爬虫基础
环境配置
- python环境以及编译器
- requests库
- re,xpath等库的使用,这里我主要使用xpath库进行匹配
python环境配置
这里我使用的是python3.11。其他版本也可以的。
可以参考这篇文章进行配置环镜
https://bbs.huaweicloud.com/blogs/350852
然后就是python的编译器破解,这里我使用的是Pycham的专业版,社区版也可以。
破解方式:
先去官网下载2024.1x以及之前版本的专业版Pycham
然后进入https://3.jetbra.in/这个网站中
 扫描后点击蓝色网站进行跳转
扫描后点击蓝色网站进行跳转
 点击jetbra.zip进行下载,并解压。
点击jetbra.zip进行下载,并解压。

进入如下目录,点击运行install-current-user

按照提示来就行。
然后打开pycham,用注册码进行登录即可
库的安装
在终端运行以下命令即可
pip install requestspip install lxml
零基础学习爬取小说
首先,我们先导入我们配置好的库,并找一个小说网站
import requests
from lxml import etreeurl='https://m.ydxrf.com/'然后我们可以使用requests库查看网站的html内容
import requests
from lxml import etreeurl='https://m.ydxrf.com/'respons=requests.get(url=url)print(respons.text)
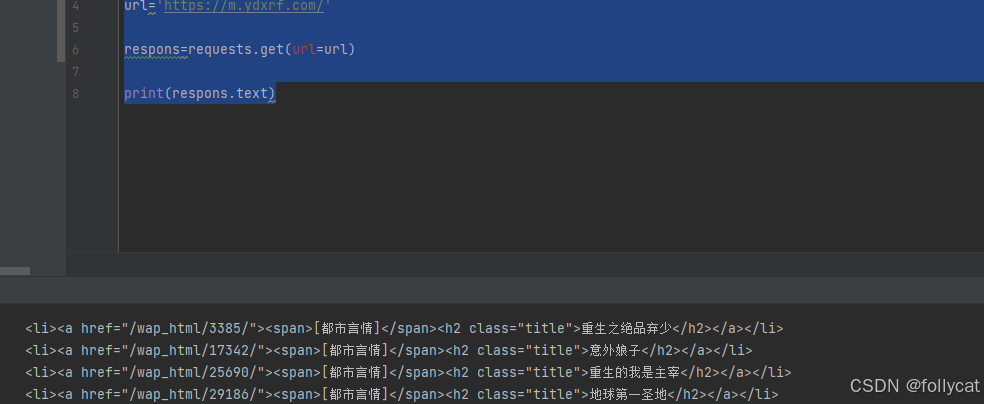 可以看到这个就是我们查看的网站的html内容
可以看到这个就是我们查看的网站的html内容
找到自己喜欢的一本小说,进入第一章内容,右键点击源码查看器观察html内容。
可以找到我们想下载下来的小说部分的内容
 并将url换成小说第一章的url
并将url换成小说第一章的url
import requests
from lxml import etreeurl='https://m.ydxrf.com/wap_html/51036/26213925.html'respons=requests.get(url=url)print(respons.text)
再运行一次确保我们可以访问到网页
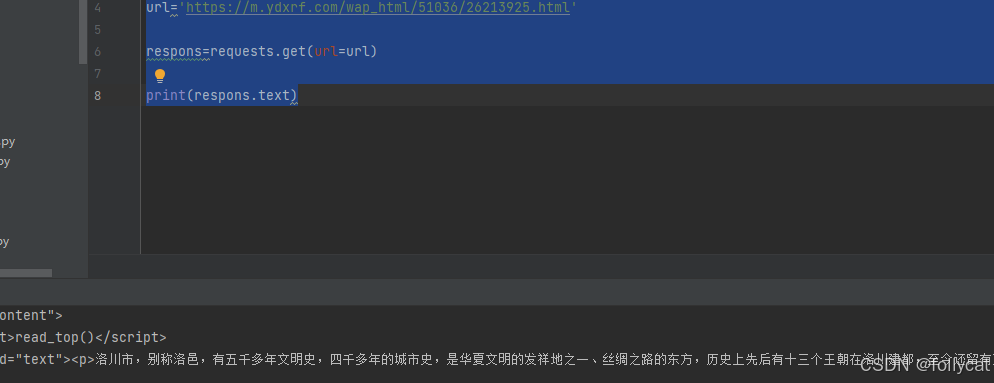 然后使用xpath进行读取我们想要的内容
然后使用xpath进行读取我们想要的内容
import requests
from lxml import etreeurl='https://m.ydxrf.com/wap_html/51036/26213925.html'respons=requests.get(url=url).contenttree = etree.HTML(respons)ree=tree.xpath("//div[@id='text']/p/text()")print(ree)
用join从ree中提取出我们想要的文字
import requests
from lxml import etreeurl='https://m.ydxrf.com/wap_html/51036/26213925.html'respons=requests.get(url=url).contenttree = etree.HTML(respons)ree=tree.xpath("//div[@id='text']/p/text()")text = "".join(ree)print(text) 然后,我们回到网页,点击下一章,观察url有什么不同
然后,我们回到网页,点击下一章,观察url有什么不同

可以看到最后一个数字变成了6。
所以我们可以使用for循环来遍历小说内容
import requests
from lxml import etreefor i in range(26213925,26213930):url = f'https://m.ydxrf.com/wap_html/51036/{i}.html'respons = requests.get(url=url).contenttree = etree.HTML(respons)ree = tree.xpath("//div[@id='text']/p/text()")text = "".join(ree)print(text) 可以看到每一章内容
可以看到每一章内容
我们使用同样方法来输出每一章标题
import requests
from lxml import etreefor i in range(26213925,26213930):url = f'https://m.ydxrf.com/wap_html/51036/{i}.html'respons = requests.get(url=url).contenttree = etree.HTML(respons)ree = tree.xpath("//div[@id='text']/p/text()")reee=tree.xpath("//h1/text()")text = "".join(ree)header = "".join(reee)print(header)print(text)
然后将其写入文件即可
import requests
from lxml import etreefor i in range(26213925,26834535):url = f'https://m.ydxrf.com/wap_html/51036/{i}.html'respons = requests.get(url=url).contenttree = etree.HTML(respons)ree = tree.xpath("//div[@id='text']/p/text()")reee=tree.xpath("//h1/text()")text = "".join(ree)+'\n\n\n'header = "".join(reee)+'\n\n'with open("文件路径", 'a') as file:file.write(header)file.write(text)print("文本已追加到文件。")print("over")


)
感知机)


