文章目录
- 一、关于 LaTeX OCR
- 1、项目概览
- 架构图
- 2、相关链接资源
- 3、功能特性
- 二、安装配置
- 基础环境要求
- Linux 安装
- Mac 安装
- 三、使用指南
- 1、快速训练(小数据集)
- 2、完整训练(大数据集)
- 四、可视化功能
- 训练过程可视化
- 预测过程可视化
- 五、模型评估
- 六、技术细节
- 数据处理流程
- 模型架构
一、关于 LaTeX OCR
1、项目概览
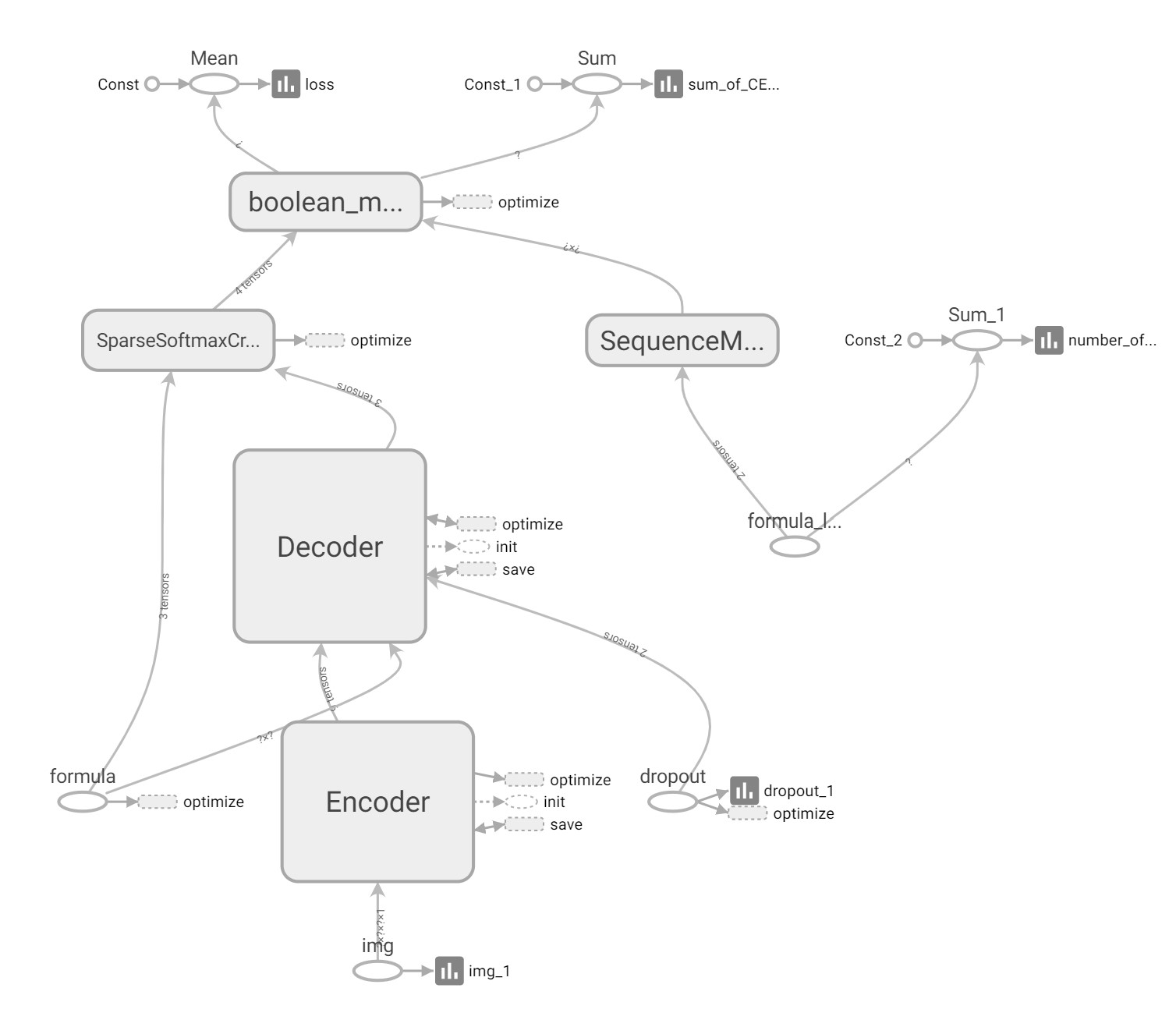
基于 Seq2Seq + Attention + Beam Search 架构的数学公式识别系统,可将数学公式图片转换为 LaTeX 代码。

架构图
2、相关链接资源
- GitHub:https://github.com/LinXueyuanStdio/LaTeX_OCR
- 增强版:https://github.com/LinXueyuanStdio/LaTeX_OCR_PRO
- 数据集来源:im2latex-100k , arXiv:1609.04938
- 参考论文:
- Show, Attend and Tell
- Harvard’s paper and dataset
- Seq2Seq for LaTeX generation
3、功能特性
1、多平台支持
- 支持 Linux/Mac/Windows 系统
- 提供一键安装脚本
2、可视化训练
- 集成 TensorBoard 训练过程可视化
- 支持注意力机制可视化
3、评估指标
- 支持 perplexity/EditDistance/BLEU-4/ExactMatchScore 四种评估指标
二、安装配置
基础环境要求
- Python 3.5 + TensorFlow 1.12.2
- LaTeX (latex 转 pdf)
- Ghostscript (图片处理)
- ImageMagick (pdf 转 png)
Linux 安装
一键安装
make install-linux
或分步安装
# 创建环境
virtualenv env35 --python=python3.5
source env35/bin/activate
pip install -r requirements.txt# 安装 latex (latex 转 pdf)
sudo apt-get install texlive-latex-base texlive-latex-extra# 安装 ghostscript
sudo apt-get update && sudo apt-get install ghostscript libgs-dev# 安装 magick (pdf 转 png)
wget http://www.imagemagick.org/download/ImageMagick.tar.gz
tar -xvf ImageMagick.tar.gz
cd ImageMagick-7.*
./configure --with-gslib=yes
make
sudo make install
sudo ldconfig /usr/local/lib
rm ImageMagick.tar.gz
rm -r ImageMagick-7.*
Mac 安装
一键安装
make install-mac
分步安装
sudo pip install -r requirements.txt
wget http://www.imagemagick.org/download/ImageMagick.tar.gz
tar -xvf ImageMagick.tar.gz
cd ImageMagick-7.*
./configure --with-gslib=yes
make
sudo make install
rm ImageMagick.tar.gz
rm -r ImageMagick-7.*
三、使用指南
1、快速训练(小数据集)
一键训练(约2分钟)
make small
分步执行
python build.py --data=configs/data_small.json --vocab=configs/vocab_small.json
python train.py --data=configs/data_small.json --vocab=configs/vocab_small.json --training=configs/training_small.json --model=configs/model.json --output=results/small/
python evaluate_txt.py --results=results/small/
python evaluate_img.py --results=results/small/
2、完整训练(大数据集)
一键训练(2-3小时)
make full
分步执行
python build.py --data=configs/data.json --vocab=configs/vocab.json
python train.py --data=configs/data.json --vocab=configs/vocab.json --training=configs/training.json --model=configs/model.json --output=results/full/
python evaluate_txt.py --results=results/full/
python evaluate_img.py --results=results/full/
四、可视化功能
训练过程可视化
# 小数据集
cd results/small
tensorboard --logdir ./# 大数据集
cd results/full
tensorboard --logdir ./
预测过程可视化
python visualize_attention.py --image=data/images_test/6.png --vocab=configs/vocab.json --model=configs/model.json --output=results/full/
五、模型评估
| 指标 | 训练分数 | 测试分数 |
|---|---|---|
| perplexity | 1.39 | 1.44 |
| EditDistance | 81.68 | 80.45 |
| BLEU-4 | 78.21 | 75.42 |
| ExactMatchScore | 13.93 | 12.44 |
六、技术细节
数据处理流程
- 获取 LaTeX 公式数据
- 公式规范化处理
- 生成图片数据集
- 构建字典和映射文件
模型架构
- Encoder: CNN
- Decoder: LSTM/GRU
- 注意力机制层
- Beam Search/Greedy 输出策略
伊织 xAI 2025-05-18(日)




