使用知识图谱处理大数据:一份详细指南
大数据本身蕴含着无数的故事,但发现这些数据的价值需要大量的人工挖掘。知识图谱让这一切变得更容易,它可以通过将分散的信息连接成结构化、可搜索的格式,将数据发现时间减少高达70%。这意味着少些挖掘,多些发现。
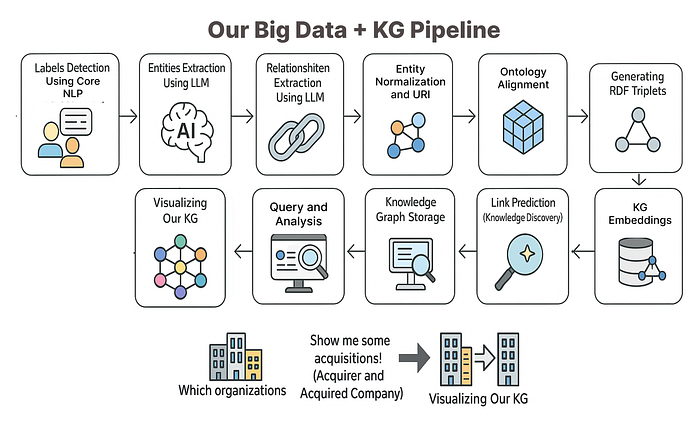
我们将基于理论知识和方法,创建一个关于如何使用知识图谱方法处理大数据的端到端管道项目。
设置环境
首先,我们需要准备工具。我们将使用一些关键的 Python 库来完成任务。让我们安装它们。
# 安装库(仅运行一次)
pip install openai rdflib spacy pyvis datasets scikit-learn matplotlib tqdm pandas
现在我们已经安装好了,让我们将所有内容导入到脚本中。
# 导入必要的库
import os
import re
import json
from collections import Counter
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
import pandas as pd
import time# NLP 和知识图谱库
import spacy
from rdflib import Graph, Literal, Namespace, URIRef
from rdflib.namespace import RDF, RDFS, XSD, SKOS # 添加 SKOS 用于 altLabel# OpenAI 客户端用于 LLM
from openai import OpenAI# 可视化
from pyvis.network import Network# Hugging Face 数据集库
from datasets import load_dataset# 用于嵌入相似性
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
完美!我们的工具箱已经准备好了。所有必要的库都已加载到我们的环境中。
我们的大数据概览
在本博客中,我们将处理 CNN/DailyMail 数据集。它包含300K+篇新闻文章及其人工编写的摘要,是提取实体、关系和事件的丰富资源。
让我们加载这个数据集并打印一个样本。
# 使用特定版本有助于保持一致性
cnn_dm_dataset = load_dataset("cnn_dailymail", "3.0.0")
我们使用的是版本 3.0.0,这是该数据集的最新版本。
让我们打印一些关于这些数据的基本信息。
# 计算总记录数
total_records = len(cnn_dm_dataset["train"]) + len(cnn_dm_dataset["validation"]) + len(cnn_dm_dataset["test"])# 打印总数和一个样本记录
print(f"数据集中的总记录数:{total_records}\n")
print("训练数据集中的样本记录:")
print(cnn_dm_dataset["train"][0]#### 输出结果 ####
数据集中的总记录数:311971训练数据集中的样本记录:
{'article': 'LONDON, England (Reuters) -- Harry Potter star Daniel ...'}
因此,我们总共有300K+篇新闻文章,从这些文章中提取洞见肯定是一项具有挑战性的任务。然而,我们将使用知识图谱来了解它们如何对我们有用。
数据获取与预处理
使用整个数据集(300K+篇新闻文章)创建知识图谱是不可行的,因为数据中并非所有内容都是相关的。新闻可以分类,例如,技术相关的新闻可以形成一个大型知识图谱,而体育新闻则形成另一个。
大数据知识图谱链的早期阶段是将数据分解成更小的部分。
由于我们处理的是新闻文章,我们可以使用基于关键词的方法将300K+数据集分解成不同的子集。
让我们创建那个 ACQUISITION_KEYWORDS 列表,它将帮助我们从大数据集中筛选出相关内容。
# 定义与技术公司收购相关的关键词
ACQUISITION_KEYWORDS = ["acquire", "acquisition", "merger", "buyout", "purchased by", "acquired by", "takeover"]
TECH_KEYWORDS = ["technology", "software", "startup", "app", "platform", "digital", "AI", "cloud"]
这些关键词通常在对数据进行文本分析时出现,但为了简化,我们预先定义了它们。它们是常见的,很可能频繁出现在新闻文章中。
我们将使用预先定义的关键词,针对技术公司收购、合并或收购的新闻文章。
# 只取训练集
cnn_dm_dataset_train = cnn_dm_dataset['train']# 初始化一个空列表,用于存储筛选后的文章
filtered_articles = []# 遍历数据集,根据关键词筛选文章
for record in cnn_dm_dataset_train:# 检查文章文本中是否出现任何关键词found_keyword = Falsefor keyword in ACQUISITION_KEYWORDS:if keyword.lower() in record['article'].lower():found_keyword = Truebreak # 找到关键词后停止# 如果找到关键词,则将文章添加到筛选列表中if found_keyword:filtered_articles.append(record)
现在我们已经筛选了文章,让我们检查筛选后文章的总数以及其中一个样本。
# 打印筛选后文章的总数
print(f"筛选后文章的总数:{len(filtered_articles)}")# 打印一个筛选后文章的样本
print("\n筛选后文章的样本:")
print(filtered_articles[0]['article'])### 输出结果 ####
筛选后文章的总数:65249筛选后文章的样本:
SAN DIEGO, California (CNN) -- You must know whats really driving the
immigration debate ...
我们的筛选后文章大约有65K篇,因此一旦生成了数据子集,下一步就是清理记录。
我们需要尽可能多地删除不必要的信息,因为这些数据稍后将作为 LLM 的输入,这可能会影响处理大数据集时的成本和性能。
在我们的新闻数据中,我们可以删除链接、不必要的字符、频道名称等。让我们来做这件事。
cleaned_articles = []for record in filtered_articles:text = record['article']# 使用正则表达式进行基本清理text = re.sub(r'^\(CNN\)\s*(--)?\s*', '', text) # 删除 (CNN) 前缀text = re.sub(r'By .*? for Dailymail\.com.*?Updated:.*', '', text, flags=re.I | re.S) # 删除作者信息text = re.sub(r'PUBLISHED:.*?UPDATED:.*', '', text, flags=re.I | re.S) # 删除发布/更新信息text = re.sub(r'Last updated at.*on.*', '', text, flags=re.I) # 删除最后更新时间text = re.sub(r'https?://\S+|www\.\S+', '[URL]', text) # 替换 URLtext = re.sub(r'<.*?>', '', text) # 删除 HTML 标签text = re.sub(r'\b[\w.-]+@[\w.-]+\.\w+\b', '[EMAIL]', text) # 替换电子邮件text = re.sub(r'\s+', ' ', text).strip() # 规范化空白字符# 存储清理后的结果cleaned_articles.append({"id": record['id'],"cleaned_text": text,"summary": record.get('highlights', '')})
通过对筛选后的新闻进行循环,我们删除了所有不必要的垃圾数据,这些数据对于知识图谱的构建并不必要。
这种清理是基于我自己的知识和对数据的观察。当然,当团队合作处理数据集时,需要付出更多的努力,因为这进一步减少了每篇文章的大小。
使用 Core NLP 定义实体
我们目前有65K+篇新闻文章,从这些文章中提取实体是一项具有挑战性的步骤。我们通常使用 LLM 从每个文本片段中提取实体,但 LLM 应该寻找什么样的实体呢?
如果我们让 LLM 自由发挥,它可能会从每个片段中提取不同的实体。为了避免这种情况,我们必须使用 NLP 技术来定义一组固定的实体,以便 LLM 聚焦于这些特定的实体。
有许多方法可以做到这一点,例如使用嵌入和其他技术,但我们将使用 SpaCy 训练的模型。它将分析我们的数据,从中提取实体标签,然后我们将使用这组标签指导 LLM 从每篇文章中提取这些特定的实体。
# 下载并加载 SpaCy 的英语语言模型
# (只需运行一次)
spacy.cli.download("en_core_web_sm")
nlp = spacy.load("en_core_web_sm")# 初始化一个计数器,用于存储实体标签计数(例如,PERSON、ORG、DATE)
entity_counts = Counter()# 遍历每篇文章并应用 SpaCy 的命名实体识别
for article in cleaned_articles:text = article['cleaned_text'] # 获取清理后的文本doc = nlp(text) # 使用 SpaCy 处理文本# 统计文本中找到的每个实体标签for ent in doc.ents:entity_counts[ent.label_] += 1
让我们打印实体计数并查看一个样本。
print(entity_counts)### 输出结果 ###
spaCy 实体计数:ORG: 2314GPE: 1253PERSON: 524NORP: 3341CARDINAL: 7542DATE: 6344...
让我们也绘制这些标签的图表,以便更好地直观了解我们的数据在实体及其数量方面的分布情况。
# 提取标签和计数
labels, counts = zip(*entity_counts)# 绘制条形图
plt.figure(figsize=(12, 7)) # 设置图形大小
plt.bar(labels, counts, color='skyblue') # 创建条形图
plt.title("通过 spaCy 的顶级实体类型分布") # 图表标题
plt.ylabel("频率") # Y 轴标签
plt.xlabel("实体标签") # X 轴标签
plt.xticks(rotation=45, ha="right") # 旋转 X 轴标签以便更好地显示
plt.tight_layout() # 调整布局以确保所有内容都合适
plt.show() # 显示图表
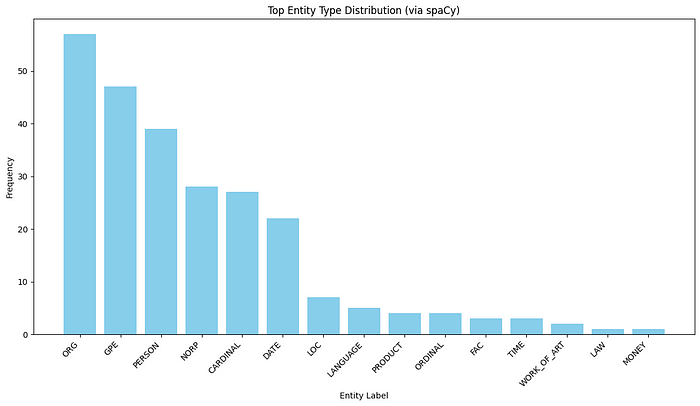
我们目前使用的是 SpaCy 的小型模型,但我们可以切换到一个更大的模型。这可能会从我们的数据中提取更多有效且更深入的标签。
这些标签将被我们的 LLM 用来从文章中提取实体。我们将使用一个 Phi-4 微软模型,它将使用这些实体计数作为从每篇文章中提取实体的来源。
使用 LLM 提取实体
实体,它们将作为知识图谱中的节点,需要被提取出来。
为此,我们必须定义一个系统提示(它将指导 LLM 如何使用 SpaCy 处理提取的实体),用户提示(在我们的例子中,是文章),以及一些其他组件。
首先,我们设置与 LLM 的连接。让我们继续进行。
# 使用提供的配置初始化 OpenAI 客户端
client = OpenAI(base_url="YOUR LLM API Provider link",api_key="LLM API KEY"
)
我们需要一个辅助函数来打包我们的请求并将其发送给 LLM。这个函数将接受我们的系统提示、用户提示(文章文本)和模型名称。
def call_llm(system_prompt, user_prompt, model_name):"""向语言模型(LLM)发送请求,以根据提供的提示提取实体。参数:system_prompt (str): LLM 的指令或上下文(例如,如何行为)。user_prompt (str): 包含要提取实体的文本的用户输入。model_name (str): 要使用的 LLM 模型的标识符(例如,“gpt-4”)。返回:str: LLM 的 JSON 格式字符串响应,或者如果客户端不可用则为 None。"""# 构造并发送聊天完成请求给 LLMresponse = client.chat.completions.create(model=model_name,messages=[{"role": "system", "content": system_prompt}, # 系统级指令{"role": "user", "content": user_prompt} # 用户提供的输入],)# 提取并返回响应内容(JSON 字符串)return response.choices[0].message



