.aliyun.credentials.Client credentialClient = new com.aliyun.credentials.Client();Config config = new Config()// 通过credentials获取配置中的AccessKey ID.setAccessKeyId(credentialClient.getAccessKeyId())// 通过credentials获取配置中的AccessKey Secret.setAccessKeySecret(credentialClient.getAccessKeySecret());// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.comconfig.endpoint = "docmind-api.cn-hangzhou.aliyuncs.com";Client client = new Client(config);// 创建RuntimeObject实例并设置运行参数RuntimeOptions runtime = new RuntimeOptions();SubmitDocParserJobAdvanceRequest advanceRequest = new SubmitDocParserJobAdvanceRequest();File file = new File("D:\\example.pdf");advanceRequest.fileUrlObject = new FileInputStream(file);advanceRequest.fileName = "example.pdf";// 发起请求并处理应答或异常。SubmitDocParserJobResponse response = client.submitDocParserJobAdvance(advanceRequest, runtime);
}
对于传入文档URL调用方式的请求示例代码如下,调用SubmitDocParserJob接口,通过fileUrl参数实现传入文档URL,参考代码如下:
import com.aliyun.docmind_api20220711.models.*;
import com.aliyun.teaopenapi.models.Config;
import com.aliyun.docmind_api20220711.Client;public static void submit() throws Exception {// 使用默认凭证初始化Credentials Client。com.aliyun.credentials.Client credentialClient = new com.aliyun.credentials.Client();Config config = new Config()// 通过credentials获取配置中的AccessKey ID.setAccessKeyId(credentialClient.getAccessKeyId())// 通过credentials获取配置中的AccessKey Secret.setAccessKeySecret(credentialClient.getAccessKeySecret());// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.comconfig.endpoint = "docmind-api.cn-hangzhou.aliyuncs.com";Client client = new Client(config);SubmitDocParserJobRequest request = new SubmitDocParserJobRequest();request.fileName = "example.pdf";request.fileUrl = "https://example.com/example.pdf";SubmitDocParserJobResponse response = client.submitDocParserJob(request);
}
根据请求任务接口返回的业务单号 Id 来进行后面调用获取异步任务接口 QueryDocParserStatus接口,查询status状态和numberOfSuccessfulParsing已处理块,接口请求参数

接口调用示例代码如下
import com.aliyun.docmind_api20220711.models.*;
import com.aliyun.teaopenapi.models.Config;
import com.aliyun.docmind_api20220711.Client;public static void submit() throws Exception {// 使用默认凭证初始化Credentials Client。com.aliyun.credentials.Client credentialClient = new com.aliyun.credentials.Client();Config config = new Config()// 通过credentials获取配置中的AccessKey ID.setAccessKeyId(credentialClient.getAccessKeyId())// 通过credentials获取配置中的AccessKey Secret.setAccessKeySecret(credentialClient.getAccessKeySecret());// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.comconfig.endpoint = "docmind-api.cn-hangzhou.aliyuncs.com";Client client = new Client(config);QueryDocParserStatusRequest resultRequest = new QueryDocParserStatusRequest();resultRequest.id = "docmind-20220902-824b****";QueryDocParserStatusResponse response = client.queryDocParserStatus(resultRequest);
}
最后根据接口调用的返回状态 Status 处理成功来决定是否调用获取结果服务GetDocParserResult接口,接口请求参数如下
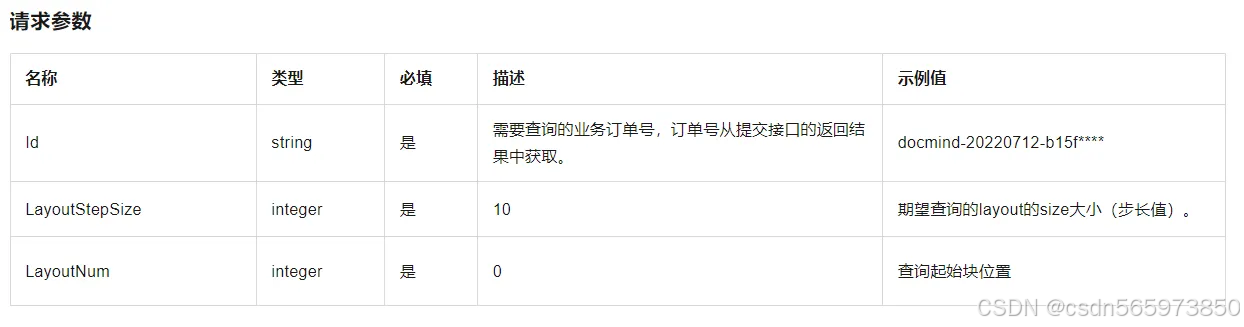
接口调用的示例代码可以参考如下
import com.aliyun.docmind_api20220711.models.*;
import com.aliyun.teaopenapi.models.Config;
import com.aliyun.docmind_api20220711.Client;public static void submit() throws Exception {// 使用默认凭证初始化Credentials Client。com.aliyun.credentials.Client credentialClient = new com.aliyun.credentials.Client();Config config = new Config()// 通过credentials获取配置中的AccessKey ID.setAccessKeyId(credentialClient.getAccessKeyId())// 通过credentials获取配置中的AccessKey Secret.setAccessKeySecret(credentialClient.getAccessKeySecret());// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.comconfig.endpoint = "docmind-api.cn-hangzhou.aliyuncs.com";Client client = new Client(config);GetDocParserResultRequest resultRequest = new GetDocParserResultRequest();resultRequest.id = "docmind-20220902-824b****";resultRequest.layoutStepSize = 10;resultRequest.layoutNum = 0;GetDocParserResultResponse response = client.getDocParserResult(resultRequest);
}
接口请求成功之后你就可以看到你获取的结果,结果以 JSON的格式返回

关于接口中涉及到的返回数据的字段解释说明等信息你可以直接参考官方接口文档:https://help.aliyun.com/zh/document-mind/developer-reference/document-parsing-large-model-version 文档中对于接口的调用请求参数,返回参数,示例代码等都有详细的说明,你可以放心参考调用。
资源使用情况
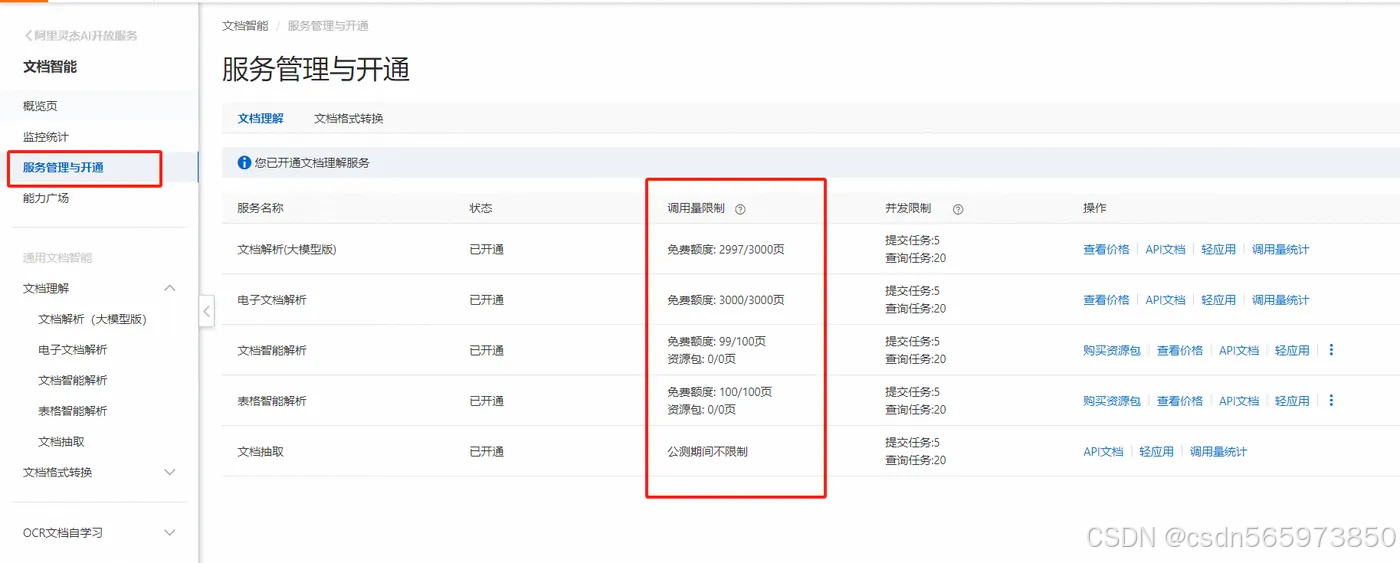
对于初次开通文档智能的用户来说,你可以点击控制台菜单的【服务管理与开通】查看你当前账户对应不同文档理解服务下的免费调用次数的使用情况,
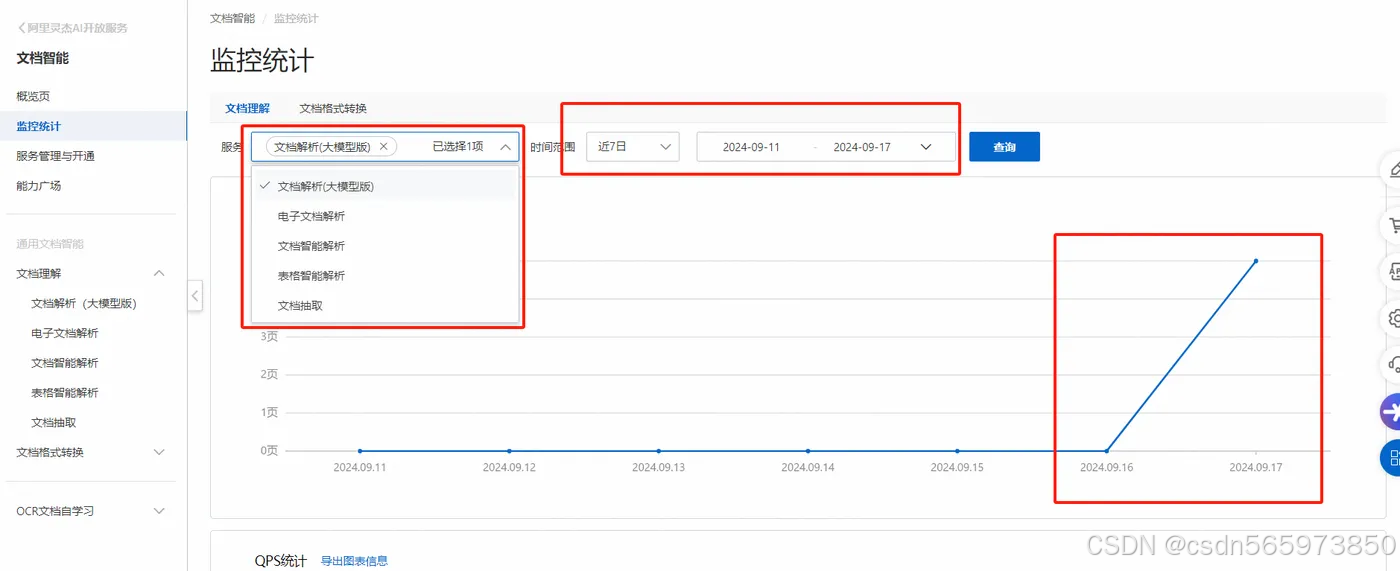
或者你也可以点击【监控统计】来查看当前或者一段时间内的文档智能产品能力的使用情况,通过筛选条件选择不同服务及时间段,查询指定服务指定时间段下的调用次数情况
体验总结
关于文档智能的文档解析(大模型版)的体验到这里就结束了,本文主要从在线体验效果分析以及API接口调用接入文档方面进行体验测试,整个测试流程比较流畅,目前可以支持小白新手入手接入,在实际的接入过程中,也没有出现意料之外的异常,便于提升接入效率。
在体验过程中是否得到足的产品内引导以及文档帮助?
在体验过程中,对于文档智能的文档解析(大模型版)的控制台体验可以不用产品引导或者文档就可以轻松掌握在线操作,对于API接口的调用,官方提供的文档中也详细介绍了接口请求参数,返回参数以及示例代码等信息,方便开发者接入的同时也降低了对于新接入文档智能产品的学习成本,考虑的比较全面,赞赞赞。
产品功能是否满足预期?
产品的功能方面,我这边主要是在控制台体验,上传文档后的识别结果毫秒级返回,根本感受不到文档智能解析的延时。对于代码接入这一块,目前暂时没有相应的业务需要,因此并没有测这一块的功能和性能。不过根据在线体验的结果以及文档中的示例代码来看,功能方面和性能方面应能轻松满足预期效果,不会有大的差异。
针对大模型建设的场景,有哪些可以改进的地方?
对于当前体验的产品文档智能本身来说,大模型建设场景目前已经足够用了,并不需要再投入更多的力量来进行完善。文档智能本身的应用场景主要是为了提升文档处理效率,那么只要在文档解析识别准确率上以及文档格式转化这两个方面保证足够高的准确率就可以了。
文档解析-大模型版是否有与其他产品联动组合的可能?
当然有产品联动组合的可能,在回答这个问题之前,首先要理解一下文档智能产品产生的背景。【企业数据大多数都以文本、图片、扫描件、电子表格、在线文档、邮件等文档的形式存在,难以流通和处理,大量有价值的信息都被锁定在非结构化的文档中,无法充分发挥出数据价值。】那么有了文档智能之后,企业的各种文档形式的数据就可以进行识别、处理、整理,那么基于这些数据的识别整理主要还是要用于后续的数据分析,也只有参与了数据分析的原始数据才有价值,而不是说将企业各种形式文档识别之后就放置不理,因此可以和数据分析产品进行联动,从现有的文档识别内容中筛选出需要的或者有历史意义的内容。

)
感知机)


