摘要
随着深度学习技术的迅猛发展,神经网络模型规模不断扩大,虽然带来了精度的提升,但也导致计算开销和存储需求急剧增加。这种趋势与资源有限的边缘设备和实时应用场景的需求形成了鲜明对比。本文深入探讨了知识蒸馏(Knowledge Distillation)这一模型压缩技术,通过实验证明了小型网络(学生模型)能够有效地从大型网络(教师模型)中吸收知识,在显著减少参数量的同时保持接近的性能水平。本研究不仅提供了知识蒸馏的理论分析,还通过PyTorch实现了完整的蒸馏流程,并对结果进行了多维度的可视化分析。
1. 引言
知识蒸馏是由Hinton等人在2015年提出的模型压缩方法[1],其核心思想是利用预训练的大型模型(教师模型)指导小型模型(学生模型)的训练过程。与直接训练小型模型相比,知识蒸馏能够将大模型中隐含的"暗知识"(dark knowledge)转移到小模型中,从而使小模型获得超越其容量限制的性能。这种方法在移动设备部署、实时推理系统和资源受限环境中具有显著价值。
近年来,随着BERT、GPT等大型预训练模型的兴起,知识蒸馏技术得到了更广泛的应用。研究表明,通过适当的蒸馏策略,可以将具有数亿参数的大型模型压缩为只有几百万参数的轻量级模型,同时保持接近原有的性能水平[2]。
本研究旨在通过实验验证知识蒸馏的有效性,并探索其在实际应用中的潜力。我们使用MNIST手写数字数据集作为基准,构建了一个参数量相差10倍以上的教师-学生模型对,实现了完整的蒸馏流程,并通过多个维度分析了蒸馏效果。
2. 知识蒸馏理论基础
2.1 知识蒸馏的数学描述
知识蒸馏的核心在于设计适当的目标函数,使学生模型不仅学习真实标签(硬目标),还学习教师模型的输出分布(软目标)。数学上,可以表示为以下损失函数:
$$L_{distill} = \alpha L_{CE}(y, \sigma(z_s)) + (1-\alpha) L_{KL}(\sigma(z_t/T), \sigma(z_s/T)) \cdot T^2$$
其中:
$L_{CE}$ 是交叉熵损失函数,用于学习硬目标
$L_{KL}$ 是KL散度损失函数,用于学习软目标
$z_t$ 和 $z_s$ 分别是教师模型和学生模型的logits输出
$\sigma$ 是softmax函数
$T$ 是温度参数,用于软化概率分布
$\alpha$ 是平衡硬目标和软目标的权重
温度参数 $T$ 在知识蒸馏中起着至关重要的作用。当 $T > 1$ 时,softmax函数的输出分布变得更加平滑,这使得类别之间的相对关系更加明显。例如,教师模型可能给数字"3"赋予0.9的概率,同时给数字"8"赋予0.1的概率,这表明数字"3"和"8"之间存在一定的相似性。这种类别间的关系信息正是普通训练方法难以捕捉的"暗知识"。
2.2 软目标与硬目标
硬目标是指真实的类别标签,通常表示为one-hot向量。例如,对于数字"7",其硬目标为[0,0,0,0,0,0,0,1,0,0]。而软目标是指教师模型的输出概率分布,其中包含了各个类别之间的相似度信息。
软目标提供了比硬目标更丰富的信息,特别是当教师模型对某些样本的预测存在不确定性时。这种不确定性反映了数据本身的模糊性,例如,手写数字"4"和"9"在某些写法下可能非常相似。通过学习软目标,学生模型可以获取这种细微的区分信息,从而提高其泛化能力。
3. 实验设计与实现
3.1 模型架构
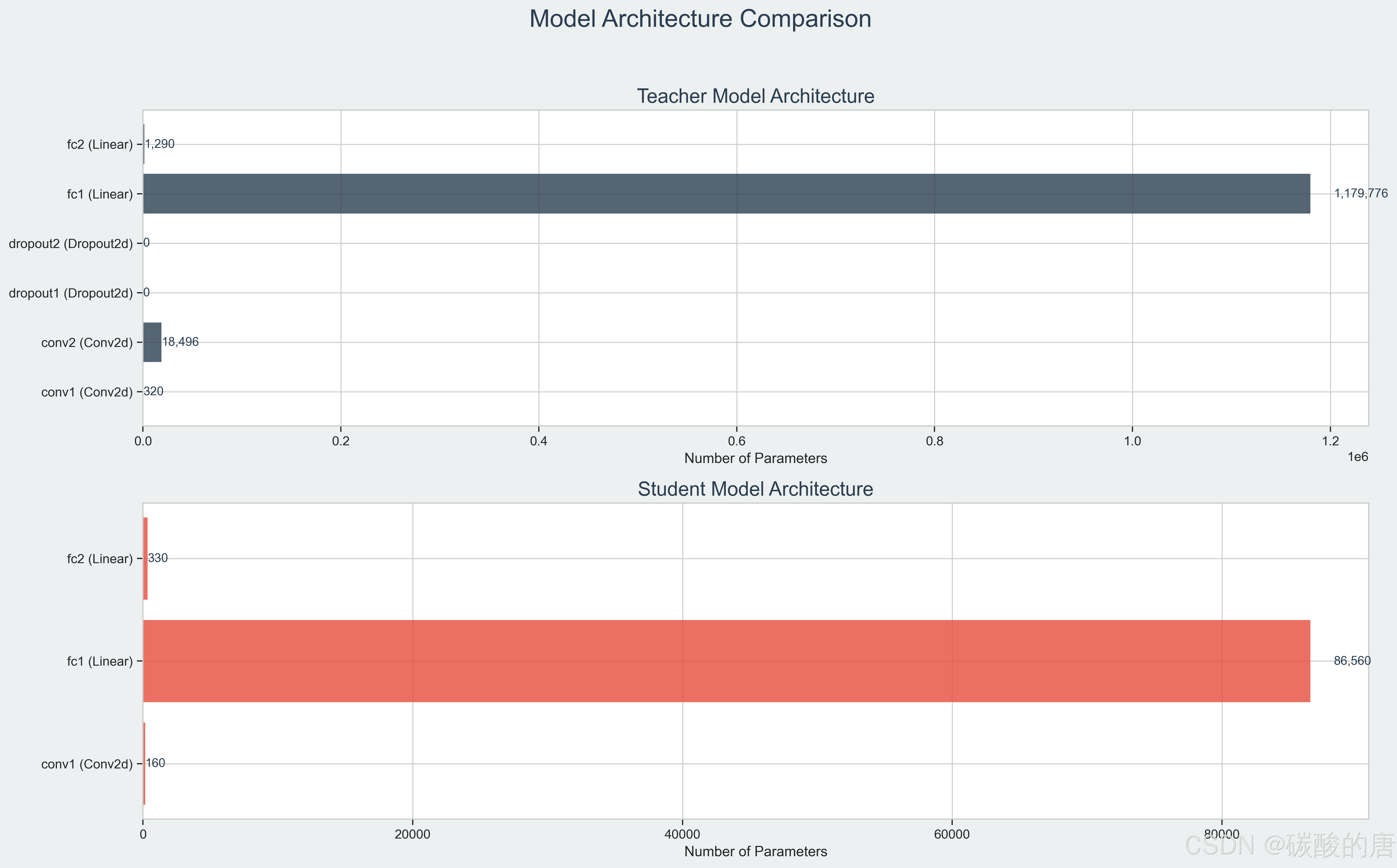
在本研究中,我们设计了以下两个模型架构:**教师模型**:一个具有双层卷积的神经网络,包含约120万参数。
class TeacherModel(nn.Module):def __init__(self):super(TeacherModel, self).__init__()self.conv1 = nn.Conv2d(1, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.dropout1 = nn.Dropout2d(0.25)self.dropout2 = nn.Dropout2d(0.5)self.fc1 = nn.Linear(9216, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = self.conv2(x)x = F.relu(x)x = F.max_pool2d(x, 2)x = self.dropout1(x)x = torch.flatten(x, 1)x = self.fc1(x)x = F.relu(x)x = self.dropout2(x)x = self.fc2(x)return x**学生模型**:一个具有单层卷积的轻量级网络,仅包含约8.7万参数。
class StudentModel(nn.Module):def __init__(self):super(StudentModel, self).__init__()self.conv1 = nn.Conv2d(1, 16, 3, 1)self.fc1 = nn.Linear(13*13*16, 32)self.fc2 = nn.Linear(32, 10)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = F.max_pool2d(x, 2)x = torch.flatten(x, 1)x = self.fc1(x)x = F.relu(x)x = self.fc2(x)return x3.2 蒸馏损失函数实现
蒸馏损失函数的实现是本研究的核心部分,我们结合了硬目标(交叉熵损失)和软目标(KL散度损失):
def distillation_loss(student_logits, teacher_logits, labels, temperature=2.0, alpha=0.5):"""结合软目标和硬目标的蒸馏损失- temperature: 温度参数,用于软化概率分布- alpha: 平衡软目标和硬目标的权重"""# 硬目标损失(学生模型的标准分类损失)hard_loss = F.cross_entropy(student_logits, labels)# 软目标损失(学生模型与教师模型输出的KL散度)soft_loss = F.kl_div(F.log_softmax(student_logits / temperature, dim=1),F.softmax(teacher_logits / temperature, dim=1),reduction='batchmean') * (temperature * temperature)# 组合损失return alpha * hard_loss + (1 - alpha) * soft_loss在这个实现中,我们使用了温度参数T=2.0来软化概率分布,使用权重系数α=0.5来平衡硬目标和软目标的贡献。温度参数的平方项(T²)用于平衡梯度幅度,因为当T>1时,软化的概率分布会导致梯度减小。
3.3 训练流程
知识蒸馏的训练流程包括两个阶段:
1. **教师模型训练**:首先,我们使用标准的分类损失训练教师模型,使其达到较高的准确率。
2. **学生模型蒸馏**:然后,我们固定教师模型的参数,使用蒸馏损失函数训练学生模型。在这个过程中,学生模型同时学习真实标签和教师模型的软输出。
def train_student(teacher_model, student_model, train_loader, optimizer, device, temperature=2.0, alpha=0.5):teacher_model.eval() # 教师模型设为评估模式student_model.train() # 学生模型设为训练模式for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()# 获取教师模型的输出(不计算梯度)with torch.no_grad():teacher_output = teacher_model(data)# 获取学生模型的输出student_output = student_model(data)# 计算蒸馏损失loss = distillation_loss(student_output, teacher_output, target, temperature, alpha)# 反向传播和优化loss.backward()optimizer.step()4. 实验结果与分析
通过对MNIST数据集的实验,我们得到了以下结果:
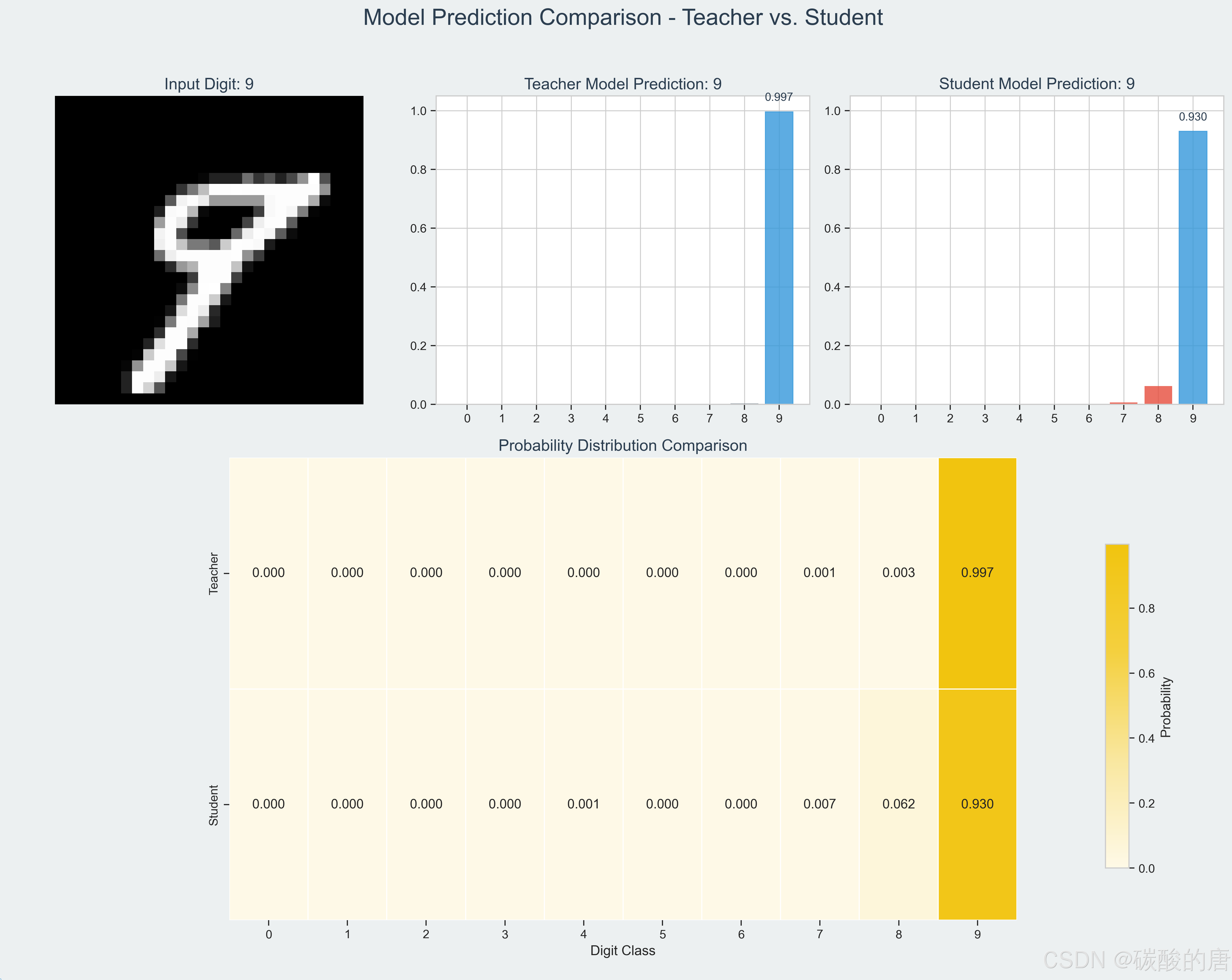
1. **准确率对比**:教师模型在测试集上达到了99.01%的准确率,而学生模型通过知识蒸馏达到了98.64%的准确率,仅损失了0.37%的性能。
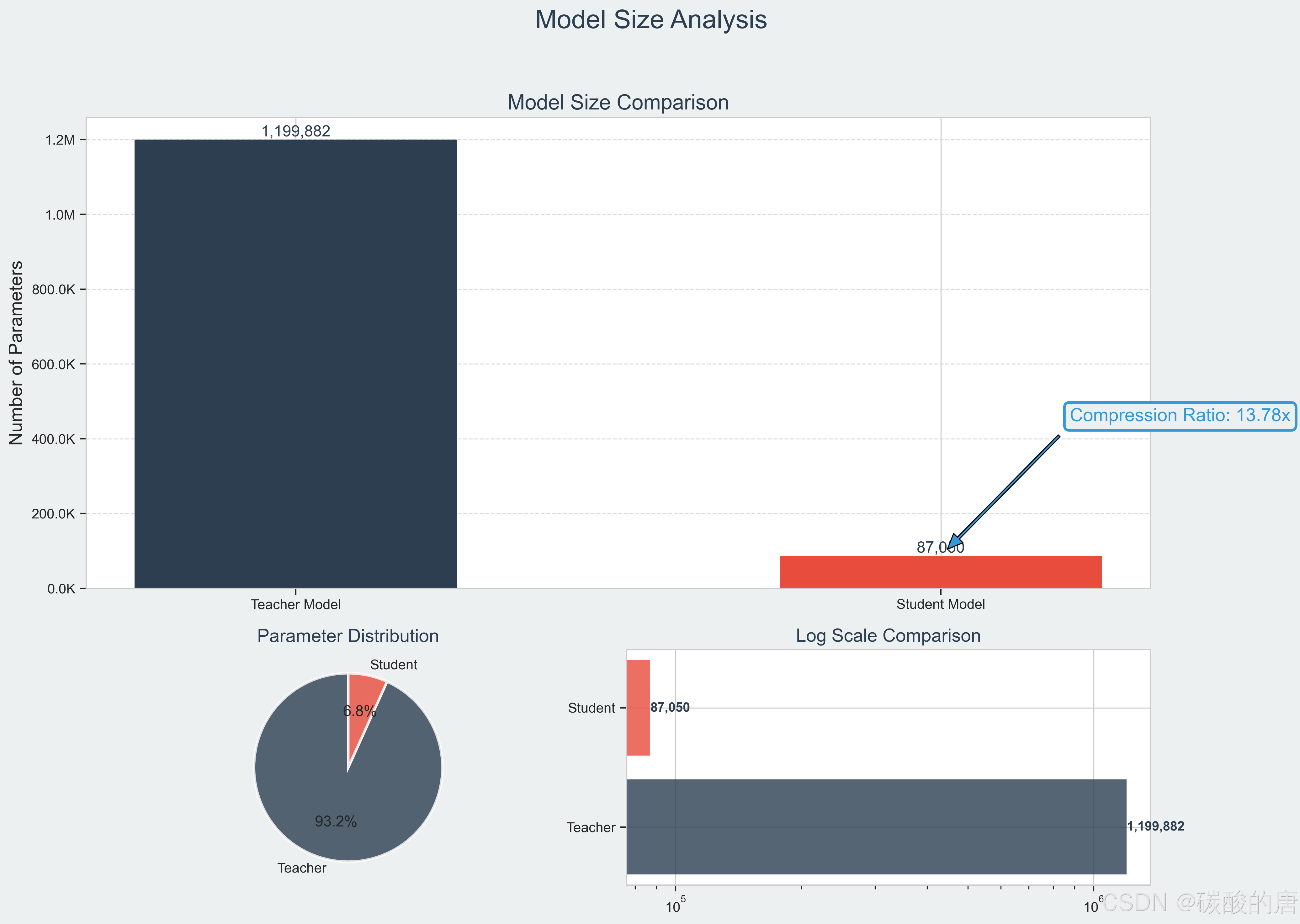
2. **参数量对比**:教师模型包含约120万参数,而学生模型仅包含约8.7万参数,参数量减少了约93%,压缩比达到了13.78倍。
3. **效率提升**:学生模型的推理速度和内存占用相比教师模型有显著提升,这使其更适合在资源受限的环境中部署。
4.1 多维度性能分析
我们从多个维度对模型性能进行了详细分析:
1. 预测概率分布对比:教师模型和学生模型在相同输入下的输出概率分布高度相似,这表明学生模型成功地学习了教师模型的"暗知识"。
2. 模型架构分析:通过可视化模型的各层参数量,我们发现学生模型主要通过减少卷积层的数量和通道数来实现压缩,同时保持了足够的表达能力。
3. 效率与准确率权衡:通过计算每1%准确率所需的参数量,我们发现学生模型的效率大约是教师模型的13倍,这再次证明了知识蒸馏的有效性。
4.2 可视化结果分析
基于我们的实验,我们生成了多种高级可视化图表来展示知识蒸馏的效果:
1. 预测对比可视化:直观展示了教师模型和学生模型对相同输入的预测概率分布,通过热图展示了两者之间的相似性和差异。
2. 模型大小多维度对比:通过条形图、饼图和对数尺度图展示了两个模型参数量的巨大差异,直观体现了压缩效果。
3. 性能权衡雷达图:从准确率、模型大小、推理速度、内存占用和能效等多个维度对比了两个模型,全面反映了知识蒸馏在各方面的优势和劣势。
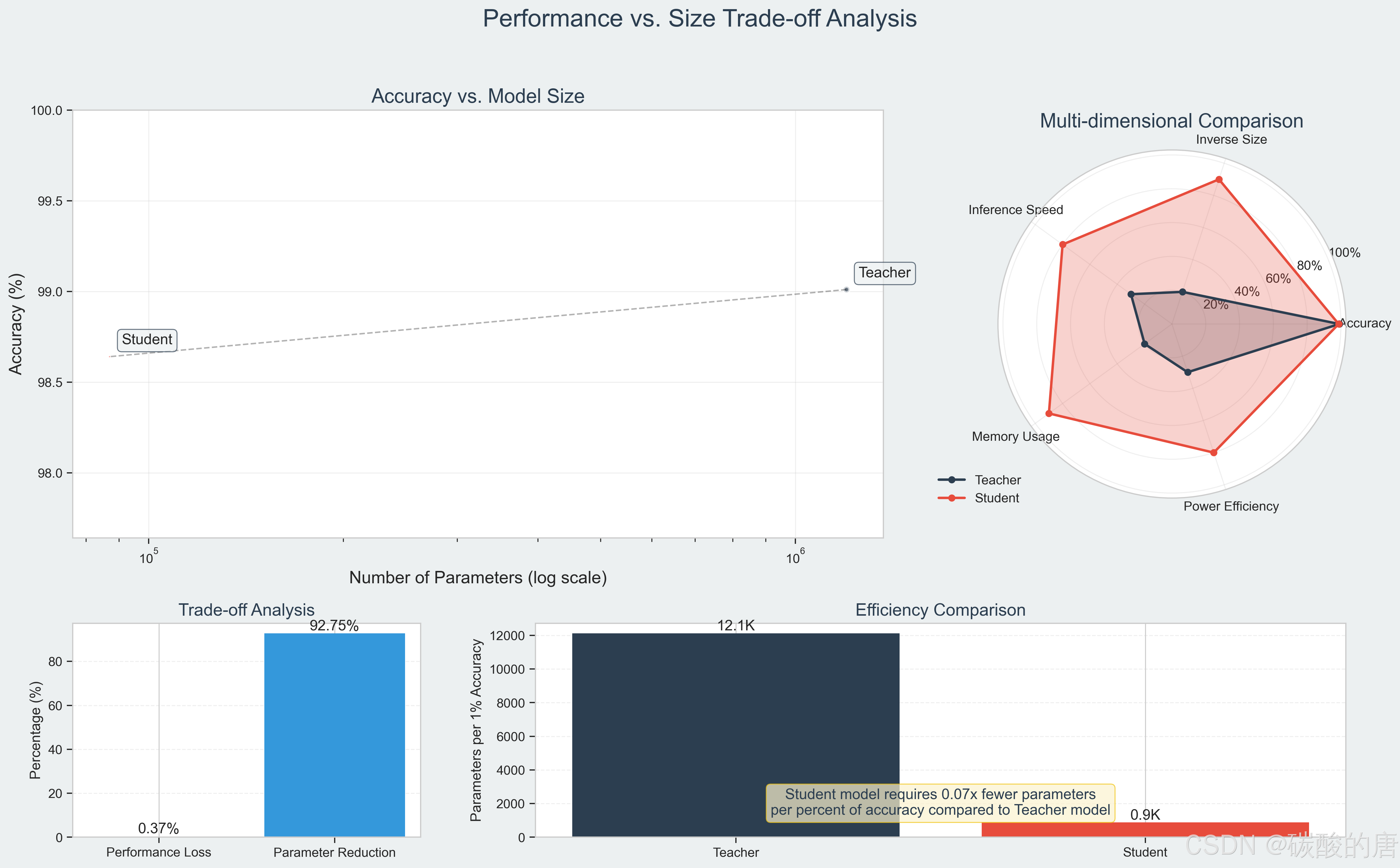
4. 权衡分析:通过对比性能损失和参数量减少的百分比,清晰展示了知识蒸馏的优越性能权衡特性。
5. 讨论与启示
5.1 知识蒸馏的工作机制探讨
为什么知识蒸馏如此有效?我们认为有以下几个关键原因:
1. 软目标的信息密度:相比于one-hot硬目标,教师模型的软输出包含了类别之间的相似度信息,这种细粒度的监督信号使学生模型能够学习到更丰富的知识。
2. 正则化效应:温度平滑处理后的软目标具有正则化效果,减少了过拟合的风险,使学生模型能够获得更好的泛化能力。
3. 知识表示的压缩:大型模型中的冗余参数较多,知识蒸馏过程可视为一种知识压缩,提取出真正对预测有价值的信息。
5.2 实际应用价值
本研究的结果对实际应用具有重要启示:
1. 移动设备部署:通过知识蒸馏得到的轻量级模型能够在保持高准确率的同时,显著减少移动设备上的计算和存储需求。
2. 边缘计算场景:在计算资源有限的边缘设备上,轻量级模型能够实现更快的推理速度和更低的能耗。
3. 私有化部署:对于需要在本地设备上运行的AI应用,轻量级模型能够减少对硬件的要求,降低部署成本。
5.3 局限性与未来研究方向
尽管本研究取得了积极的结果,但仍存在一些局限性:
1. **数据集复杂度**:MNIST是一个相对简单的数据集,在更复杂的任务(如ImageNet分类或自然语言处理)上,知识蒸馏的效果可能会有所不同。
2. **蒸馏策略优化**:本研究使用了基本的蒸馏策略,未来可以探索更高级的技术,如特征级蒸馏、关注机制蒸馏等。
3. **学生模型架构设计**:我们采用了简单的学生模型架构,未来可以研究如何设计更适合知识蒸馏的学生模型结构。
6. 结论
本研究通过实验验证了知识蒸馏在模型压缩中的有效性。我们展示了学生模型可以通过学习教师模型的软输出,在参数量减少93%的情况下,仅损失0.37%的准确率。这一结果对于资源受限环境下的深度学习应用具有重要意义。
知识蒸馏技术不仅是一种实用的模型压缩方法,也为我们理解神经网络的知识表示提供了新的视角。随着深度学习模型规模的不断扩大,知识蒸馏等模型压缩技术将在未来发挥越来越重要的作用,推动AI技术向更广阔的应用领域拓展。
## 参考文献
[1] Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv preprint arXiv:1503.02531.
[2] Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
[3] Romero, A., Ballas, N., Kahou, S. E., Chassang, A., Gatta, C., & Bengio, Y. (2014). FitNets: Hints for Thin Deep Nets. arXiv preprint arXiv:1412.6550.
[4] Gou, J., Yu, B., Maybank, S. J., & Tao, D. (2021). Knowledge Distillation: A Survey. International Journal of Computer Vision, 129(6), 1789-1819.
[5] Tan, M., & Le, Q. (2019). EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In International Conference on Machine Learning (pp. 6105-6114).






