大多数人听到“二进制”的时候,脑海里可能马上就会联想到电影《黑客帝国》中由“0”和“1”组成的矩阵。
笔者不打算在这里详细讨论二进制的运算、反码、补码之类枯燥的东西,但有几个和开发相关的概念需要做一点澄清和普及。因为这些内容就像空气——用的时候不觉得,但一认真审视起来就容易犯迷糊。
我们在计算机中看到的各种文件,例如文本、图片、音乐、视频、Word文件等,对于计算机来说,没有任何差别,因为它们都是由“0”和“1”组成的。但这么说还是太笼统,举个例子就很容易理解了。
首先,在Windows中下载并安装一个叫做Hex Editor Neo的软件,这是一种十六进制编辑器。当然也可以通过安装Vscode或Notepad++的插件的方式安装。
然后,在Windows的桌面上新建一个txt文本文件,名字可以任意起,在文件其中输入一些内容后保存,比如输入“Java编程语言”。
关闭文本编辑器窗口,然后光标悬停在文本文件的图标上并单击鼠标右键,选择用Hex Editor Neo软件打开它,如图1-4所示。
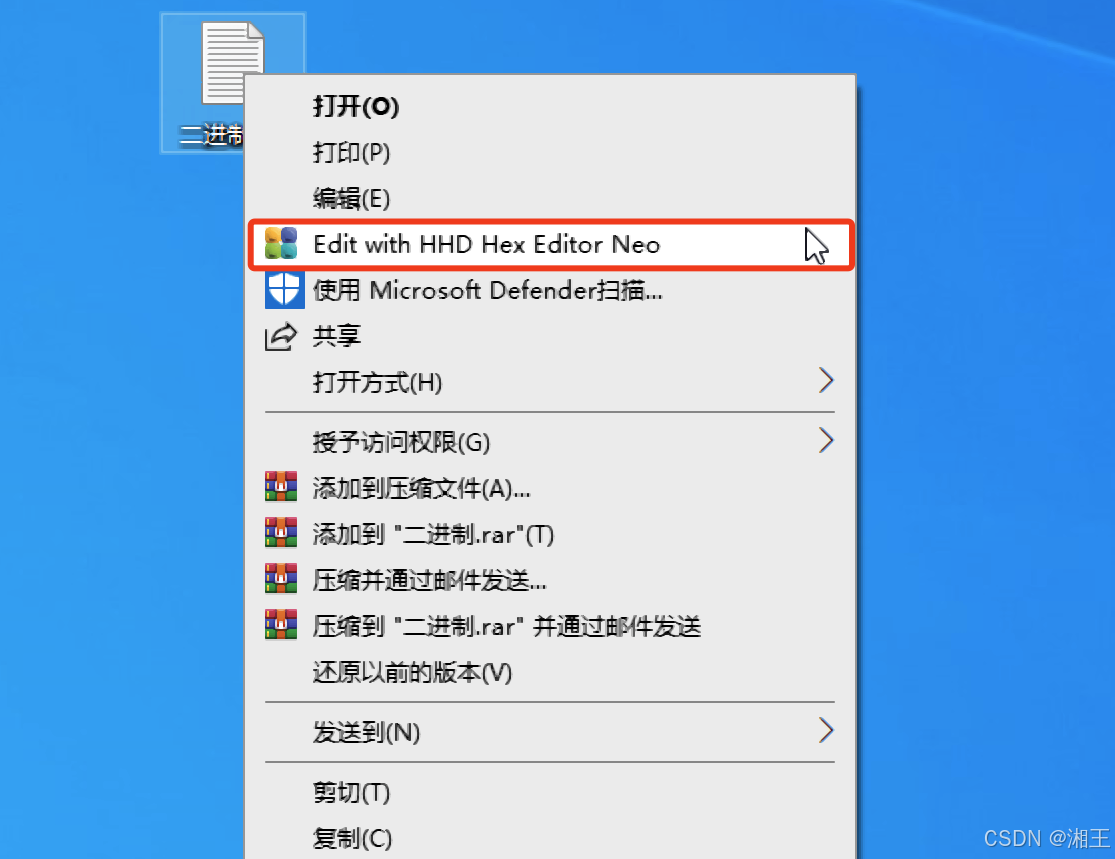
图1-4 用Hex Editor Neo打开文本文件
打开后如图1-5所示。
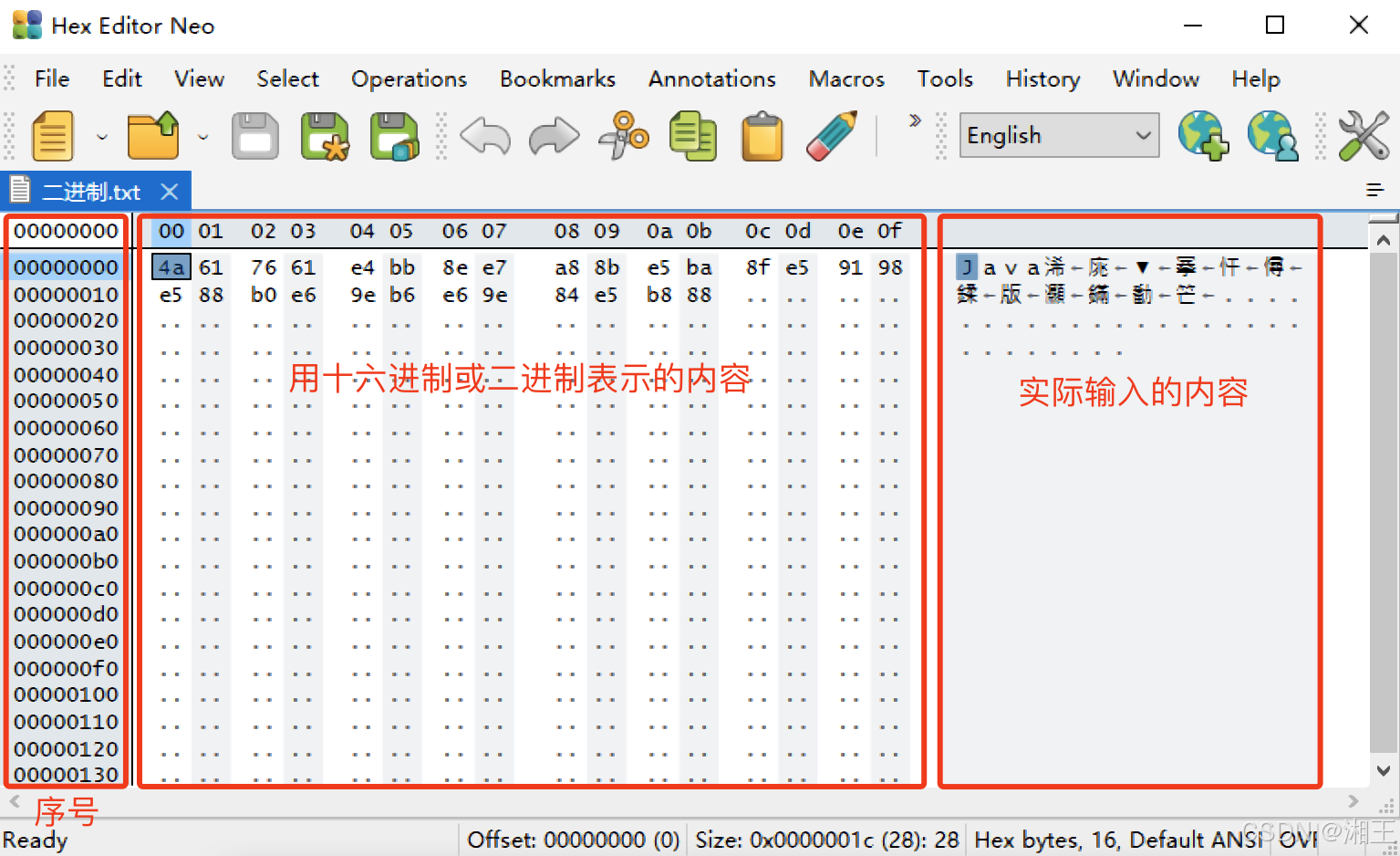
图1-5 用Hex Editor Neo打开文本文件后显示的内容
可以很清楚地看到,整个区域分为左中右三个部分。左边部分显示的是十六进制序号;中间部分显示的是刚才输入的内容,用十六进制数字表示;而右边则是内容的字符编码,只不过中文都变成了乱码。现在换成用二进制来显示它。依次点击菜单上的“View”->“Display As”->“Binary”。
切换之后,显示出来的二进制内容如图1-6所示。
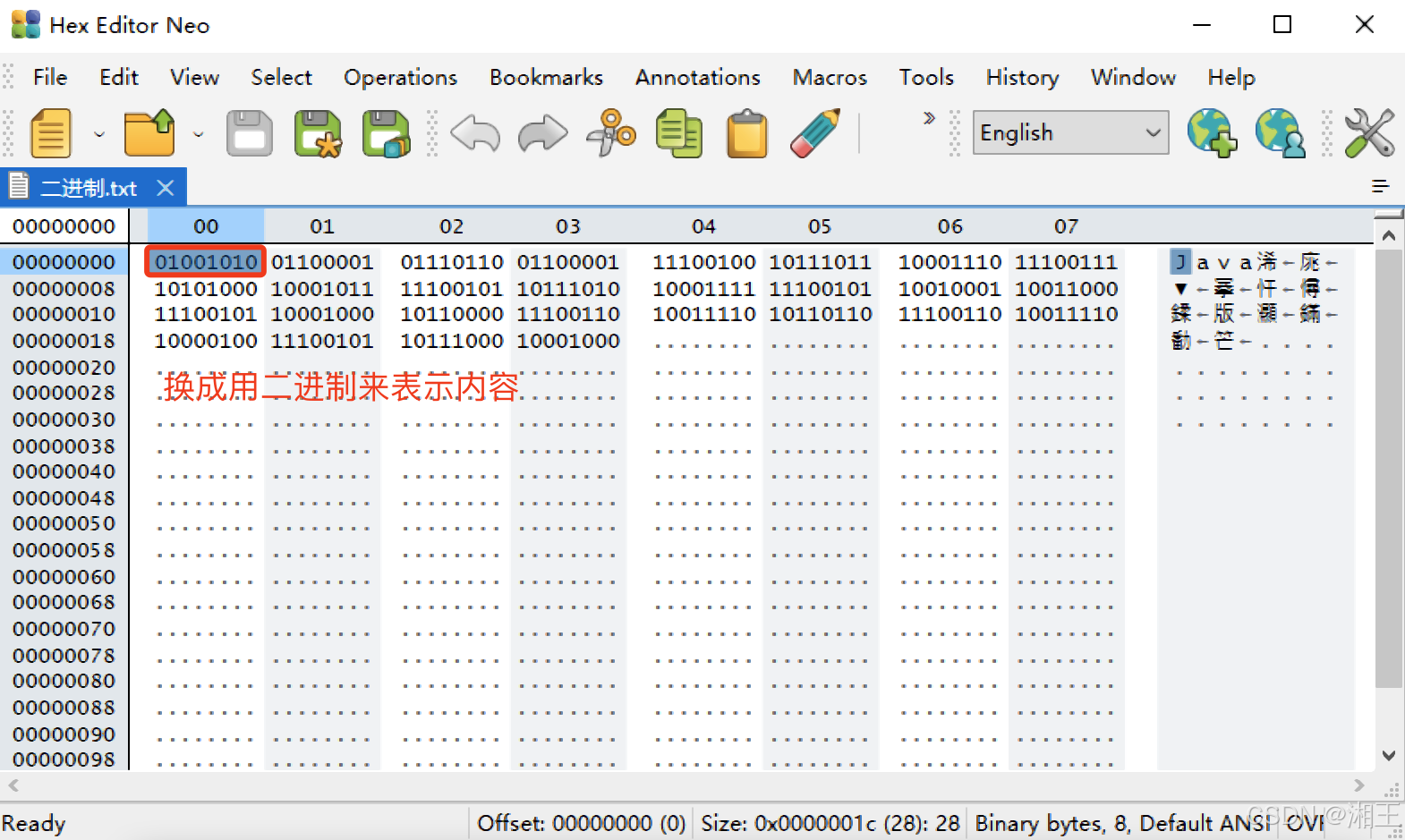
图1-6 用二进制显示文本内容
可以看到第一行第一列,原来显示十六进制的“4a”换成了二进制“01001010”。这正是“4a”对应的二进制数值,而将“01001010”转换成十进制数就是“74”。为什么要转换为十进制数呢?因为只有转换为十进制才能通过ASCII码表查到“74”所对应的字符是大写字母“J”,也就是刚才在文本中输入的第一个字母,如图1-7所示。
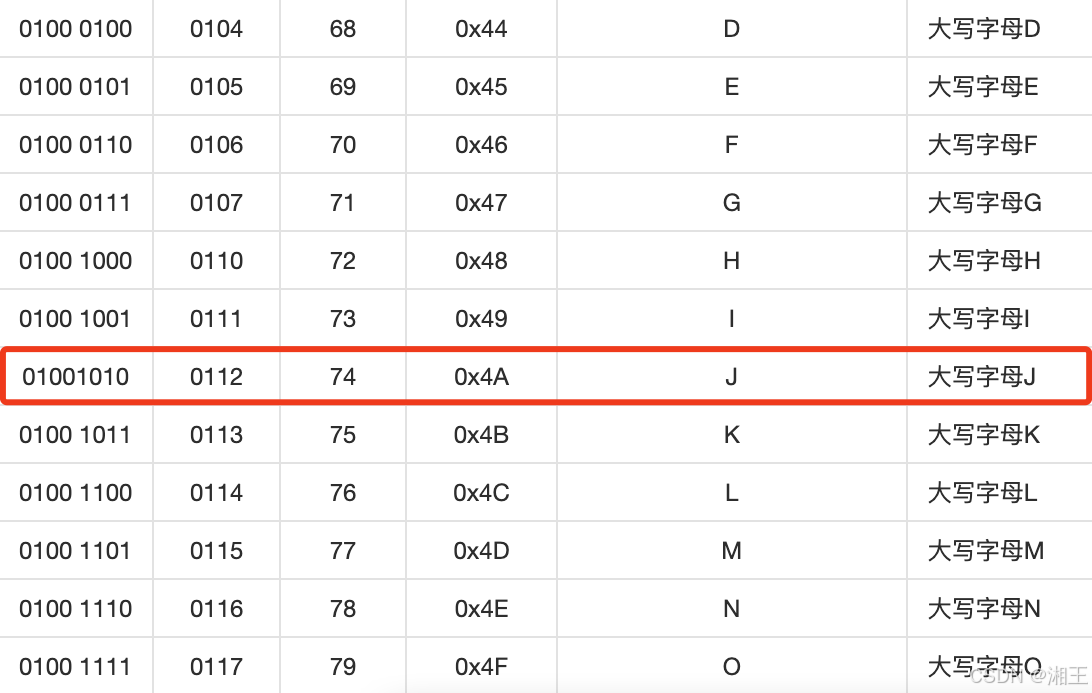 图1-7 十进制数字“74”对应字母“J”
图1-7 十进制数字“74”对应字母“J”
依此类推,这些十六进制内容转换之后正是刚才输入的“Java编程语言”。
刚才展示的是文本数据,现在再来看一下图像数据。
用Photoshop或其他画图软件创建一个10×10像素的正方形,底色为白色,如图1-8所示。

图1-8 10×10像素的白色正方形
然后再次用Hex Editor Neo软件打开它,可以看到如图1-9所示的二进制内容。
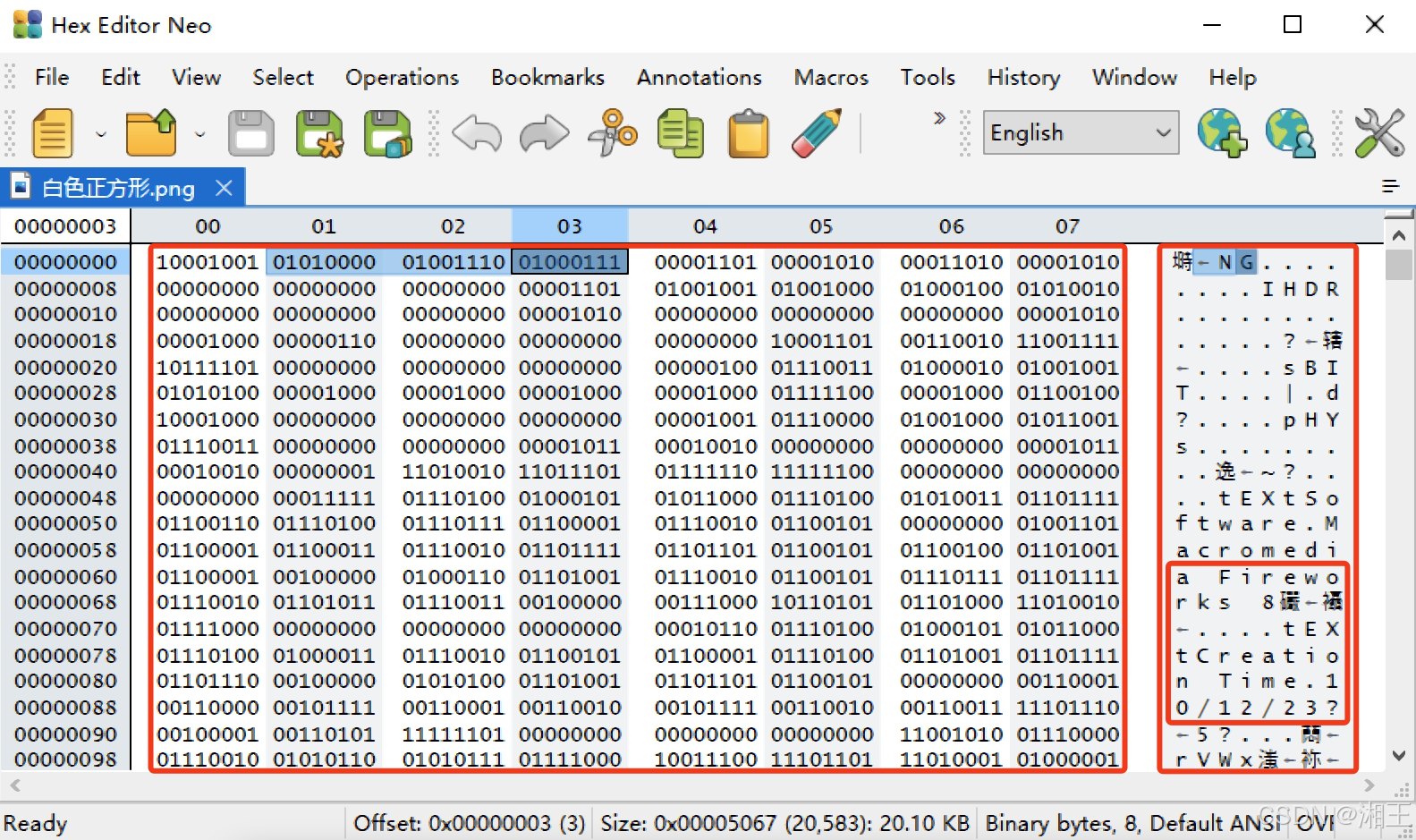
图1-9 白色正方形图片的二进制内容
上图中间部分第一行第二至四列的内容分别为“01010000”、“01001110”和“01000111”,按照图1-7中的方法,它们分别对应ASCII中的“P”、“N”、“G”。
这正是文件名后缀“PNG”。这是巧合吗?并不是,因为在右边部分的剩余内容中可以看到其他和这个文件相关的一些信息,如创建文件的软件工具,文件创建时间等信息,这和用Windows属性工具显示出来的信息是一致的,如图1-10所示。
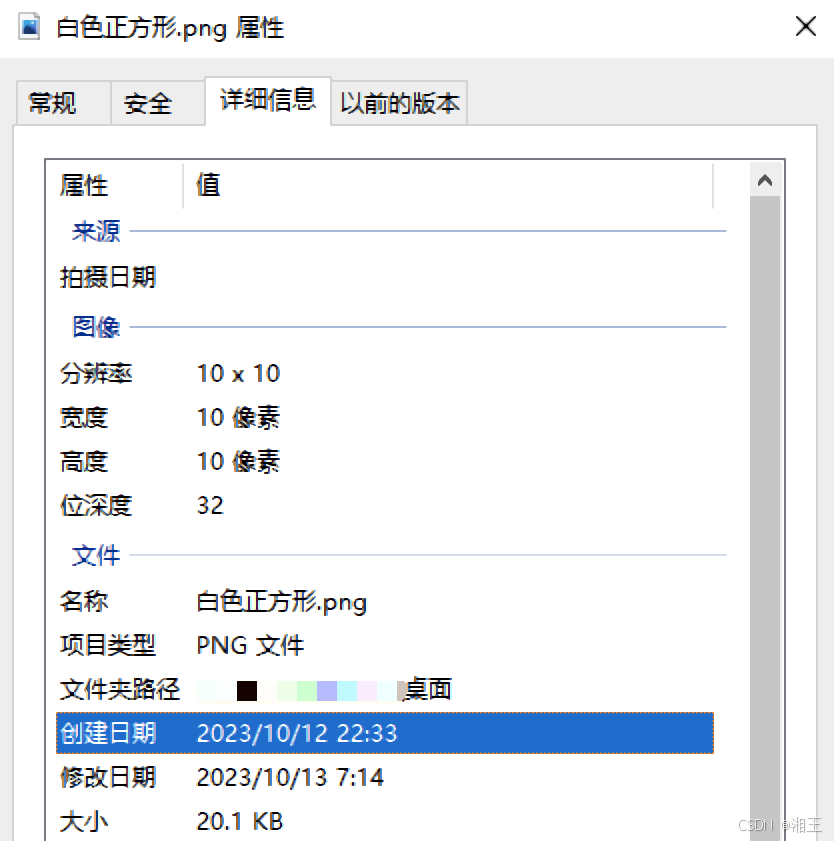
图1-10 图形文件的属性信息
这里没有再继续深入了解,但可以断定:Hex Editor Neo显示的内容一定包含了所有Windows属性显示的内容。
从这个意义上说,如果能够完全掌握用二进制创建文件的规则,是不是可以用Hex Editor Neo代替任何软件呢?例如用Hex Editor Neo代替文本编辑器,代替Word,代替Photoshop,甚至代替IDEA来编程呢?这不但理论上是完全可行的,而且事实上也确实可行。不过,却不会有人真的那么做,因为太费时费力,效率太低,而且极易出错。
我们平常所看到的任何文件,除了文件的内容本身,还含有一部分附加信息。这些附加信息用户是看不到的,即使看到了也没有意义。因为它们是给计算机操作系统准备的,用以区分各类不同的文件类型及读取、存储方式,如图1-11所示。

图1-11 操作系统读取二进制内容的方式
从上图可以看出,操作系统和各种软件是这样工作的:
1. 读取时,操作系统通过附加信息就知道该将文件交给哪个软件处理、转译并展示;
2. 存储时,各种软件会先给文件添加专属的附加信息(软件安装时会在操作系统的注册表中“登记”这些附加信息),然后再交由操作系统一并保存;
3. 卸载后,由于对应的附加信息被从注册表中清除,所以操作系统也就不知道对应类型的文件该给哪种软件处理了。
这种附加信息有一个计算机专有名词:文件头。这也正是操作系统和各种应用软件存在的意义:有些文件头十分庞大,如果要人力用二进制的方式去编写完成,无疑既费力又不讨好,但计算机却十分擅长这种精确无误且枯燥无比的重复性劳动。
当前,AI应用开发正在经历快速发展和深度融合,具体表现为在商业服务、医疗卫生、教育培训、自媒体传播等多领域全面开花。与云计算、物联网、5G技术结合,实现边缘智能;与传统软件开发过程融合,逐步标准化和模块化,实现很多基础性的编码工作;与工具和框架生态绑定,实现简化开发流程和快速迭代的目的。
作为AI应用的基础设施,大模型的重要性自然不言而喻。尤其是目前业界如火如荼的大模型训练,以其千亿级别的超大规模参数、庞大的数据与算力需求、模型的精细化调整、能源与效率的优化等,让人们想要爱它不容易。
具体来说,AI大模型训练涉及到的技术难点和关键挑战,主要包括如下七个方面。
一、数据质量与数量挑战。
训练大模型需要超大规模且高质量的数据集,但数据质量不均、标注不完整会极大地影响模型性能。而数据规模庞大时,存储和处理成本会又会显著增加。因此,应对策略包括但不限于如下方式:
- 合理做好数据的动静分离、冷热分离及主从分离,建设企业的分层、在线/离线数仓,利用各种数据清洗和增强技术确保数据质量。
- 采用分布式存储和“流批”框架(如Hadoop、HBase、Spark和Flink等)处理大规模或超大规模数据集。
- 使用合成数据、增量学习或迁移学习逐步减少对大规模标注数据的依赖。
二、模型设计与优化挑战。
大模型通常具有数十亿甚至上千亿的参数,设计合理的模型架构(如Transformer)就显得尤为重要了。因为模型复杂度过高,可能导致过拟合、收敛慢、结果不准确等问题。所以,相应的应对策略如下:
- 使用神经架构搜索(NAS)自动优化模型结构。
- 通过引入正则化、Dropout等技术防止过拟合。
- 利用优化算法(如AdamW)加速模型的收敛。
三、算力需求与分布式训练挑战。
大模型的训练需要巨大的计算资源来支撑,对GPU、TPU等硬件设备的需求很高。而一般商用的大模型是不可能通过单机训练来完成的,这就需要部署分布式训练模型,涉及节点间通信、数据同步以及一致性的复杂问题。可以通过以下策略来应对。
- 部署高性能计算集群或租用算力云计算资源(如AWS、阿里云、AutoDL等)。
- 使用AI分布式框架(如Horovod、DeepSpeed、Colossal-AI)优化多节点协作。
- 通过混合精度训练(FP16/FP8)来降低对算力的需求。
四、训练效率与成本挑战。
AI大模型的训练时间通常耗时比较久,尤其是超大规模的AI模型,可能耗费数天、数周乃至数月。昂贵的计算资源和能源消耗会给成本带来不小的压力。可以这样来解决这些问题:
- 使用分布式数据并行、模型并行等方法提高训练效率。
- 通过剪枝、量化等技术减少大模型的复杂度,使之聚焦于解决主要目标。
- 使用低功耗硬件和能效优化技术降低能源消耗。
五、模型稳定性与可控性挑战。
大模型非常容易陷入梯度爆炸或消失的问题,从而导致训练结果的不稳定,输出不可靠的结果,需要进行更为精细的控制和调优。对于这类问题,其应对策略如下:
- 使用梯度裁剪(Gradient Clipping)防止梯度爆炸。
- 设计合理的学习率调度策略(如Warm-up + Cosine Annealing)。
- 使用对抗训练或多任务学习不断增强模型的鲁棒性。
六、训练后的部署与服务挑战。
大模型训练完成后的输出结果会占用大量的存储空间,推理时需要高性能硬件支持。部署大模型时需考虑延迟、吞吐量等各种性能指标。可以通过如下方式应对:
- 使用模型压缩技术(如蒸馏、剪枝)来降低部署成本。
- 利用分布式推理框架(如TensorRT、ONNX Runtime)加速推理。
- 通过微服务架构和Docker技术支持弹性扩展,优化部署效率。
七、隐私与伦理问题挑战。
大规模训练数据可能包含用户敏感信息,带来隐私泄露或法律风险。而模型生成的结果又可能会存在偏见或误导性的内容,招致公众反感以及监管部门的介入。基于此,其应对策略如下:
- 采用联邦学习和差分隐私技术保护数据安全。
- 定期对模型进行审查,通过相关性过滤技术杜绝可能产生的风险。
- 建立技术伦理委员会,监督AI系统的使用和影响。
综合以上所述,AI大模型训练涉及从数据准备、模型优化到资源分配、部署和伦理等“七座大山”。要成功完成训练,需要技术、资源和管理多方面的协同,同时又需要持续关注最新技术的发展以保持核心竞争力。

)
感知机)


