一、引言
大型语言模型(LLM)及其应用正快速改变技术格局。Gartner报告指出,组织正从试点转向生产,LLM自身也在不断演化,带来新机遇与挑战。
二、LLM训练过程
(一)预训练
模型在大量无结构文本上通过自监督学习(SSL)训练,无需标签,通过预测遮蔽词学习。如在句子“Scotch whisky的成分之一是麦芽[MASK]”中预测“barley”。
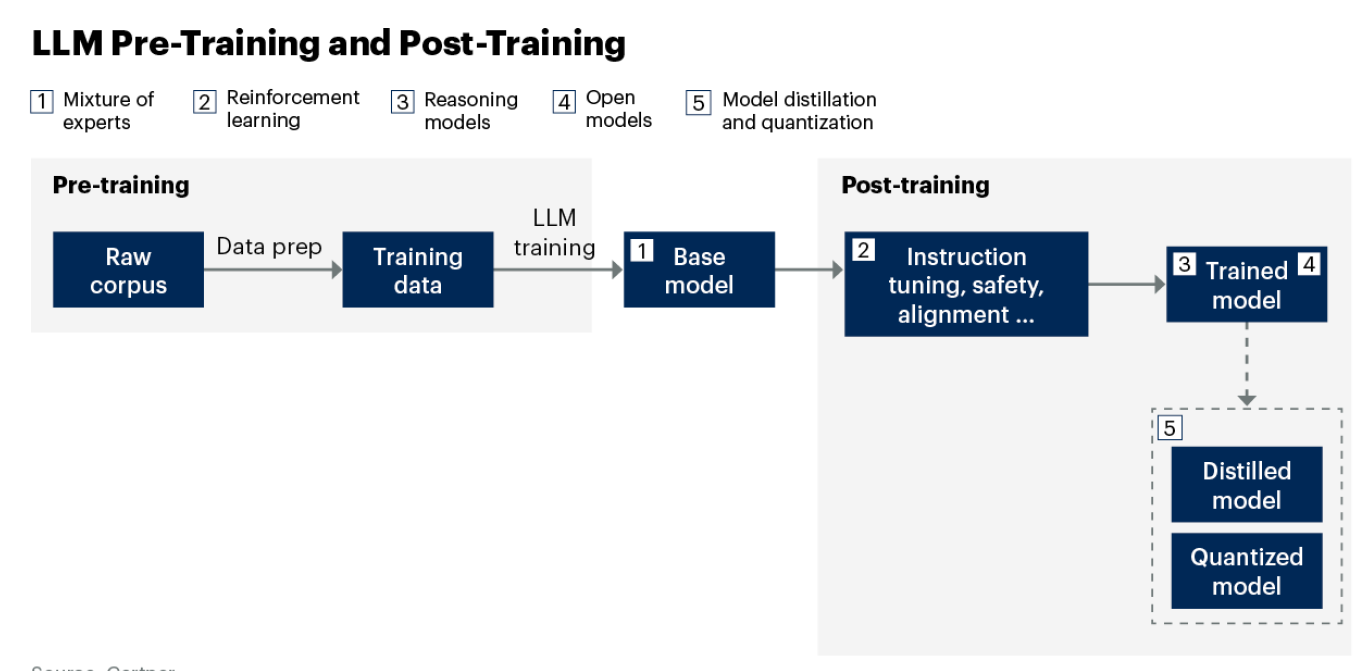
(二)后训练
解决预训练模型无法遵循指令等问题,通过监督微调等增强能力,使其能遵循指令、识别有害行为并符合人类偏好。
三、五项技术发展
(一)专家混合(MoE)
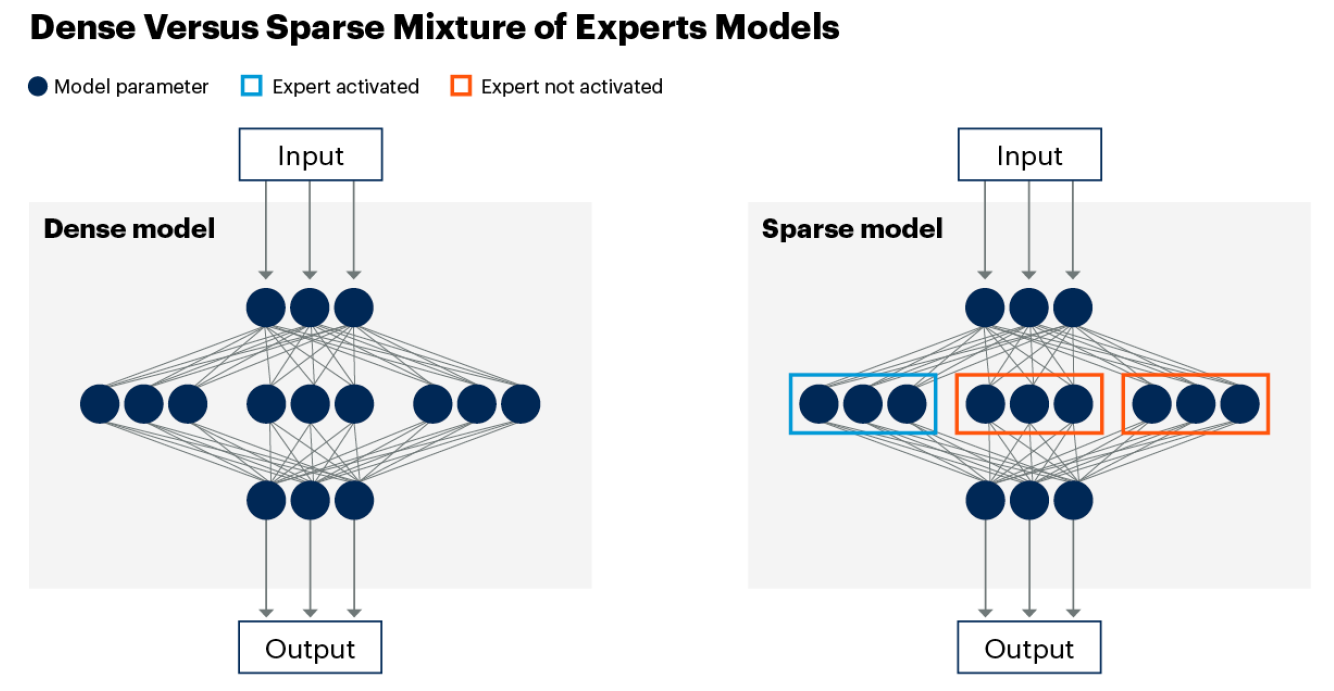
-
背景:Transformer架构虽强大,但扩展和性能面临挑战,主要因密集注意力机制导致所有参数在处理时激活,增加GPU内存需求。
-
技术细节:MoE引入稀疏性,通过“专家”学习不同信息,推理时仅激活相关专家。路由器决定激活哪些专家。例如, punctuation专家和verbs专家。</






