可观测性
什么是可观测性
可观察性(Observability)是从外部输出知识中推断所获得,可理解为衡量一个系统内部状态的方法。可观测性是一种能力,它能帮助你回答系统内部发生了什么——无需事先定义每种可能的故障或状态。系统的可观测性越高,就可以根据已识别的性能问题更快速、更准确地定位到其根本原因,而无需进行额外的测试或编码。
举个例子,水处理厂的操作员如果无法看到水管的内部状况,就无法监测到水的正常流动,流动的方式,以及水质的干净程度。但在管道内可以添加可观察性的工具——流量计和传感器后,状况就截然不同,这些工具将通过遥测连接到仪表板,帮助操作员能够完全掌握管道中水流的情况,并及时根据状况进行调整,大大提高了工作效率。
可观测性是应用程序性能监控 (APM)和网络性能管理 (NPM)数据收集方法的自然演变,它能更好地适应云原生应用程序部署日益加快、分布式和动态的本质。可观测性并不会取代监控,但可以完善监控以及 APM 和 NPM。
为什么需要可观测性
现如今,企业正在迅速采用现代化开发实践。这包括敏捷开发、持续集成和持续部署 (CI/CD)、DevOps、多种编程语言。
企业也在采用云原生技术,如微服务、Docker 容器、Kubernetes。因此,这些企业正以前所未有的速度将更多服务推向市场。但在此过程中,他们也在部署新的应用程序组件,每种服务使用不同的语言开发、在 Kubernetes + 微服务 + 异步消息 的架构中,应用之间的调用变得极其复杂。传统方式很难排查问题。比如:
- 一个订单失败,到底是前端?中间件?后端?哪个组件异常?
- 日志查不出东西,但用户反馈就是卡顿;
- 应用指标显示正常,但系统无相应或超时。
这时候,“可观测性”能帮助你,它可以针对每个应用程序用户的请求或事务创建高精确度、上下文丰富且完全相关的记录。
快速定位问题:
Trace + Log 可以告诉你:“哪个服务、哪一段代码、哪一次请求出了问题”。
主动发现异常:
Metric + 告警可以告诉你:“服务 QPS 降低了、错误率升高了”,即使你没看到用户投诉。
可观测性如何工作
可观测性平台通过集成应用程序和基础架构组件内置的现有检测功能,并提供各种工具来为这些组件添加检测功能,以便持续发现和收集性能遥测数据。 可观测性包含三大核心数据支柱。
| 类型 | 描述 | 举例 |
|---|---|---|
| Logs 日志 | 记录事件的时间线信息,常用于故障排查 | ERROR: failed to connect to DB |
| Metrics 指标 | 数值型数据,便于聚合、报警和绘图 | CPU usage 85%, request_count=1000 |
| Traces 链路追踪 | 展现请求如何在系统中流转 | 请求从 API 网关 → 订单服务 → 库存服务 |
可观测性的优势
- 快速定位问题(故障排查更高效)
- 能清楚看到请求从入口到各个服务的调用路径(Trace)。
- 能查看每一步的耗时、错误详情。
- 再也不用靠“猜”+ grep 日志找问题。
- 系统运行状态全面透明(从黑盒变成玻璃盒)
- CPU、内存只是基础指标,可观测性能告诉你:
- 访问量波动
- 请求成功率、错误率
- 每个组件的性能表现
- 支持黑盒 + 白盒监控,多维度了解系统状态。
- 异常发现更及时(主动报警)
- 使用 Metrics + Alerts,可以在问题刚发生时自动通知你,而不是等用户投诉。
- 可设定阈值规则,如:
- 错误率 > 1%
- 响应时间 > 1s
- QPS 突降
- 更好地理解系统行为(观测而非盲猜)
- 看到应用之间真实交互的链路图。
- 发现一些你“以为不会调用”的组件其实被调用了。
- 理解系统运行模式,帮助架构优化。
- 性能优化的依据
- 找出慢接口、慢 SQL、瓶颈节点。
- 基于数据调整服务部署、限流策略或数据库索引。
- 提高团队协作效率
- 开发、测试、运维、SRE 团队有统一的数据源。
- 不同角色可以快速对齐问题来源与解决路径。
- 提升系统稳定性与用户体验
- 可观测性让你提前发现潜在问题(比如内存泄漏、连接池耗尽);
- 系统出问题能快速恢复,用户影响最小化。
链路追踪
什么是链路追踪
链路追踪是分布式系统下的一个概念,它是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如,各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
想象一下,你点了一个外卖(发起了请求),但外卖迟迟没送到(请求响应慢),你想知道:
- 餐馆什么时候开始做的?
- 骑手什么时候接的单?
- 途中有没有绕路?堵车?
- 是哪一环节慢了?
链路追踪就像是在每一环节都装了摄像头,并记录时间、状态、异常等,最终汇总成一条完整的调用链路图。
链路追踪核心概念
Trace: 表示“一次完整的请求路径”,从用户发起请求到最终响应的全流程。(比如一个订单请求, 每个 Trace 有一个唯一的 Trace ID)
Span:Trace 中的每一步操作(比如调用了哪个服务、哪个方法)
Parent-Child: Span 之间通过父子关系构成树形结构。 (父子关系)
Context: 是 Trace 信息的“载体”,用于在服务间传递追踪信息(HTTP Header)
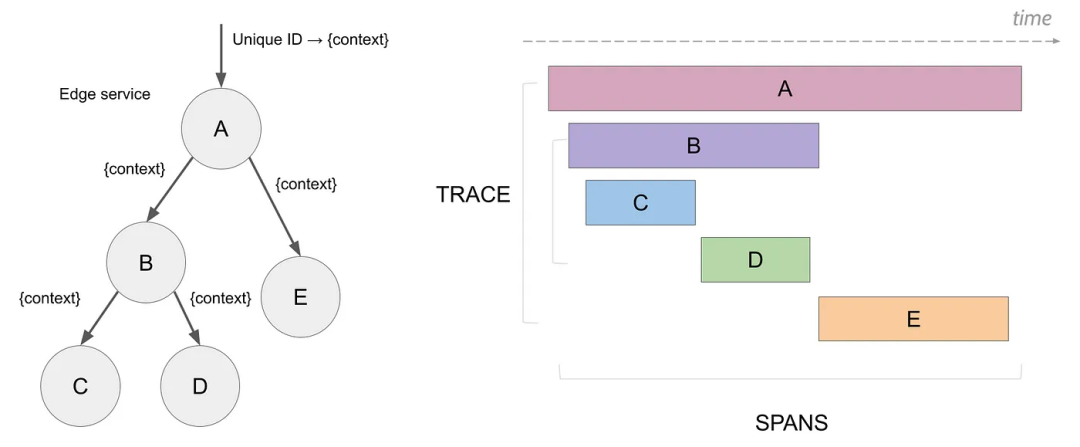
如何实现链路追踪
- 埋点
应用代码中集成 OpenTelemetry SDK / Jaeger SDK / Zipkin SDK,或者使用 Agent 自动注入。 - 传递 + 收集
把 TraceID 等信息通过 HTTP Header / gRPC Metadata 等方式传递给下游服务。 - 存储 + 展示
用 OpenTelemetry Collector / Tempo 等组件采集并转发 trace 数据,再用 Jaeger / Grafana 展示。
常见链路追踪方案
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Jaeger | CNCF 项目,社区活跃 支持 OpenTelemetry UI 直观、部署灵活 | 存储依赖较多(Elasticsearch/Clickhouse) UI 功能相对基础 | 中大型微服务系统 希望使用标准化工具链 |
| Zipkin | 启动快,轻量 组件少,易部署 支持多语言客户端 | 功能相对简单 与 OpenTelemetry 集成不如 Jaeger 完善 | 资源受限的环境 适合入门 |
| SkyWalking | 支持 APM(性能监控)+ Trace 一体 对 Java 支持极好(Agent 模式) 支持链路拓扑图 | 复杂度较高,学习成本较大 资源占用相对高 | Java 系统为主的企业系统 需要拓扑可视化 |
| OpenTelemetry + Collector + Jaeger/Tempo/Elastic APM | 灵活的标准化协议 多语言支持好 可自定义处理流程(Pipeline) | 配置较复杂,需要搭配 Collector 使用 学习成本较高 | 新系统从零建设可观测性 统一采集链路+日志+指标 |
| Tempo (Grafana Labs) | 支持与 Loki、Prometheus 集成 存储成本低(对象存储) 支持 OpenTelemetry | UI 功能依赖 Grafana 查询需结合 Logs/Metric 联动 | 已使用 Grafana Stack 的团队 关注成本控制和联动分析 |
| Elastic APM | 与 ELK 集成方便 提供自动化探针(Java、Node.js 等) 强大的查询分析能力 | 依赖 Elastic Stack 免费功能有限制(X-Pack) | 已使用 ELK 的团队 希望用一体化可观测方案 |
OpenTelemetry 介绍
OpenTelemetry 是什么
OpenTelemetry (OTel) 是一个开源可观测性框架,为我们提供了一个与供应商无关的可观测性标准,该框架由 CNCF(云原生计算基金会)托管的开源可观测性框架,用于采集、处理和导出应用的 Trace(链路追踪)、Metrics(指标)、Logs(日志) 三大核心可观测性数据。
OpenTelemetry不是像Jaeger、Prometheus或商业供应商那样的观测性后端。OpenTelemetry关注于追踪数据的生成、收集、管理和导出。存储和可视化数据留给其他工具。
OpenTelemetry 优点
传统可观测性方案的问题:
- 各家标准不统一(Prometheus、Jaeger、Zipkin、ELK 各搞各的),后期更换组件成本巨大。
- SDK 难以复用,语言多了埋点就变得混乱
- 很多工具不支持日志 + 指标 + 链路统一分析
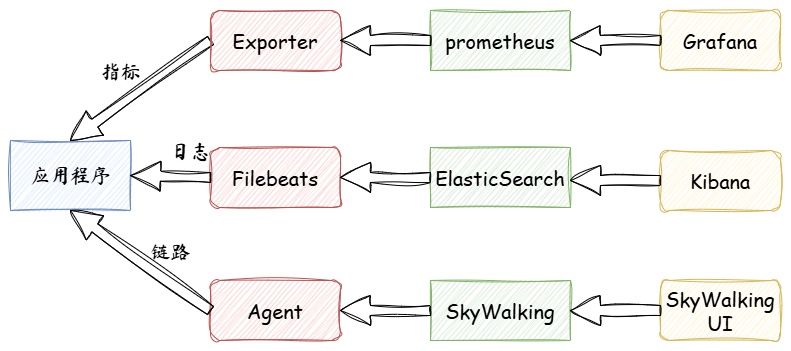
OpenTelemetry 的优势是:
- 用一个统一协议打通链路、指标、日志三者
- 支持多语言自动埋点
- 和 Prometheus/Grafana/Jaeger 无缝对接
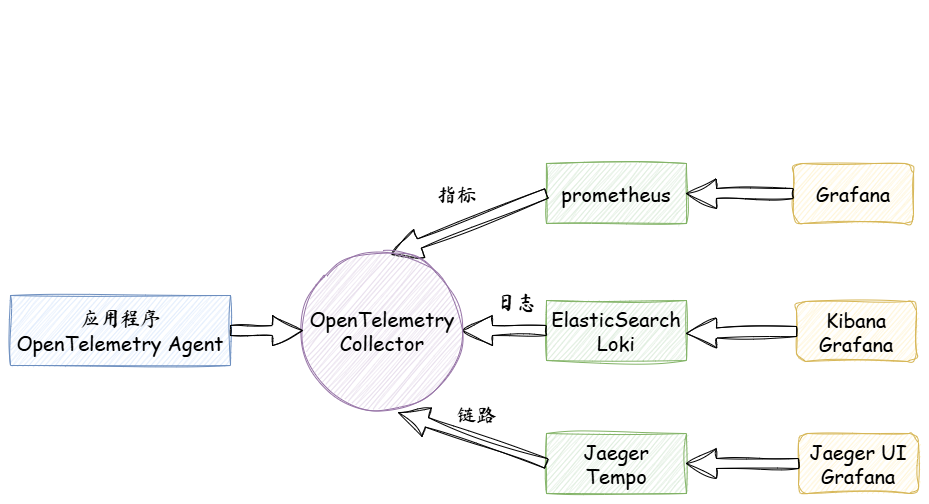
OpenTelemetry 组件架构
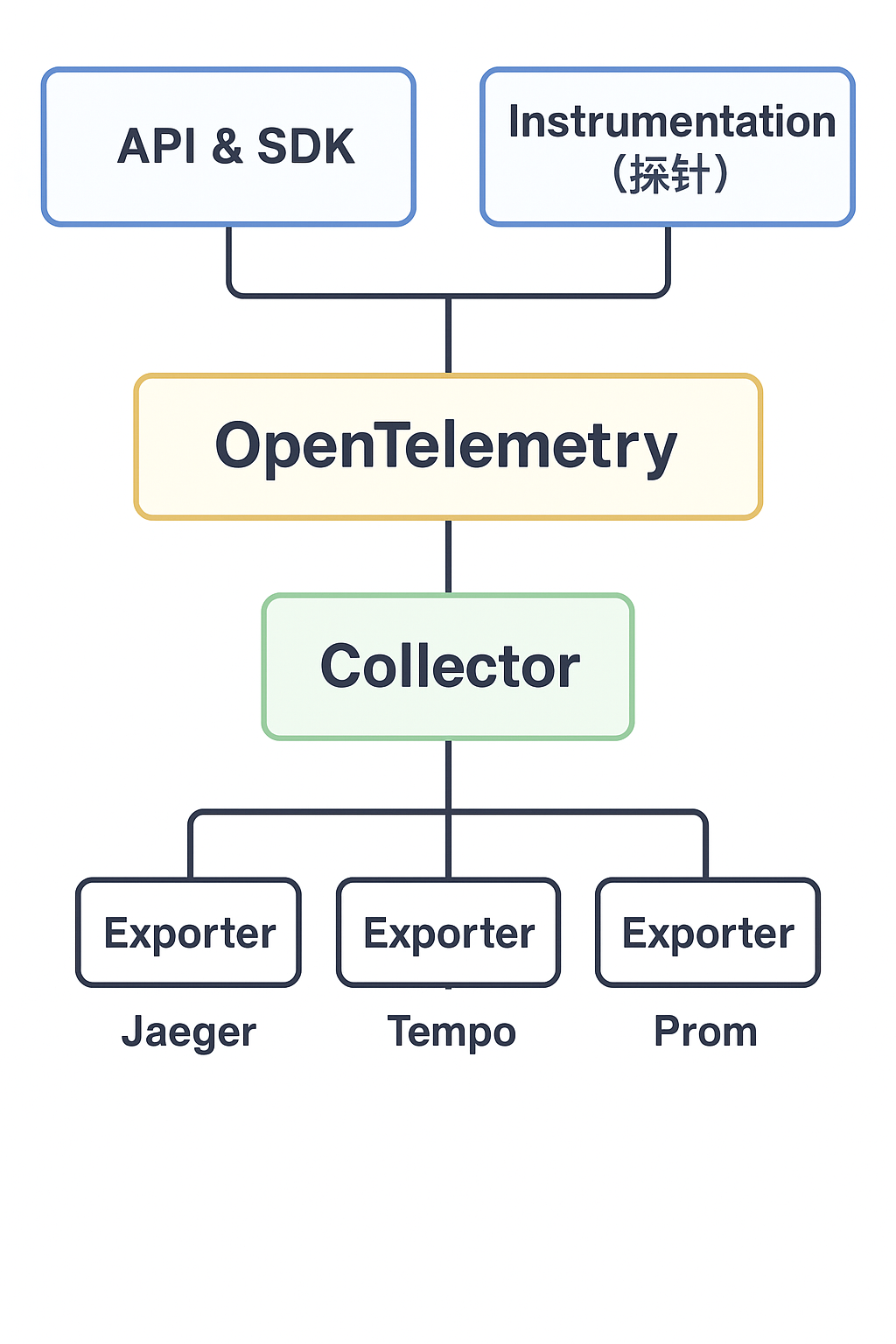
| 组件 | 说明 |
|---|---|
| API & SDK | 提供各语言(Go、Java、Python、Node.js 等)的统一接口和实现,供开发者在应用中埋点 |
| Instrumentation | 自动或手动的代码埋点方式,用于生成 Trace、Metric 数据 |
| Collector | 一个独立服务,接收应用数据,进行处理(过滤/增强/聚合)后导出到后端系统(Jaeger、Tempo 等) |
| Exporter | Collector 的插件或 SDK 端模块,将数据导出到目标后端存储或 APM 工具 |
| Protocol(OTLP) | 标准数据格式(OTel Protocol),支持 HTTP/gRPC 传输,统一 Trace、Metrics、Logs |
OTLP协议
OpenTelemetry 协议(OTLP)规范描述了遥测数据在遥测源、收集器和遥测后端之间的编码、传输和传递机制。
每种语言的 SDK 都提供了一个 OTLP 导出器,可以配置该导出器来通过 OTLP 导出数据。然后,OpenTelemetry SDK 会将事件转换为 OTLP 数据。
OTLP 是代理(配置为导出器)和收集器(配置为接收器)之间的通信。
Collector
收集器(Collector)是 OpenTelemetry 的一个组件,它接收遥测数据(span、metrics、logs 等),处理(预处理数据)并导出数据(将其发送到想要的通信后端)。
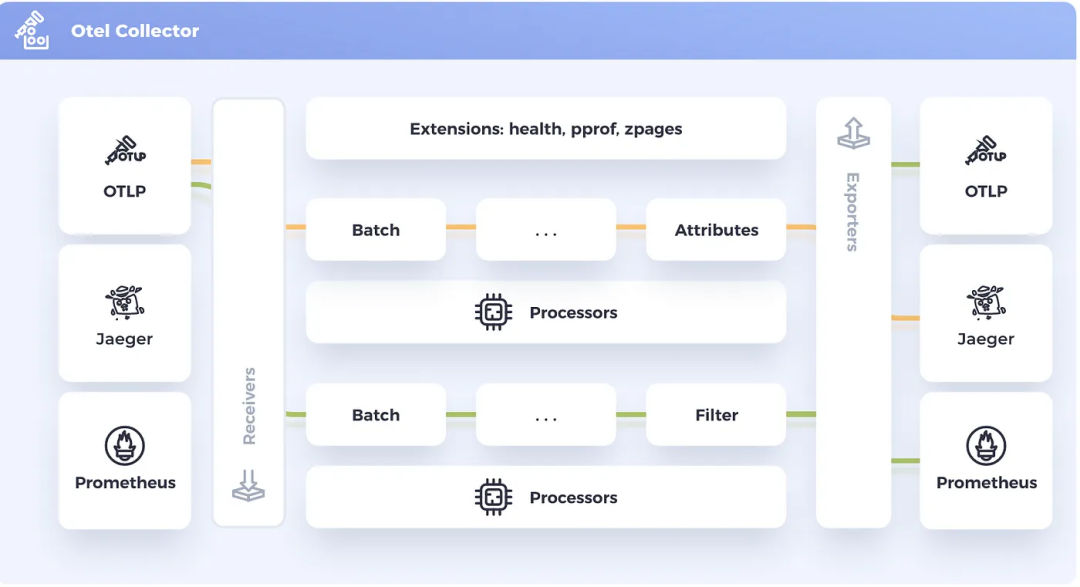
接收器(Receiver)
收集器可以被配置为从各种来源接收各种格式的遥测数据。一旦接收到,所有这些数据都会被转换为 OTLP。OpenTelemetry 同时支持基于推和拉的接收器。
处理器(Processor)
一旦接收器将遥测数据转换为 OTLP,就会有各种处理器可用。处理器可以被配置为执行各种任务。
- 清洗数据以删除敏感数据,如 PII(个人身份信息)。
- 数据规范化,例如将数据源的旧版本转换为与当前后台使用的仪表盘和查询相匹配的版本。
- 根据某些属性将数据路由到特定的后端。例如,将与欧盟用户有关的数据存储在欧盟境内托管的存储系统上。
- 基于尾部的采样,以帮助确保错误和异常值更有可能被捕获,同时对嘈杂和无趣的信息进行速率限制。
导出器(Exporter)
一旦遥测数据被处理,它可以被输出到各种后端,OTLP 可以被转换为目前流行的系统所支持的许多格式。
除了将遥测数据转换为单一格式外,还可以安装多个导出器。遥测数据可以按类型分开,并发送到不同的后端。例如,将追踪数据发送到 Jaeger,将度量数据发送到 Prometheus。
管道(Pipeline)
收集器允许接收器、处理器和导出器组合成复杂的管道(pipeline),可以同时运行。
和skywalking 对比
OpenTelemetry和Skywalking都是用于应用程序性能监控和分布式追踪的工具,但它们之间有一些区别:
- 开源社区支持:OpenTelemetry是由云原生计算基金会(CNCF)支持的开源项目,而Skywalking是Apache软件基金会的顶级项目。
- 语言支持:OpenTelemetry支持多种编程语言,包括Java、Python、Go等,而Skywalking主要支持Java和.NET。
- 数据采集方式:OpenTelemetry通过标准的API和插件机制来收集数据,而Skywalking采用Agent的方式来收集数据。
- 生态系统:OpenTelemetry有一个庞大的生态系统,包括多个厂商和社区的支持,可以方便地集成各种监控工具和服务。而Skywalking的生态系统相对较小,支持的插件和集成相对有限。
总的来说,OpenTelemetry是一个更加通用、灵活和开放的监控和追踪工具,适用于各种不同场景和环境。而Skywalking更专注于Java和.NET应用程序的监控和追踪,可以提供更深度的性能分析和优化。选择哪个工具取决于具体的需求和使用场景。
查看更多
崔亮的博客-专注devops自动化运维,传播优秀it运维技术文章。更多原创运维开发相关文章,欢迎访问https://www.cuiliangblog.cn


?)
![[C#] Winform - 进程间通信(SendMessage篇)](http://pic.xiahunao.cn/nshx/[C#] Winform - 进程间通信(SendMessage篇))

