目录
- Pod
- 基础概念
- Pod 对象在 Kubernetes 中的生命周期
- Pod 对象使用
- Pod 的临时容器
Pod
基础概念
Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume。
Pod 最重要的一个事实是:它只是一个逻辑概念。
Kubernetes 真正处理的,还是宿主机操作系统上 Linux 容器的 Namespace 和 Cgroups,而并不存在一个所谓的 Pod 的边界或者隔离环境。
在 Kubernetes 项目里,Pod 的实现需要使用一个中间容器,这个容器叫作 Infra 容器。在这个 Pod 中,Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起。这样的组织关系,可以用下面这样一个示意图来表达:
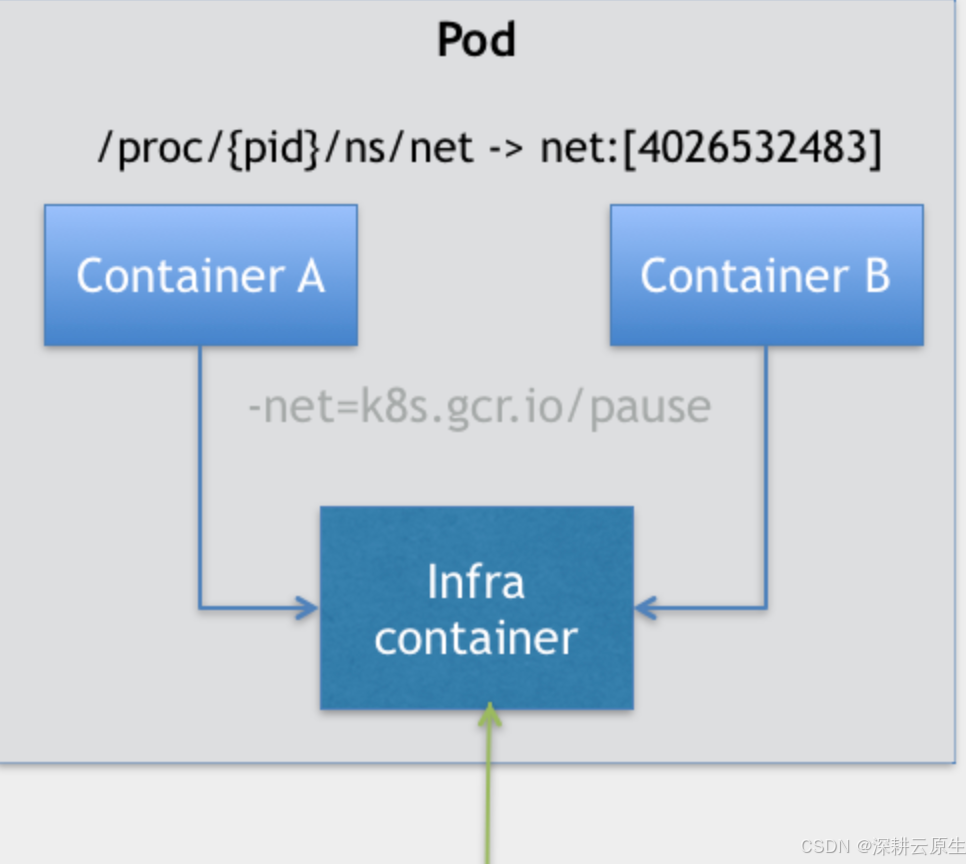
如上图所示,这个 Pod 里有两个用户容器 A 和 B,还有一个 Infra 容器。很容易理解,在 Kubernetes 项目里,Infra 容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作:k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右。
而在 Infra 容器“Hold 住”Network Namespace 后,用户容器就可以加入到 Infra 容器的 Network Namespace 当中了。所以,如果你查看这些容器在宿主机上的 Namespace 文件(这个 Namespace 文件的路径),它们指向的值一定是完全一样的。
这也就意味着,对于 Pod 里的容器 A 和容器 B 来说:
- 它们可以直接使用 localhost 进行通信;
- 它们看到的网络设备跟 Infra 容器看到的完全一样;
- 一个 Pod 只有一个 IP 地址,也就是这个 Pod 的 Network Namespace 对应的 IP 地址;
- 当然,其他的所有网络资源,都是一个 Pod 一份,并且被该 Pod 中的所有容器共享;
- Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
Pod 的设计,就是要让它里面的容器尽可能多地共享 Linux Namespace,仅保留必要的隔离和限制能力。这样,Pod 模拟出的效果,就跟虚拟机里程序间的关系非常类似了。
举个例子,在下面这个 Pod 的 YAML 文件中,我定义了 shareProcessNamespace=true:
这就意味着这个 Pod 里的容器要共享 PID Namespace。
而在这个 YAML 文件中,我还定义了两个容器:一个是 nginx 容器,一个是开启了 tty 和 stdin 的 shell 容器。
我在前面介绍容器基础时,曾经讲解过什么是 tty 和 stdin。而在 Pod 的 YAML 文件里声明开启它们俩,其实等同于设置了 docker run 里的 -it(-i 即 stdin,-t 即 tty)参数。
如果你还是不太理解它们俩的作用的话,可以直接认为 tty 就是 Linux 给用户提供的一个常驻小程序,用于接收用户的标准输入,返回操作系统的标准输出。当然,为了能够在 tty 中输入信息,你还需要同时开启 stdin(标准输入流)。
于是,这个 Pod 被创建后,你就可以使用 shell 容器的 tty 跟这个容器进行交互了。我们一起实践一下:
kubectl create -f nginx.yaml
接下来,我们使用 kubectl attach 命令,连接到 shell 容器的 tty 上:
kubectl attach -it nginx -c shell
这样,我们就可以在 shell 容器里执行 ps 指令,查看所有正在运行的进程:
$ kubectl attach -it nginx -c shell
/ # ps
PID USER TIME COMMAND1 65535 0:00 /pause7 root 0:00 nginx: master process nginx -g daemon off;35 101 0:00 nginx: worker process36 101 0:00 nginx: worker process37 101 0:00 nginx: worker process38 101 0:00 nginx: worker process39 root 0:00 sh45 root 0:00 ps
可以看到,在这个容器里,我们不仅可以看到它本身的 ps ax 指令,还可以看到 nginx 容器的进程,以及 Infra 容器的 /pause 进程。这就意味着,整个 Pod 里的每个容器的进程,对于所有容器来说都是可见的:它们共享了同一个 PID Namespace。
Pod 对象在 Kubernetes 中的生命周期
pod从开始创建到终止退出的时间范围称为Pod生命周期。
生命周期包含以下几个重要流程:
创建主容器(containers)是必须的操作,初始化容器(initContainers),容器启动后的钩子,启动探测、存活性探测,就绪性探测,容器停止前的钩子。
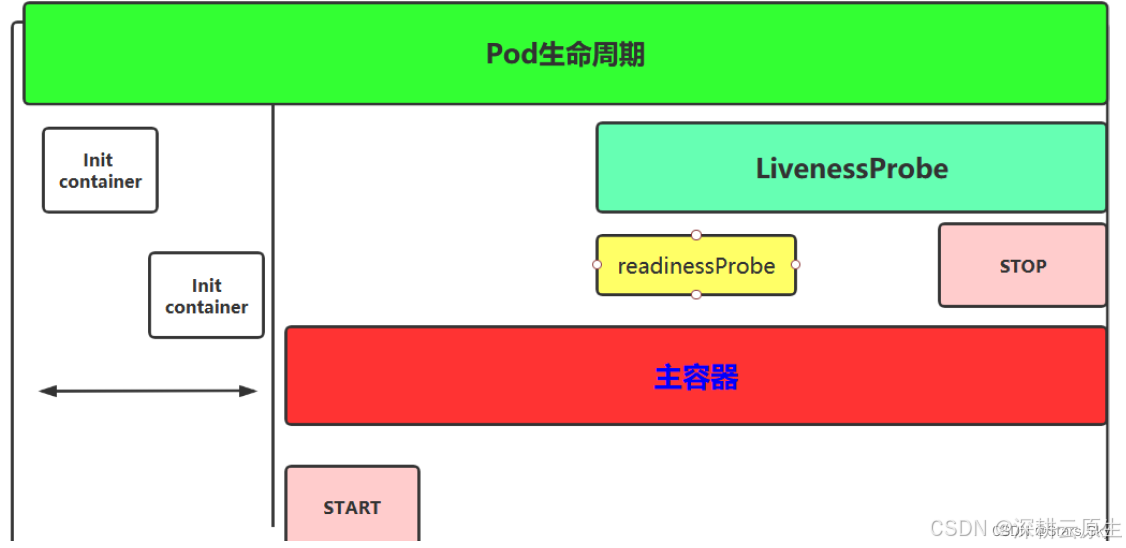
pod 在整个生命周期的过程中总会处于以下几个状态:
- Pending:创建了 pod 资源并存入etcd 中,但尚未完成调度。
- ContainerCreating:Pod 的调度完成,被分配到指定 Node 上。处于容器创建的过程中。通常是在拉取镜像的过程中。
- Running:Pod 包含的所有容器都已经成功创建,并且成功运行起来。
- Succeeded:Pod 中的所有容器都已经成功终止并且不会被重启
- Failed:所有容器都已经终止,但至少有一个容器终止失败,也就是说容器返回了非0值的退出状态或已经被系统终止。
- Unknown:因为某些原因无法取得 Pod 的状态。这种情况通常是因为与 Pod 所在主机通信失败。
pod 生命周期的重要行为
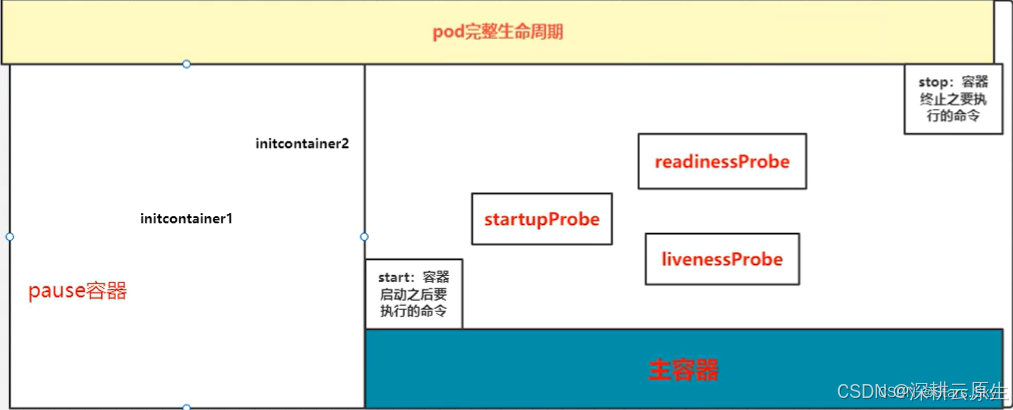
1.在启动任何容器之前,先创建 pause 基础容器,它初始化 Pod 的环境并为后续加⼊的容器
提供共享的名称空间。
2.初始化容器(initcontainer):一个 pod 可以拥有任意数量的 init 容器。init 容器是按照顺序以此执行的,并且仅当最后一个 init 容器执行完毕才会去启动主容器。
3.生命周期钩子:pod 允许定义两种类型的生命周期钩子,启动后(post-start)钩子和停止前(pre-stop)钩子这些生命周期钩子是基于每个容器来指定的,和 init 容器不同的是,init 容器是应用到整个 pod。而这些钩子是针对容器的,是在容器启动后和停止前执行的。
4.容器探测:对 Pod 健康状态诊断。分为三种: Startupprobe、Livenessprobe(存活性探测),Readinessprobe(就绪性检测)。
- Startup(启动探测):探测容器是否正常运行
- Liveness(存活性探测):判断容器是否处于runnning 状态,根据重启策略决定是否重启容器
- Readiness(就绪性检测):判断容器是否准备就绪并对外提供服务,将容器设置为不可用,不接受
- service 转发的请求
三种探针用于 Pod 检测: - ExecAction:在容器中执行一个命令,并根据返回的状态码进行诊断,只有返回 0 为成功
- TCPSocketAction:通过与容器的某 TCP 端口尝试建立连接
- HTTPGetAction:通过向容器 IP 地址的某指定端口的path 发起 HTTP GET 请求。
容器的重启策略:定义是否重启 Pod 对象。 - Always:只要 Pod 对象终止就重启,默认设置
- OnFailure:仅在 Pod 出现错误时才重启
- Never:不重启 Pod
注:一旦 Pod 绑定到一个节点上,就不会被重新绑定到另一个节点上,要么重启,要么终止 。
pod 的终止过程
终止过程主要分为如下几个步骤:
- 用户发出删除 pod 命令:kubectl delete pods 或者 kubectl delete -f yaml
- Pod 对象随着时间的推移更新,在宽限期(默认情况下30 秒),pod 被视为“dead”状态
- 将 pod 标记为“Terminating”状态
- 与第三步同时运行,监控到 pod 对象为“Terminating”状态的同时启动 pod 关闭过程
- 与第三步同时进行,endpoints 控制器监控到 pod 对象关闭,将 pod 与 service 匹配的endpoints 列表中删除
- 如果 pod 中定义了 preStop 钩子处理程序,则 pod 被标记为“Terminating”状态时以同步的方式启动执行;若宽限期结束后,preStop 仍未执行结束,第二步会重新执行并额外获得一个 2 秒的小宽限期
- Pod 内对象的容器收到 TERM 信号
- 宽限期结束之后,若存在任何一个运行的进程,pod 会收到 SIGKILL 信号
- Kubelet 请求 API Server 将此 Pod 资源宽限期设置为 0 从而完成删除操作
Lifecycle 字段
Container Lifecycle Hooks. 容器状态发生变化时触发一系列“钩子”
apiVersion: v1
kind: Pod
metadata:name: lifecycle-demo
spec:containers:- name: lifecycle-demo-containerimage: nginxlifecycle:postStart:exec:command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]preStop:exec:command: ["/usr/sbin/nginx","-s","quit"]
postStart 指的是,在容器启动后,立刻执行一个指定的操作。需要明确的是,postStart 定义的操作,虽然是在 Docker 容器 ENTRYPOINT 执行之后,但它并不严格保证顺序。也就是说,在 postStart 启动时,ENTRYPOINT 有可能还没有结束。
如果 postStart 执行超时或者错误,Kubernetes 会在该 Pod 的 Events 中报出该容器启动失败的错误信息,导致 Pod 也处于失败的状态。
而类似地,preStop 发生的时机,则是容器被杀死之前(比如,收到了 SIGKILL 信号)。而需要明确的是,preStop 操作的执行,是同步的。所以,它会阻塞当前的容器杀死流程,直到这个 Hook 定义操作完成之后,才允许容器被杀死,这跟 postStart 不一样。
所以,在这个例子中,我们在容器成功启动之后,在 /usr/share/message 里写入了一句“欢迎信息”(即 postStart 定义的操作)。而在这个容器被删除之前,我们则先调用了 nginx 的退出指令(即 preStop 定义的操作),从而实现了容器的“优雅退出”。
Pod 对象使用
Projected Volume
- Secret;
- ConfigMap;
- Downward API;
- ServiceAccountToken。
- Volume Sources:组合多个卷源,并将它们投影到同一个目录中
以下是一个使用 Projected Volume 来组合多个 Volume Sources(包括 ConfigMap、Secret、Downward API 和 ServiceAccountToken)的示例。在这个例子中,所有这些不同的数据源将被投影到同一个目录中,供容器使用。
apiVersion: v1
kind: Pod
metadata:name: mypod
spec:containers:- name: mycontainerimage: nginxvolumeMounts:- name: myprojectedvolumemountPath: /etc/projectedvolumes:- name: myprojectedvolumeprojected:sources:- configMap:name: myconfigmapitems:- key: configKeypath: configFile- secret:name: mysecretitems:- key: secretKeypath: secretFile- downwardAPI:items:- path: "podname"fieldRef:fieldPath: metadata.name- serviceAccountToken:path: "token"expirationSeconds: 3600
容器内查看:
ls /etc/projected/
serviceAccountToken:
Service Account 对象的作用,就是 Kubernetes 系统内置的一种“服务账户”,它是 Kubernetes 进行权限分配的对象。比如,Service Account A,可以只被允许对 Kubernetes API 进行 GET 操作,而 Service Account B,则可以有 Kubernetes API 的所有操作的权限。
像这样的 Service Account 的授权信息和文件,实际上保存在它所绑定的一个特殊的 Secret 对象里的。这个特殊的 Secret 对象,就叫作ServiceAccountToken。任何运行在 Kubernetes 集群上的应用,都必须使用这个 ServiceAccountToken 里保存的授权信息,也就是 Token,才可以合法地访问 API Server。
为了方便使用,Kubernetes 已经为你提供了一个的默认“服务账户”(default Service Account)。并且,任何一个运行在 Kubernetes 里的 Pod,都可以直接使用这个默认的 Service Account,而无需显示地声明挂载它( Projected Volume 机制)。
容器内
ls /var/run/secrets/kubernetes.io/serviceaccount
ca.crt namespace token
容器健康检查和恢复机制
Pod 的恢复策略
字段:pod.spec.restartPolicy
- Always:在任何情况下,只要容器不在运行状态,就自动重启容器;
- OnFailure: 只在容器 异常时才自动重启容器;
- Never: 从来不重启容器。
这里用kafka yaml做示例,具体不再介绍
apiVersion: apps/v1
kind: StatefulSet
metadata:name: kafkanamespace: kafka
spec:serviceName: kafka-hsreplicas: 3selector:matchLabels:app: kafkatemplate:metadata:labels:app: kafkaspec:containers:- name: kafkaimagePullPolicy: IfNotPresentimage: zhaoguanghui6/kubernetes-kafka:v3.5.2resources:requests:memory: "2Gi"cpu: 1000mports:- containerPort: 9092name: servercommand:- sh- -c- "exec /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties \--override broker.id=${HOSTNAME##*-} \--override listeners=PLAINTEXT://:9092 \--override advertised.listeners=PLAINTEXT://10.10.101.114:$((${HOSTNAME##*-}+30127)) \--override zookeeper.connect=zk-0.zk-hs.default.svc.cluster.local:2181,zk-0.zk-hs.default.svc.cluster.local:2181,zk-0.zk-hs.default.svc.cluster.local:2181 \--override log.dir=/var/lib/kafka/ \--override auto.create.topics.enable=true \--override auto.leader.rebalance.enable=true \--override background.threads=10 \--override compression.type=producer \--override delete.topic.enable=true \--override leader.imbalance.check.interval.seconds=300 \--override leader.imbalance.per.broker.percentage=10 \--override log.flush.interval.messages=9223372036854775807 \--override log.flush.offset.checkpoint.interval.ms=60000 \--override log.flush.scheduler.interval.ms=9223372036854775807 \--override log.retention.bytes=-1 \--override log.retention.hours=168 \--override log.roll.hours=168 \--override log.roll.jitter.hours=0 \--override log.segment.bytes=1073741824 \--override log.segment.delete.delay.ms=60000 \--override message.max.bytes=1000012 \--override min.insync.replicas=1 \--override num.io.threads=8 \--override num.network.threads=3 \--override num.recovery.threads.per.data.dir=1 \--override num.replica.fetchers=1 \--override offset.metadata.max.bytes=4096 \--override offsets.commit.required.acks=-1 \--override offsets.commit.timeout.ms=5000 \--override offsets.load.buffer.size=5242880 \--override offsets.retention.check.interval.ms=600000 \--override offsets.retention.minutes=1440 \--override offsets.topic.compression.codec=0 \--override offsets.topic.num.partitions=50 \--override offsets.topic.replication.factor=3 \--override offsets.topic.segment.bytes=104857600 \--override queued.max.requests=500 \--override quota.consumer.default=9223372036854775807 \--override quota.producer.default=9223372036854775807 \--override replica.fetch.min.bytes=1 \--override replica.fetch.wait.max.ms=500 \--override replica.high.watermark.checkpoint.interval.ms=5000 \--override replica.lag.time.max.ms=10000 \--override replica.socket.receive.buffer.bytes=65536 \--override replica.socket.timeout.ms=30000 \--override request.timeout.ms=30000 \--override socket.receive.buffer.bytes=102400 \--override socket.request.max.bytes=104857600 \--override socket.send.buffer.bytes=102400 \--override unclean.leader.election.enable=true \--override zookeeper.session.timeout.ms=6000 \--override zookeeper.set.acl=false \--override broker.id.generation.enable=true \--override connections.max.idle.ms=600000 \--override controlled.shutdown.enable=true \--override controlled.shutdown.max.retries=3 \--override controlled.shutdown.retry.backoff.ms=5000 \--override controller.socket.timeout.ms=30000 \--override default.replication.factor=1 \--override fetch.purgatory.purge.interval.requests=1000 \--override group.max.session.timeout.ms=300000 \--override group.min.session.timeout.ms=6000 \--override log.cleaner.backoff.ms=15000 \--override log.cleaner.dedupe.buffer.size=134217728 \--override log.cleaner.delete.retention.ms=86400000 \--override log.cleaner.enable=true \--override log.cleaner.io.buffer.load.factor=0.9 \--override log.cleaner.io.buffer.size=524288 \--override log.cleaner.io.max.bytes.per.second=1.7976931348623157E308 \--override log.cleaner.min.cleanable.ratio=0.5 \--override log.cleaner.min.compaction.lag.ms=0 \--override log.cleaner.threads=1 \--override log.cleanup.policy=delete \--override log.index.interval.bytes=4096 \--override log.index.size.max.bytes=10485760 \--override log.message.timestamp.difference.max.ms=9223372036854775807 \--override log.message.timestamp.type=CreateTime \--override log.preallocate=false \--override log.retention.check.interval.ms=300000 \--override max.connections.per.ip=2147483647 \--override num.partitions=1 \--override producer.purgatory.purge.interval.requests=1000 \--override replica.fetch.backoff.ms=1000 \--override replica.fetch.max.bytes=1048576 \--override replica.fetch.response.max.bytes=10485760 \--override reserved.broker.max.id=1000"env:- name: KAFKA_HEAP_OPTSvalue : "-Xmx2G -Xms2G"- name: KAFKA_OPTSvalue: "-Dlogging.level=INFO"volumeMounts:- name: datadirmountPath: /var/lib/kafkavolumeClaimTemplates:- metadata:name: datadirspec:accessModes: [ "ReadWriteMany" ]resources:requests: storage: 1GistorageClassName: "nfs-client"
affinity:# 定义Pod之间的反亲和性规则podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: "app"operator: Invalues:- kafka# 使用kubernetes.io/hostname作为拓扑键,确保相同标签的Pod不会调度到同一节点topologyKey: "kubernetes.io/hostname"# 定义Pod之间的亲和性规则podAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 1 # 低优先级的偏好规则,权重为1podAffinityTerm:labelSelector:matchExpressions:- key: "app"operator: Invalues:- zk# 使用kubernetes.io/hostname作为拓扑键,偏好将带有相同标签的Pod调度到同一节点topologyKey: "kubernetes.io/hostname"# 定义Pod的优雅关闭时间,单位为秒,设置为300秒
terminationGracePeriodSeconds: 300
probe的原理是通过"exec"来实现的
readinessProbe:tcpSocket:port: 9092 # 检查Pod上的端口9092是否可以连接,用于判断服务是否准备就绪timeoutSeconds: 5 # 每次探测的超时时间为5秒periodSeconds: 5 # 每5秒执行一次探测initialDelaySeconds: 40 # Pod启动后等待40秒再开始第一次探测livenessProbe:exec:command:- sh- -c- "/opt/kafka/bin/kafka-broker-api-versions.sh --bootstrap-server=localhost:9093"# 使用命令行检查Kafka Broker API是否可用,判断容器是否活着timeoutSeconds: 5 # 每次探测的超时时间为5秒periodSeconds: 5 # 每5秒执行一次探测initialDelaySeconds: 70 # Pod启动后等待70秒再开始第一次探测
securityContext:runAsUser: 1000fsGroup: 1000
Pod 的临时容器
- 当由于容器崩溃或容器镜像不包含调试工具而导致 kubectl exec 无用的时候,临时容器对于交互式故障排查非常有用。
- 比如,像 distroless 镜像 允许用户部署最小的容器镜像,从而减少攻击面并减少故障和漏洞的暴露。由于 distroless 镜像 不包含 Shell 或任何的调试工具,因此很难单独使用 kubectl exec 命令进行故障排查。
- 使用临时容器的时候,启用 进程名字空间共享 很有帮助,可以查看其他容器中的进程。
apiVersion: v1
kind: Pod
metadata:name: nginx
spec:shareProcessNamespace: truecontainers:- name: nginximage: nginx- name: shellimage: busybox:1.28securityContext:capabilities:add:- SYS_PTRACEstdin: truetty: true
root@iv-yda4ksktts5i3z33qz30:~# kubectl attach -it nginx -cshell
If you don't see a command prompt, try pressing enter.
/ # ps
PID USER TIME COMMAND1 65535 0:00 /pause7 root 0:00 nginx: master process nginx -g daemon off;13 101 0:00 nginx: worker process43 root 0:00 sh49 root 0:00 ps
/ # cat /proc/7/root/etc/nginx/nginx.confuser nginx;
worker_processes 1;error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;events {worker_connections 1024;
}

)
感知机)


