《VLM-RL: A Unified Vision Language Models and Reinforcement Learning Framework for Safe Autonomous Driving》2024年12月发表,来自Wisconsin Madison分校和Purdue大学的论文。
近年来,基于强化学习(RL)的学习驾驶策略的方法在自动驾驶领域越来越受到关注,并在各种驾驶场景中取得了显著进展。然而,传统的强化学习方法依赖于人工设计的奖励,这需要大量的人力,而且往往缺乏通用性。为了解决这些局限性,我们提出了VLM-RL,这是一个统一的框架,将预训练的视觉语言模型(VLM)与RL集成在一起,使用图像观察和自然语言目标生成奖励信号。VLM-RL的核心是对比语言目标(CLG)作为奖励范式,它使用积极和消极的语言目标来产生语义奖励。我们进一步引入了一种分层奖励合成方法,该方法将基于CLG的语义奖励与车辆状态信息相结合,提高了奖励稳定性,并提供了更全面的奖励信号。此外,在训练过程中采用批处理技术来优化计算效率。CARLA模拟器中的大量实验表明,VLM-RL优于最先进的基线,碰撞率降低了10.5%,路线完成率提高了104.6%,对看不见的驾驶场景具有鲁棒的泛化能力。此外,VLM-RL可以无缝集成几乎任何标准的RL算法,有可能彻底改变依赖人工奖励工程的现有RL范式,并实现持续的性能改进。
1. 核心问题与动机
传统强化学习(RL)在自动驾驶中依赖人工设计奖励函数,存在以下问题:
-
人工成本高:需专家经验,反复调试。
-
泛化性差:手动奖励难以覆盖复杂动态场景。
-
语义理解不足:无法捕捉“安全驾驶”等抽象目标的语义信息。
VLM-RL提出通过预训练视觉语言模型(VLM)生成语义奖励,结合RL策略学习,解决上述问题。
2. 核心贡献
-
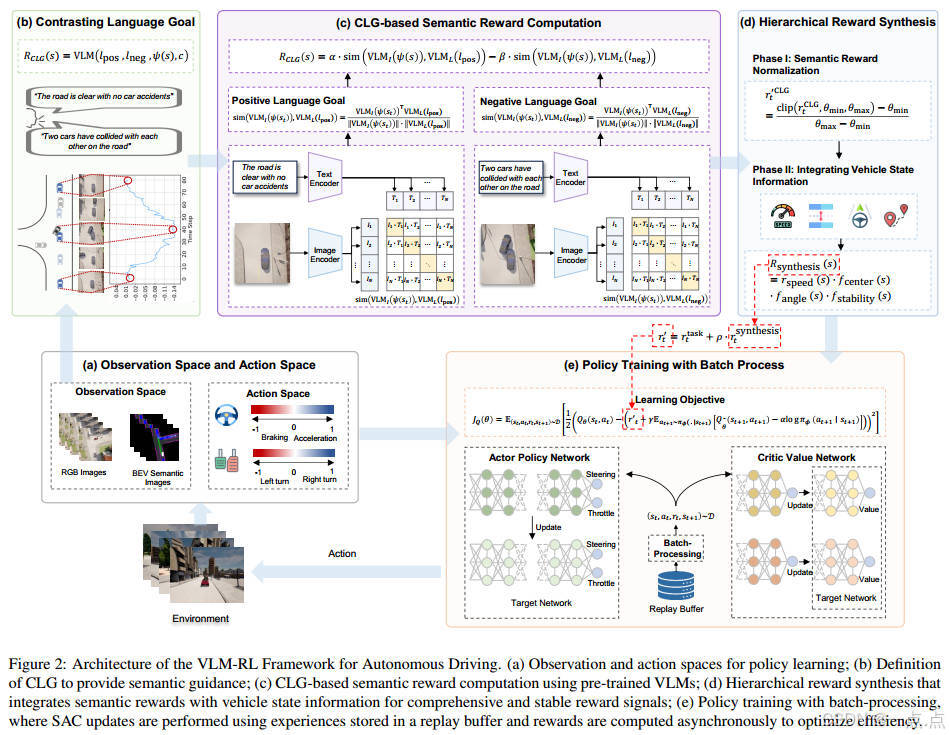
VLM-RL框架:
-
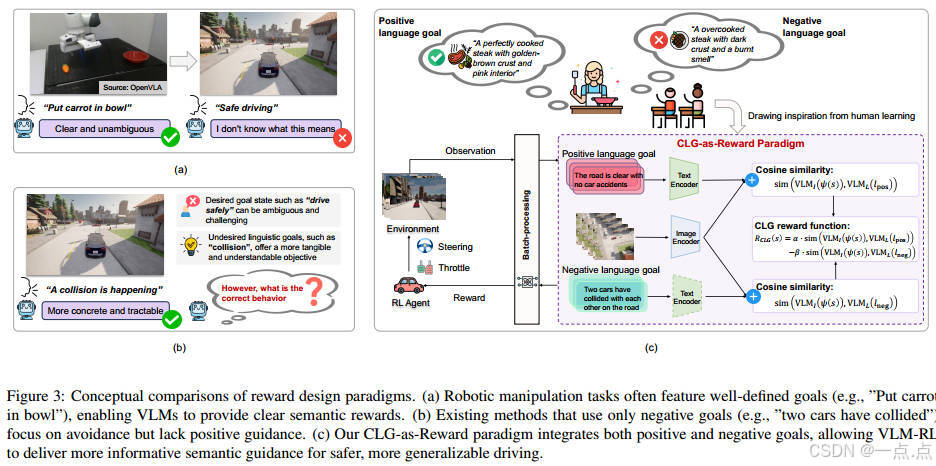
CLG-as-Reward范式:通过对比语言目标(Contrasting Language Goals, CLG),即正负语言描述(如“道路畅通” vs. “车辆碰撞”),计算语义相似性生成奖励。
-
分层奖励合成:将CLG语义奖励与车辆状态信息(速度、车道居中、航向角等)结合,增强奖励的稳定性和全面性。
-
批量处理技术:异步计算奖励,提升训练效率。
-
-
端到端训练:
-
输入:鸟瞰图(BEV)语义分割图像、车辆状态、导航路径。
-
输出:连续控制指令(转向、油门/刹车)。
-
-
实验验证:
-
在CARLA模拟器中,VLM-RL相比基线方法:
-
碰撞率降低10.5%,路线完成率提升104.6%。
-
在未训练过的城镇和交通密度下表现出强泛化性。
-
-
消融实验证明:CLG中正负目标结合、分层奖励设计、BEV输入均对性能提升至关重要。
-
3. 方法创新
-
CLG-as-Reward:
-
奖励公式:
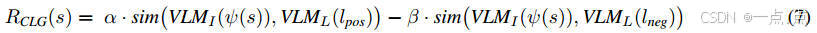
其中,α和β控制正负目标的权重。
-
优势:同时鼓励正向行为、规避负向行为,提供更丰富的学习信号。
-
-
分层奖励合成:
-
结合语义奖励与车辆动态指标(如速度对齐、车道居中),通过乘积形式融合,避免多目标冲突。
-
示例:
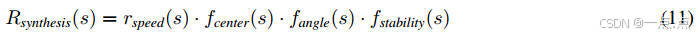
-
-
批量处理优化:
-
从回放缓冲区周期性采样观测数据,异步计算CLIP嵌入,减少实时推理开销。
-
4. 实验结果
-
训练性能:
-
VLM-RL在路线完成数(4.4 vs. 基线1.9)、总行驶距离(1780m vs. 671m)上显著优于基于LLM/VLM的方法。
-
碰撞速度(2.6 km/h)低于大多数基线,安全性更优。
-
-
泛化能力:
-
未见城镇:在Town 1-5中保持高成功率(0.87-1.00)和低碰撞速度(0.03-2.15 km/h)。
-
不同交通密度:在40辆自动驾驶车辆的密集场景中,碰撞速度仅0.11 km/h,优于基线。
-
-
模型规模影响:
-
更大CLIP模型(如ViT-bigG-14)生成更精准的语义奖励,但需权衡计算成本。
-
5. 局限性与未来方向
-
局限性:
-
实时性:CLIP推理延迟可能影响部署效率。
-
场景覆盖:未考虑行人、交通信号灯等复杂交互。
-
语言目标局限:部分场景(如偏离道路)的语义奖励不够敏感。
-
-
未来工作:
-
模型轻量化(蒸馏、量化)以提升效率。
-
扩展任务范围(行人交互、交通灯响应)。
-
结合人类反馈动态调整CLG目标。
-
6. 总结
VLM-RL通过语义奖励自动生成和分层奖励融合,显著降低了传统RL对人工奖励设计的依赖,提升了自动驾驶策略的安全性和泛化性。其核心创新在于:
-
利用VLM的语义理解能力,将抽象驾驶目标转化为可学习的奖励信号。
-
结合车辆动态信息,构建稳定、全面的奖励函数。
-
在复杂动态场景中展现了优异的性能与鲁棒性。
该框架为自动驾驶的奖励设计提供了新范式,并为VLM与RL的融合应用开辟了方向。未来的优化可围绕实时性、场景扩展和人机协同展开。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!


?)
![[C#] Winform - 进程间通信(SendMessage篇)](http://pic.xiahunao.cn/nshx/[C#] Winform - 进程间通信(SendMessage篇))

